一、大数据的来源
1.人类活动
2.计算机
3.物理世界
二、大数据采集设备
1.科研数据
(1)大型强子对撞机
(2)射电望远镜
(3)电子显微镜
2.网络数据
我们可以利用数据中心采集网络中的数据。
三、大数据采集方法
1.科研数据
2.网络数据
爬虫(慎用)
3.系统日志
(1)Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量应用。Scribe架构如下图所示: 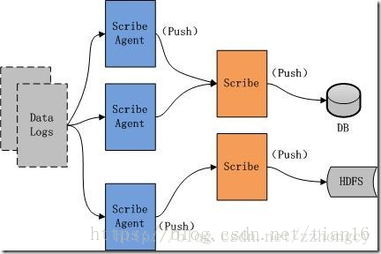
(2)Chukwa
Chukwa提供了一种对大数据量日志类数据采集、存储、分析和展示的全套解决方案和框架。Chukwa结构如下图所示: 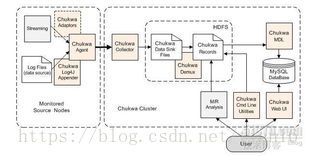
四、大数据预处理技术
1.目前存在四种主流的数据预处理技术:数据清理、数据集成、数据规约和数据变换。
2.数据处理的主要任务
(1)数据处理的主要步骤:数据清理、数据集成、数据规约和数据变换。
(2)数据清理例程通过填写缺失值、光滑噪声数据、识别或者删除离群点并且解决不一致性来“清理数据”。
(3)数据集成过程将来自多个数据源的数据集成到一起。
(4)数据规约的目的是得到数据集的简化表示。数据规约包括维规约和数值规约。
(5)数据变换使用规范化、数据离散化和概念分层等方法使得数据的挖掘可以在多个抽象层上进行。数据变换操作是引导数据挖掘过程成功的附加预处理过程。
3.数据清理
(1)缺失值
对于缺失值的处理一般是想法设法把它补上,或者干脆弃之不用。一般处理方法有:忽略元组、人工填写缺失值、使用一个全局变量填充缺失值、使用属性的中心度量填充缺失值、使用与给定元组属同一类的所有样本的属性均值或中位数、使用最可能的值填充缺失值
(2)噪声数据
噪声是被测量变量的随机误差或方差。去除噪声、使数据“光滑”的技术:分箱、回归、离群点分析
(3)数据清理的过程
数据清理过程主要包括数据预处理、确定清理方法、校验清理方法、执行清理工具和数据归档。
数据清理的原理是通过分析“脏数据”产生的原因和存在形式,利用现有的技术手段和方法去清理“脏数据”,将“脏数据”转化为满足数据质量或应用要求的数据,从而提高数据集的数据质量。
数据分析主要有两种方法:数据派生和数据挖掘。
五、数据集成
1.实体识别
2.冗余和相关分析
冗余是数据集成的另一个重要问题。有些冗余是可以被相关分析检测到的,例如,数值属性,可以使用相关系数和协方差来评估一个属性随着另一个属性的变化。
3.数据冲突的检测与处理
六、数据变换与数据离散化(重点)
1.数据变换的常用方法
(1)中心化变换。中心化变换是一种坐标轴平移处理方法。
(2)极差规格化变换。规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,且二者的差称为极差。
(3)标准化变换。标准化变换是对变量的数值和量纲进行类似于规格化变换的一种数据处理方法。
(4)对数变换。对数变换是将各个原始数据取对数,将原始数据的对数值作为变换后的新值。对数变换的用途:使服从对数正态分布的资料正态化;将方差进行标准化;使曲线直线化,常用于曲线拟合。
2.数据离散化
数据离散化的目的:
(1)算法需要。例如,决策树和朴素贝叶斯本身不能直接使用连续型变量
(2)离散化可以有效克服数据中隐藏的缺陷,使模型结果更加稳定。
(3)有利于对非线性关系进行诊断和描述。
数据离散化的原则:
(1)等距
等距可以保持数据原有的分布,段落越多对数据原貌保持得越好。
(2)等频
等频处理则把数据变换成均匀分布,但其各段内观察值相同这一点是等距分割做不到的。
(3)优化离散
需要把自变量和目标变量联系起来考察。切分点是导致目标变量出现明显变化的折点。常用的检验指标有信息增益、基尼指数或WOE(要求目标变量是两元变量)。
数据离散化方法:
聚类
决策树
相关分析(ChiMerge)