MySQL集群之MyCat
一、MyCat简介及分析
数据库中间件
1.1 MyCat是什么?
mycat就是一个数据库中间件,数据库的代理,它屏蔽了物理数据库,应用连接mycat,然后mycat再连接物理数据库
它支持水平拆分(分库分表,通过分库达到分表),支持多种分片规则,比如范围切片、自然月分片、hash取模分片等。
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
——————来源于官网MyCat官网
1.2 关键特性及应用场景
1.2.1 关键特性
- 支持SQL92标准
- 支持MySQL、Oracle、DB2、SQL Server、PostgreSQL等DB的常见SQL语法
- 遵守Mysql原生协议,跨语言,跨平台,跨数据库的通用中间件代理。
- 基于心跳的自动故障切换,支持读写分离,支持MySQL主从,以及galera cluster集群。
- 支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数,支持跨库分页。
- 支持单库内部任意join,支持跨库2表join,甚至基于caltlet的多表join。
- 支持通过全局表,ER关系的分片策略,实现了高效的多表join查询。
- 支持多租户方案。
- 支持分布式事务(弱xa)。
1.2.2 应用场景
- 单纯的读写分离,此时配置最为简单,支持读写分离,主从切换;
- 分表分库,对于超过1000万的表进行分片,最大支持1000亿的单表分片;
- 多租户应用,每个应用一个库,但应用程序只连接Mycat,从而不改造程序本身,实现多租户化;
- 报表系统,借助于Mycat的分表能力,处理大规模报表的统计;
- 替代Hbase,分析大数据;
1.2.3 MyCat不适合的应用场景
- 设计使用Mycat时有非分片字段查询,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时有分页排序,请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果要进行表JOIN操作,要确保两个表的关联字段具有相同的数据分布,否则请慎重使用Mycat,可以考虑放弃!
- 设计使用Mycat时如果有分布式事务,得先看是否得保证事务得强一致性,否则请慎重使用Mycat,可以考虑放弃!
需要注意: 在生产环境中, Mycat节点最好使用双节点, 即双机热备环境, 防止Mycat这一层出现单点故障. 可以使用的高可用集群方式有: Keepalived+Mycat+Mysql, Keepalived+LVS+Mycat+Mysql, Keepalived+Haproxy+Mycat+Mysql
1.3 MyCat监控及分片策略
1.3.1 Mycat的监控体系
- 支持对Mycat、Mysql性能监控
- 支持对Mycat的JVM内存提供监控服务
- 支持对线程的监控
- 支持对操作系统的CPU、内存、磁盘、网络的监控
1.3.2 MyCat的分片策略
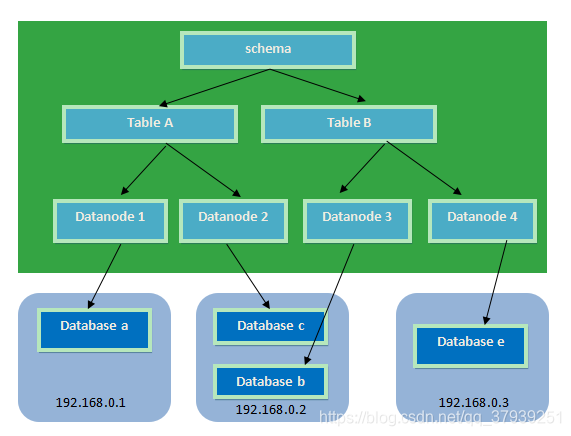
- 逻辑库(schema) :
数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
- 逻辑表(table):
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。
分片表:是指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。 总而言之就是需要进行分片的表。
非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
- 分片节点(dataNode):
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
- 节点主机(dataHost)
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
- 分片规则(rule):
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
1.4 Mycat读写分离与主从复制
1.4.1 Mycat读写分离
对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个读节点的配置。

Mycat读写分离和自动切换机制,需要mysql的主从复制机制配合。
1.4.2 Mysql的主从复制

主从配置需要注意的地方
1、主DB server和从DB server数据库的版本一致
2、主DB server和从DB server数据库数据名称一致
3、主DB server开启二进制日志,主DB server和从DB server的server_id都必须唯一
1.5 Mycat的主要作用及其工作原理
1.5.1 Mycat的主要作用
作为分布式数据库中间层使用(关系型与菲关系型均可)。
1.5.2 MyCat的工作原理
Mycat的原理中最重要的一个动词是“拦截”,它拦截了用户发送过来的SQL语句,首先对SQL语句做了一些特定的分析:如分
片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL发往后端的真实数据库,并将返回的结果做适当的处理,最终再返回给用户。
上述图片里,Orders表被分为三个分片datanode(简称dn),这三个分片是分布在两台MySQL Server上(DataHost),即datanode=database@datahost方式,因此你可以用一台到N台服务器来分片,分片规则为(sharding rule)典型的字符串枚举分片规则,一个规则的定义是分片字段(sharding column)+分片函数(rule function),这里的分片字段为prov而分片函数为字符串枚举方式。
当Mycat收到一个SQL时,会先解析这个SQL,查找涉及到的表,然后看此表的定义,如果有分片规则,则获取到SQL里分片字段的值,并匹配分片函数,得到该SQL对应的分片列表,然后将SQL发往这些分片去执行,最后收集和处理所有分片返回的结果数据,并输出到客户端。以select * from Orders where prov=?语句为例,查到prov=wuhan,按照分片函数,wuhan返回dn1,于是SQL就发给了MySQL1,去取DB1上的查询结果,并返回给用户。
如果上述SQL改为select * from Orders where prov in (‘wuhan’,‘beijing’),那么,SQL就会发给MySQL1与MySQL2去执行,然后结果集合并后输出给用户。
二、MyCat配置
Mycat的配置文件都在conf目录里面,介绍几个常用的文件:
| 文件 | 说明 |
|---|---|
| server.xml | Mycat的配置文件,设置账号,参数等 |
| schema.xml | Mycat对应的物理数据库和数据库表的配置 |
| rule.xml | Mycat分片(分库分表)规则 |
Mycat的架构,Mycat是代理,Mycat后面就是物理数据库。和Web服务器的Nginx类似。
对于使用者来说,访问的都是Mycat,不会接触到后端的数据库。