执行过程
第一步:编写汇编源程序
使用文本编辑器(如Edit、记事本),用汇编语言编写汇编源程序。第一步的结果是产生了一个存储源程序的文本文件。
第二步:对源程序进行编译连接
使用汇编语言编译程序对源程序文件中的源程序进行编译,产生目标文件;再用连接程序对目标文件进行连接,生成可在操作系统中直接运行的可执行文件。
可执行文件包括两部分内容:1.程序(源程序中的汇编指令翻译过来的机器码)和数据(源程序中定义的数据)。 2.相关的描述信息(程序多大、要占用多少内存空间等)
第三步:执行可执行文件中的程序
操作系统依照可执行文件中的描述信息,将可执行文件中的机器码和数据加载入内存,并进行相关的初始化(比如设置CS:IP指向第一条要执行的命令),然后由CPU执行程序。
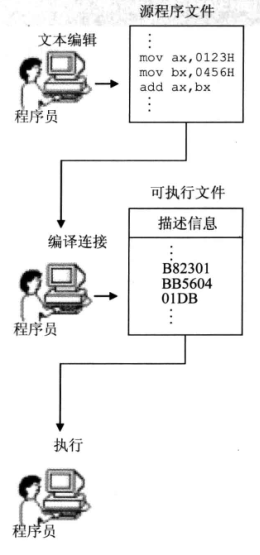
源程序

伪指令
在汇编语言源程序中,包含两种指令, 一种是汇编指令, 一种是伪指令。汇编指令是有对应的机器码的指令,可以被编译为机器指令,最终为CPU 所执行。而伪指令没有对应的机器指令,最终不被CPU 所执行。那么谁来执行伪指令呢?伪指令是由编译器来执行的指令,编译器根据伪指令来进行相关的编译工作。
segment和ends 是一对成对使用的伪指令,这是在写可被编译器编译的汇编程序时,必须要用到的一对伪指令。segment和ends 的功能是定义一个段,segment说明一个段开始,ends说明一个段结束。一个段必须有一个名称来标识,使用格式为:
段名 segment 段名 ends
codesg segment #定义一个段,段的名称为“codesg",这个段从此开始 codesg ends #名称为“codesg"的段到此结束
一个汇编程序是由多个段组成的,这些段被用来存放代码、数据或当作栈空间来使用。一个源程序中所有将被计算机所处理的信息:指令、数据、栈,被划分到了不同的段中。
end
end是一个汇编程序的结束标记,编译器在编译汇编程序的过程中,如果碰到了伪指令end,就结束对源程序的编译。所以,在我们写程序的时候,如果程序写完了,要在结尾处加上伪指令end。否则,编译器在编译程序时,无法知道程序在何处结束。
注意,不要搞混了end和ends,ends是和segment成对使用的,标记一个段的结束,ends的含义可理解为“end segment"。
assume
这条伪指令的含义为“假设“。它假设某一段寄存器和程序中的某一个用segment … ends定义的段相关联。通过assume说明这种关联,在需要的情况下,编译程序可以将段寄存器和某一个具体的段相联系。以后我们编程时,记着用assume将有特定用途的段和相关的段寄存器关联起来即可。
用codesg segment... codesg ends 定义了一个名为codseg的段,在这个段中存放代码,所以这个段是一个代码段。在程序的开头,用assume cs : codesg 将用作代码段的段codesg 和CPU 中的段寄存器cs 联系起来。
源程序中的“程序”
用汇编语言写的源程序,包括伪指令和汇编指令,我们编程的最终目的是让计算机完成一定的任务。源程序中的汇编指令组成了最终由计算机执行的程序,而源程序中的伪指令是由编译器来处理的,它们并不实现我们编程的最终目的。这里所说的程序就是指源程序中最终由计算机执行、处理的指令或数据。
以将源程序文件中的所有内容称为源程序,将源程序中最终由计算机执行、处理的指令或数据,称为程序。程序最先以汇编指令的形式存在源程序中,经编译、连接后转变为机器码,存储在可执行文件中。

标号
汇编源程序中,除了汇编指令和伪指令外,还有一些标号,比如“codesg"。一个标号指代了一个地址。比如codesg在segment的前面,作为一个段的名称,这个段的名称最终将被编译、连接程序处理为一个段的段地址。
程序的结构
源程序是由一些段构成的。我们可以在这些段中存放代码、数据、或将某个段当作栈空间。
1.定义一个段,名称为abc
abc segment
abc ends
2.在这个段中写入汇编指令,来实现我们的任务
abc segment mov ax,2 add ax,ax add ax,ax abc ends
3.指出程序在何处结束
abc segment mov ax , 2 add ax , ax add ax,ax abc ends end
4.abc被当作代码段来用,所以,应该将abc和cs联系起来
assume cs:abc abc segment mov ax,2 add ax,ax add ax, ax abc ends end
程序返回
这两条指令所实现的功能就是程序返回。
mov ax, 4c00H int 21H
与结束相关的概念,段结束、程序结束、程序返回:

语法错误和逻辑错误
程序在编译时被编译器发现的错误是语法错误

程序中有编译器不能识别的aume, 而且编译器在编译的过程中也无法知道abc段到何处结束。

在源程序编译后,在运行时发生的错误是逻辑错误。语法错误容易发现,也容易解决。而逻辑错误通常不容易被发现。例如没有程序返回语句。
编辑源程序
可以用任意的文本编辑器来编辑源程序,只要最终将其存储为纯文本文件即可。

编写程序
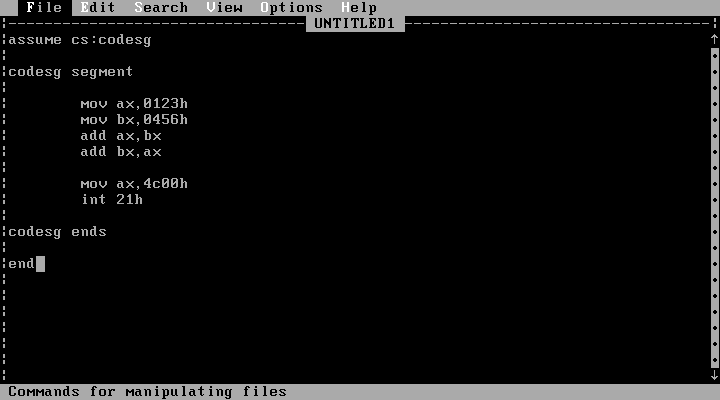
将程序保存为文件C:1.asm后,退出Edit。
编译
可以对asm源程序进行编译,生成包含机器代码的目标文件。
在编译一个源程序之前首先要找到一个相应的编译器。采用微软的masm5.0 汇编编译器,文件名为masm.exe。
1.进入DOS方式,进入c:masm 目录,运行masm.exe

运行masm 后,首先显示出一些版本信息,然后提示输入将要被编译的源程序文件的名称。注意, ”[. ASM]" 提示我们,默认的文件扩展名是asm, 比如,要编译的源程序文件名是“pl.asm", 只要在这里输入“ pl" 即可。可如果源程序文件不是以asm 为扩展名的话,就要输入它的全名。比如源程序文件名为“ pl.txt ", 就要输入全名。
在输入源程序文件名的时候一定要指明它所在的路径。如果文件就在当前路径下,只输入文件名就可以,可如果文件在其他的目录中,则要输入路径。比如,要编译的文件pl.txt 在“c:windowsdesktop"下,则要输入“c:windowsdesktopp1.txt"。
我们要编译的文件是C 盘根目录下的1.asm , 所以此处输入“c:1.asm" 。
2.输入要编译的源程序文件名后,按Enter 键
在输入源程序文件名后,程序继续提示我们输入要编译出的目标文件的名称,目标文件是我们对一个源程序进行编译要得到的最终结果。注意屏幕上的显示:"[1.obj]",因为我们已经输入了源程序文件名为1.asm,则编译程序默认要输出的目标文件名为1.obj,所以可以不必再另行指定文件名。直接按Enter 键,编译程序将在当前的目录下, 生成1.obj文件。
这里,也可以指定生成的目标文件所在的目录,比如,想让编译程序在" c:w indowsdesktop" 下生成目标文件I.obj, 则可输入“c:windowsdesktop1" 。我们直接按Enter 键,使用编译程序设定的目标文件名。
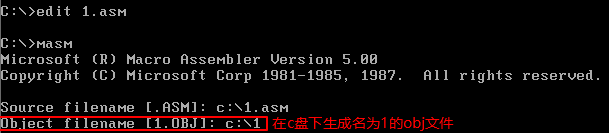
3.确定了目标文件的名称后
编译程序提示输入列表文件的名称,这个文件是编译器将源程序编译为目标文件的过程中产生的中间结果。可以让编译器不生成这个文件,直接按Enter 键即可。
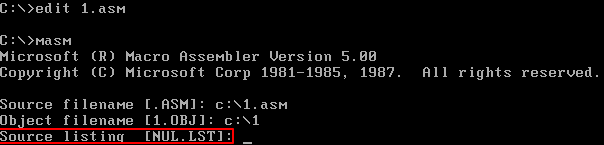
4.忽略了列表文件的生成后
编译程序提示输入交叉引用文件的名称,这个文件同列表文件一样,是编译器将源程序编译为目标文件过程中产生的中间结果。可以让编译器不生成这个文件,直接按Enter 键即可。
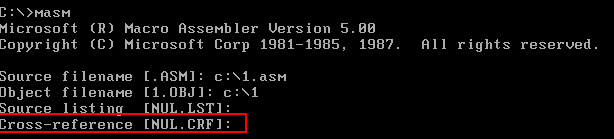
5.忽略了交叉引用文件的生成后
对源程序的编译结束,编译器输出的最后两行告诉我们这个源程序没有警告错误和必须要改正的错误。
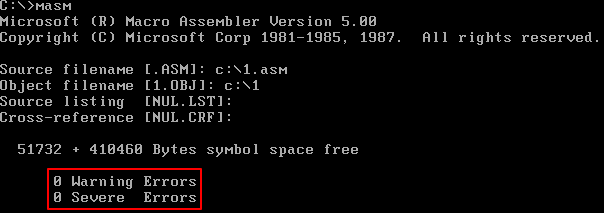
通过对C 盘根目录下的l.asm 进行编译的过程,展示了使用汇编编译器对源程序进行编译的方法。按照上面的过程进行了编译之后,在编译器masm.exe 运行的目录c:masm 下(即当前路径下),将出现一个新的文件:1.obj,这是对源程序1.asm 进行编译
所得到的结果。当然,如果编译的过程中出现错误,那么将得不到目标文件。一般来说,有两类错误使我们得不到所期望的目标文件:
- 程序中有“Severe Errors" ;
- 找不到所给出的源程序文件。
在编译的过程中,我们提供了一个输入,即源程序文件。最多可以得到3 个输出:目标文件(.obj)、列表文件(.lst)、交叉引用文件(.crf),这3 个输出文件中,目标文件是我们最终要得到的结果,而另外两个只是中间结果,可以让编译器忽略对它们的生成。
连接
在对源程序进行编译得到目标文件后,我们需要对目标文件进行连接,从而得到可执行文件。对c:1.asm进行编译得到c:masm1.obj,现在再将c:masm1.obj,连接为c:masm1.exe
使用微软的Overlay Linker3.60 连接器,文件名为link.exe。
1.进入DOS 方式,进入c:masm目录
运行link 后,首先显示出一些版本信息,然后提示输入将要被连接的目标文件的名称。注意,”[.OBJ]" 提示我们,默认的文件扩展名是obj, 比如要连接的目标文件名是“p1.obj" ,只要在这里输入“p1" 即可。可如果文件不是以obj 为扩展名,就要输入它的全名。比如目标文件名为“p1.bin",就要输入全名。
在输入目标文件名的时候,要注意指明它所在的路径。这里,要连接的文件是当前目录下的1.obj,所以此处输入“1”。
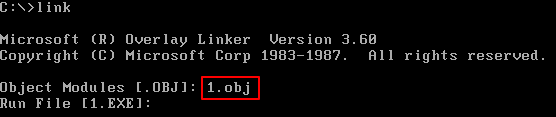
2.输入要连接的目标文件名后,按Enter键
在输入目标文件名后,程序继续提示我们输入要生成的可执行文件的名称,可执行文件是我们对一个程序进行连接要得到的最终结果。注意屏幕上的显示:
"[1.EXE]",因为已经确定了目标文件名为1.obj,则程序默认要输出的可执行文件名为1.EXE,所以可以不必再另行指定文件名。直接按Enter键,编译程序将在当前的目录下,生成1.EXE 文件。这里,也可以指定生成的可执行文件所在的目录,比如,想让连接程序在"c:windowsdesktop"下生成可执行文件1.EXE,则可输入“c:windowsdesktop1“。我们直接按Enter键,使用连接程序设定的可执行文件名。
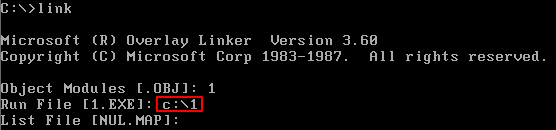
3.确定了可执行文件的名称后
连接程序提示输入映像文件的名称,这个文件是连接程序将目标文件连接为可执行文件过程中产生的中间结果,可以让连接程序不生成这个文件,直接按Enter键即可。
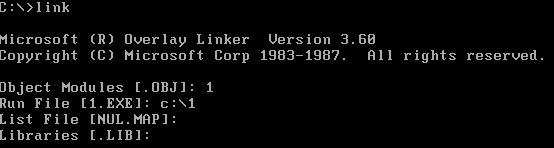
4.忽略了映像文件的生成后
连接程序提示输入库文件的名称。库文件里面包含了一些可以调用的子程序,如果程序中调用了某一个库文件中的子程序,就需要在连接的时候,将这个库文件和目标文件连接到一起,生成可执行文件。但是,这个程序中没有调用任何子程序,所以,这里忽略库文件名的输入,直接按Enter 键即可。
5.忽略了库文件的连接后
对目标文件的连接结束,连接程序输出的最后一行告诉我们,这个程序中有一个警告错误: “没有栈段”,这里我们不理会这个错误。

上面我们通过对当前路径下的1.obj进行连接的过程,展示了使用连接器对目标文件进行连接的方法。按照上面的过程进行了连接之后,在连接器link.exe 运行的目录c:masm下(即当前路径下),将出现一个新的文件:1.exe,这是对目标文件1.obj进行连接所得到的结果。当然,如果连接过程中出现错误,那么将得不到可执行文件。
汇编语言编程,就要用到编辑器(Edit)、编译器(masm)、连接器(link)、调试工具(Debug)等所有工具,而这些工具都是在操作系统之上运行的程序,所以我们的学习过程必须在操作系统的环境中进行。
连接的作用
(1) 当源程序很大时,可以将它分为多个源程序文件来编译,每个源程序编译成为目标文件后,再用连接程序将它们连接到一起,生成一个可执行文件;
(2) 程序中调用了某个库文件中的子程序,需要将这个库文件和该程序生成的目标文件连接到一起,生成一个可执行文件;
(3) 一个源程序编译后,得到了存有机器码的目标文件,目标文件中的有些内容还不能直接用来生成可执行文件,连接程序将这些内容处理为最终的可执行信息。所以,在只有一个源程序文件,而又不需要调用某个库中的子程序的情况下,也必须用连接程序对目
标文件进行处理,生成可执行文件。
注意,对千连接的过程,可执行文件是我们要得到的最终结果。
以简化的方式进行编译和连接
使用masm和link进行编译和连接。可以看出,我们编译、连接的最终目的是用源程序文件生成可执行文件。在这个过程中所产生的中间文件都可以忽略。我们可以用一种较为简捷的方式进行编译、连接。
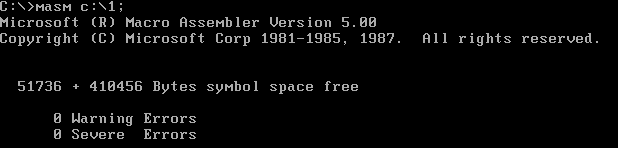
命令行“ masm c:1;",在masm 后面加上被编译的源程序文件的路径、文件名, 在命令行的结尾再加上分号,按Enter 键后,编译器就对c:1.asm 进行编译,在当前路径下生成目标文件1.obj,并在编译的过程中自动忽略中间文件的生成。

命令行“link 1;",在link 后面加上被连接的目标文件的路径、文件名,在命令行的结尾再加上分号,按Enter 键后,连接程序就对当前路径下的1.obj 进行处理,在当前路径下生成可执行文件1.exe, 并在过程中自动忽略中间文件的生成。
exe的执行
直接运行即可
将可执行文件中的程序装载进入内存井使它运行
在DOS中,可执行文件中的程序P1若要运行,必须有一个正在运行的程序P2,将P1从可执行文件中加载入内存,将CPU的控制权交给它,P1才能得以运行;当P1运行完毕后,应该将CPU的控制权交还给使它得以运行的程序P2。

(1)在DOS中直接执行1.exe 时,是正在运行的command,将1.exe中的程序加载入内存;
(2)command设置CPU的CS:IP指向程序的第一条指令(即程序的入口),从而使程序得以运行;
(3)程序运行结束后,返回到command中,CPU继续运行command。
汇编程序从写出到执行的过程
编程(Edit) -》1.asm -》编译(masm) -》1.obj -》连接(link) -》1.exe -》加载内存中的程序(command) -》运行(CPU)
程序执行过程的跟踪
在DOS中运行一个程序的时候,是由command将程序从可执行文件中加载入内存,并使其得以执行。但是,这样我们不能逐条指令地看到程序的执行过程,因为command的程序加载,设置CS:IP指向程序的入口的操作是连续完成的,而当CS:IP一指向程序的入口,command就放弃了CPU的控制权,CPU立即开始运行程序,直至程序结束。
为了观察程序的运行过程,可以使用Debug。Debug可以将程序加载入内存,设置CS:IP指向程序的入口,但Debug并不放弃对CPU 的控制,这样,我们就可以使用Debug 的相关命令来单步执行程序,查看每一条指令的执行结果。
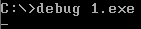
在提示符后输入“debug 1.exe",按Enter 键,Debug将程序从1.exe中加载入内存,进行相关的初始化后设置CS:IP指向程序的入口。
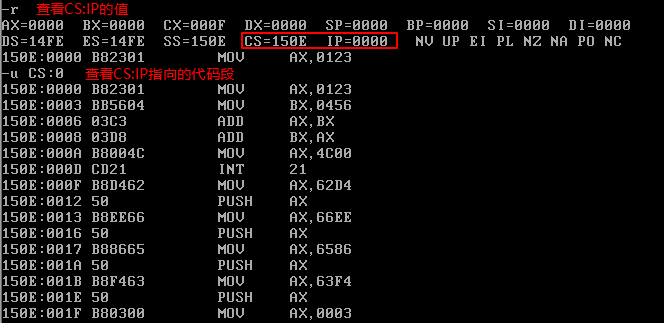
Debug将程序从可执行文件加载入内存后,cx中存放的是程序的长度。1.exe 中程序的机器码共有15个字节。则1.exe加载后,cx中的内容为000FH。
EXE文件中程序的加载过程

(1) 程序加载后,ds中存放着程序所在内存区的段地址,这个内存区的偏移地址为0, 则程序所在的内存区的地址为ds:0;
(2) 这个内存区的前256个字节中存放的是PSP,DOS 用来和程序进行通信。从256字节处向后的空间存放的是程序。

物理地址=段地址x16+偏移地址;(x16是左移4位正好用20根数据总线)
从ds中可以得到PSP的段地址SA,PSP的偏移地址为0,则物理地址为SAx16+0。
因为PSP占256(100H)字节,所以程序的物理地址是:SAx16+0+256 = SAx16 + 16x16 + 0 = (SA+16)x16+0,可用段地址和偏移地址表示为: SA+10H:0 。
DS=14FE,则PSP 的地址为14FE:0, 程序的地址为150E:0(即14FE+10:0) 。
CS=150E,IP=0000, CS:IP 指向程序的第一条指令。注意,源程序中的指令是mov ax,0123H,在Debug中记为mov ax,0123,这是因为Debug默认所有数据都用十六进制表示。
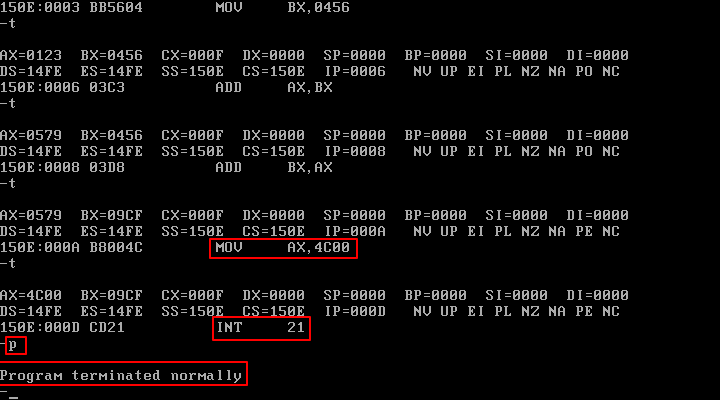
用T命令单步执行程序中的每一条指令,并观察每条指令的执行结果,到了int 21,要用P命令执行。
int 21 执行后,显示出“ Program terminated normally", 返回到Debug中。表示程序正常结束。注意,要使用P命令执行int 21。
在DOS中运行程序时,是command将程序加载入内存,所以程序运行结束后返回到command中,而在这里是Debug将程序加载入内存,所以程序运行结束后要返回到Debug中。
使用Q命令退出Debug,将返回到command中,因为Debug 是由command加载运行的。在DOS中用“debug 1.exe"运行Debug对1.exe进行跟踪时,程序加载的顺序是:command加载Debug,Debug加载1.exe。返回的顺序是:从1.exe中的程序返回到Debug,从Debug返回到command。
实例
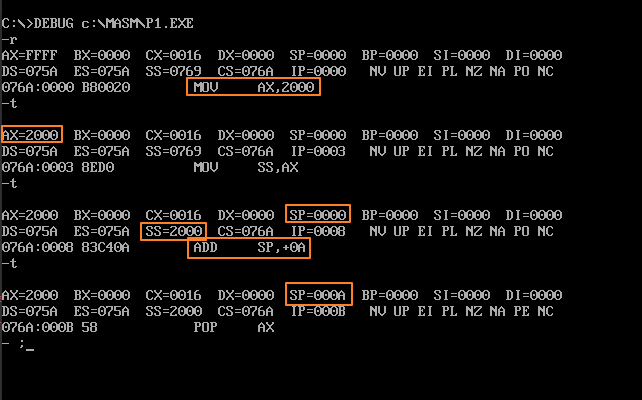
assume cs:codesg codesg segment mov ax,2000H mov ss,ax mov sp,0 add sp,10 pop ax pop bx push ax push bx pop ax pop bx mov ax,4c00H int 21H codesg ends end
用Debug跟踪exe 的执行过程,写出每一步执行后,相关寄存器中的内容和栈顶的内容。
DS+10H:000 = CS:IP,DS到CS中间这
查看PSP中的指令
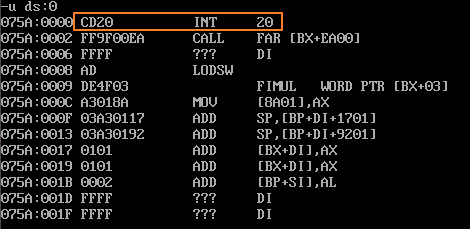
PSP的头两个字节是CD20, 用Debug加载exe,查看PSP的内容。
