当服务器不多,并且不考虑扩容的时候,可直接使用简单的路由算法,用服务器数除缓存数据KEY的hash值,余数作为服务器下标即可。
但是当业务发展,网站缓存服务需要扩容时就会出现问题,比如3台缓存服务器要扩容到4台,就会导致75%的数据无法命中,当100台服务器中增加一台,不命中率会到达99%(n/(n+1)),这显然是不能接受的。
在设计分布式缓存集群的时候,需要考虑集群的伸缩性,也就是当向集群中增加服务器的时候,要尽量减小对集群的影响,而一致性hash算法就是用来解决集群伸缩性。
一致性hash算法通过构造一个长度为2^32的整数环,根据节点名的hash值将缓存服务器节点放置在这个环上,然后计算要缓存的数据的key的hash值,顺时针找到最近的服务器节点,将数据放到该服务器上。
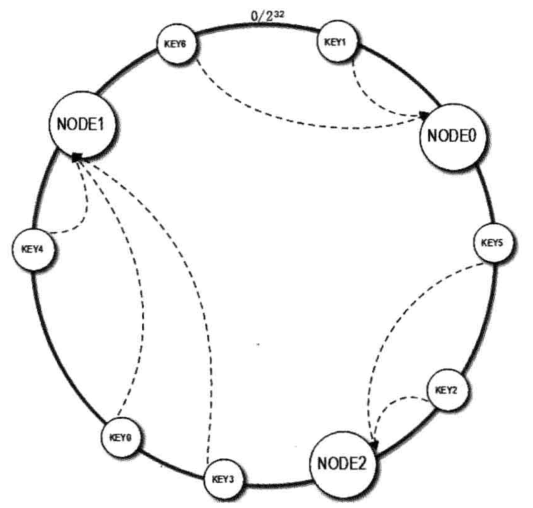
有Node0,Node1,Node2三个节点,假设Node0的hash值是1024,key1的hash值是500,key1在环上顺时针查找,最近的节点就是Node0。
当服务器集群又开始扩容,新增了Node3节点,从三个节点扩容到了四个节点。
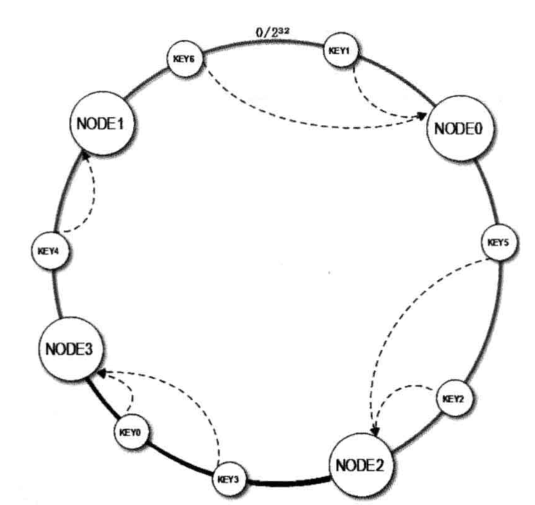
Node3加到了Node2和Node1之间,除了Node2到Node3之间原本是Node1的数据无法再命中,其它的数据不受影响,3台扩容到4台可命中率高达75%,
而且集群越大,影响越小,100台服务器增加一台,命中率可达到99%。
查找不小于查找树的最小值是用的二叉查找树实现的。
但是这样子还是会存在一个问题,就是负载不均衡的问题,当Node3加到Node2和Node1之间时,原本会访问Node1的缓存数据有50%的概率会缓存到Node3上了,这样Node0和Node2的负载会是Node1和Node3的两倍。
要解决一致性hash算法带来的负载不均衡问题,可通过将每台物理服务器虚拟成一组虚拟缓存服务器,将虚拟服务器的hash值放置在hash环上,KEY在环上先找到虚拟服务器节点,然后再映射到实际的服务器上。

这样在Node0,1,2虚拟节点都已存在的情况下,将Node3的多个虚拟节点分散到它们中间,多个虚拟的Node3节点会影响到其它的多个虚拟节点,而不是只影响其中一个,这样将命中率不会有变化,但是负载却更加均衡了而且虚拟节点越多越均衡。