前要
飞桨首次开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。首阶段的开源套件推出了重磅模型:8.6M超轻量中英文识别模型。该超轻量模型由1个文本检测模型(4.1M,DB算法)和1个文本识别模型(4.5M,CRNN算法)组成,共8.6M。同时支持中英文识别;aistudio项目地址:https://www.paddlepaddle.org.cn/hub/scene/ocr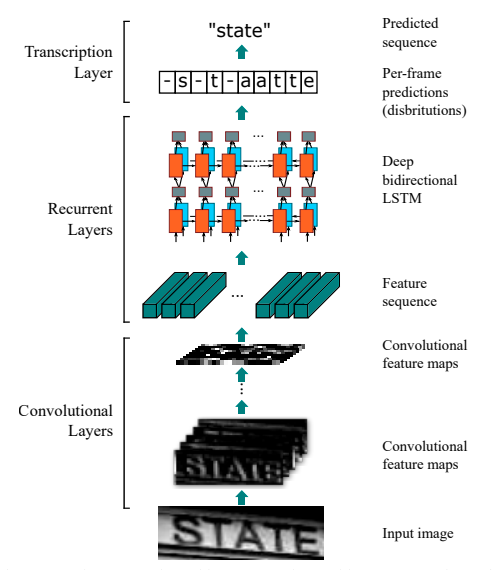
开始实验
一 安装必要库:
pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple (这个库如果使用此方法安装,在使用时可能会出现问题,如果出现问题,可以先卸载,再到http://www.lfd.uci.edu/~gohkle/pythonlibs/下载shapely库)
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv -i https://pypi.tuna.tsinghua.edu.cn/simple
二 定义预测数据
显示图片:

读取测试集文件夹:

用户只需把文件路径放到test_image.txt文件即可。
三 加载预训练模型
import paddlehub as hub
ocr = hub.Module(name="chinese_ocr_db_crnn_server") # 服务端可以加载大模型,效果更好。
#ocr = hub.Module(name="chinese_ocr_db_crnn_mobile") #移动端模型加载,速度更快。

模型概述:chinese_ocr_db_crnn_server Module用于识别图片当中的汉字。其基于chinese_text_detection_db_server检测得到的文本框,继续识别文本框中的中文文字。识别文字算法采用(Convolutional Recurrent Neural Network)即卷积递归神经网络。DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中习,不需要详细的字符级的标注。该Module是一个通用的OCR模型,支持直接预测。
四 开始预测
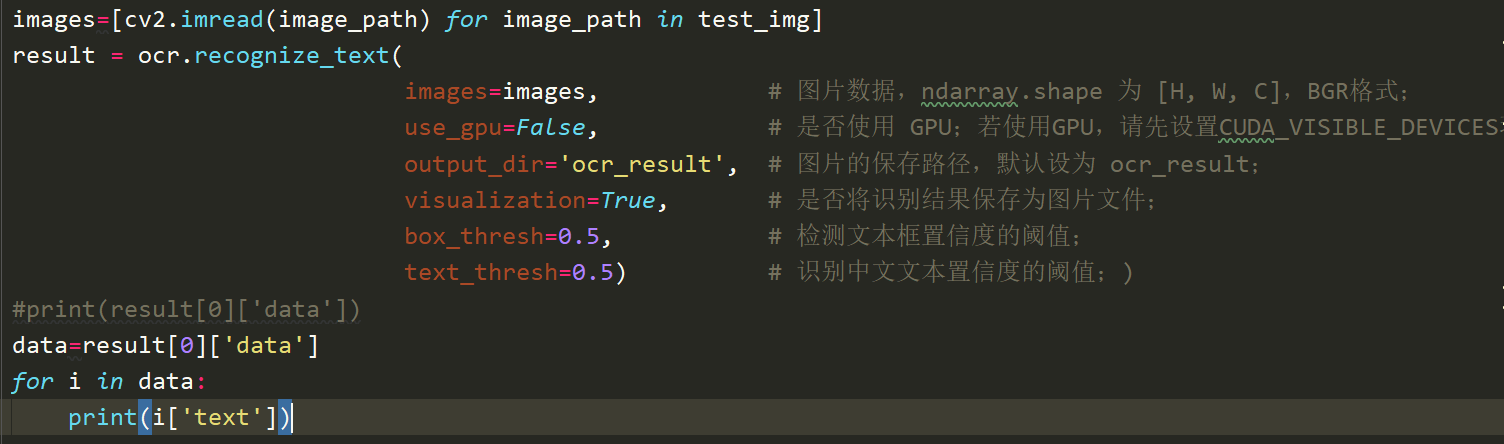
预测结果:

五 效果展示:
程序会自动将识别结果保存为图片文件,并默认保存在ocr_result文件夹中。![]()
成品一:

成品二:

成品三:

六 总结与收获
通过本次暑期实践,我学会了如何运用paddlehub做出一个作品,PaddleHub 是基于 PaddlePaddle 开发的预训练模型管理工具,可以借助预训练模型更便捷地开展迁移学习工作,旨在让 PaddlePaddle 生态下的开发者更便捷体验到大规模预训练模型的价值。
PaddleHub 目前的预训练模型覆盖了图像分类、目标检测、词法分析、Transformer、情感分析五大类别。未来会持续开放更多类型的深度学习模型,如语言模型、视频分类、图像生成等预训练模型。
我也认识到python在机器学习,深度学习中的重要性。很多框架都是由python编写的,如:tensorflow,pytorch,paddlepaddle等,所以学好python十分重要,paddlehub只是预训练的模型,对于模型的编写话要靠paddlepaddle,所以在之后的学习中我将继续学习paddle paddle与pytorch,来提高自己的编写神经网络的能力,来提高自己的学习能力与实践能力。所以路漫漫其修远兮,吾将上下而求索。