本周的内容是Amortized Analysis,是对算法复杂度的另一种分析。它的基本概念是,给定一连串操作,大部分的操作是非常廉价的,有极少的操作可能非常昂贵,因此一个标准的最坏分析可能过于消极了。因此,其基本理念在于,当昂贵的操作特别少的时候,他们的成本可能会均摊到所有的操作上。如果人工均摊的花销仍然便宜的话,对于整个序列的操作我们将有一个更加严格的约束。本质上,均摊分析就是在最坏的场景下,对于一连串操作给出一个更加严格约束的一种策略。
均摊分析与平均情况分析的区别在于,平均情况分析是平均所有的输入,比如,INSERTION SORT算法对于所有可能的输入在平均情况下表现性能不错就算它在某些输入下表现性能是非常差的。而均摊分析是平均操作,比如,TABLEINSERTION算法在所有的操作上平均表现性能很好尽管一些操作非常耗时。在均摊分析中,不涉及概率,并且保证在最坏情况下每一个操作的平均性能。
有三类比较常见的均摊分析:
1.聚类分析:证明对所有的n,由n个操作所构成的序列的总时间在最坏情况下为T(n),每一个操作的平均成本为T(n)/n;比如栈的操作,对于一个空栈的入栈和出栈的操作
2.记账方法:在平摊分析的记帐方法中,决定每一个操作的均摊成本,对不同的操作赋予不同的费用,某些操作的费用比它们的实际代价或多或少。我们对一个操作的收费的数量称为平摊代价。当一个操作的平摊代价超过了它的实际代价时,两者的差值就被当作存款(credit),并赋予数据结构中的一些特定对象,可以用来补偿那些平摊代价低于其实际代价的操作。这种方法与聚集分析不同的是,对后者,所有操作都具有相同的平摊代价。数据结构中存储的总存款等于总的平摊代价和总的实际代价之差。注意:总存款不能是负的。在开始阶段对于过度要价存储预先支付的存款,在后面的序列中再支付操作。比如,二进制计数器: 通过二进制触发器计算一系列数字
3.势能方法:在平摊分析中,势能方法(potential method)不是将已预付的工作作为存在数据结构特定对象中存款来表示,而是将存款总体上表示成一种“势能”或“势”,它在需要时可以释放出来,以支付后面的操作。势是与整个数据结构而不是其中的个别对象发生联系的。比如,动态表,可以动态改变大小的连续存储数组。
一、聚类分析
在聚类分析中,对于一连串的n的操作,我们计算总的最坏时间T(n). 在最坏情况下,每一个操作的平均成本或者均摊成本是T(n)/n. 成本T(n)/n适用于每一个操作(可能有几种类型的操作)。另外两种方法可能将不同的均摊成本分配给不同类型的操作。
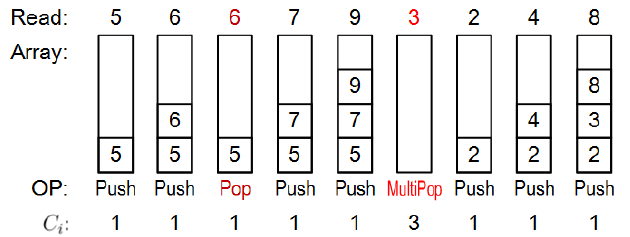
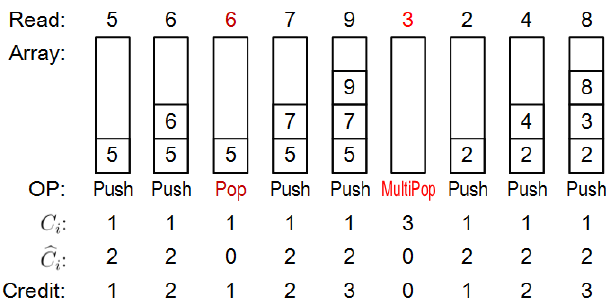
比如,有MULTIPOP操作的栈。有两种基本的栈操作都分别花费O(1)的时间: PUSH(S,x)和POP(S)分别是将对象x压入栈中,从栈S的顶部弹出并返回弹出的对象。将每一个操作的花销都赋为1. 一连串n个PUSH和POP操作的总消耗为n,对于n个操作的实际运行时间为O(n).
现在添加一个额外的栈操作MULTIPOP。MULTIPOP(S,k) 是弹出栈S的前k个对象(或者弹出整个栈如果k大于栈的大小的话)。

MULTIPOP的总消耗是min{|S|,k}.
现在考虑在一个初始为空的栈上的一序列n个POP,PUSH和MULTIPOP操作。算法伪代码如下:

下面为一个例子:
粗略地分析,MULTIPOP (S,k)将会花费O(n)的时间,因此,
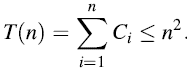
在操作序列中,一些操作可能会很廉价,但是一些操作可能会非常昂贵耗时,比如MULTIPOP(S,k). 然而,最坏的操作往往不是经常被调用的。因此,传统的最坏的单一操作分析会给出过于消极的边界。
我们的目标是,对于每一个操作,我们希望能够赋予其一个均摊的成本

这里,
使用聚类分析使得有更加紧凑的边界分析,对于所有的操作都有相同的均摊成本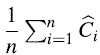
观察得知,POP操作的数目一定小于或者等于PUSH操作的数目。因此,我们可以得到:
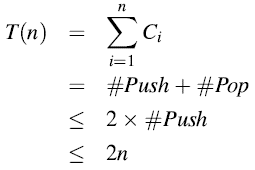
因此,平均来看,MULTIPOP(S,k)这一步将花费O(1)而不是O(k)的时间。
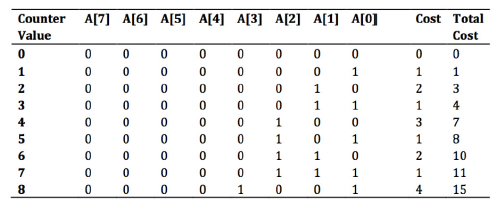
这里来看另一个例子,考虑一个从0开始计数的k位的二进制计数器。使用位的数组A[0,…, k-1]来记录计数。存储在计数器中的二进制数在A[0]有最低阶的位,在A[k-1]有最高阶的位,并且有
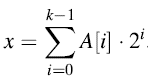
初始时,x=0, 对于i = 0,… k-1, 都有A[i]=0
一个存储案例如下:
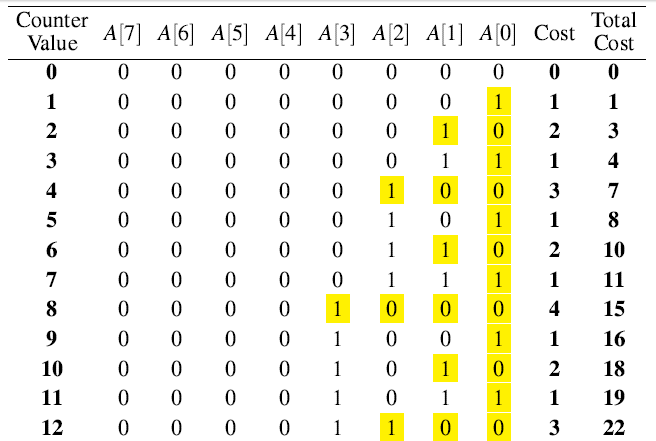
INCREMENT算法是用来在计数器中加1(2^k)到一个值上。
算法伪代码描述为:

考虑从0开始计数的n个操作的一个序列:

那么粗略计算,我们可以得到T(n)<= kn,因为一个增加操作可能会改变所有的k位。
我们使用聚类计数来紧凑分析的话,有基本的操作flip(1->0)和flip(0->1)
在n个INCREMENT操作的一个序列中,
A[0] 每一次INCREMENT被调用的时候都会flip,因此flip n次;
A[1] 每两次调用INCREMENT时flip,因此flip n/2次;(通过列中标记的黄色可以看出来规律)
…
A[i] flips 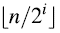
因此,
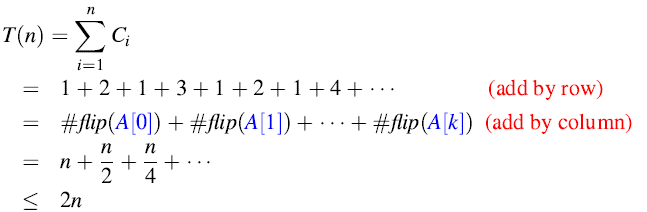
每一个操作的均摊成本为: O(n)/n =O(1).
二、记账方法
记账方法的基本思路为,对于每一个有实际成本COP的操作OP而言,均摊成本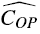
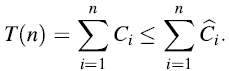
如果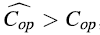
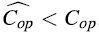
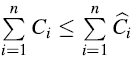
我们回到有MULTIPOP操作的栈的问题,对于这样的栈,将均摊成本分配为:

其中,credit是栈中条目的数目。
从一个空栈开始,n1个PUSH,n2个POP和n3个MULTIPOP操作的任意序列最多的花销是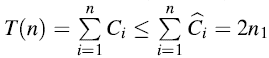
需要注意的是,当有超过一种类型的操作时,每一种类型的操作可能被赋予不同的均摊成本。
下面通过一个银行家的观点来看记账方法。假如你正在租一个操作硬币的机器,并且根据操作的数量来收费。那么有两种支付方法:
A. 对每一种实际的操作支付实际费用:比如PUSH支付1元,POP支付1元,MULTIPOP支付k元
B. 开一个账户,对每一个操作支付平均费用:比如PUSH支付2元,POP支付0元,MULTIPOP支付0元
如果平均花销大于实际的费用,那么额外的将被存储为credit(存款);如果平均成本小于实际的花费,那么credit将被用来支付实际的花费。这里的限制条件为:
对任意的n个操作,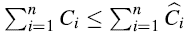
下面是一个例子:
对于之前的二进制计数器有一样的道理,赋予均摊成本为:

我们可以观察到flip(0->1)的数目大于等于flip(1->0),因此有
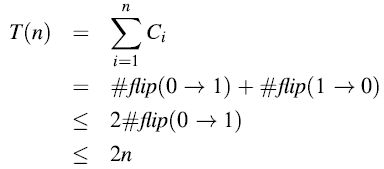
三、势能方法
势能方法是从一个物理学家的角度出发看问题,基本思路是有势,对于每一个操作OP直接设置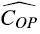
定义势能函数为: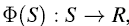
均摊成本的设置为: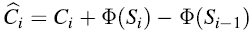
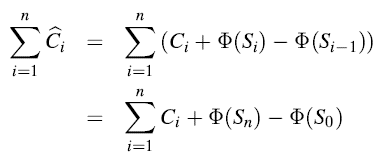
为了保证 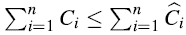

对于栈的例子,令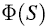
因此,栈S的状态为:
那么势能函数 的折线图表示为下图:
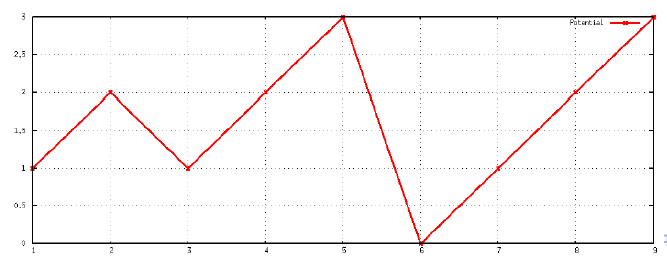
我们如下定义:
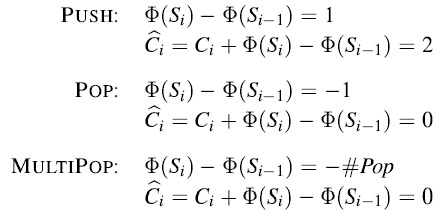
因此,从一个空栈开始,n1个PUSH,n2个POP和n3个MULTIPOP操作的任意序列花费最多
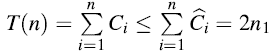
,这里n = n1 + n2 + n3.
在二进制计数器中,在计数器中将
此时,势能函数 的折线图表示为:
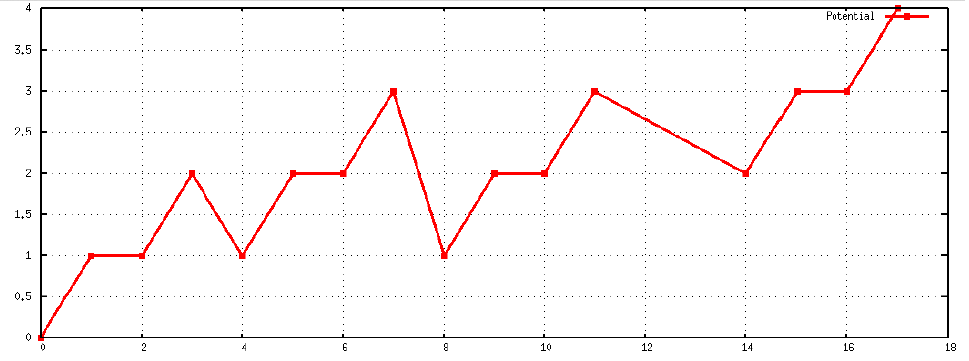
在计数器中将
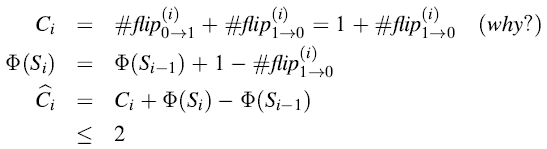
因此,我们有
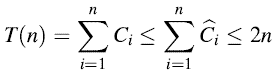
换句话说,从00…0开始,n个INCREMENT操作的一个序列最多花费2n时间。
下面考虑一个实际的问题:
假设现在我们被要求开发一个C++的编译器。Vector是一个C++的类模板来存储一系列的对象。它支持一下操作:
a.push_back: 添加一个新的对象到末尾
b.pop-back:将最后一个对象弹出
注意vector使用一个连续的内存区域来存储对象。那么我们该如何为vector设计一个有效的内存分配策略呢?
这就引出了动态表的问题。
在许多应用中,我们不能够提前知道在一个表中要存储多少个对象。因此,我们不得不对一个表分配一定空间,但最后发现其实不够用。下面引出两个概念:
动态扩展:当在一个全表中插入一个新的项时,这个表必须被重新成一个更大的表,原来表中的对象必须被拷贝到新表中。
动态收缩:相似的,如果从一个表中删除了许多的对象,那么这个表可以被重新分配成一个尺寸变小的新表。
我们将给出一个内存分配策略使得插入和删除的均摊成本是O(1).,就算一个操作触发扩展或者收缩时其实际成本是较大的。

动态表扩展的例子:

考虑从一个空栈开始的操作的一个序列:
Overflow之后扩展表的操作:

粗略地分析,考虑这样的一个操作序列,如果我们根据基本的插入和删除操作来定义成本,那么第i个操作的实际成本Ci是
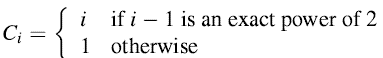
这里的Ci = i是当表为满的时候,因为此时我们需要插入一次,并且拷贝i-1项到新表中。
如果n个操作被执行了,那么一个操作的最坏情况下的成本将为O(n). 这样的话,对于总的n个操作的总运行时间为O(n^2),并不如我们需要的紧凑。
对于以上情况,我们如果使用聚类分析:
首先观察到表的扩展是非常少的, 因为在n个操作中表扩展不常发生,因此O(n^2)的边界并不紧凑。
特别的,表扩展发生在第i次操作,其中i-1恰好是2的幂。

因此,我们可以将Ci分解为:

这样n个操作的总花费为:
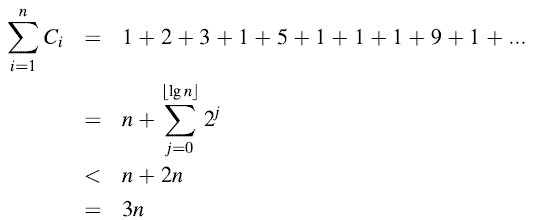
因此,每一个操作的均摊成本为3,换句话说,每一个TABLEINSERT操作的平均成本为O(n)/n=O(1)
如果我们使用记账方法:
对于第i次操作,一个均摊成本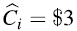
因此,对于第i个操作,$3被用在以下场合:
A.$1支付自身插入操作
B.$2存储为之后的表扩展,包括$1给拷贝最近的i/2项和$1给拷贝之前的i/2项
如图:
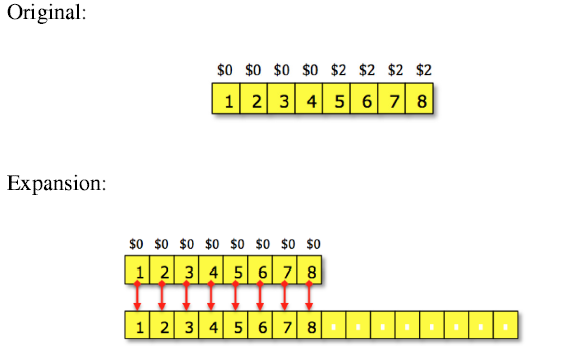
存款绝不会为负。换句话说,均摊成本的和给出了实际成本的和的一个上界。

如果我们使用势能方法:
银行账户可以被看做一个动态集合的势能函数。更加明确来说,我们希望有一个这样性质的势能函数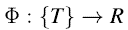
a.在一次扩展之后,
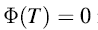
b.在一次扩展之前,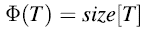
一个可能的情况:

其折线图为:
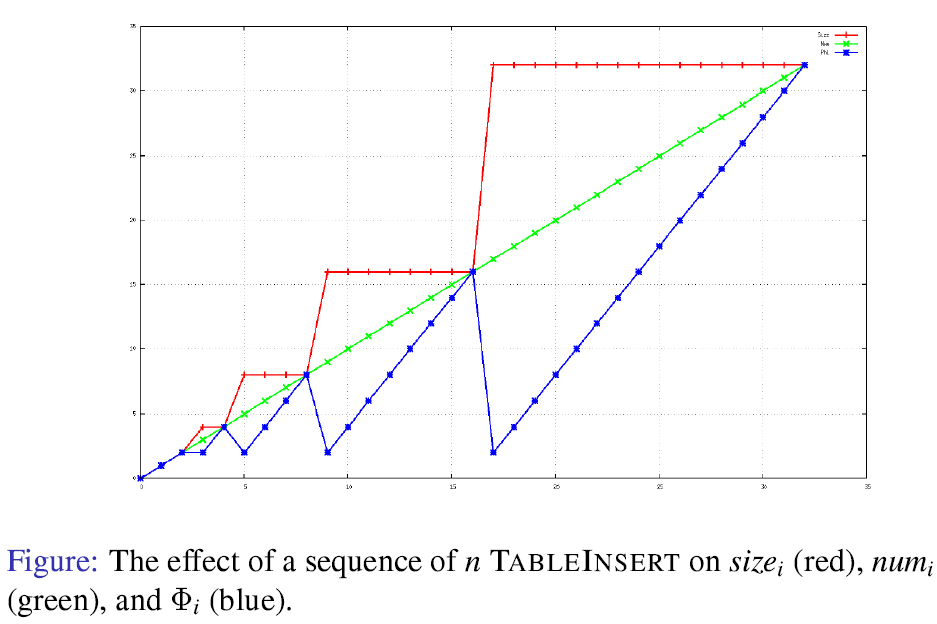
初始时,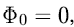
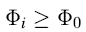
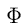
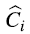
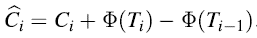
这样的话, 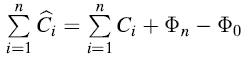
下面分
Case-1:第i次插入不会触发一个扩展
此时,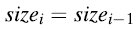

Case-2:第i次操作触发了一个表的扩展
此时,
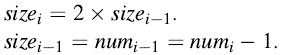

因此,从一个空表开始,一个n个TABLEINSERT操作的序列在最坏情况下花费O(n).
删除操作是类似的分析。
总的来说,因为每一个操作的均摊分析是被一个常数给界顶了,因此如果是从空表开始,在一个动态表上的任何n个TABLEINSERT和TABLEDELETE操作的序列的实际花销都是O(n).
均摊分析可以为数据结构性能提供一个清晰的抽象。当一个均摊分析被调用时,任何的分析方法都可以被使用,但是每一种方法都有一些是被有争议为最简单的情况。不同的方法可能适用于不同的均摊成本赋值,并且有时可能得到完全不同的界。