前言
该文章主要介绍面对AJAX的网页如何爬去信息,主要作用是适合刚入门爬虫查看学习
修改时间:20191219
天象独行
首先,我们先介绍一下什么是AJAX,AJAX是与服务器交换数据并跟新部分网页的艺术,整个过程并没有加载整个页面。下面我们直接举例:
1;确定爬虫目标,这里选择豆瓣电影来举例,这里我们点击“加载更多”发现在网页局部发生变化。

2;使用抓包工具抓取数据:

3;这里主要分析参数page_limit,以及page_start,经过分析,我们发现,page_limit参数表示需要获取电影的数目。page_start参数控制页面显示的页数。下面我们来构建爬虫。
我们先设定算法,计算page_limit以及page_start关系。

4;设定请求地址,设定GET字典传参,请求头字典
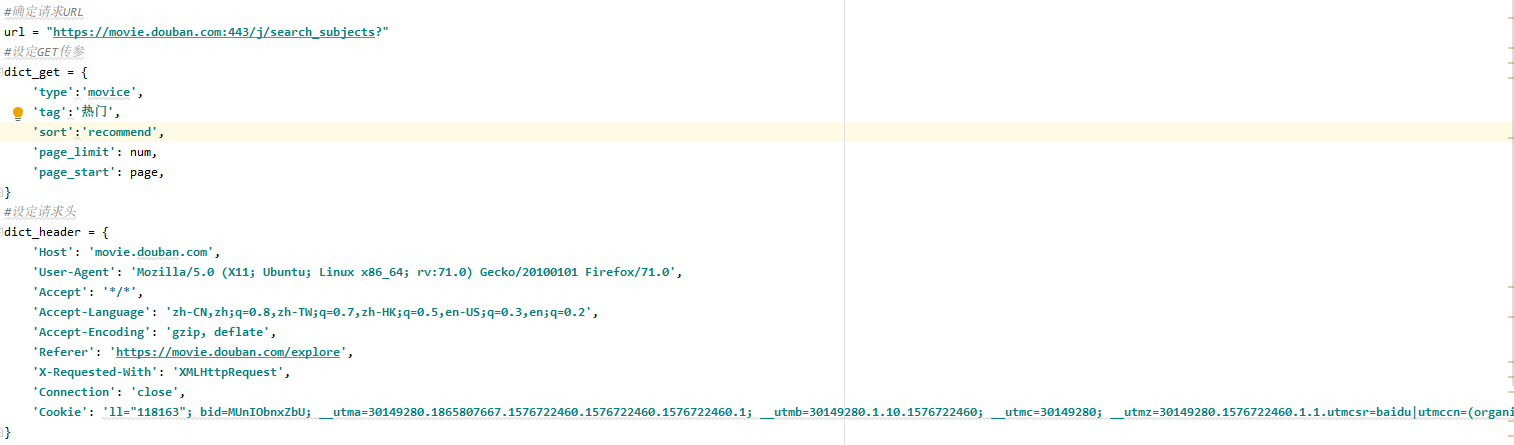
5;拼接URL,构建请求对象,发送请求,输出请求数据