需求:爬取“理财大视野”网站的排名、代码、名称、市净率、市盈率等信息,并分别写入txt、excel和mysql
环境:python3.6.5
网站:http://www.dashiyetouzi.com/tools/value/Graham.php
查看html源码:信息在html中以table形式存在,每个股票信息是一行,存放在tr中,单元格信息存放在td中
因此思路为:通过id或者class查找table→查找tr→查找td
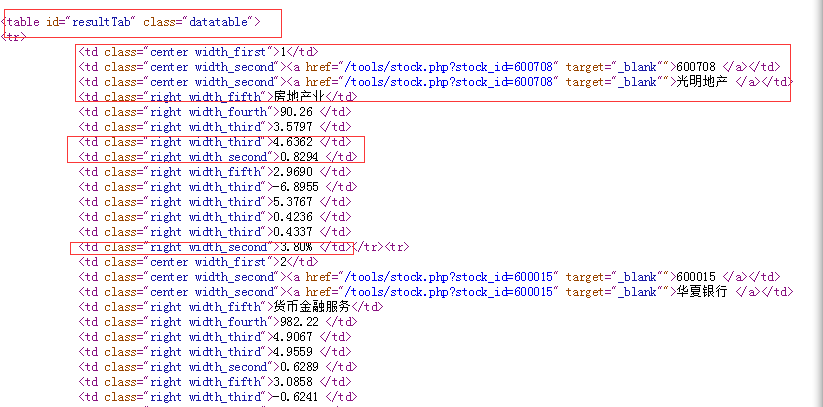
第三方库
1 from bs4 import BeautifulSoup 2 from urllib import request 3 import time 4 import xlrd 5 import xlwt 6 import pymysql
获取html源码
1 url = "http://www.dashiyetouzi.com/tools/value/Graham.php" 2 htmlData = request.urlopen(url).read().decode('utf-8') 3 soup = BeautifulSoup(htmlData, 'lxml') 4 #print(soup.prettify()) 5 allData = soup.find("table", {'class': 'datatable'})
遍历表格中的每一行进行查找
1 for tr in allData.find_all('tr'): 2 eachData = tr.find_all('td') 3 #print(eachData) 4 rank = eachData[0].string#排名 5 code = eachData[1].find('a').string#代码 6 name = eachData[2].find('a').string#名称 7 industry = eachData[3].string#行业 8 PE = eachData[6].string#市净率 9 PBV = eachData[7].string#市盈率 10 #返回类型不一样,get_text()返回的是字符串,末尾有空格。需要先去掉末尾的空格,再去掉百分号 11 GXL = eachData[-1].get_text().rstrip().strip('%')#股息率
股息率用string取的类型不是字符串,无法进行后续操作
将股息率大于4的结果保存成一位数组形式allIms。
同时写入txt文档,本次写入的方式是生成一个股票信息info立马写入(无需整合成数组eachIms),而不是最后整体写入,因此直接写到循环里面了
1 if float(GXL) > 4: 2 # 写入txt文件,循环写入 3 info = "排名:" + rank + ",代码:" + code + ",股票名称:" + name + ",所属行业:" + industry + ",市盈率:" + PE + ",市净率:" + PBV + ",股息率:" + GXL +' ' 4 #print(info,type(info)) 5 txtFile.writelines(info) 6 7 8 eachIms = [rank,code,name,industry,PE,PBV,GXL] 9 allIms.append(eachIms) 10 #print(eachIms) 11 12 #print(allIms) 13 txtFile.close()
输出结果: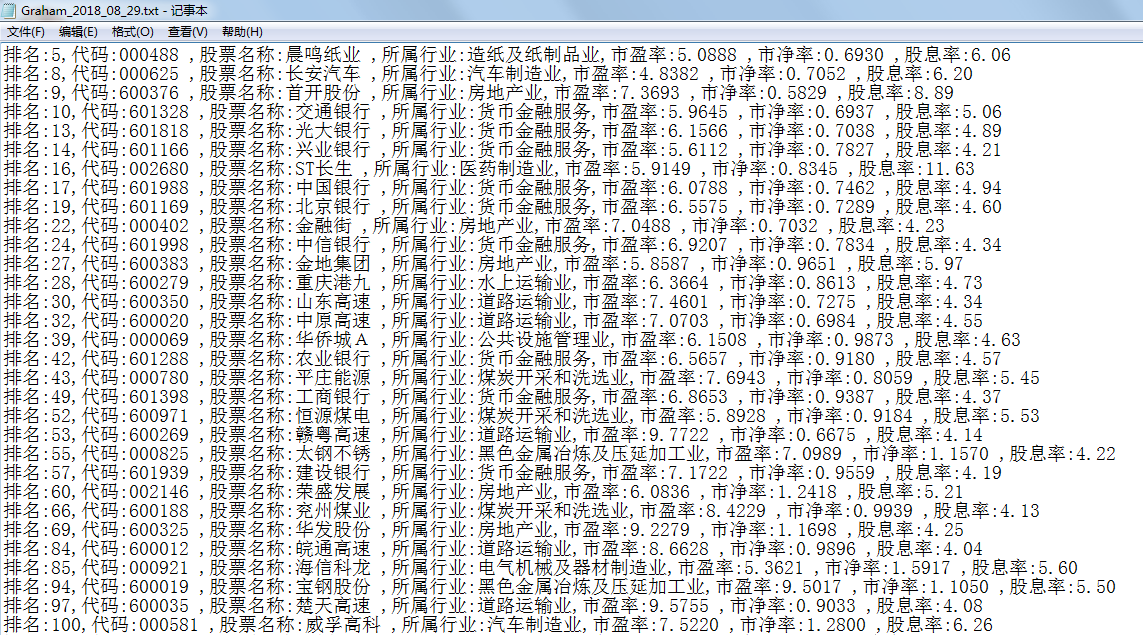
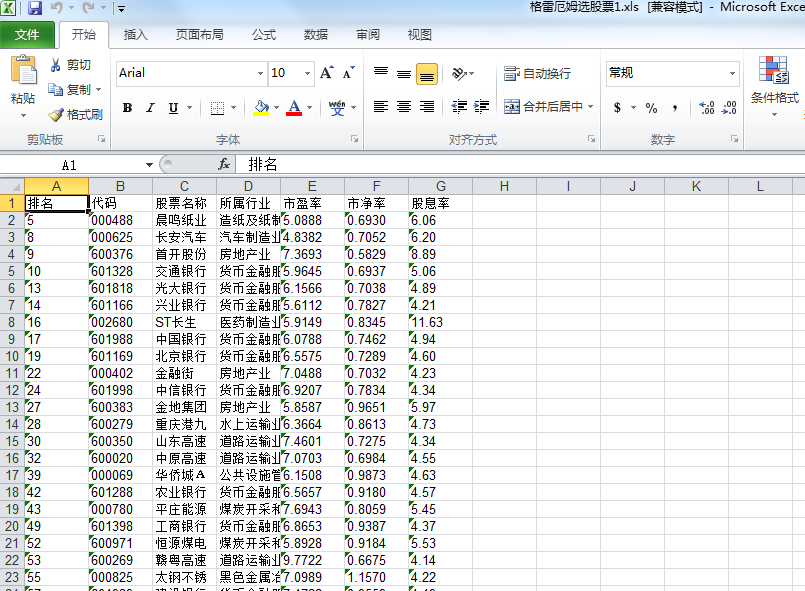
写入excel,python对excel支持的一版,插件对excel版本的支持也略有差别,本次采用xls这个格式,此次无法写覆盖
写入方法就是按照行坐标、列坐标循环写入
1 #写入excel文件,数据以二维数组的形式存放于allIms中,无法写覆盖 2 workbook = xlwt.Workbook(encoding='utf-8')# 创建工作簿 3 # 创建sheet 4 data_sheet = workbook.add_sheet('格雷厄姆选股票1')#表单的名字而不是excel文件名 5 title = ['排名','代码','股票名称','所属行业','市盈率','市净率','股息率'] 6 for j in range(len(title)):#先写入标题行 7 data_sheet.write(0, j, title[j]) 8 #print(len(allIms),len(title)) 9 10 for i in range(len(allIms)):#i表示行数 11 for j in range(len(title)):#j表示列数 12 data_sheet.write(i+1,j, allIms[i][j])#行坐标、列坐标、数据 13 14 workbook.save('格雷厄姆选股票1.xls')#文件名
输出结果:
写入数据库mysql,首先在mysql中新建一个库graham,然后测试python与mysql连通性,这里采用返回数据库版本的形式验证
1 #测试与mysql中的graham库的连通性 2 import pymysql 3 db= pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',database='graham',charset='utf8') 4 cur= db.cursor()#SQLServer的游标 5 cur.execute("SELECT VERSION()") 6 data = cur.fetchone()#读一行 7 print(data)
可以在数据库中创建表单,也可在python中创建,这里我直接在navicat中创建了,python只是写入具体数据
1 #写入数据库mysql,数据以二维数组的形式存放于allIms中 2 #提前新建数据graham和字段,字段属性需要与eachIms中的各个属性一致(本程序中均为字符串) 3 db= pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',database='graham',charset='utf8') 4 cur= db.cursor()#SQLServer的游标 5 sql=""" 6 INSERT INTO 格雷厄姆选股票1(排名,代码, 股票名称, 所属行业, 市盈率,市净率,股息率) 7 VALUES (%s,%s,%s,%s,%s,%s,%s) 8 """ 9 for i in allIms: 10 cur.execute(sql,i)#执行数据库相应的语句 11 db.commit() 12 db.close()
输出结果:
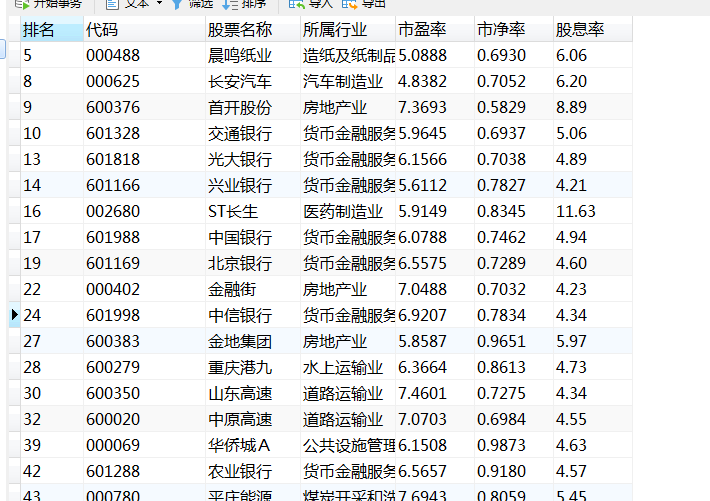
源代码:
1 """ 2 通过理财大视野,获取股票的名称、代码、行业、市净率、市盈率、股息率 3 并将股息率大于4%的结果分别写入txt、excel和mysql 4 """ 5 6 from bs4 import BeautifulSoup 7 from urllib import request 8 import time 9 import xlrd 10 import xlwt 11 import pymysql 12 13 url = "http://www.dashiyetouzi.com/tools/value/Graham.php" 14 htmlData = request.urlopen(url).read().decode('utf-8') 15 soup = BeautifulSoup(htmlData, 'lxml') 16 #print(soup.prettify()) 17 allData = soup.find("table", {'class': 'datatable'}) 18 19 time = time.strftime('%Y_%m_%d', time.localtime(time.time()))#获取当前时间年_月_日 20 filename = "Graham_" + time # Graham格雷厄姆 21 txtFile = open(filename + ".txt", 'w') 22 allIms = [] 23 for tr in allData.find_all('tr'): 24 #eachData是每一行信息(一位数组) 25 eachData = tr.find_all('td') 26 #print(eachData) 27 rank = eachData[0].string#排名 28 code = eachData[1].find('a').string#代码 29 name = eachData[2].find('a').string#名称 30 industry = eachData[3].string#行业 31 PE = eachData[6].string#市净率 32 PBV = eachData[7].string#市盈率 33 #返回类型不一样,get_text()返回的是字符串,末尾有空格。需要先去掉末尾的空格,再去掉百分号 34 GXL = eachData[-1].get_text().rstrip().strip('%')#股息率 35 36 if float(GXL) > 4: 37 # 写入txt文件,循环写入 38 info = "排名:" + rank + ",代码:" + code + ",股票名称:" + name + ",所属行业:" + industry + ",市盈率:" + PE + ",市净率:" + PBV + ",股息率:" + GXL +' ' 39 #print(info,type(info)) 40 txtFile.writelines(info) 41 42 eachIms = [rank,code,name,industry,PE,PBV,GXL]#每条股票信息,一位数组 43 allIms.append(eachIms)#所有股票信息,二维数组通过append()整合 44 #print(eachIms) 45 print(allIms) 46 txtFile.close() 47 48 49 50 #写入excel文件,数据以二维数组的形式存放于allIms中,无法写覆盖 51 workbook = xlwt.Workbook(encoding='utf-8')# 创建工作簿 52 # 创建sheet 53 data_sheet = workbook.add_sheet('格雷厄姆选股票1')#表单的名字而不是excel文件名 54 title = ['排名','代码','股票名称','所属行业','市盈率','市净率','股息率'] 55 for j in range(len(title)):#先写入标题行 56 data_sheet.write(0, j, title[j]) 57 #print(len(allIms),len(title)) 58 59 for i in range(len(allIms)):#i表示行数 60 for j in range(len(title)):#j表示列数 61 data_sheet.write(i+1,j, allIms[i][j])#行坐标、列坐标、数据 62 63 workbook.save('格雷厄姆选股票1.xls')#文件名 64 65 #写入数据库mysql,数据以二维数组的形式存放于allIms中 66 #提前新建数据graham和字段,字段属性需要与eachIms中的各个属性一致(本程序中均为字符串) 67 db= pymysql.connect(host='127.0.0.1',port=3306,user='root',password='',database='graham',charset='utf8') 68 cur= db.cursor()#SQLServer的游标 69 sql=""" 70 INSERT INTO 格雷厄姆选股票1(排名,代码, 股票名称, 所属行业, 市盈率,市净率,股息率) 71 VALUES (%s,%s,%s,%s,%s,%s,%s) 72 """ 73 for i in allIms: 74 cur.execute(sql,i)#执行数据库相应的语句 75 db.commit() 76 db.close()