MNIST数据集包含了70000张0~9的手写数字图像。
一、准备工作:导入MNIST数据集
1 import sys 2 assert sys.version_info >= (3, 5) 3 4 import sklearn 5 assert sklearn.__version__ >= "0.20" 6 7 import numpy as np 8 import os 9 10 from sklearn.datasets import fetch_openml 11 12 mnist = fetch_openml('mnist_784', version=1) #加载数据集
fatch_openml用来加载数据集,所加载的数据集是一个key-value的字典结构
输入:mnist.keys()
可以看到字典的键值包括:dict_keys(['data', 'target', 'frame', 'categories', 'feature_names', 'target_names', 'DESCR', 'details', 'url'])
其中'data'键包含一个数组:实例为行,特征为列;'target'键包含一个带有标记数组。
为了更好的展示'data'和'target'执行下列语句:
X, y = mnist["data"], mnist["target"]
print(X.shape) #data 中有7w张图即实列为7w,图像由28*28大小的像素组成即特征为784
print(y.shape) #y为标签,y[i]显示x[i]对应的数字
输出:
(70000, 784) (70000,)
现在我们观察数据集中的第一个元素:
在这之前我们先准备图像打印的相关参数:
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
mpl.rc('axes', labelsize=14)
mpl.rc('xtick', labelsize=12)
mpl.rc('ytick', labelsize=12)
现在我们尝试将数据集中第一个元素的图像打印出来,执行下列语句:
some_digit = X[0] #抓取X的第一行
some_digit_image = some_digit.reshape(28, 28) #将特征向量重新排序为28*28的像素矩阵
plt.imshow(some_digit_image, cmap=mpl.cm.binary) #imshow函数用于显示图像 cmap为颜色设置
plt.axis("off") #不显示坐标轴
plt.show()
输出:

二、使用KNN分类器在MNIST数据集上进行分类首先需要将原始数据集进行切片操作:我们将原始数据集的前60000个元素用于对分类器的训练,后10000个元素用于对分类器分类效果的检验
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]
接下来我们导入KNN分类器,并用训练数据集对分类器进行训练,这里我们设定的KNN中的K=4
from sklearn.neighbors import KNeighborsClassifier knn_clf = KNeighborsClassifier(weights='distance', n_neighbors=4) knn_clf.fit(X_train, y_train) #使用指定的训练数据集进行训练 y_knn_pred = knn_clf.predict(X_test) #用训练好的分类器对测试数据集进行分类预测
值得一提的是KNeighborsClassifier()中可以通过增加n_jobs参数来指定设定工作的core数量,n_jobs=-1时使用全部core。
训练好的分类器对测试数据集的预测结果存储在y_knn_pred中,y_knn_pred[i]代表分类器认为的X_test[i]所对应的数字。y_knn_pred是一个序列,其中的元素类型为字符
通过执行语句:
print(y_knn_pred)
输出:
['7' '2' '1' ... '4' '5' '6']
三、评判分类器的性能我们可以通过混淆矩阵来判断一个分类器的性能。
通过confusion_matrix()函数我们可以很容易的获取混淆矩阵,例如执行以下代码:
from sklearn.metrics import confusion_matrix
print(confusion_matrix(y_test, y_knn_pred))
则输出:
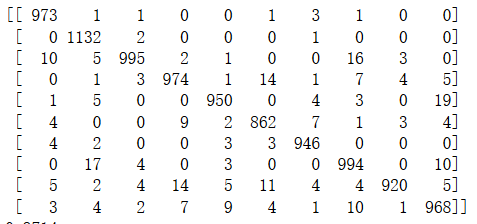
通过混淆矩阵可以知道分类器将某两个数字混淆的次数,例如matrix[0,1]=1,就表示分类器将数字0和数字1混淆了1次。
另一方面,混淆矩阵的行表示【实际类别】,列表示【预测类别】,很直观的可以将预测结果分为以下四类:
TP:真正类
FP:假正类
TN:真负类
FN:假负类
假如说现在的目标是选取数字【5】,则对预测结果的划分如下图所示:
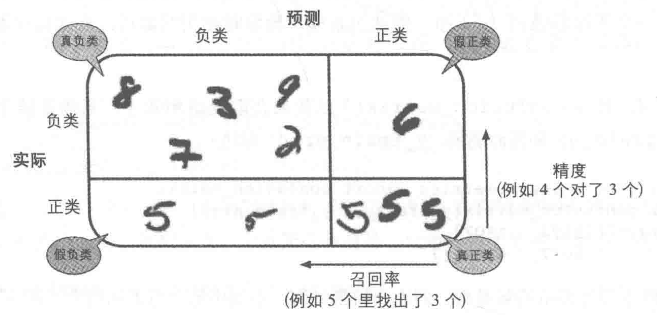
公式:精度=(TP/(TP+FP))
公式:召回率=(TP/(TP+FN))
执行下列代码,可以查看一个分类器的精度和召回率:
from sklearn.metrics import recall_score,precision_score print(recall_score(y_test, y_knn_pred, average=None)) print(precision_score(y_test,y_knn_pred, average=None)) """输出为: [0.99285714 0.99735683 0.96414729 0.96435644 0.96741344 0.96636771 0.9874739 0.96692607 0.94455852 0.95936571] [0.973 0.96834902 0.98417409 0.96819085 0.97535934 0.96312849 0.97828335 0.95945946 0.98818475 0.95746785]"""
另一个显而易见的问题是如何平衡精度与召回率,这个问题实际上还是蛮复杂的,我会单独写一篇博客探讨。