先来看看识别中文的xml是怎么写的。其实和英文的差不多,先把LANGID改成中文编号为804,且存储的时候必须使用Unicode编码。其他的和英文的区别不大。
 代码
代码

<GRAMMAR LANGID="804">
<DEFINE>
<ID NAME="VID_Counter" VAL="1"/>
<ID NAME="VID_Single" VAL="10"/>
<ID NAME="VID_Double" VAL="11"/>
<ID NAME="VID_Short" VAL="14"/>
<ID NAME="VID_Tall" VAL="15"/>
<ID NAME="VID_Mocha" VAL="25"/>
<ID NAME="VID_Cappuch" VAL="28"/>
<ID NAME="VID_Place" VAL="253"/>
<ID NAME="VID_Navigation" VAL="254"/>
<ID NAME="VID_EspressoDrinks" VAL="255"/>
<ID NAME="VID_Shots" VAL="258"/>
<ID NAME="VID_Size" VAL="261"/>
<ID NAME="VID_DrinkType" VAL="262"/>
<ID NAME="VID_OrderList" VAL="263"/>
<ID NAME="VID_Shots_PRO" VAL="500"/>
<ID NAME="VID_Size_PRO" VAL="501"/>
<ID NAME="VID_DrinkType_PRO" VAL="502"/>
<ID NAME="VID_Place_PRO" VAL="503"/>
<ID NAME="VID_Shots_PRO2" VAL="504"/>
<ID NAME="VID_Size_PRO2" VAL="505"/>
<ID NAME="VID_DrinkType_PRO2" VAL="506"/>
</DEFINE>
<RULE ID="VID_EspressoDrinks" TOPLEVEL="ACTIVE">
<O>
<L>
<P>我想吃</P>
<P>请来一份</P>
</L>
</O>
<O>一份</O>
<P MIN="1" MAX="7">
<RULEREF REFID="VID_OrderList" />
</P>
<O>please</O>
</RULE>
<RULE ID="VID_Navigation" TOPLEVEL="ACTIVE">
<O>请</O>
<P>
<L>
<P>进入</P>
<P>来吧</P>
</L>
</P>
<RULEREF REFID="VID_Place" />
</RULE>
<RULE ID="VID_Place" >
<L PROPID="VID_Place_PRO">
<P VAL="VID_Counter">商店</P>
<P VAL="VID_Counter">咖吧</P>
</L>
</RULE>
<RULE ID="VID_Shots" >
<L PROPID="VID_Shots_PRO2">
<P VAL="VID_Single">一杯</P>
<P VAL="VID_Double">两杯</P>
</L>
</RULE>
<RULE ID="VID_Size" >
<L PROPID="VID_Size_PRO2">
<P VAL="VID_Short">小杯</P>
<P VAL="VID_Tall">大杯</P>
</L>
</RULE>
<RULE ID="VID_DrinkType" >
<L PROPID="VID_DrinkType_PRO2">
<P VAL="VID_Mocha">摩卡</P>
<P VAL="VID_Cappuch">意大利面</P>
</L>
</RULE>
<RULE ID="VID_OrderList" >
<L>
<RULEREF REFID="VID_Shots" PROPID="VID_Shots_PRO"/>
<RULEREF REFID="VID_Size" PROPID="VID_Size_PRO"/>
<RULEREF REFID="VID_DrinkType" PROPID="VID_DrinkType_PRO"/>
</L>
</RULE>
</GRAMMAR>
这个xml其实给出来的另外一种解读是这样的。
树状结构如下所示
因为有两个rule的状态被设置为ACTIVE,所以应该有两棵树
第一棵树根据RULE ID为VID_Navigation的规则而定
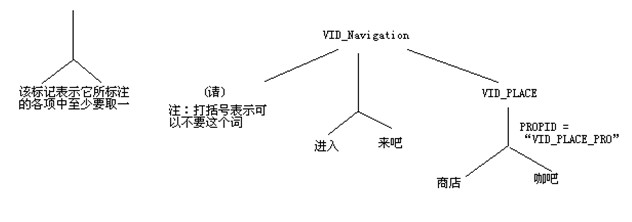
第二棵树根据RULE ID为VID_EspressoDrinks的规则而定
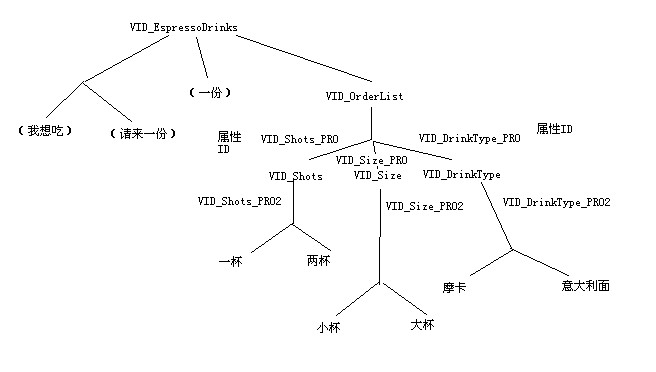
注意这些图示,然后就可以理解下面代码中的某些语句的含义了
pElements->Rule.ulId 这一句其实找到的是top-level的rule的id,就是在xml里被标记为ACTIVE的RULE的ID
pRule = pElements->Rule.pFirstChild;(在第二张图中)相当于是找到了VID_OrderList
pProp = pElements->pProperties;相当于是找到VID_OrderList下的属性VID_Shots_PRO,VID_Size_PRO, VID_DrinkTye_PRO中的一个(按照实际识别出来的单词属于那个属性而定)
pProp = pProp->pNextSibling;在上图中等于是找旁支,在逻辑上其实是过渡到下一个别识别词上
pRule = pRule->pNextSibling;在上图中等于是找旁支等于是找到下一个词所属于的rule上
简言之,第一个属性是按照树形结构查下来的第一个PROP_ID,firstchild是第一个孩子,而NextSibling是旁支。
另外,在识别之后,每一个被识别的单词都会有对应的rule和property
其实我觉得比较难以理解的是rule和property的关系。原文是这么讲的Grammar rules are elements that SAPI 5-compliant speech recognition (SR) engines use to restrict the possible word or sentence choices during the SR process. 而property也被称作semantic tags。It provides a powerful means for semantic information to be easily embedded inside a grammar.研究了老半天搞不懂。
在大致的思考之后得出了如下的猜测:
rule规定了一个句子,此句子是由一组词和/或rule组成的。最难懂的是property,也就是语义标签。我后来觉得它是不是用来提醒系统,看到了打了property的地方就是可能出现需要识别的词的地方(可能是rule也可能是某个词)。如果按照这个逻辑,那么如下代码也很好理解了。那就是要找到那个词需要用property(SPPHRASEPROPERTY),而要找到词所在的句子,或者根据句子找到所识别出来的词的位置,就需要rule(SPPHRASERULE)。
另外,有一点必须要注意的,比如说对于第二章图这个例子,即使我们在说话的时候说的是“意大利面,摩卡”,那么在识别的时候也是按照在xml里的定义顺序出来的,也就是说,得到的结果是“摩卡,意大利面”
再看看根据这些规则而写的一系列的函数实现
代码
{
SPPHRASE *pElements;
// Get the phrase elements, one of which is the rule id we specified in
// the grammar. Switch on it to figure out which command was recognized.
if (SUCCEEDED(pPhrase->GetPhrase(&pElements)))
{
switch ( pElements->Rule.ulId )
//被识别出来的词所属的top-level的rule。SPPHRASE::RULE指的是top-level rule (and rule-reference hierarchy)。我的理解就是这里获取最主要的(在xml里被定义为ACTIVE)那些RULE的id
{
case VID_EspressoDrinks:
{
ID_TEXT *pulIds = new ID_TEXT[MAX_ID_ARRAY];
// This memory will be freed when the WM_ESPRESSOORDER
// message is processed
const SPPHRASEPROPERTY *pProp = NULL;
const SPPHRASERULE *pRule = NULL;
ULONG ulFirstElement, ulCountOfElements;
int iCnt = 0;
if ( pulIds )
{
ZeroMemory( pulIds, sizeof( ID_TEXT[MAX_ID_ARRAY] ) );
//获取子一级rule的属性
pProp = pElements->pProperties;
//获取子一级的RULE,如果没有子集RULE那么就会返回NULL
pRule = pElements->Rule.pFirstChild;
// Fill in an array with the drink properties received
while ( pProp && iCnt < MAX_ID_ARRAY )
{
// Fill out a structure with all the property ids received as well
// as their corresponding text
//SPPHRASEPROPERTY::ulFirstElement 指的是The first spoken element spanned by this property.
pulIds[iCnt].ulId = static_cast< ULONG >(pProp->pFirstChild->vValue.ulVal);
// Get the count of elements from the rule ref, not the actual leaf
// property
if ( pRule )
{
//取得所识别出来的单词在整个语句中的位置,0为第一个单词
// SPPHRASERULE::ulFirstElement指的是The index of the first spoken element (word) of this rule.
ulFirstElement = pRule->ulFirstElement;
// SPPHRASERULE::ulCountOfElements指的是Number of spoken elements (words) spanned by this rule.
ulCountOfElements = pRule->ulCountOfElements;
}
else
{
ulFirstElement = 0;
ulCountOfElements = 0;
}
// This is the text corresponding to property iCnt - it must be
// released when we are done with it
// 获取识别出来那个词的文本
pPhrase->GetText( ulFirstElement, ulCountOfElements,
FALSE, &(pulIds[iCnt].pwstrCoMemText), NULL);
//我的理解是接下去要做的事情就是检查同根的旁支
// Loop through all properties
pProp = pProp->pNextSibling;
// Loop through rulerefs corresponding to properties
if ( pRule )
{
pRule = pRule->pNextSibling;
}
iCnt++;
}
PostMessage( hWnd, WM_ESPRESSOORDER, NULL, (LPARAM) pulIds );
}
}
break;
case VID_Navigation:
{
switch( pElements->pProperties->vValue.ulVal )
{
case VID_Counter:
PostMessage( hWnd, WM_GOTOCOUNTER, NULL, NULL );
break;
}
}
break;
}
// Free the pElements memory which was allocated for us
::CoTaskMemFree(pElements);
}
}
