概述
任务并行库(TPL TaskParallel Library)提供了数据流组件,以帮助提高启用并发的应用程序的健壮性。 这些数据流组件统称为TPL数据流库。该数据流模型通过为粗粒度数据流和流水线任务提供进程内消息传递来促进基于参与者的编程。数据流组件基于TPL的类型和调度基础结构,并与C#,Visual Basic和F#语言支持集成在一起,以进行异步编程。
https://docs.microsoft.com/zh-cn/dotnet/standard/parallel-programming/dataflow-task-parallel-library
一个具体的场景
在处理数据同步的过程中,我们一般需要经过以下一系列步骤:
1、从源数据库读取数据
2、处理和转换源数据
3、将处理后的数据保存到目标数据库。
在对以上数据处理编程实现时,如果处理和转换步骤比较多,并且逻辑上跨了领域,比较好的做法是抽象一个 Data Pipeline , 对每一步做一个Handler,然后在Pipe 中组装 handler.
一个抽象管道的设计可能如下:
public class CommonDataPipeline<Tin>
{
private List<IHandler> Handlers;
private PipelineContext<Tin> context;
public CommonDataPipeline()
{
this.Handlers = new List<IHandler>();
}
public CommonDataPipeline(object param)
: this()
{
this.context = new PipelineContext<Tin>(this.Handlers, param);
}
public void AddHanlder(IHandler handler)
{
Handlers.Add(handler);
}
public virtual void Invoke()
{
context.InvokeNext();
}
public virtual async Task InvokeAsync()
{
context.InvokeNextAsync();
}
public Dictionary<string, object> Result
{
get
{
return this.context.OutputData;
}
}
}
管道上下文数据:
/// 管道上下文
public class PipelineContext<Tin>
{
private readonly IEnumerable<IHandler> handlers;
public IHandler CurrentHandler { get; set; }
public Tin InputData { get; }
public Dictionary<string, object> OutputData { get; set; }
public PipelineContext(List<IHandler> handlers, object param)
{
this.handlers = handlers;
this.InputData = (Tin)param;
this.OutputData = new Dictionary<string, object>();
}
public void InvokeNext()
{
foreach (var hanlder in this.handlers)
{
CurrentHandler = hanlder;
hanlder.Invoke(this);
}
}
public void InvokeNextAsync()
{
foreach (var handler in this.handlers)
{
Task.Run(() => handler.Invoke(this));
}
}
}
客户端对管道的调用:
//初始化管道.
var pipeline = new CommonDataPipeline<TSource>(sourceData);
// 数据抽取.
pipeline.AddHanlder(new DataExtractHandler);
// 数据装载处理 .
pipeline.AddHanlder(new DataLoadHandler);
// 发消息处理.
pipeline.AddHanlder(new DataPublishHandler);
pipeline.Invoke();
以上的实现,把处理逻辑分离了,抽象的管道上下文能力比较弱,并且处理器需要了解Context 的细节。
使用 TPL Dataflow Block 构建数据流处理管道
对一般数据处理过程进行一些分析,可以抽象成如下管道模型:
1、一个数据处理管道 是将一块源数据 转换或者装配成 一块目标数据
2、管道可以添加多种处理节点,上一个节点的输出是下一个节点的输入
按以上需求,可以定义出客户端调用代码(通过链式调用,提高可读性 ):
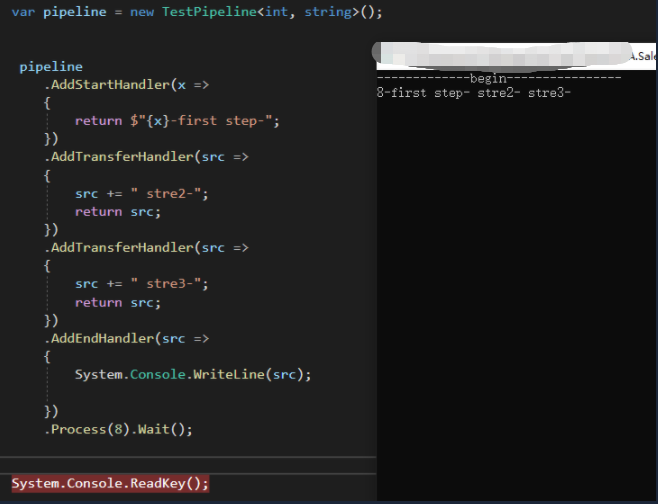
// 初始化管道
// int 是输入的数据类型
// string 是输出的数据类型
var pipeline = new TestPipeline<int, string>();
// StartHandler 表示有一个开始节点,传入一个处理函数用Func<int,string> 表示
pipeline
.AddStartHandler(x =>
{
return $"{x}-first step-";
})
// transfer 表示数据转换处理,源数据是上一个节点的输出,处理输出的是和输入的结构一样,用于作为下一个节点的输入,所以处理函数表示为 Func<string,string>
// transfer 节点可以自由添加
.AddTransferHandler(src =>
{
src += " stre2-";
return src;
})
.AddTransferHandler(src =>
{
src += " stre3-";
return src;
})
// End 节点不需要输出,只有输入
.AddEndHandler(src =>
{
System.Console.WriteLine(src);
})
.Process(8).Wait();
根据以上客户端代码,通用的管道处理模型使用 DataFlow 的 TransferBlock<> 实现如下:
public class CommonDataPipeline<TSource, TTarget>
{
private IPropagatorBlock<TSource, TTarget> _startBlock;
private List<TransformBlock<TTarget, TTarget>> _tempBlock = new List<TransformBlock<TTarget, TTarget>>();
public CommonDataPipeline<TSource, TTarget> AddStartHandler(Func<TSource, TTarget> func)
{
var actionBlock = new TransformBlock<TSource, TTarget>(func);
_startBlock = actionBlock;
return this;
}
public CommonDataPipeline<TSource, TTarget> AddTransferHandler(Func<TTarget, TTarget> func)
{
var transferBlock = new TransformBlock<TTarget, TTarget>(func);
if (_tempBlock.Any())
{
_tempBlock.Last().LinkTo(transferBlock);
_tempBlock.Add(transferBlock);
}
else
{
_tempBlock.Add(transferBlock);
_startBlock.LinkTo(transferBlock);
}
return this;
}
public CommonDataPipeline<TSource, TTarget> AddEndHandler(Action<TTarget> action)
{
if (_tempBlock == null)
{
throw new ArgumentException(" need transfer node....");
}
var actionBlock = new ActionBlock<TTarget>(action);
_tempBlock.Last().LinkTo(actionBlock);
return this;
}
public void Process(TSource source)
{
_startBlock.Post(source);
}
测试结果:
小结
TPL 的数据流块还有很多类型的块,如果我们有大量数据需要并发处理,可以使用BufferBlock 缓冲输入流,构建 一个生产者--消费者模式的管道,然以将消费者并行,提高数据处理能力。
TransferBlock 和ActionBlock 是数据流块基础,可以基于此模型构建高可用高性能的数据处理管道。