任务目标:以分布式的方式爬取链家网上二手房信息,包括标题、城市、行政区、总价、户型、面积、朝向等信息
分布式爬虫,即在多台电脑上同时执行同一个爬虫任务,在分布式爬取之前,需要先完成单机爬虫,然后部署到多台机器上,完成分布式。
链家网单机爬虫:从城市页面开始爬取,到每个城市的不同行政区,以及每个行政区的多个页面,每个页面的多个二手房信息,到最后的二手房详情页面。
经过相应的网页结构分析,得到项目(项目名lianjia、爬虫名lj)结构及最终代码如下:
项目结构:
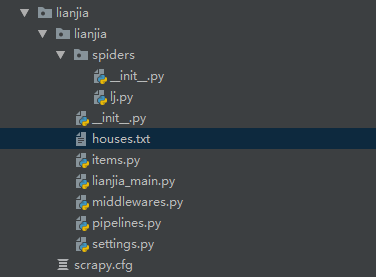
items.py
import scrapy
class LianjiaItem(scrapy.Item):
title = scrapy.Field()
city = scrapy.Field()
# 行政区
region = scrapy.Field()
total_price = scrapy.Field()
unit_price = scrapy.Field()
# 户型
house_type = scrapy.Field()
# 朝向
orientation = scrapy.Field()
full_area = scrapy.Field()
inside_area = scrapy.Field()
# 建筑类型
building_type = scrapy.Field()
pipelines.py
import json
class LianjiaPipeline:
def __init__(self):
self.fp = open('houses.txt', 'w', encoding='utf-8')
def process_item(self, item, spider):
self.fp.write(json.dumps(dict(item), ensure_ascii=False) + '
')
return item
def close_spider(self, spider):
self.fp.close()
由于最终要实现分布式爬取,数据是存储在redis数据库中,这里先用txt文件暂存数据,用以测试代码
settings.py
BOT_NAME = 'lianjia'
SPIDER_MODULES = ['lianjia.spiders']
NEWSPIDER_MODULE = 'lianjia.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 5
DOWNLOAD_DELAY = 0.2
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
ITEM_PIPELINES = {
'lianjia.pipelines.LianjiaPipeline': 300,
}
lj.py
import scrapy
from ..items import LianjiaItem
class LjSpider(scrapy.Spider):
name = 'lj'
allowed_domains = ['lianjia.com']
start_urls = ['https://www.lianjia.com/city/']
def parse(self, response):
city_li_list = response.xpath('//div[@class="city_list_section"]//li[@class="city_list_li'
' city_list_li_selected"]//div[@class="city_list"]//ul//li')
for city_li in city_li_list:
city = city_li.xpath('.//text()').get()
city_url = city_li.xpath('.//a/@href').get()
yield scrapy.Request(url=city_url + 'ershoufang', callback=self.parse_house_region, meta={'city': city})
def parse_house_region(self, response):
position_list = response.xpath('//div[@class="position"]//div[@data-role="ershoufang"]/div//a')
for position in position_list:
position_url = response.urljoin(position.xpath('.//@href').get())
yield scrapy.Request(url=position_url, callback=self.parse_house_list, meta=response.meta)
def parse_house_list(self, response):
house_url_list = response.xpath('//ul[@class="sellListContent"]//li/a/@href').getall()
for house_url in house_url_list:
yield scrapy.Request(url=house_url, callback=self.parse_house_detail, meta=response.meta)
# 翻页 todo
def parse_house_detail(self, response):
item = LianjiaItem()
item['title'] = response.xpath('//div[@class="sellDetailHeader"]//div[@class="title"]/h1/text()').get()
item['city'] = response.meta['city']
item['region'] = ''.join(response.xpath('//div[@class="areaName"]//span[@class="info"]//text()').getall()).strip()
item['total_price'] = response.xpath('//span[@class="total"]/text()').get() + '万'
item['unit_price'] = response.xpath('//span[@class="unitPriceValue"]/text()').get() + '元/平米'
house_base_info = response.xpath('//div[@class="base"]//div[@class="content"]/ul//li')
item['house_type'] = house_base_info[0].xpath('./text()').get()
item['orientation'] = house_base_info[6].xpath('./text()').get()
item['full_area'] = house_base_info[2].xpath('./text()').get()
item['inside_area'] = house_base_info[4].xpath('./text()').get()
item['building_type'] = response.xpath('//div[@class="area"]//div[@class="subInfo"]/text()').get()
yield item
lianjia_main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl lj'.split(' '))
运行lianjia_main.py后发现,可以正常抓取到数据保存到houses.txt中:


接下来需实现分布式:
scrapy本身是不支持分布式的,此时需要用到scrapy_redis组件, pip install scrapy_redis 即可安装使用
分布式爬虫中需指定一台机器为Redis服务器,可以用来管理爬虫服务器请求的URL并去重,还可以用来存储爬虫服务器爬取的数据;
需指定若干台机器为爬虫服务器,用来执行爬虫任务,从Redis服务器获取请求,并把爬取下来的数据发送给Redis服务器。
分布式爬虫的部署准备:
说明:由于我只有一台机器,系统为windows7,为了模拟分布式的部署,我使用了VMware Workstation虚拟机,里面有两个Ubuntu18,一台作为Redis服务器,ip为192.168.1.103;一台作为爬虫服务器,ip为192.168.1.105,配合本机windows7一同爬取。
-
爬虫服务器端安装scrapyd: pip3 install scrapyd
由于我已安装过,这里没有再次安装。 -
从 '/usr/local/lib/python3.6/dist-packages/scrapyd' 下拷贝出 'default_scrapyd.conf' 放到 '/etc/scrapyd/scrapyd.conf'

若提示没有文件夹,则新建对应的路径即可 -
修改 '/etc/scrapyd/scrapyd.conf' 中的 'bind_address' 为自己的IP(或改为 0.0.0.0 表示允许任意机器访问)
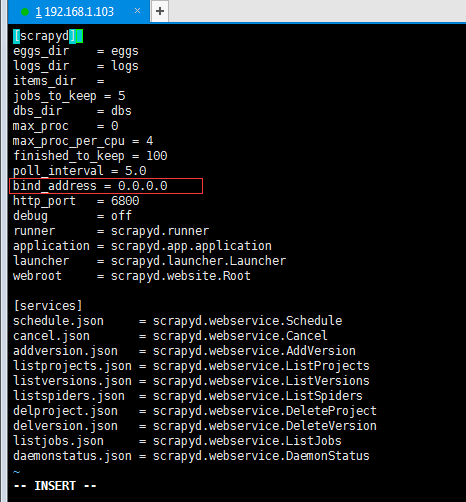
-
在开发机(自己的windows电脑)上安装scrapyd-client: pip install scrapyd-client
-
安装scrapyd-client后有一个bug,无法直接使用命令scrapyd-deploy,解决办法为:
进入安装python的文件夹下(配置python环境变量的那个),进入Scripts文件夹下,可以看到有个scrapyd-deploy,在此文件夹下新建文件scrapyd-deploy.bat,编辑内容为
@echo off
C:Python37-32python.exe C:Python37-32Scriptsscrapyd-deploy %*
路径根据实际情况更改,随后进入命令行敲入scrapyd-deploy -h,若出现相关提示信息即表示成功
- 修改项目中的 scrapy.cfg
[settings]
default = lianjia.settings
[deploy]
url = http://192.168.1.105:6800/
project = lianjia
192.168.1.105 为我要部署该项目的爬虫服务器的IP
- 在项目所在路径下执行部署命令,将项目部署到cfg文件所配置的爬虫服务器: scrapyd-deploy default -p lianjia
- 通过curl命令(需下载并配置环境变量)启动爬虫,格式如下: curl http://localhost:6800/schedule.json -d project=myproject -d spider=somespider
分布式爬虫的部署:
-
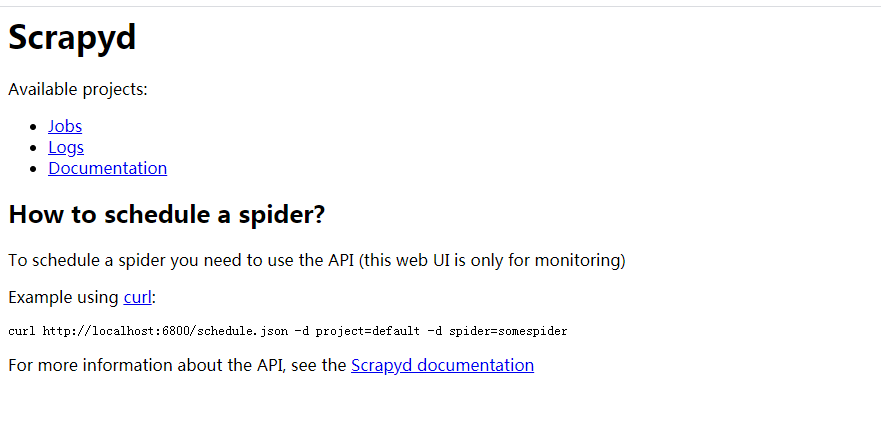
首先需要待部署的服务器开启scrapyd服务,这里我在 /srv 文件夹下新建文件夹lj,用来保存部署相关信息,在lj文件夹下输入scrapyd,回车,即可开启该服务
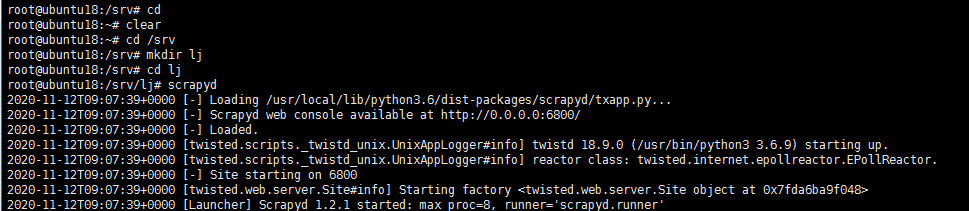
可以看到scrapyd服务的相关信息,在浏览器中输入 http://192.168.1.105:6800 出现如下页面,表示服务开启成功
-
在项目所在路径下执行部署命令: scrapyd-deploy
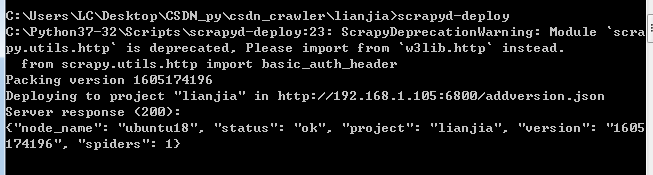
可以看到,部署成功 -
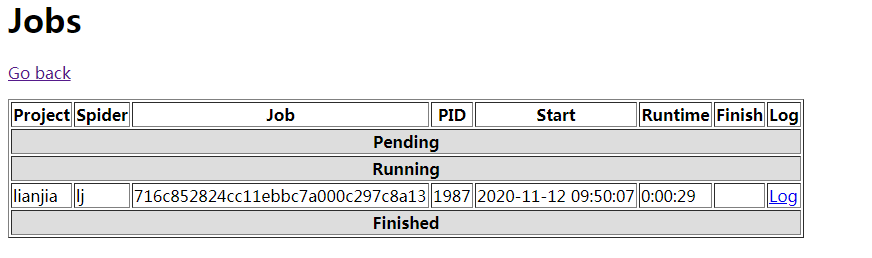
部署成功后就可以运行爬虫了: curl http://192.168.1.105:6800/schedule.json -d project=lianjia -d spider=lj

打开 http://192.168.1.105:6800 ,点击jobs,可以看到爬虫正在运行,点击log,可以查看日志输出
-
此时分布式爬虫并未部署,因为Redis服务器还没有配置,先关闭之前运行的爬虫:curl http://192.168.1.105:6800/cancel.json -d project=lianjia -d job=716c852824cc11ebbc7a000c297c8a13

-
选择ip为192.168.1.103的Ubuntu18为Redis服务器,安装redis:sudo apt install redis-server,然后修改配置文件 '/etc/redis/redis.conf',取消bind注释,修改为本机IP 102.168.1.103 或修改为 0.0.0.0,重启服务 sudo service redis-server restart
-
修改爬虫代码lj.py,使用scrapy_redis.spiders.RedisSpider替代原来的scrapy.Spider,或使用scrapy_redis.spiders.RedisCrawlSpider替代CrawlSpider,删除start_urls并设置redis_key,这个redis_key是后面控制redis启动爬虫用的,爬虫的第一个url,就是redis通过这个key发送出去的
import scrapy
from ..items import LianjiaItem
from scrapy_redis.spiders import RedisSpider
class LjSpider(RedisSpider):
name = 'lj'
allowed_domains = ['lianjia.com']
# start_urls = ['https://www.lianjia.com/city/']
redis_key = 'lj'
def parse(self, response):
......
- 在settings.py中对scrapy_redis进行相关配置
删除原来的pipeline配置并进行如下配置
# 确保request存储到redis中
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 确保所有爬虫共享相同的去重指纹
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 设置redis为item pipeline
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300,
}
# 是否在关闭时候保留原来的调度器和去重记录,True=保留,False=清空
SCHEDULER_PERSIST = True
REDIS_HOST = '192.168.1.103'
REDIS_PORT = 6379
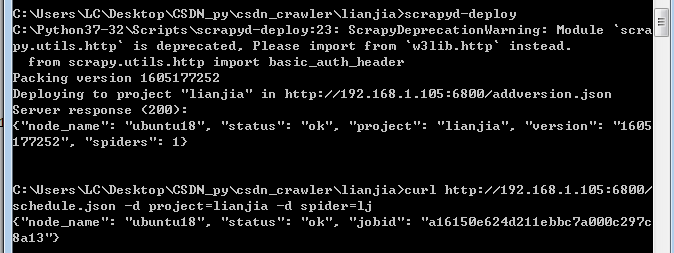
- 重新部署项目并运行: 首先将项目重新部署到192.168.1.105的爬虫服务器上并运行,然后在本地windows上也运行该项目,查看日志,可以看到,两个爬虫项目都没有开始爬取数据,而是等待Redis服务器的调度开始
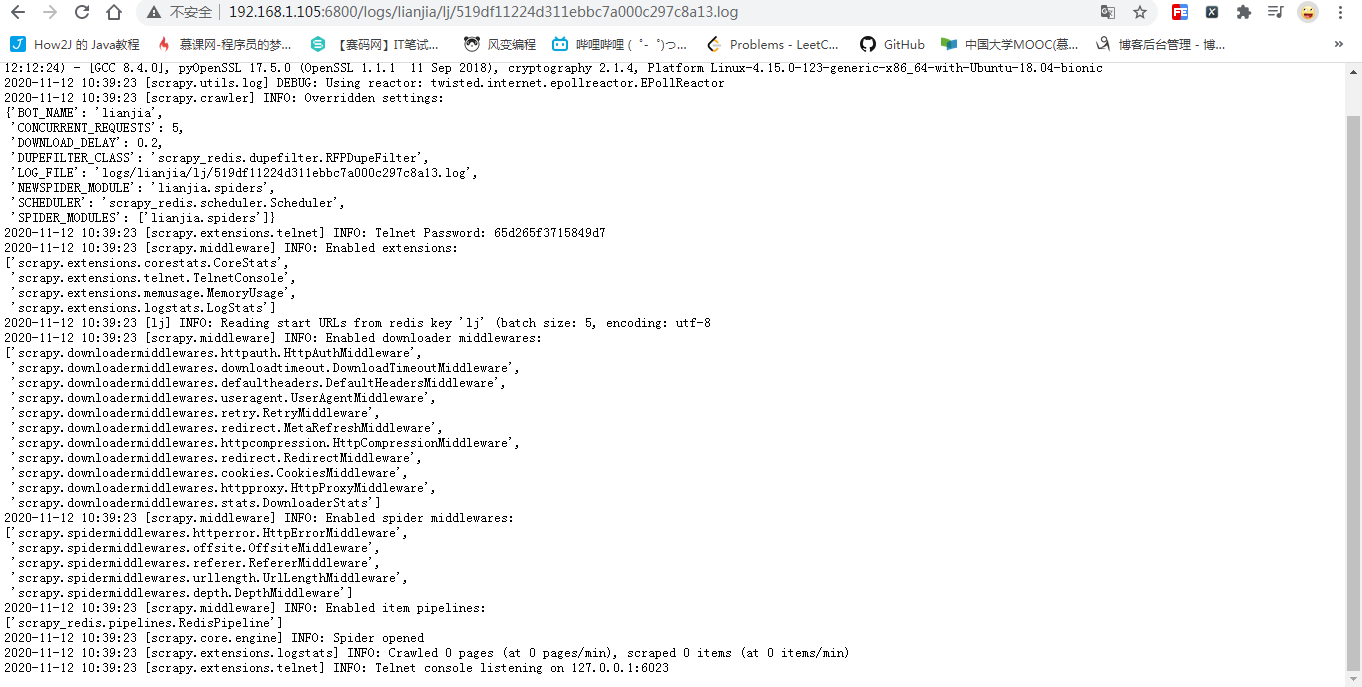
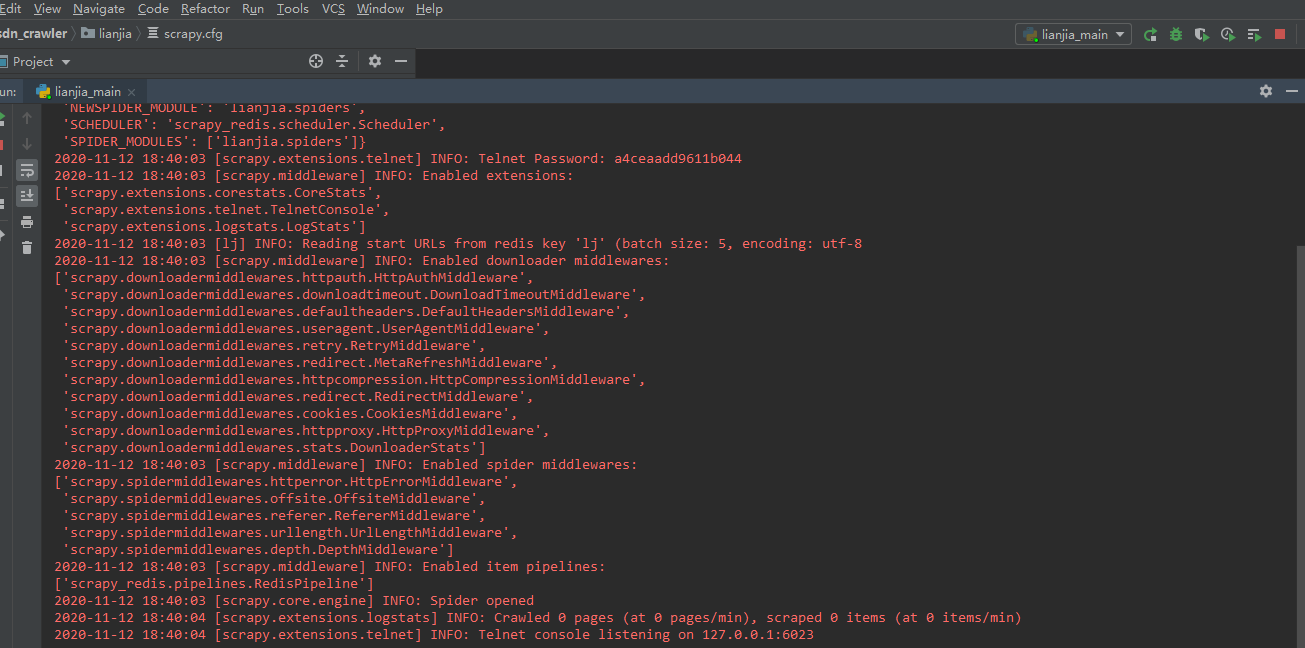
- 进入Redis服务器,推入一个开始的url链接: redis-cli>lpush [redis_key] start_url 开始爬取



可以看到,两个爬虫服务器同时开始爬取数据了,实现了分布式的爬取
- 查看redis服务器内的数据:
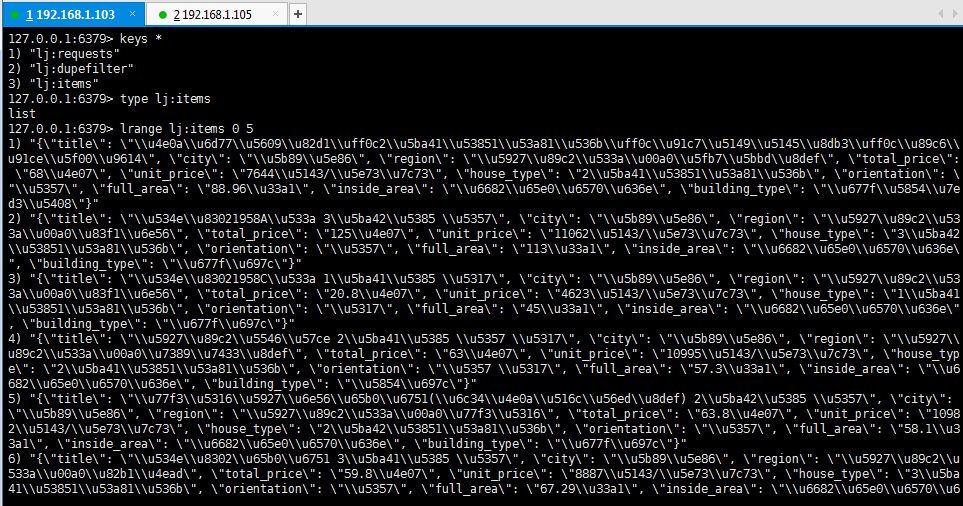
可以看到,有三种key:lj:requests、lj:dupefilter、lj:items,分别表示请求信息、去重过滤信息、爬取的数据信息
查看 lj:items 可以看到,里面已经存储了爬取到的数据,至此,分布式爬取链家网二手房数据的项目完成。