1.HBase(NoSQL:不是关系型数据库)的逻辑数据模型
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协调工具。

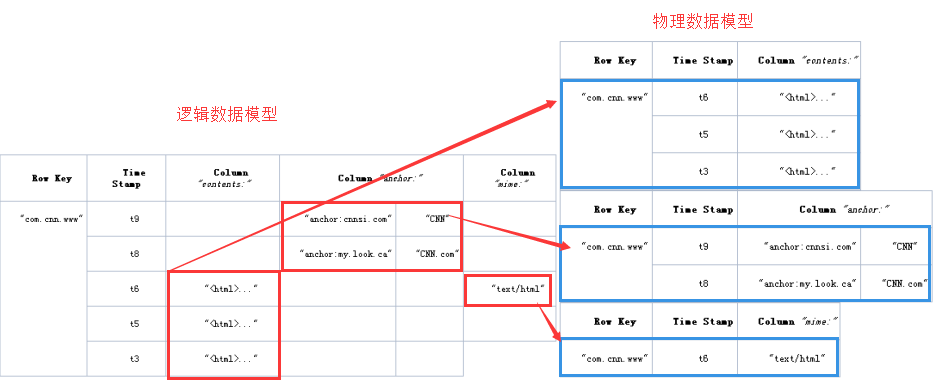
1.1 表(table),是存储管理数据的。
1.2 行键(row key),类似于MySQL中的主键。
行键是HBase表天然自带的。
1.3 列族(column family),列的集合。
HBase中列族是需要在定义表时指定的,列是在插入记录时动态增加的。
HBase表中的数据,每个列族单独一个文件。
1.4 时间戳(timestamp),列(也称作标签、修饰符)的一个属性。
行键和列确定的单元格,可以存储多个数据,每个数据含有时间戳属性,数据具有版本特性。
如果不指定时间戳或者版本,默认取最新的数据。
1.5 存储的数据都是字节数组。
1.6 表中的数据是按照行键的顺序物理存储的。
2.HBase的物理数据模型

2.1 HBase是适合海量数据(如20PB,1024T=1P)的秒级简单查询的数据库。
2.2 HBase表中的记录,按照行键进行拆分, 拆分成一个个的region。
许多个region存储在region server(单独的物理机器)中的。
这样,对表的操作转化为对多台region server的并行查询。
3.HBase的体系结构

3.1 HBase是主从式结构,HMaster、HRegionServer
Client 包含访问hbase 的接口,client 维护着一些cache 来加快对hbase 的访问,比如regione 的位置信息
Zookeeper 保证任何时候,集群中只有一个running master
存贮所有Region 的寻址入口
实时监控Region Server 的状态,将Region server 的上线和下线信息,实时通知给Master
存储Hbase 的schema,包括有哪些table,每个table 有哪些column family
Master 可以启动多个HMaster,通过Zookeeper的Master Election机制保证总有一个Master运行
为Region server 分配region
负责region server 的负载均衡
发现失效的region server 并重新分配其上的region
Region Server 维护Master 分配给它的region,处理对这些region 的IO请求
负责切分在运行过程中变得过大的region

HBase中有两张特殊的Table,-ROOT-和.META.
1、.META.:记录了用户表的Region信息,.META.可以有多个regoin
2、-ROOT-:记录了.META.表的Region信息,-ROOT-只有一个region Zookeeper中记录了-ROOT-表的location
Client访问用户数据之前需要首先访问zookeeper,然后访问-ROOT-表,接着访问.META.表,最后才能找到用户数据的位置去访问
