1、前言
今天看代码时候,遇到一些宏,之前没有见过,感觉挺新鲜。如是上网google一下,顺便总结一下,方便以后学习和运用。C语言程序中广泛的使用宏定义,采用关键字define进行定义,宏只是一种简单的字符串替换,根据是否带参数分为无参和带参。宏的简单应用很容易掌握,今天主要总结一下宏的特殊符号及惯用法。
(1)宏中包含特殊符号:#、##.
(2)宏定义用do{ }while(0)
2、特殊符号#、##
(1)#
When you put a # before an argument in a preprocessor macro, the preprocessor turns that argument into a character array.
在一个宏中的参数前面使用一个#,预处理器会把这个参数转换为一个字符数组
简化理解:#是“字符串化”的意思,出现在宏定义中的#是把跟在后面的参数转换成一个字符串
#define ERROR_LOG(module) fprintf(stderr,"error: "#module"
")
ERROR_LOG("add"); 转换为 fprintf(stderr,"error: "add" ");
ERROR_LOG(devied =0); 转换为 fprintf(stderr,"error: devied=0 ");
(2)##
“##”是一种分隔连接方式,它的作用是先分隔,然后进行强制连接。
在普通的宏定义中,预处理器一般把空格解释成分段标志,对于每一段和前面比较,相同的就被替换。但是这样做的结果是,被替换段之间存在一些空格。如果我们不希望出现这些空格,就可以通过添加一些##来替代空格。
1 #define TYPE1(type,name) type name_##type##_type
2 #define TYPE2(type,name) type name##_##type##_type
TYPE1(int, c); 转换为:int name_int_type ; (因为##号将后面分为 name_ 、type 、 _type三组,替换后强制连接)
TYPE2(int, d);转换为: int d_int_type ; (因为##号将后面分为 name、_、type 、_type四组,替换后强制连接)
3、宏定义中do{ }while(0)
第一眼看到这样的宏时,觉得非常奇怪,为什么要用do……while(0)把宏定义的多条语句括起来?非常想知道这样定义宏的好处是什么,于是google、百度一下了。
采用这种方式是为了防范在使用宏过程中出现错误,主要有如下几点:
(1)空的宏定义避免warning:
#define foo() do{}while(0)
(2)存在一个独立的block,可以用来进行变量定义,进行比较复杂的实现。
(3)如果出现在判断语句过后的宏,这样可以保证作为一个整体来是实现:
#define foo(x)
action1();
action2();
在以下情况下:
if(NULL == pPointer)
foo();
就会出现action1和action2不会同时被执行的情况,而这显然不是程序设计的目的。
(4)以上的第3种情况用单独的{}也可以实现,但是为什么一定要一个do{}while(0)呢,看以下代码:
#define switch(x,y) {int tmp; tmp="x";x=y;y=tmp;}
if(x>y)
switch(x,y);
else //error, parse error before else
otheraction();
在把宏引入代码中,会多出一个分号,从而会报错。这对这一点,可以将if和else语句用{}括起来,可以避免分号错误。
使用do{….}while(0) 把它包裹起来,成为一个独立的语法单元,从而不会与上下文发生混淆。同时因为绝大多数的编译器都能够识别do{…}while(0)这种无用的循环并进行优化,所以使用这种方法也不会导致程序的性能降低
4、测试程序
简单写个测试程序,加强练习,熟悉一下宏的高级用法。

1 #include <stdio.h>
2
3 #define PRINT1(a,b)
4 {
5 printf("print a
");
6 printf("print b
");
7 }
8
9 #define PRINT2(a, b)
10 do{
11 printf("print a
");
12 printf("print b
");
13 }while(0)
14
15 #define PRINT(a)
16 do{
17 printf("%s: %d
",#a,a);
18 printf("%d: %d
",a,a);
19 }while(0)
20
21 #define TYPE1(type,name) type name_##type##_type
22 #define TYPE2(type,name) type name##_##type##_type
23
24 #define ERROR_LOG(module) fprintf(stderr,"error: "#module"
")
25
26 main()
27 {
28 int a = 20;
29 int b = 19;
30 TYPE1(int, c);
31 ERROR_LOG("add");
32 name_int_type = a;
33 TYPE2(int, d);
34 d_int_type = a;
35
36 PRINT(a);
37 if (a > b)
38 {
39 PRINT1(a, b);
40 }
41 else
42 {
43 PRINT2(a, b);
44 }
45 return 0;
46 }
测试结果如下:
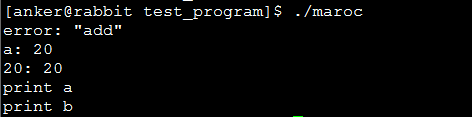
5、参考网址
http://blog.csdn.net/jiangjingui2011/article/details/6706967
http://www.kuqin.com/language/20080721/11906.html
http://www.360doc.com/content/12/0405/16/8302596_201146109.shtml
http://blog.csdn.net/liliangbao/article/details/4163440
宏定义中的#,##
1、在一个预处理器宏中的参数前面使用一个#,预处理器会把这个参数转换为一个字符数组。(原文:When you put a # before an argument in a preprocessor
macro, the preprocessor turns that argument into a character array. This,
combined with the fact that character arrays with no intervening punctuation are concatenated into a single character array, allows you to make a very convenient macro for printing the values of variables during debugging)
#include "iostream"
using namespace std;
#define P(A) cout<<#A<<": "<<(A)<<endl;
int main()
{
int a=1,b=2;
P(a);
P(b);
P(a+b);
return 1;
}
http://blog.163.com/zhoumhan_0351/blog/static/39954227201032124942513/
2、#define D(a) cout << #a "=[" << a << "]" << endl;
3、#是“字符串化”的意思。出现在宏定义中的#是把跟在后面的参数转换成一个字符串
例如:
> #define FOO(arg) my##arg
则
> FOO(abc)
相当于 myabc
例如:
> #define STRCPY(dst, src) strcpy(dst, #src)
则
> STRCPY(buff, abc)
相当于 strcpy(buff, "abc")
另外,如果##后的参数本身也是一个宏的话,##会阻止这个宏的展开,也就是只替换一次。
#define STRCPY(a, b) strcpy(a ## _p, #b)
int main()
{
char var1_p[20];
char var2_p[30];
/* 注意这里 */
STRCPY(STRCPY(var1,var2),var2);
/* 这里是否会展开为: strcpy(strcpy(var1_p,"var2")_p,"var2“)?
* 答案是否定的:
* 展开结果将是: strcpy(STRCPY(var1,var2)_p,"var2")
* ## 阻止了参数的宏展开!
* 如果宏定义里没有用到 # 和 ##, 宏将会完全展开
*/
}
http://blog.chinaunix.net/u/17855/showart_113663.html
4、about ## in common text
(1)关于记号粘贴操作符(token paste operator): ##
简单的说,“##”是一种分隔连接方式,它的作用是先分隔,然后进行强制连接。
其中,分隔的作用类似于空格。我们知道在普通的宏定义中,预处理器一般把空格解释成分段标志,对于每一段和前面比较,相同的就被替换。但是这样做的结果是,被替换段之间存在一些空格。如果我们不希望出现这些空格,就可以通过添加一些##来替代空格。
另外一些分隔标志是,包括操作符,比如 +, -, *, /, [,], ...,所以尽管下面的
宏定义没有空格,但是依然表达有意义的定义: define add(a, b) a+b
而其强制连接的作用是,去掉和前面的字符串之间的空格,而把两者连接起来。
(2)举列 -- 试比较下述几个宏定义的区别
#define A1(name, type) type name_##type##_type 或
#define A2(name, type) type name##_##type##_type
A1(a1, int); /* 等价于: int name_int_type; */
A2(a1, int); /* 等价于: int a1_int_type; */
解释:
1) 在第一个宏定义中,"name"和第一个"_"之间,以及第2个"_"和第二个"type"之间没有被分隔,所以预处理器会把name_##type##_type解释成3段:
“name_”、“type”、以及“_type”,这中间只有“type”是在宏前面出现过
的,所以它可以被宏替换。
2) 而在第二个宏定义中,“name”和第一个“_”之间也被分隔了,所以
预处理器会把name##_##type##_type解释成4段:“name”、“_”、“type”
以及“_type”,这其间,就有两个可以被宏替换了。
3) A1和A2的定义也可以如下:
#define A1(name, type) type name_ ##type ##_type
<##前面随意加上一些空格>
#define A2(name, type) type name ##_ ##type ##_type
结果是## 会把前面的空格去掉完成强连接,得到和上面结果相同的宏定义
(3)其他相关 -- 单独的一个 #
至于单独一个#,则表示对这个变量替换后,再加双引号引起来。比如
#define __stringify_1(x) #x
那么
__stringify_1(linux) <==> "linux"
(5)#(stringizing)字符串化操作符。其作用是:将宏定义中的传入参数名转换成用一对双引号括起来参数名字符串。其只能用于有传入参数的宏定义中,且必须置于宏定义体中的参数名前。
如:
#define example(instr) printf("the input string is: %s ",#instr)
#define example1(instr) #instr
当使用该宏定义时:
example(abc); 在编译时将会展开成:printf("the input string is: %s ","abc");
string str=example1(abc); 将会展成:string str="abc";
注意:
对空格的处理
a。忽略传入参数名前面和后面的空格。
如:str=example1( abc ); 将会被扩展成 str="abc";
b.当传入参数名间存在空格时,编译器将会自动连接各个子字符串,用每个子字符串中只以一个空格连接,忽略其中多于一个的空格。
如:str=exapme( abc def); 将会被扩展成 str="abc def";
其它参考
[1]http://blog.chinaunix.net/u/17855/showart_113663.html
C语言宏的高级应用
关于#和##在C语言的宏中,#的功能是将其后面的宏参数进行字符串化操作(Stringfication),简单说就是在对它所引用的宏变量通过替换后在其左右各加上一个双引号。比如下面代码中的宏:
#define WARN_IF(EXP)
do{ if (EXP)
fprintf(stderr, "Warning: " #EXP " "); }
while(0)
那么实际使用中会出现下面所示的替换过程:
WARN_IF (divider == 0);
被替换为
do {
if (divider == 0)
fprintf(stderr, "Warning" "divider == 0" " ");
} while(0);
这样每次divider(除数)为0的时候便会在标准错误流上输出一个提示信息。
而##被称为连接符(concatenator),用来将两个Token连接为一个Token。注意这里连接的对象是Token就行,而不一定是宏的变量。比如你要做一个菜单项命令名和函数指针组成的结构体的数组,并且希望在函数名和菜单项命令名之间有直观的、名字上的关系。那么下面的代码就非常实用:
struct command
{
char * name;
void (*function) (void);
};
#define COMMAND(NAME) { NAME, NAME ## _command }
// 然后你就用一些预先定义好的命令来方便的初始化一个command结构的数组了:
struct command commands[] = {
COMMAND(quit),
COMMAND(help),
...
}
COMMAND宏在这里充当一个代码生成器的作用,这样可以在一定程度上减少代码密度,间接地也可以减少不留心所造成的错误。我们还可以n个##符号连接 n+1个Token,这个特性也是#符号所不具备的。比如:
#define LINK_MULTIPLE(a,b,c,d) a##_##b##_##c##_##d
typedef struct _record_type LINK_MULTIPLE(name,company,position,salary);
// 这里这个语句将展开为:
// typedef struct _record_type name_company_position_salary;
关于...的使用
...在C宏中称为Variadic Macro,也就是变参宏。比如:
#define myprintf(templt,...) fprintf(stderr,templt,__VA_ARGS__)
// 或者
#define myprintf(templt,args...) fprintf(stderr,templt,args)
第一个宏中由于没有对变参起名,我们用默认的宏__VA_ARGS__来替代它。第二个宏中,我们显式地命名变参为args,那么我们在宏定义中就可以用 args来代指变参了。同C语言的stdcall一样,变参必须作为参数表的最有一项出现。当上面的宏中我们只能提供第一个参数templt时,C标准要 求我们必须写成:
myprintf(templt,);
的形式。这时的替换过程为:
myprintf("Error!
",);
替换为:
fprintf(stderr,"Error!
",);
这是一个语法错误,不能正常编译。这个问题一般有两个解决方法。首先,GNU CPP提供的解决方法允许上面的宏调用写成:
myprintf(templt);
而它将会被通过替换变成:
fprintf(stderr,"Error! ",);
很明显,这里仍然会产生编译错误(非本例的某些情况下不会产生编译错误)。除了这种方式外,c99和GNU CPP都支持下面的宏定义方式:
#define myprintf(templt, ...) fprintf(stderr,templt, ##__VAR_ARGS__)
这时,##这个连接符号充当的作用就是当__VAR_ARGS__为空的时候,消除前面的那个逗号。那么此时的翻译过程如下:
myprintf(templt);
被转化为:
fprintf(stderr,templt);
这样如果templt合法,将不会产生编译错误。
错误的嵌套-Misnesting
宏的定义不一定要有完整的、配对的括号,但是为了避免出错并且提高可读性,最好避免这样使用。
由操作符优先级引起的问题-Operator Precedence Problem
由于宏只是简单的替换,宏的参数如果是复合结构,那么通过替换之后可能由于各个参数之间的操作符优先级高于单个参数内部各部分之间相互作用的操作符优先级,如果我们不用括号保护各个宏参数,可能会产生预想不到的情形。比如:
#define ceil_div(x, y) (x + y - 1) / y
那么
a = ceil_div( b & c, sizeof(int) );
将被转化为:
a = ( b & c + sizeof(int) - 1) / sizeof(int);
// 由于+/-的优先级高于&的优先级,那么上面式子等同于:
a = ( b & (c + sizeof(int) - 1)) / sizeof(int);
这显然不是调用者的初衷。为了避免这种情况发生,应当多写几个括号:
#define ceil_div(x, y) (((x) + (y) - 1) / (y))
消除多余的分号-Semicolon Swallowing
通常情况下,为了使函数模样的宏在表面上看起来像一个通常的C语言调用一样,通常情况下我们在宏的后面加上一个分号,比如下面的带参宏:
MY_MACRO(x);
但是如果是下面的情况:
#define MY_MACRO(x) {
/* line 1 */
/* line 2 */
/* line 3 */ }
//...
if (condition())
MY_MACRO(a);
else
{...}
这样会由于多出的那个分号产生编译错误。为了避免这种情况出现同时保持MY_MACRO(x);的这种写法,我们需要把宏定义为这种形式:
#define MY_MACRO(x) do {
/* line 1 */
/* line 2 */
/* line 3 */ } while(0)
这样只要保证总是使用分号,就不会有任何问题。
Duplication of Side Effects
这里的Side Effect是指宏在展开的时候对其参数可能进行多次Evaluation(也就是取值),但是如果这个宏参数是一个函数,那么就有可能被调用多次从而达到不一致的结果,甚至会发生更严重的错误。比如:
#define min(X,Y) ((X) > (Y) ? (Y) : (X))
//...
c = min(a,foo(b));
这时foo()函数就被调用了两次。为了解决这个潜在的问题,我们应当这样写min(X,Y)这个宏:
#define min(X,Y) ({
typeof (X) x_ = (X);
typeof (Y) y_ = (Y);
(x_ < y_) ? x_ : y_; })
({...})的作用是将内部的几条语句中最后一条的值返回,它也允许在内部声明变量(因为它通过大括号组成了一个局部Scope)
宏定义中使用do{}while(0)的好处
#define MACRO_NAME(para) do{macro content}while(0)
从而不会与上下文发生混淆。同时因为绝大多数的编译器都能够识别do{…}while(0)这种无
用的循环并进行优化,所以使用这种方法也不会导致程序的性能降低
在C++中,有三种类型的循环语句:for, while, 和do...while, 但是在一般应用中作循环时, 我们可能用for和while要多一些,do...while相对不受重视。
但是,最近在读我们项目的代码时,却发现了do...while的一些十分聪明的用法,不是用来做循环,而是用作其他来提高代码的健壮性。
1. do...while(0)消除goto语句。
通常,如果在一个函数中开始要分配一些资源,然后在中途执行过程中如果遇到错误则退出函数,当然,退出前先释放资源,我们的代码可能是这样:
version 1
{
// 分配资源
int *p = new int;
bool bOk(true);
// 执行并进行错误处理
bOk = func1();
if(!bOk)
{
delete p;
p = NULL;
return false;
}
bOk = func2();
if(!bOk)
{
delete p;
p = NULL;
return false;
}
bOk = func3();
if(!bOk)
{
delete p;
p = NULL;
return false;
}
// ..........
// 执行成功,释放资源并返回
delete p;
p = NULL;
return true;
}
这里一个最大的问题就是代码的冗余,而且我每增加一个操作,就需要做相应的错误处理,非常不灵活。于是我们想到了goto:
version 2
{
// 分配资源
int *p = new int;
bool bOk(true);
// 执行并进行错误处理
bOk = func1();
if(!bOk) goto errorhandle;
bOk = func2();
if(!bOk) goto errorhandle;
bOk = func3();
if(!bOk) goto errorhandle;
// ..........
// 执行成功,释放资源并返回
delete p;
p = NULL;
return true;
errorhandle:
delete p;
p = NULL;
return false;
}
代码冗余是消除了,但是我们引入了C++中身份比较微妙的goto语句,虽然正确的使用goto可以大大提高程序的灵活性与简洁性,但太灵活的东西往往是很危险的,它会让我们的程序捉摸不定,那么怎么才能避免使用goto语句,又能消除代码冗余呢,请看do...while(0)循环:
version3
{
// 分配资源
int *p = new int;
bool bOk(true);
do
{
// 执行并进行错误处理
bOk = func1();
if(!bOk) break;
bOk = func2();
if(!bOk) break;
bOk = func3();
if(!bOk) break;
// ..........
}while(0);
// 释放资源
delete p;
p = NULL;
return bOk;
}
2 宏定义中的do...while(0)
如果你是C++程序员,我有理由相信你用过,或者接触过,至少听说过MFC, 在MFC的afx.h文件里面, 你会发现很多宏定义都是用了do...while(0)或do...while(false), 比如说:
#define
AFXASSUME(cond) do { bool __afx_condVal=!!(cond);
ASSERT(__afx_condVal); __analysis_assume(__afx_condVal); } while(0)
粗看我们就会觉得很奇怪,既然循环里面只执行了一次,我要这个看似多余的do...while(0)有什么意义呢?
当然有!
为了看起来更清晰,这里用一个简单点的宏来演示:
#define SAFE_DELETE(p) do{ delete p; p = NULL} while(0)
假设这里去掉do...while(0),
#define SAFE_DELETE(p) delete p; p = NULL;
那么以下代码:
if(NULL != p) SAFE_DELETE(p)
else ...do sth...
就有两个问题,
1) 因为if分支后有两个语句,else分支没有对应的if,编译失败
2) 假设没有else, SAFE_DELETE中的第二个语句无论if测试是否通过,会永远执行。
你可能发现,为了避免这两个问题,我不一定要用这个令人费解的do...while, 我直接用{}括起来就可以了
#define SAFE_DELETE(p) { delete p; p = NULL;}
的确,这样的话上面的问题是不存在了,但是我想对于C++程序员来讲,在每个语句后面加分号是一种约定俗成的习惯,这样的话,以下代码:
if(NULL != p) SAFE_DELETE(p);
else ...do sth...
其else分支就无法通过编译了(原因同上),所以采用do...while(0)是做好的选择了。
也许你会说,我们代码的习惯是在每个判断后面加上{}, 就不会有这种问题了,也就不需要do...while了,如:
if(...)
{
}
else
{
}
诚然,这是一个好的,应该提倡的编程习惯,但一般这样的宏都是作为library的一部分出现的,而对于一个library的作者,他所要做的就是让其库具有通用性,强壮性,因此他不能有任何对库的使用者的假设,如其编码规范,技术水平等