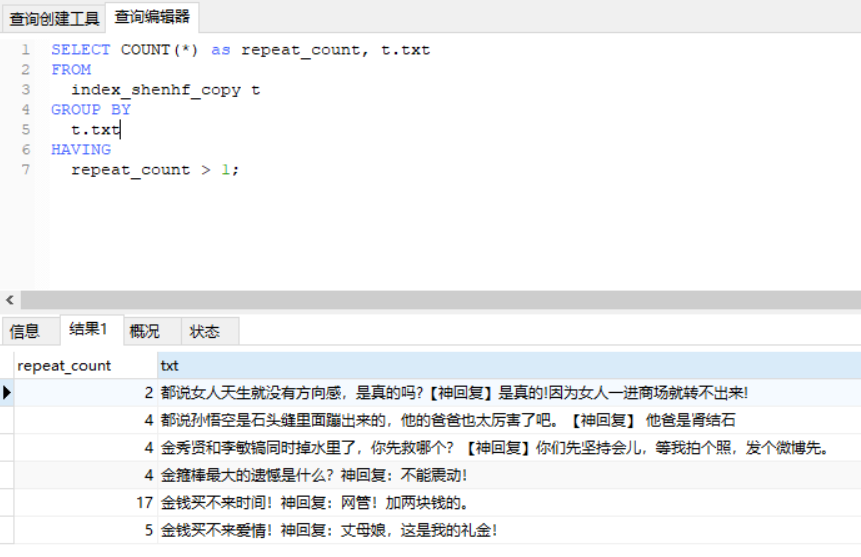
统计重复数据:
SELECT COUNT(*) as repeat_count, t.txt FROM index_shenhf_copy t GROUP BY t.txt HAVING repeat_count > 1;
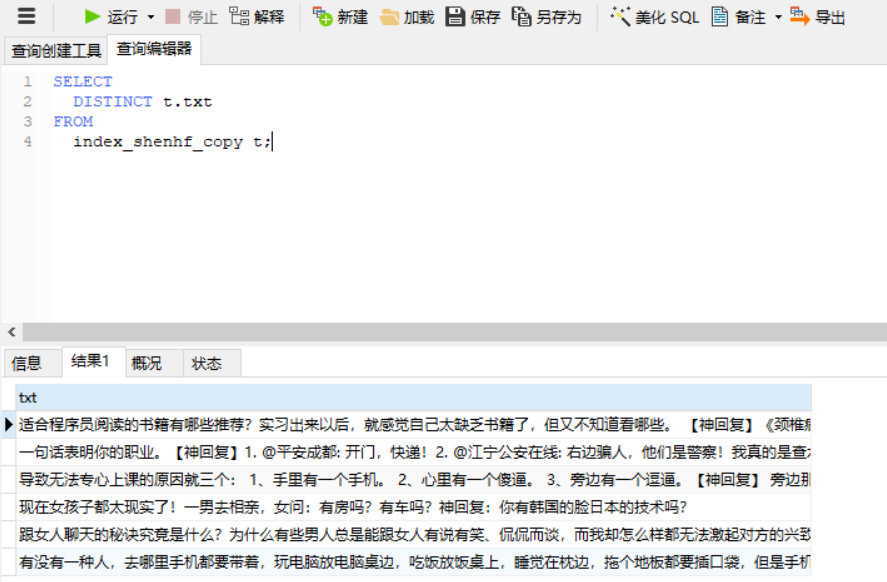
过滤重复数据方式1:
SELECT
DISTINCT t.txt
FROM
index_shenhf_copy t;
过滤重复数据方式2
SELECT
t.txt,t.id
FROM
index_shenhf_copy t
GROUP BY
t.txt,t.id;

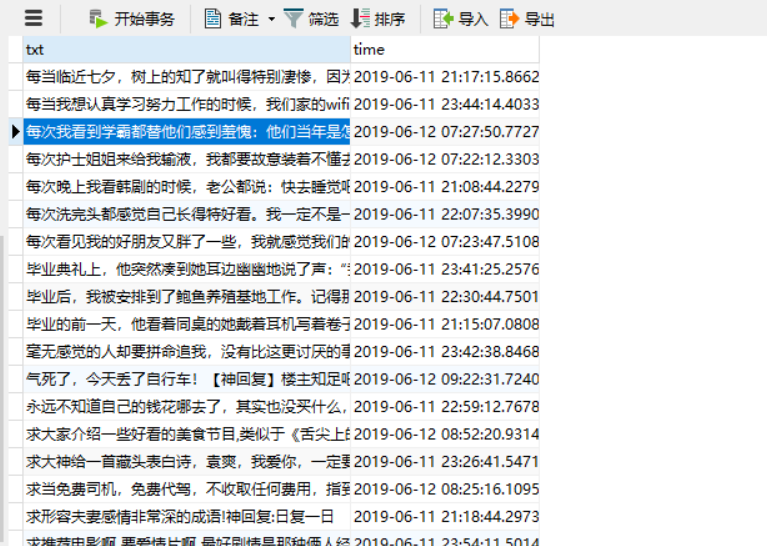
过滤创建新表
CREATE TABLE tmp SELECT
t.txt,t.time
FROM
index_shenhf_copy t
GROUP BY
t.txt;
CREATE TABLE newtmp LIKE index_shenhf; 复制表结构