第三百七十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现我的搜索以及热门

我的搜素简单实现原理
我们可以用js来实现,首先用js获取到输入的搜索词
设置一个数组里存放搜素词,
判断搜索词在数组里是否存在如果存在删除原来的词,重新将新词放在数组最前面
如果不存在直接将新词放在数组最前面即可,然后循环数组显示结果即可
热门搜索
实现原理,当用户搜索一个词时,可以保存到数据库,然后记录搜索次数,
利用redis缓存搜索次数最到的词,过一段时间更新一下缓存
备注:Django结合Scrapy的开源项目可以学习一下
django-dynamic-scraper
https://github.com/holgerd77/django-dynamic-scraper
补充
默认的elasticsearch(搜索引擎)只能搜索1万条数据,在大就会报错了
设置方法
步骤一:
打开项目的索引库地址,将该索引先关闭,否则设置操步骤二无法提交
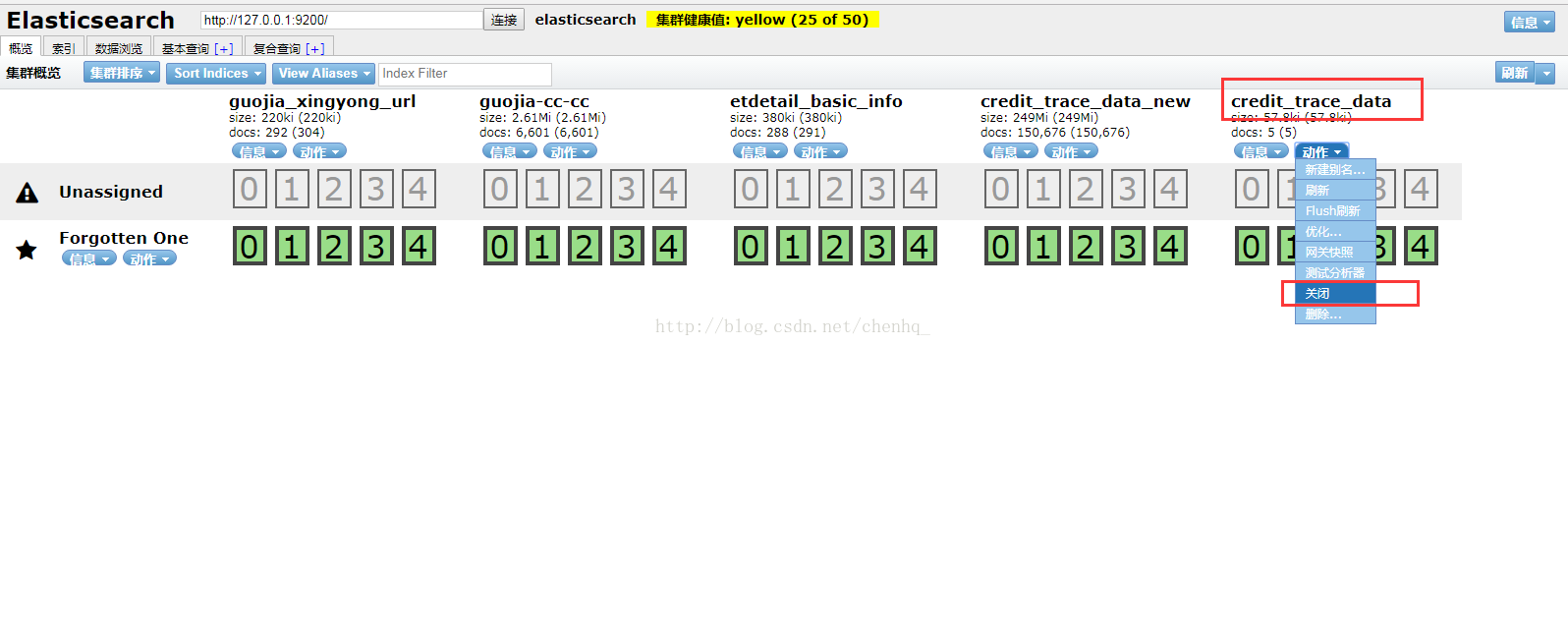
步骤二:
打开复合查询,填入如下信息,记得选择PUT方式提交,credit_trace_data改为本索引库中的索引,max_result_window设为20亿,此值是integer类型,不能无限大
http://127.0.0.1:9200/ PUT
credit_trace_data/_settings?preserve_existing=true
{
"max_result_window" : "2000000000"
}
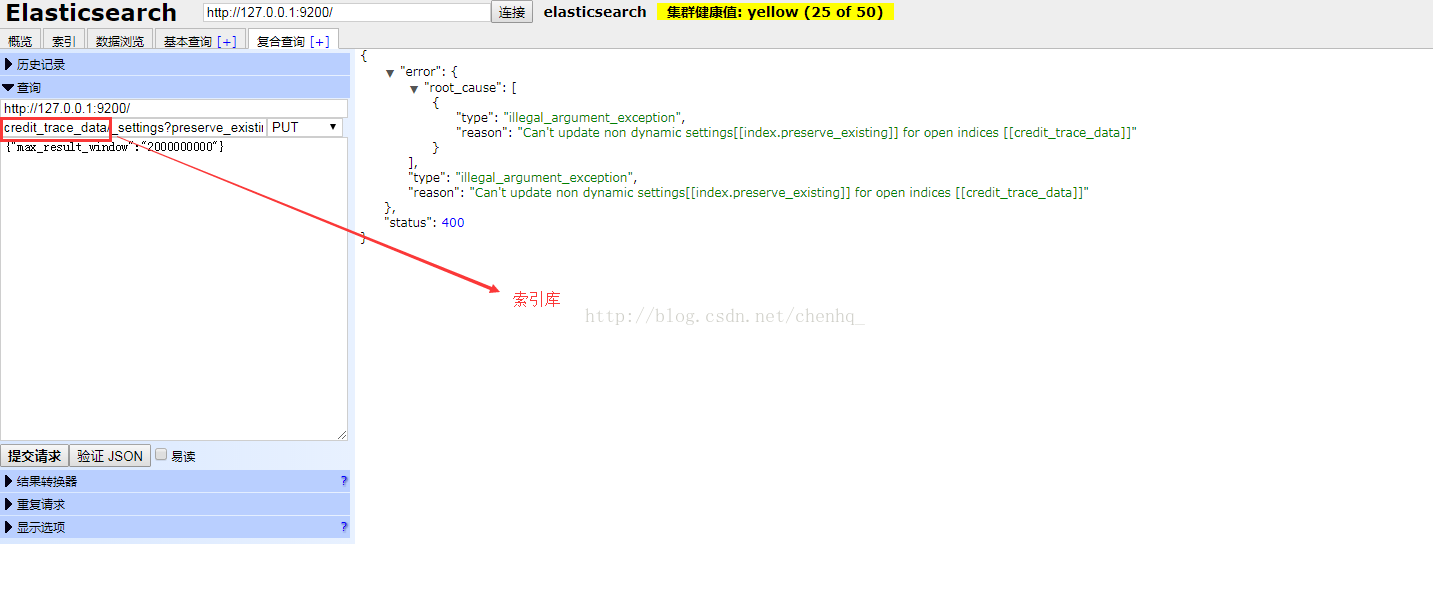
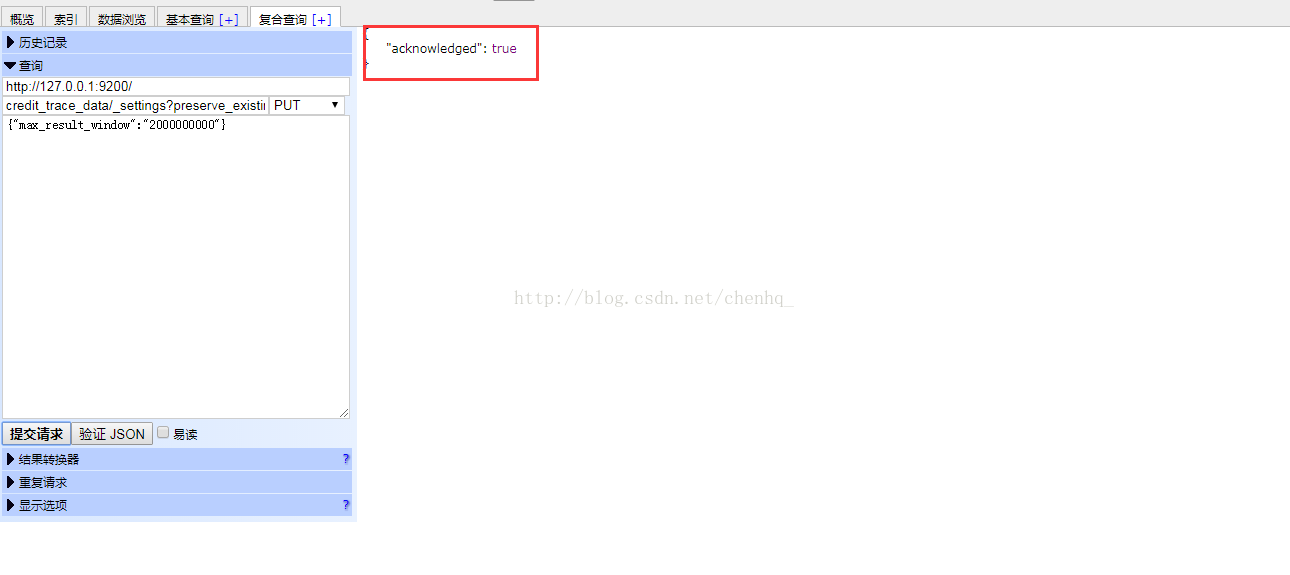
最后点击提交申请,如果配置正确右侧窗口会显示如下信息
如果要查询max_result_window时只需要将PUT改为get即可
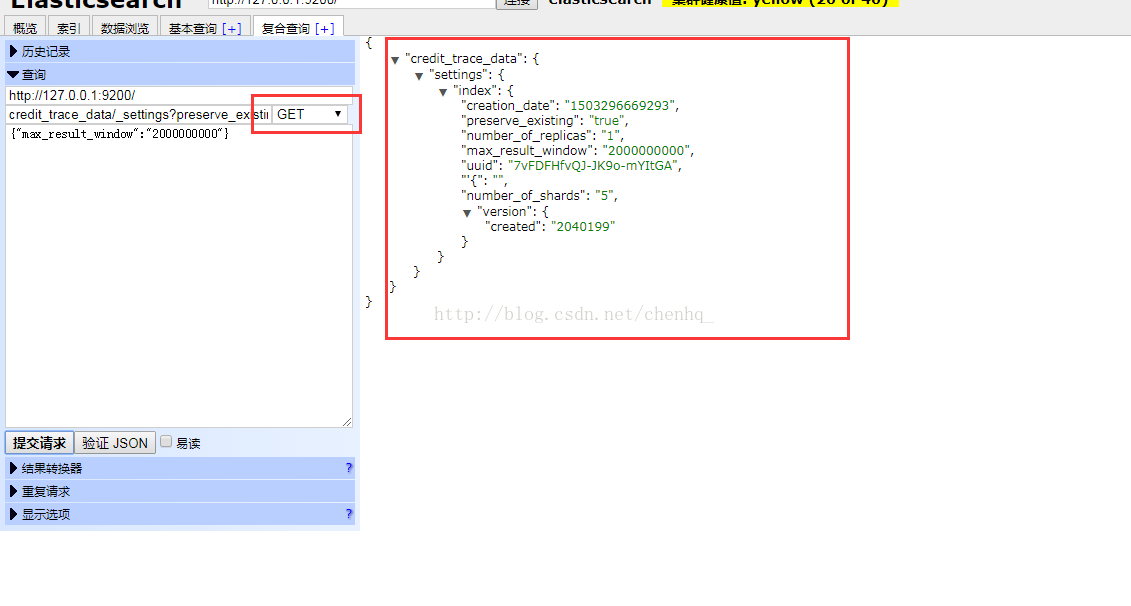
最后记得开启索引!