今天来简单说一下node用来执行子进程的child_process。这两个方法如果经常用node执行其他脚本的人一定会经常使用。
首先我们来说一下spawn,这个方法实际上本质上是继承于node的stream的。那么也就是说大多时候我们可以将他执行的命令当做一种具有可读流特性的一种程序。我们先来看一下使用该命令的几种api。
const { spawn } = require('child_process');
const ls = spawn('sh',['/Users/xiaofeng/Codinglife/feng/server/test.sh']);
ls.stdout.on('data', (data) => {
}); ls.stderr.on('data', (data) => {
}); ls.on('close', (code) => { console.log(`子进程退出: ${code}`); });
此处代码修改自node官方api。 此处可以看到,spawn确实是基于流的写法。也就是说通过注册监听的方式,接受到子进程中的输出的时候,将结果整理输出。同时可以监听子程序的退出,以及错误。但是我在尝试的时候发现一个非常有意思的地方。
当我再执行的脚本中,执行多条echo的时候。
#!/bin/bash ll echo "33333333" echo "44444444"
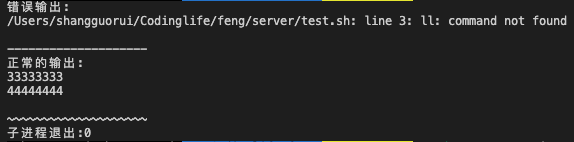
由此图可以看到,错误异常是无法阻止shell脚本执行的。同时,即使是多个echo也会在同一个data中被接收,但是,由于这是一个流。我们可以简单理解成一次性接受的数据肯定是有限的,不可能是无限的。那么这个上限大概是多少呢?原谅我没有找到具体的数值。不过我想这个数值应该不会很大。毕竟流的产生本身就是为了在不占用过多内存的情况下对于某个可读流的内容进行处理,之后成为可写流,写入到某个目的文件中。
那么,如果是流的上限有控制,那么每次执行程序,所读入的流内容是完全相同的吗???是否具有一定的随机性呢?
#!/bin/bash path="/ceshi.writein/" result="" for ((a = 1; a < 100; a++ )) do result=$result$path done echo $result echo "33333333" echo "44444444"


上方为使用spawn,监听方式所得程序结果,可以明显看出两者的输出内容不同,虽然我尝试运行多次。但是只有这两种结果产生,虽然我没有办法彻底理解为什么会产生这样的输出结果。但是这样的结果说明一个问题,如果我们想要直接通过这种方式来截取某一段程序的输出。或者拿某一段输出作为输出结果的话。恐怕我们要失望了,流处理实际上并不能很好地支持这种需求。因为它输出的内容带有一定的随机性。在我的多次尝试下,除非你得输出内容非常少,只有100个左右的输出时它会保持稳定输出。否则的话它还是有可能截断某次看起来应该一次echo的内容。
那么也就是说,假设我们此时有一个执行时间较长。需要获取某一段,或者某几段输出内容的时候,我们不应该使用spawn这种子进程的执行方式。spawn更适合做某种大文件的流式处理,例如此时我们有一个非常大的文件需要压缩,那么spawn是一个非常好的一种方式。由于流的特性他不会占用过多内存使用,毕竟node的默认内存只有1.7g。
既然spawn会截断输出,并不能满足我此时的需求。那么我们再来看一下exec命令呢?
const { exec } = require('child_process');
exec('sh /Users/xiaofeng/Codinglife/feng/server/test.sh', (error, stdout, stderr) => {
if (error) {
console.error(`执行的错误: ${error}`);
return;
}
console.log(`stdout: ${stdout}`);
console.error(`stderr: ${stderr}`);
});

此处执行的脚本文件和上面的是完全一样的,但是我们可以看到输出内容是完整的。并没有进行截断,也就是说我们可以将它理解成,他将数据收集到一起。最终一起返回给我们。
除此之外还有一个和exec非常类似的方法,execFile这个方法的使用实际上是为了执行某个文件命令。例如我们使用node命令执行某个文件的时候,就可以使用execFile,除了入参不太一样,实际上使用并没有什么不同,但是,如果我们要执行某个文件的话。那么还是应该优先使用execFile的,它的效率会高于exec执行命令。
日常使用中还有一个fork方法, 他是为了node程序所产生的。它在正常执行某个node程序外,还加上了一个非常有趣的东西就是父子进程的通信通道。也就是说我们可以通过process.send()由子进程向父进程发送信息。也可以使用fork方法创建的实例同样使用send方法进行父向子传递信息。
简单总结一下
- 如果你执行的子进程程序是需要处理压缩几百兆,甚至更大的文件的程序,时间较长,任务较重。那么推荐你使用spawn。此处需要你辨别,这个程序是否是node是执行主体。也就是说是否需要将文件完全读入node内存再进行处理。
- 接上一条。如果你只是想获取某个程序处理的结果。例如你执行某个shell脚本。让它去压缩,打包某一种文件,最终获取结果时。推荐使用exec,它会将shell脚本所有的输出整理最终统一返回。
- 如果你想要执行的是某个文件,建议使用execFile,它可以一定程度上加快执行的速度,减少系统资源的使用。
- 如果你想要在一个node程序中执行另一个node程序。并且还希望他们可以互相通信的话。fork是你最优的选择。
最后,再强调一点,spawn是基于流的输出处理,他可以很轻松的处理大文件。但是它并不是不能用于收集每一段程序的执行内容。只是因为它的截断的不确定性,最好还是不要使用这个命令。