Spark学习笔记0——简单了解和技术架构
笔记摘抄自 [美] Holden Karau 等著的《Spark快速大数据分析》
什么是Spark
Spark 是一个用来实现快速而通用的集群计算的平台。
- 扩展了广泛使用的MapReduce 计算模型
- 能够在内存中进行计算
- 一个统一的框架简单而低耗地整合各种处理流程
- 接口非常丰富
技术架构和软件栈
Spark 的核心是一个对由很多计算任务组成的、运行在多个工作机器或者是一个计算集群上的应用进行调度、分发以及监控的计算引擎
Spark 项目还包含多个紧密集成的组件,这些组件关系密切并且可以相互调用
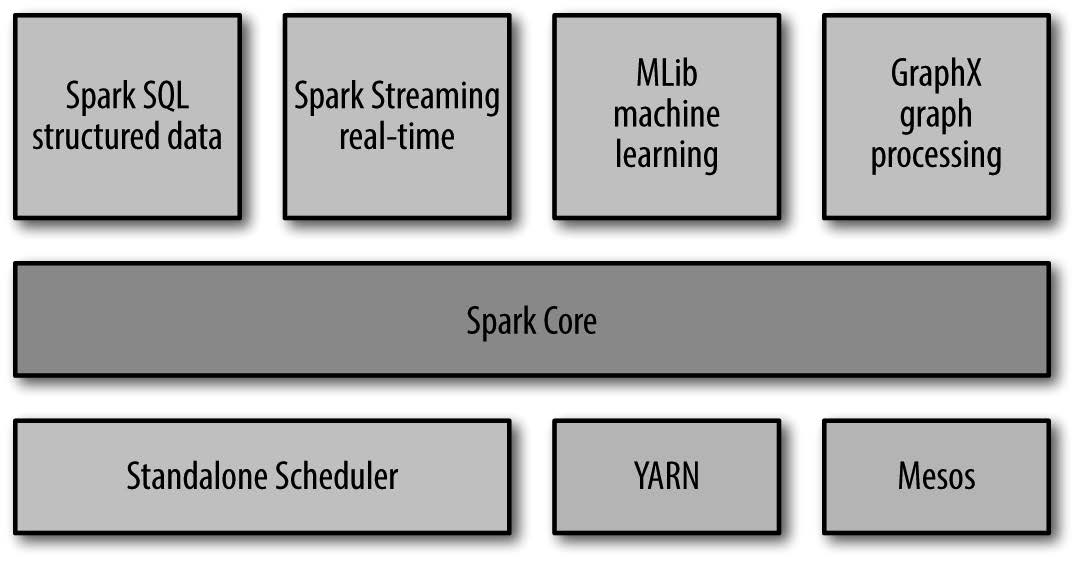
各组件间密切结合的设计原理的优点:
- 软件栈中所有的程序库和高级组件都可以从下层的改进中获益
- 只需要一套软件系统,运行整个软件栈的代价变小了
- 能够构建出无缝整合不同处理模型的应用(例如机器学习和数据分析同时进行)
Spark Core
- Spark Core 实现了Spark 的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块
- Spark Core 中包含了对 RDD[1] 的 API 定义
Spark SQL
Spark 用来操作结构化数据的程序包
- 可以使用 SQL 和 Apache Hive 版本的SQL 方言(HQL)来查询数据
- 支持多种数据源(比如Hive 表、Parquet 以及JSON 等)
- 支持开发者将SQL 和传统的 RDD 编程的数据操作方式相结合,使用 Python、Java 或 Scala 在单个应用中同时使用 SQL 和复杂的数据分析
Spark Streaming
Spark Streaming 是Spark 提供的对实时数据进行流[2]式计算的组件
- Spark Streaming 提供了用来操作数据流的API,并且与Spark Core 中的RDD API 高度对应
- 从底层设计来看,Spark Streaming 支持与 Spark Core 同级别的容错性、吞吐量以及可伸缩性
MLlib
一个提供常见的机器学习(ML)功能的程序库
- MLlib 提供了很多种机器学习算法
- 提供了一些更底层的机器学习原语(包括一个通用的梯度下降优化算法)
P.s. 所有这些方法都被设计为可以在集群上轻松伸缩的架构
GraphX
GraphX 是用来操作图(比如社交网络的朋友关系图)的程序库
- 可以进行并行的图计算
- 扩展了Spark 的RDD API,能用来创建一个顶点和边都包含任意属性的有向图
- 支持针对图的各种操作以及一些常用图算法
集群管理器
- Spark 支持在各种集群管理器(cluster manager)上运行,包括Hadoop YARN、Apache Mesos
- Spark 自带的一个简易调度器,叫作独立调度器
受众
- 数据科学家——数据科学应用
- 工程师——数据处理应用
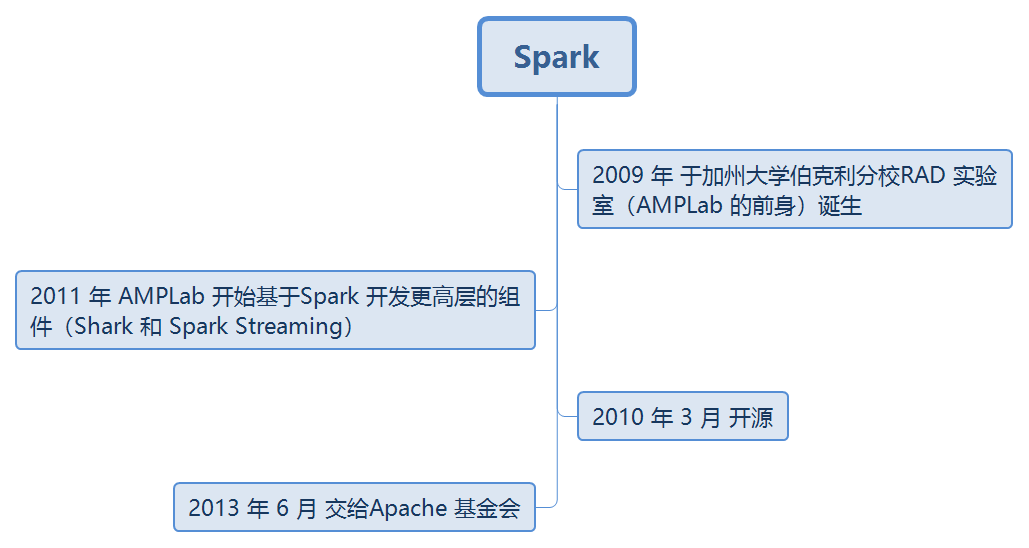
起源和发展