(一)编程实现以下功能,并利用 Hadoop 提供的 Shell 命令完成相同任务:
(1)向 HDFS 中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,则由用户来
指定是追加到原有文件末尾还是覆盖原有的文件;


(2)从 HDFS 中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载
的文件重命名;

(3)将 HDFS 中指定文件的内容输出到终端中;

(4)显示 HDFS 中指定的文件的读写权限、大小、创建时间、路径等信息;

(5)给定 HDFS 中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、
路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;

(6)提供一个 HDFS 内的文件的路径,对该文件进行创建和删除操作。如果文件所在目
录不存在,则自动创建目录;

(7)提供一个 HDFS 的目录的路径,对该目录进行创建和删除操作。创建目录时,如果
目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目
录不为空时是否还删除该目录;

(8)向 HDFS 中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
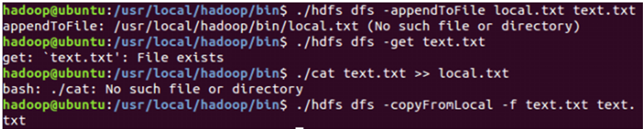
(9)删除 HDFS 中指定的文件;

(10)在 HDFS 中,将文件从源路径移动到目的路径。

(二)编程实现一个类"MyFSDataInputStream",该类继承"org.apache.hadoop.fs.FSDataInputStream",要求如下:实现按行读取 HDFS 中指定文件的方法"readLine()",如果读到文件末尾,则返回空,否则返回文件一行的文本。
public void cat() throws Exception {
FSDataInputStream fin = fileSystem.open(newPath("/hdfsapi/test/hdfstest2.txt"));
BufferedReader in = new BufferedReader(new InputStreamReader(fin, "UTF-8"));
System.out.println(in.readLine());
in.close();
}
(三)查看 Java 帮助手册或其它资料,用"java.net.URL"和"org.apache.hadoop.fs.FsURLStreamHandlerFactory"编程完成输出 HDFS 中指定文件的文本到终端中。
package cn.edu.zucc.hdfs;
import java.io.IOException;
import java.io.InputStream;
import java.net.URL;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.io.IOUtils;
public class FsUrl {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void cat(String remoteFilePath) {
try (InputStream in = new URL("hdfs", "localhost", 9000, remoteFilePath)
.openStream()) {
IOUtils.copyBytes(in, System.out, 4096, false);
IOUtils.closeStream(in);
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* 主函数
*/
public static void main(String[] args) {
String remoteFilePath = "/user/tiny/text.txt"; // HDFS路径
try {
System.out.println("读取文件: " + remoteFilePath);
FsUrl.cat(remoteFilePath);
System.out.println(" 读取完成");
} catch (Exception e) {
e.printStackTrace();
}
}
}