前言:
目录:
1.串类型的定义
2.串的表示和实现
3.串的模式匹配算法
4.串操作应用举例
正文:
串的模式匹配即,在给定主串S 中,搜索子串T 的位置,如果存在T 则返回其所在位置,否则返回 0
串的模式匹配算法
主串 S: a b c a b c d s v t
子串 T: a b c d
一、原始算法
匹配一旦失败,子串即向右移动一个单位,直到完全匹配停止。
第一次匹配:(注:红色代表不匹配(失配))
S: a b c a b c a b c d s v t
T: a b c d
第二次匹配:
S: a b c a b c d s v t
T: a
代码实现:(在 上一节已经实现的堆分配存储结构的基础 上实现)
//模式匹配(子串定位通常称为模式匹配) //求主串S 第 pos 个字符之后,与模式串 T 相等的位置 int Index(HString S,HString T,int pos){ int i=pos; int j=0; //没有到主串末尾 while(i<S.length){ if(S.ch[i]==T.ch[j]){ //如果子串已经匹配结束,那么返回主串S 中开始匹配的位置 if(j+1==T.length) return i-j+1; //否则继续往后比较 i++; j++; }else{ //存在字符不相等,i指向主串S 当前开始匹配位置的下一位。 j 在子串中重头开始 i=i-j+1; j=0; } } //匹配失败 return 0; }
运行结果:
匹配位置: 7 、比较总次数:16次
二、算法的第一次改进
第一次匹配:
下标: 0 1 2 3
S[i]: a b c a b c a b c d s v t
T[j]: a b c d
原始算法中,第一次匹配时,在i=3, j=3 时,a <> b。这时发现将 T 向右移动一个位置 和 自动两个位置都是没有必要的。这时我们在第二次匹配时,直接将子串 T 向右移动 3 个位置即可。
第二次匹配:
S: a b c a b c a b c d s v t
T: a b c d
T之所以可以向右移动 3 个位置,是因为 在 已匹配的位置 a b c 中, b c 和 a 不相等,所有串不可能匹配起来。
总结如下:
当已匹配的串中(包含n个字符)
1.除首个字符外,不存在字符和首字符相等,那么子串 T 应向右移动 n-1个位置
2.如果存在 和首字符相等的元素 Tj,那么应该把子串 T 向右移动 j 个位置
因此,一旦子串确定,我们就可以确定当子串T 中的 Tj 和主串S 中的Si 匹配失败时,子串应该移动的位置。此时,我们只需要把注意力放在子串T 上即可。
以上面子串T 为例,设step[j] 为比较到T[j] 匹配失败时,子串T 应该向右移动的位置长度。
下标j: 0 1 2 3
T[j]: a b c d
step[j]: 1 1 2 3
综上所述,只要子串T 确定, step[j] 数组就可以被确定。那么推广到一般情况,我们通过函数构造 step数组的算法如下。
//构造step数组 int *next; void InitStep(HString T){ int *step; step=(int *)malloc(T.length*sizeof(int)); if(!step) exit(OVERFLOW); step[0]=1; int equalPos=0; //记录和首字符相等的字符首次出现的位置,为0说明不存在 for(int i=1;i<T.length;i++){ if(T.ch[i]==T.ch[0]){ //记录出现位置 if(equalPos==0) equalPos=i; step[i]=i; }else{ if(equalPos==0){ step[i]=i; }else{ step[i]=equalPos; } } } next=step; }
此时,只需将 原始的模式匹配算法中 步长增1 改为 增step[j] 如下
//存在字符不相等,i指向主串S 当前开始匹配位置的下一位。 j 在子串中重头开始
i=i-j+1; (改为:i=i-j+next[j]; )
j=0;
算法即得到改进。
运行结果:
匹配位置: 7 、比较总次数:12次
当主串数据量增大时,此改进后的算法的优势会越来越明显。
三、算法的第二次改进即(KMP算法)
假设此时的主串和子串为:
S[i]: a b c r a b c a b c d s v t
T[j]: a b c r a b c d
第一次匹配:
下标: 0 1 2 3 4 5 6 7
S[i]: a b c r a b c s a b c r a b c d s v t
T[j]: a b c r a b c d
如果根据第一次改进的算法将会得到step:
下标j: 0 1 2 3 4 5 6 7
T[j]: a b c r a b c d
step[j]: 1 1 2 3 4 4 4 4
可得第一次匹配失败时,step[7]=4,那么子串T 向右移动4 个长度的位置开始第二次匹配, 从主串的第4个下标开始比较,即 S[4]=a 开始比较。
第二次匹配:
下标: 0 1 2 3 4 5 6 7
S: a b c r a b c s a b c r a b c d s v t
T: a b c r a b c d
但是我们发现:
下标4,5,6 对应的a,b,c。这三次比较也是没有必要进行的。
即第二次匹配,我们仅仅需要令 S[7]=s 和 T[3]=r 开始比较即可。
分析:
之所以可以从 子串T 的第4 个字符开始进行比较,而不需要比较前3 个字符。是因为T[0,1,2] 分别等于 S[4,5,6],又因为在第一次匹配过程中,S[7]失配的时候,已匹配字符序列为:T[0,1,2,3,4,5,6] = S[0,1,2,3,4,5,6],可知:
T[0,1,2,3,4,5,6] = S[0,1,2,3,4,5,6] 可知 T[4,5,6] = S[4,5,6]
又T[0,1,2] = S[4,5,6]
因此有:T[0,1,2] = S[4,5,6] =T[4,5,6]
在子串T 中: a b c r a b c d 中失配字符 d前面的子串sub:a b c r a b c,其前缀等于后缀(即两端相等)。
总结,在 S[i] 、T[j] 的匹配过程中,当 S[i] 不等于 T[j] 时,在已匹配的串 T[0,1,...,j-1]中 其前缀等于后缀,那么下一次匹配只需要将其前缀和 上次后缀对其即可,然后从匹配前缀的下一位置和主串继续比较,S[7]=d 和 T[3]=r进行比较。那么当前 主串下标 i=7 ,子串下标 j=3。我们设此时的子串下标为 k。
那么此时有:
T[0,1,...,k-1] = T[j-k,...,j-1] 长度为 k 且 0<k<j-1
下标: 0 1 2 3 4 5 6 7
S[i]: a b c r a b c s a b c r a b c d s v t
第一次匹配: T[j]: a b c r a b c d
第二次匹配: T[j]: a b c r a b c d
这时,我们发现,只要子串确定,我们就可以确定当 T 在 j 出失配的时候,S[i] 应该继续和下标为k 的T 继续比较。
推广到一般情况:
设当 主串S 和子串T 失配的时候,下标分别为 i 和 j。
1、当已匹配的串存在前缀 = 后缀,那么我们保持 i 不变,让S[i] 和 T[k]继续往下比较即可。
2、当已匹配的串不存在 前缀 = 后缀的情况
如果T[j] 不是T 的第一个字符,那么 S[i] 应该和 T 的第一个元素开始比较,此时 k=0
如果T[j] 是T 的第一个字符, 那么 i 后移一位,和 T的第一元素开始比较,即S[++j] 和 T[0] 开始比较,我们规定此时 k = -1
如上所述,我们设主串S[i] 和子串T[j]失配时,pos[j]=k。
此时模式匹配算法实现如下:
int KMP(HString S,HString T,int position){ int i=position; int j=0; o=0; //没有到主串末尾 while(i<S.length){ o++; if(S.ch[i]==T.ch[j]){ //如果子串已经匹配结束,那么返回主串S 中开始匹配的位置 if(j+1==T.length) return i-j+1; //否则继续往后比较 i++; j++; }else{ //i,j失配 if(pos[j]==-1){ i++; j=0; }else{ j=pos[j]; } } } //匹配失败 return 0; }
如上模式匹配算法已经实现,现在需要做的就是来实现 pos[j] 数组。
pos:
下标j: 0 1 2 3 4 5 6 7
T[j]: a b c r a b c d
pos[j]: -1 0 0 0 0 1 2 3
假设 pos[j]=k 成立,则对于已匹配部分:T[0,...,j-1] 有
如果T[j] = T[k],即T[0,...,k-1,k] = T[j-k,...,j-1,j] 那么 pos[j+1] = k+1 =pos[j] + 1
如果T[j] <> T[k]
此时可把求 pos 函数的问题看成是一个模式匹配问题,整个串及时主串又是子串,当前的匹配过程如下:
T[j-k,...,j-1], T[j]
T[0,......,k-1],T[k]
则当 T[j] <> T[k]时,即让模式串右移至 第 pos[k] 个字符和主串中的第 j 个字符相比较。
若 T[ pos[k] ] = T[j],那么 pos[j+1] = k+1 =pos[j] + 1pos[j+1]= pos[k]+1
若 T[ pos[k] ] <> T[j] ,那么如上所述以此类推,直到两者相等,或者不存在子串 前后缀相匹配 即(pos[k]=-1或0)
代码实现:
//构造pos数组 int *pos; void InitPos(HString T){ int *p; p=(int *)malloc(T.length*sizeof(int)); if(!p) exit(OVERFLOW); p[0]=-1; int i=1; int k=-1; while(i<T.length){ if(k==-1||T.ch[i-1]==T.ch[k]){ p[i]=k+1; k=p[i]; ++i; }else{ k=p[k]; } } pos=p; }
运行结果: position=9,比较次数为 18次
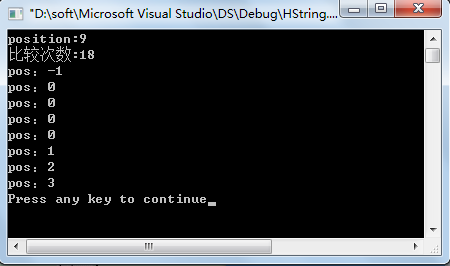
用原始Index 匹配算法测试当前的主串、子串,运行结果:position=9,比较次数为 26次
用第一次的改进匹配算法测试当前的主串、子串,运行结果:position=9,比较次数为 21次