排序在很多业务场景都要用到,今天本文介绍如何借助于自定义Partition类实现hadoop部分排序。本文还是使用java和python实现排序代码。
1、部分排序。
部分排序就是在每个文件中都是有序的,和其他文件没有关系,其实很多业务场景就需要到部分排序,而不需要全局排序。例如,有个水果电商网站,要对每个月的水果的销量进行排序,我们可以把reduce进程之后的文件分成12份,对应1到12月份。每个文件按照水果的销量从高到底排序,1月份的排序和其他月份的排序没有任何关系。
原始数据如下,有三个字段,第一个字段是水果名称,第二个字段是销售月份,第三个字段是销售量,
Apple 201701 20
Pear 201701 30
Banana 201701 40
Orange 201701 90
Apple 201702 50
Pear 201702 60
Banana 201702 20
Orange 201702 10
Apple 201703 230
Pear 201703 302
Banana 201703 140
Orange 201703 290
Apple 201704 30
Pear 201704 102
Banana 201704 240
Orange 201704 190
经过部分排序后会生成12个文件,内容如下,销量按照从高到低排序
Pear 302
Orange 290
Apple 230
Banana 140
实现思路:
1、自定义Partition类,因为一年有12个月 ,因此需要12个分区,同时在MapReduce入口类中要指定Partition类,以及partition的数量。
2、在map函数中将年月作为key值,value变为“Apple_20”的格式。
3、在reduce函数中比较每种水果的销量,按照从高到低排序。
Java代码如下,Map类:
1 public class PartSortMap extends Mapper<LongWritable,Text,Text,Text> { 2 3 public void map(LongWritable key,Text value,Context context)throws IOException,InterruptedException{ 4 String line = value.toString();//读取一行数据,数据格式为“Apple 201701 30” 5 String str[] = line.split(" ");// 6 //年月当做key值,因为要根据key值设置分区,而Apple+“_”+销量当做value 7 context.write(new Text(str[1]),new Text(str[0] + "_" + str[2])); 8 } 9 }
自定义Partition类:
1 public class PartParttition extends Partitioner<Text, Text> { 2 public int getPartition(Text arg0, Text arg1, int arg2) { 3 String key = arg0.toString(); 4 int month = Integer.parseInt(key.substring(4, key.length())); 5 if (month == 1) { 6 return 1 % arg2; 7 } else if (month == 2) { 8 return 2 % arg2; 9 } else if (month == 3) { 10 return 3 % arg2; 11 }else if (month == 4) { 12 return 4 % arg2; 13 }else if (month == 5) { 14 return 5 % arg2; 15 }else if (month == 6) { 16 return 6 % arg2; 17 }else if (month == 7) { 18 return 7 % arg2; 19 }else if (month == 8) { 20 return 8 % arg2; 21 }else if (month == 9) { 22 return 9 % arg2; 23 }else if (month == 10) { 24 return 10 % arg2; 25 }else if (month == 11) { 26 return 11 % arg2; 27 }else if (month == 12) { 28 return 12 % arg2; 29 } 30 return 0; 31 } 32 }
Reduce类:
1 public class PartSortReduce extends Reducer<Text,Text,Text,Text> { 2 class FruitSales implements Comparable<FruitSales>{ 3 private String name;//水果名字 4 private double sales;//水果销量 5 public void setName(String name){ 6 this.name = name; 7 } 8 9 public String getName(){ 10 return this.name; 11 } 12 public void setSales(double sales){ 13 this.sales = sales; 14 } 15 16 public double getSales() { 17 return this.sales; 18 } 19 20 @Override 21 public int compareTo(FruitSales o) { 22 if(this.getSales() > o.getSales()){ 23 return -1; 24 }else if(this.getSales() == o.getSales()){ 25 return 0; 26 }else { 27 return 1; 28 } 29 } 30 } 31 32 public void reduce(Text key, Iterable<Text> values,Context context)throws IOException,InterruptedException{ 33 List<FruitSales> fruitList = new ArrayList<FruitSales>(); 34 35 for(Text value: values) { 36 String[] str = value.toString().split("_"); 37 FruitSales f = new FruitSales(); 38 f.setName(str[0]); 39 f.setSales(Double.parseDouble(str[1])); 40 fruitList.add(f); 41 } 42 Collections.sort(fruitList); 43 44 for(FruitSales f : fruitList){ 45 context.write(new Text(f.getName()),new Text(String.valueOf(f.getSales()))); 46 } 47 } 48 }
入口类:
1 public class PartSortMain { 2 public static void main(String[] args)throws Exception{ 3 Configuration conf = new Configuration(); 4 //获取运行时输入的参数,一般是通过shell脚本文件传进来。 5 String [] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs(); 6 if(otherArgs.length < 2){ 7 System.err.println("必须输入读取文件路径和输出路径"); 8 System.exit(2); 9 } 10 Job job = new Job(); 11 job.setJarByClass(PartSortMain.class); 12 job.setJobName("PartSort app"); 13 14 //设置读取文件的路径,都是从HDFS中读取。读取文件路径从脚本文件中传进来 15 FileInputFormat.addInputPath(job,new Path(args[0])); 16 17 //设置mapreduce程序的输出路径,MapReduce的结果都是输入到文件中 18 FileOutputFormat.setOutputPath(job,new Path(args[1])); 19 20 21 job.setPartitionerClass(PartParttition.class);//设置自定义partition类 22 job.setNumReduceTasks(12);//设置为partiton数量 23 //设置实现了map函数的类 24 job.setMapperClass(PartSortMap.class); 25 26 //设置实现了reduce函数的类 27 job.setReducerClass(PartSortReduce.class); 28 29 //设置reduce函数的key值 30 job.setOutputKeyClass(Text.class); 31 //设置reduce函数的value值 32 job.setOutputValueClass(Text.class); 33 34 System.exit(job.waitForCompletion(true) ? 0 :1); 35 } 36 }
运行后会在hdfs中生成12个文件,如下图所示:
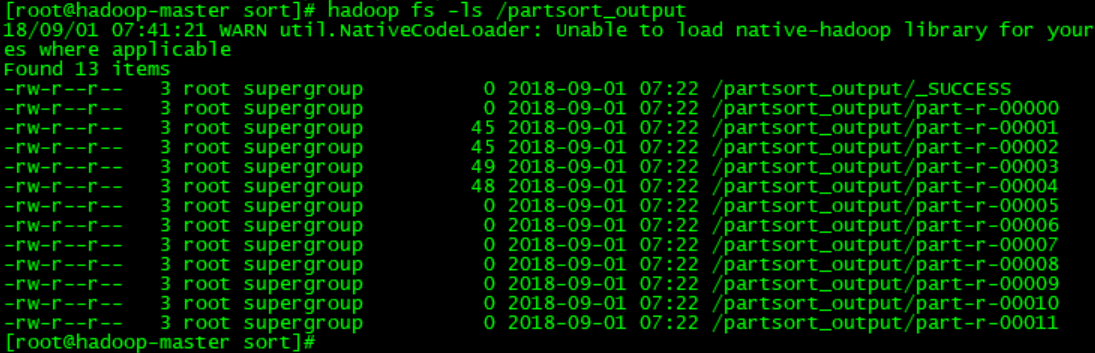
查看其中的一个文件会看到如下的内容:

可以看到是按照销量从高到低排序。
使用Python实现部分排序。
Python使用streaming的方式实现MapReduce,和Java方式不一样,不能自定义Partition,但是可以在脚本文件中指定哪个字段用作partition,哪个字段用于排序。
下图显示数据经过部分排序之后,数据变化的过程。即原始数据,经过map函数,然后到reduce函数,最终在每个文件中按照销量从高到底排序的过程:
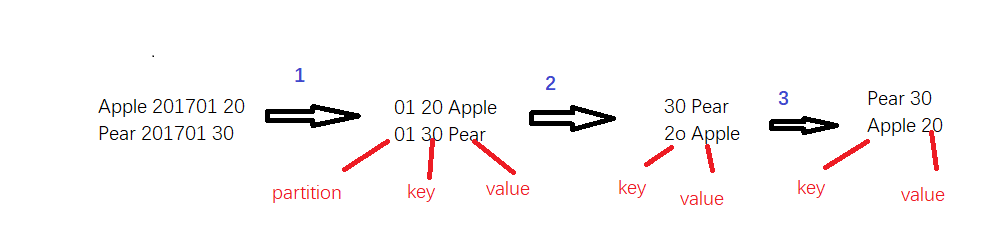
上图中的第一步是在map函数中将原始数据的第二列的“年月”转换成“月”,当做partition,将销量当做key,水果名当做value。第二步是经过MapReduce的排序之后到达Reduce函数之间的结果。第三步是在reduce函数中将map输入的数据中将key当做reduce的value,将value当做reduce的key。
代码如下:
map_sort.py
1 #!/usr/bin/python 2 import sys 3 base_numer = 99999 4 for line in sys.stdin: 5 ss = line.strip().split(' ') 6 fruit = ss[0] 7 yearmm = ss[1] 8 sales = ss[2] 9 new_key = base_number - int(sales) 10 mm = yearmm[4:6] 11 print "%s %s %s" % (int(mm), int(new_key), fruit)
reduce_sort.py
1 #!/usr/bin/python 2 import sys 3 base_number = 99999 4 for line in sys.stdin: 5 idx_id, sales, fruit = line.strip().split(' ') 6 new_key = base_number - int(sales) 7 print ' '.join([val, str(new_key)])
执行脚本如下:
run.sh
1 set -e -x 2 HADOOP_CMD="/usr/local/src/hadoop-2.6.1/bin/hadoop" 3 STREAM_JAR_PATH="/usr/local/src/hadoop-2.6.1/share/hadoop/tools/lib/hadoop-streaming-2.6.1.jar" 4 INPUT_FILE_PATH_A="/data/fruit.txt" 5 OUTPUT_SORT_PATH="/output_sort" 6 $HADOOP_CMD fs -rmr -skipTrash $OUTPUT_SORT_PATH 7 $HADOOP_CMD jar $STREAM_JAR_PATH 8 -input $INPUT_FILE_PATH_A 9 -output $OUTPUT_SORT_PATH 10 -mapper "python map_sort.py" 11 -reducer "python reduce_sort.py" 12 -file ./map_sort.py 13 -file ./red_sort.py 14 -jobconf mapred.reduce.tasks=12 15 -jobconf stream.num.map.output.key.fields=2 16 -jobconf num.key.fields.for.partition=1 17 -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner
-jobconf stream.num.map.output.key.fields=2 这行代码用于指定排序的字段,数字2指定map函数输出数据的第几列用于排序,就是例子中的sales字段。
-jobconf num.key.fields.for.partition=1这行代码指定partition字段,数字1指定map函数输出数据的第一列用于分区。
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner这行代码是调用hadoop streaming包中的分区类,实现分区功能。
实现streaming partition功能时这三行代码必不可少。
总结:
实现hadoop部分排序主要是通过partition方式实现。
java语言使用自定义分区Partition类实现分区的功能,而streaming是通过KeyFieldBasedPartitioner类,然后在脚本文件中指定partition类的方式实现。