TensorFlow(腾三福[1] )是谷歌基于DistBelief进行研发的第二代人工智能学习系统,其命名来源于本身的运行原理。Tensor(张量)意味着N维数组,Flow(流)意味着基于数据流图的计算,TensorFlow为张量从流图的一端流动到另一端计算过程。TensorFlow是将复杂的数据结构传输至人工智能神经网中进行分析和处理过程的系统。
池化层:降维,把相同特征看成一个,把相同特征中分数最高的提取,其他去掉。
batch:图像中的一小块
stride:卷积核移动的步长
优化网络:
1.梯度下降算法:
梯度下降算法并不能保证被优化的函数达到全局最优解,有可能跌入局部最优解,导致偏导为0,停止更新参数。
在海量的计算中,采用随机梯度下降算法,随机优化某一条训练数据上的损失函数,这样每一轮参数更新的速度大大加快了,但是它存在的问题也十分明显,在某一条数据上损失函数更小并不代表在全部数据上损失函数更小,于是使用随机梯度下降优化得到的神经网络甚至可能无法达到局部最优解。
2.反向传播(BP)算法(复合函数的链式法则):
而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
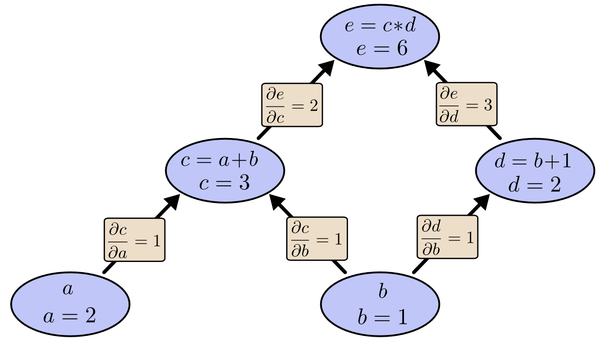
比较:
(即梯度)的计算方式上。
为了综合梯度下降算法和随机梯度下降算法,在实际应用中一般采用两个算法的折中------每次计算一小部分训练数据的损失函数。这一小部分称之为一个batch 。通过矩阵运算,每次在一个batch上优化神经网络的参数并不会比单个数据慢太多。另一方面,每次使用一个batch可以大大减少收敛所需要的迭代次数,同时可以使收敛到的结果更加接近梯度下降的效果。
学习率:定义每次参数更新的幅度
学习率设置过大,难以找到最优解,学习率设置过小,会增加迭代次数,极大提高了运算的时间。tensorflow设置了一种更加灵活的学习率设置方法------指数衰减法。
tf.train.exponential_dacay 函数实现了指数衰减学习率。它先用较大的学习率快速得到一个最优解,然后随着迭代继续逐步减小学习率,使得模型训练后期更加稳定。 exponential_dacay 会指数级地减小学习率。
dacayed_learning_rate =
learning_rate * dacay_rate ^(global_step /dacay_steps)
代码:learning_rate = tf.train.exponential_dacay(learning_rate,global_step,dacay_steps,dacay_rate,staircase=True)
dacayed_learning_rate:每一轮的学习率
learning_rate:事先设置好的学习率
dacay_rate:衰减速度
global_step:总训练样本数
dacay_steps:完整地使用一遍训练数据所需要的迭代次数
注:可以通过设置staircase的值为True,global_step / dacay_step会被转化为整数,使得学习率成为一个阶梯函数。
过拟合:当一个模型过为复杂之后,它可以很好地“记忆” 每一个训练数据中随机噪音的部分而忘记了要去“学习” 训练数据中通用的趋势。
注:过拟合虽然可以对以往的图片得到非常小的损失函数,但是对于未知数据可能无法做出可靠的判断,我们需要的是整体的规律
防止过拟合:正则化(regularization),就是在损失函数中加入刻画模型复杂的指标。加入损失函数是j(a),我们要优化j(a)+vR(w) 其中 R(w)刻画的是模型的复杂程度。而v表示模型复杂损失在总损失中的比例,a表示一个神经网络中所有的参数(它包括边上的权重w和偏置b)。一般来说模型的复杂度只由权重w决定。