ALS算法中文名又称为最小二乘法,在机器学习中,ALS特指使用最小二乘法求解的协同过滤算法中的一种
ALS算法在构建spark推荐系统时,是用的最多的协同过滤算法,集成到了spark中ml库和mllib库中(ml库算法接口基于DataFrames,mllib库算法接口基于RDDs,ml库使用越来越普遍)
ALS算法属于User-Item CF,同时会考虑User和Item两个方面,是一种同时考虑到用户和物品的算法
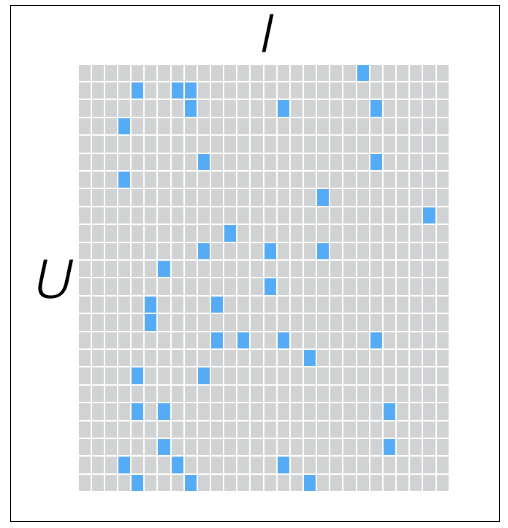
找出基于UXI的“用户-物品”矩阵如图:
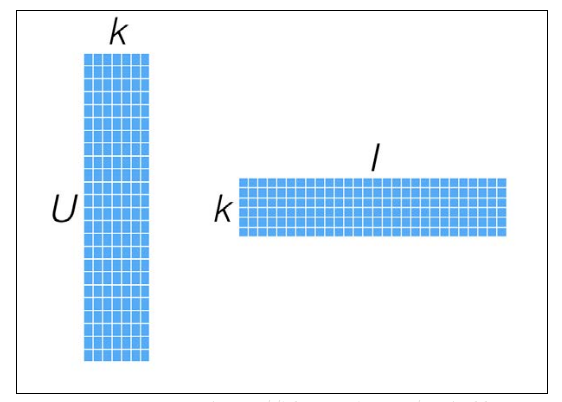
找到和“用户-物品”近似的K维低阶矩阵(K值为ALS中的超参,通常范围取10-200):用户矩阵->U x K,物品矩阵->I x K,这两个因子矩阵的乘积,得到的则为原始评级数据的近似值:
原理分析
ALS实现原理是迭代求解一系列的最小损失值,在每次迭代时,需要固定因子矩阵中的一个,来更新另一个矩阵因子矩阵,之后将更新的矩阵固定住,再更新另一个矩阵,直到模型收敛
记在原始评分矩阵中的用户Ut和对项目Is的打分Rst,由乘积(VTU)拟合获得的评分为(VTU)st.则两者平方误差为((VTU)st-Rst)2,则经验误差可以记为:
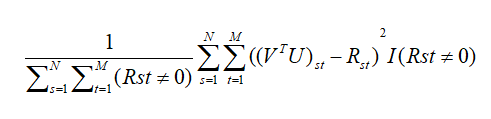
该模型对于每一个用户特征向量和项目特征向量都是凸的,意味着可以在它所有的U和I 上能达到局部最优,等价于在矩阵U,I,R中各列向量都独立服从各自的正太分布下的极大似然拟合,所以该模型也被称为概率矩阵分解模型(PMF)
测试:
import com.nj.untils.MySqlHandler import org.apache.spark.mllib.recommendation.{ALS, Rating} import org.apache.spark.sql.SparkSession import org.apache.spark.sql.expressions.Window import org.apache.spark.sql.functions._ object AlsTest { //自定义打分标准 val actToNum=udf{ (info:String)=> info match { case "BROWSE"=>1 case "COLLECT"=>2 case "BUYCAR"=>4 case "ORDERS"=>8 } } case class UserAction(act:String,act_time:String,cust_id:String,good_id:String,browse:String) def main(args: Array[String]): Unit = { val spark=SparkSession.builder().appName("job").master("local[*]").getOrCreate() //读取用户的操作行为,并读取 val dff = spark.sparkContext.textFile("file:///C:/Users/Administrator/Desktop/myact/*.log").cache() //将读入的数据转为dataframe 计算出每个用户对该用户接触过的商品的评分 import spark.implicits._ val df = dff.map(line=>{ val arr=line.split(" ") UserAction(arr(0),arr(1),arr(2),arr(3),arr(4)) }).toDF().select($"cust_id",$"good_id",actToNum($"act").alias("score")) .groupBy("cust_id","good_id").agg(sum($"score").alias("score")).cache() //为了放置用户编号或商品编号中含有非数字情况,所以对所有的商品和用户编号给一个连续的对应的数字编号后再存到缓存 val gwnd=Window.partitionBy().orderBy("good_id") val cwnd=Window.partitionBy().orderBy("cust_id") val goodstab=MySqlHandler.readMySQL(spark,"goods") .select($"good_id",row_number().over(gwnd).alias("gid") ).cache() val custtab=MySqlHandler.readMySQL(spark,"customs") .select($"cust_id",row_number().over(cwnd).alias("uid")).cache() //将df 和goodstab以及custtab join 只保留(gid,uid,score) val zc = df.join(goodstab,Seq("good_id"),"inner").join(custtab,Seq("cust_id"),"inner") .select("gid","uid","score") val alldata=zc.rdd.map(row=>{ Rating(row.getAs("uid").toString.toInt, row.getAs("gid").toString.toInt, row.getAs("score").toString.toFloat) }) //查看user为200的用户的所有评分 val a=alldata.keyBy(_.user).lookup(200) //println(a.size) //将获得的Rating集合拆分按照0.2,0.8比例拆分为两个集合 val Array(train,test)=alldata.randomSplit(Array(0.8,0.2)) //8成训练模型 2成测试模型 //使用8成的数据去训练模型 // val model = ALS.train(train,rank = 10,maxIter = 20,implicitPrefs = false) ml 适合DataFrame val model = new ALS().setRank(10).setIterations(10).setLambda(0.01).setImplicitPrefs(false).run(alldata) //mllib 适合RDD算子 val tj=model.recommendProductsForUsers(10) //每一个user都拿出打分最高的前10位 得到RDD(Int,Array[Rating]) tj.flatMap{ case(user:Int,ratings:Array[Rating])=> ratings.map{case (rat:Rating)=>(user,rat.product,rat.rating)} }.foreach(println) //可以选择存储到hdfs tj.toDF().write.mode("overwrite").save("path") spark.stop() } }