Python解释器
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
CPython
当我们从Python官方网站下载并安装好Python 3.x后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
Python的交互模式和直接运行.py文件有什么区别呢?
直接输入python进入交互模式,相当于启动了Python解释器,但是等待你一行一行地输入源代码,每输入一行就执行一行。
直接运行.py文件相当于启动了Python解释器,然后一次性把.py文件的源代码给执行了,你是没有机会以交互的方式输入源代码的。
Python的语法比较简单,采用缩进方式
当语句以冒号:结尾时,缩进的语句视为代码块。
缩进有利有弊。好处是强迫你写出格式化的代码,但没有规定缩进是几个空格还是Tab。
缩进的坏处就是“复制-粘贴”功能失效了,这是最坑爹的地方。当你重构代码时,粘贴过去的代码必须重新检查缩进是否正确。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
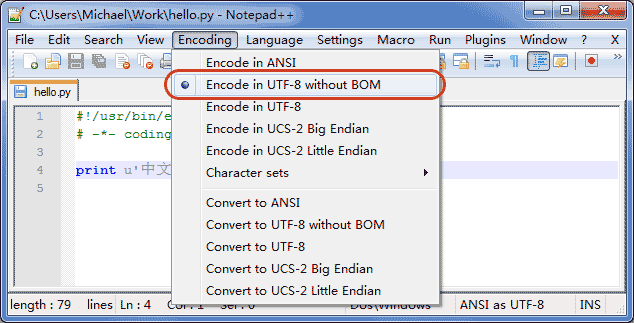
windows对于utf-8编码的文件自带BOM,但是其他系统utf-8编码默认不带BOM。
这就造成在某些情况下字符解码会出现问题,比如python自带的json在读取在window下编码得来的utf-8文件时,会报如下错误:
ValueError: No JSON object could be decoded
一句话总结:BOM对于utf-16和utf-32有用,对于utf-8没啥大用。。所以能去掉就去掉好了。。