原地址:https://zhuanlan.zhihu.com/p/127972563
回归问题是什么
回归问题是机器学习三大基本模型中很重要的一环,其功能是建模和分析变量之间的关系。
回归问题多用来预测一个具体的数值,如预测房价、未来的天气情况等等。例如我们根据一个地区的若干年的PM2.5数值变化来估计某一天该地区的PM2.5值大小,预测值与当天实际数值大小越接近,回归分析算法的可信度越高。
面对一个回归问题,我们可简要描述其求解流程:
- 选定训练模型,即我们为程序选定一个求解框架,如线性回归模型(Linear Regression)等。
- 导入训练集 train_set,即给模型提供大量可供学习参考的正确数据。
- 选择合适的学习算法,通过训练集中大量输入输出结果让程序不断优化输入数据与输出数据间的关联性,从而提升模型的预测准确度。
- 在训练结束后即可让模型预测结果,我们为程序提供一组新的输入数据,模型根据训练集的学习成果来预测这组输入对应的输出值。
在机器学习中,回归问题求解的每一个步骤具体是怎样实现的呢?
回归问题求解
步骤一:模型的选取 (Model Selection)
在一个回归问题中,很显然模型选择和好坏会直接关系到将来预测结果的接近程度,举个例子:如果将一组按二次函数关系分布的数据用线性关系拟合的结果偏差一定会相对较大。
常见的模型有两种:
- 线性模型(Linear Model):
- 多项式模型(Polynomial Model):
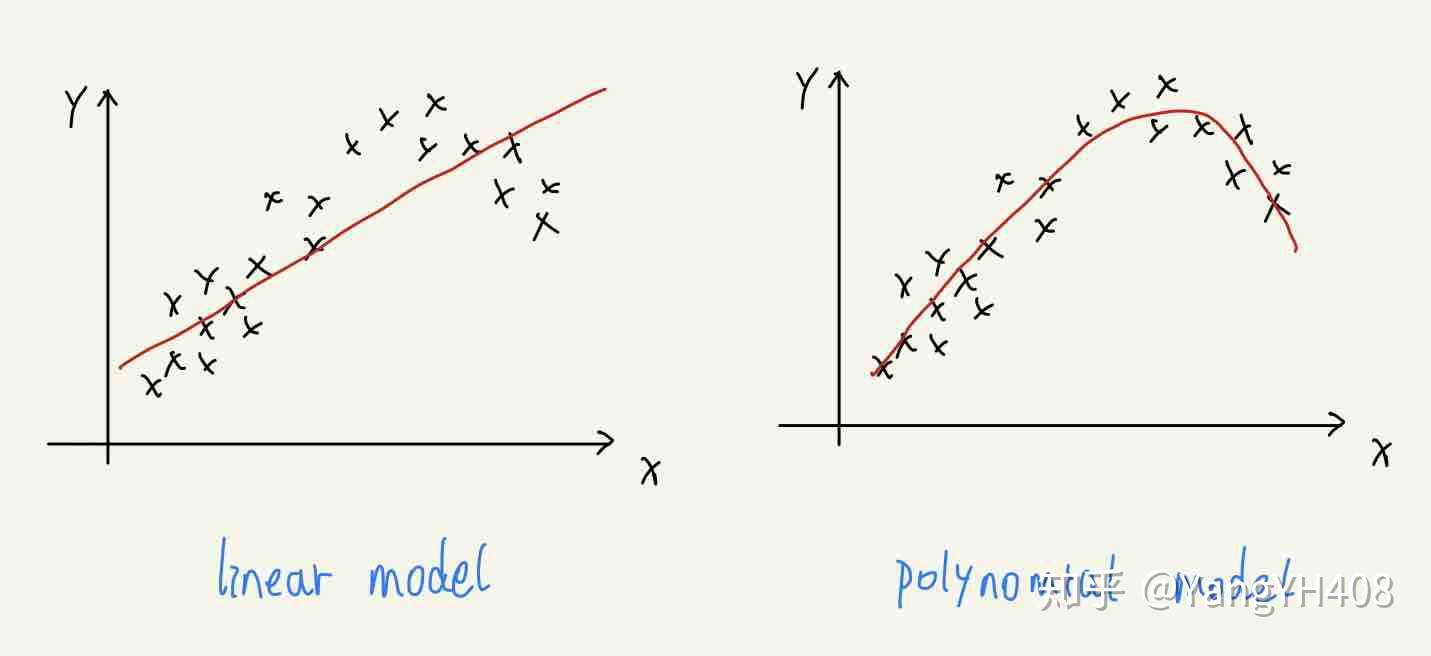
对于训练集而言,特征的次数越高,拟合所涵盖的范围越广,相应对于训练集的预测也越准确。然而,这并非说明方程越复杂预测效果越好,因为最终评价模型好坏还是取决于对测试集(test_set)的预测结果,过于复杂的模型可能产生过拟合问题,这一点会在下文介绍。
步骤二:数据处理 (Feature Scaling)
构造矩阵
为了便于后续计算,我们要将数据集内的数据进行整理。 根据矩阵的运算性质:

我们需要把训练集(train_set)中输入输出数据转化成相应的矩阵形式,输出数据为列向量,输入数据每行排布计算一个输出值所需要的m个变量。
数据标准化
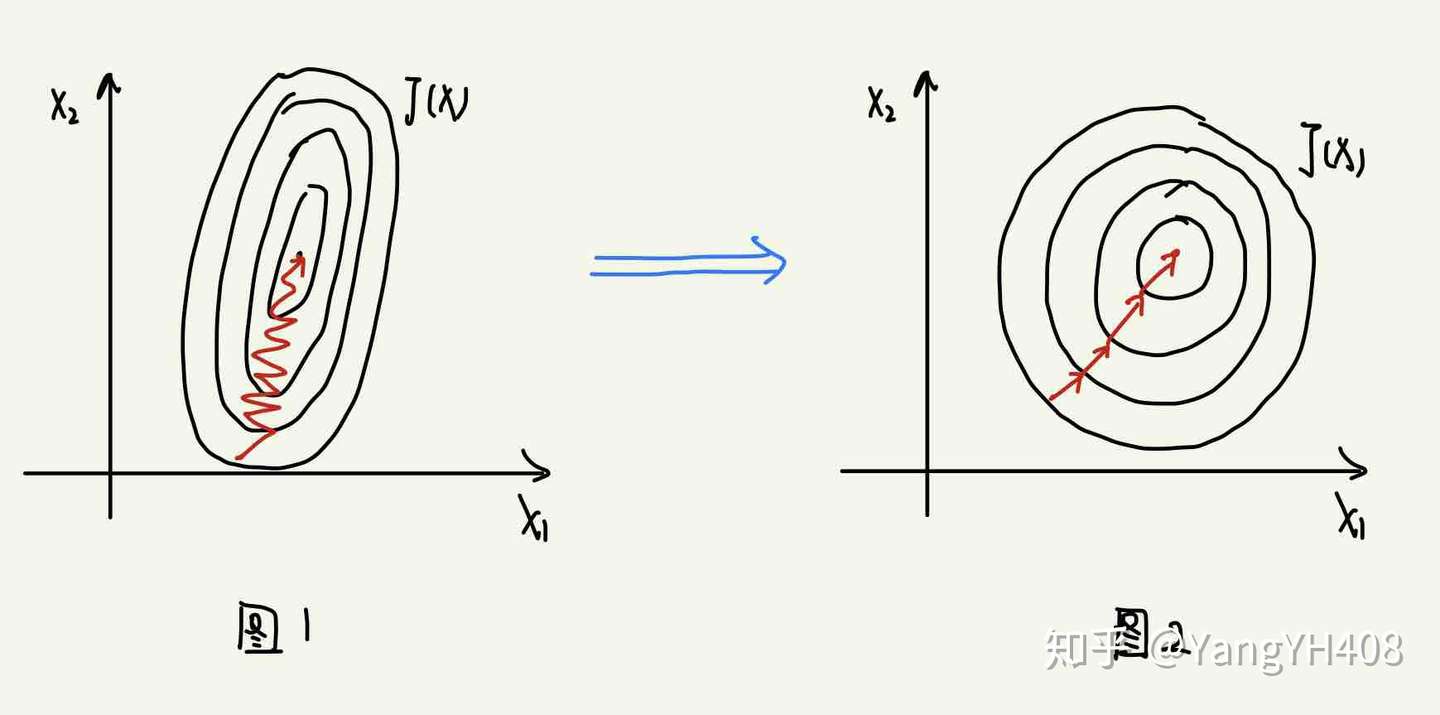
如果两特征数值差异较大时,我们在计算梯度(之后会介绍)时将会如下图1所示,过程曲折耗时。为了消除此影响,保证每个变量对于预测结果的影响权重相同,我们通常将特征量化到统一的区间内,使得特征梯度变为图2所示的状态,量化的方法主要有两种:
- 归一化(Normalization)
把数据转化为区间在[0,1]的分布:
- 标准化(Standardization)
把数据转化为区间在[-1,1]且服从标准正态分布的值:
其中 代表特征的均值,
代表特征的标准差
mean_x = np.mean(x, axis = 0)
std_x = np.std(x, axis = 0)
for i in range(len(x)):
for j in range(len(x[0])):
if std_x[j] != 0:
x[i][j] = (x[i][j] - mean_x[j]) / std_x[j]⚠️注意:我们在对测试集做特征缩放时要使用先前对训练集进行特征缩放时所使用的参数 ,而不能根据测试集另算一组均值方差做特征缩放。
步骤三:损失函数 (Loss Funtion)
何谓损失函数?说白了就是评价模型所产生的预测结果的一个函数,损失函数的反馈值是机器学习调整参数的重要依据。对于回归问题,我们通常采用以下几种损失函数:
- 均方根误差(RMSE)
均方根误差容易受异常点(误差很大的点)影响,容易朝减小异常点误差的方向行进而牺牲总体性能。
- 平均绝对值误差(MAE)
平均绝对值误差的导数是常数,不利于梯度下降法更新;同时该函数在0处不可微。
- 平滑平均绝对误差(HuberLoss)
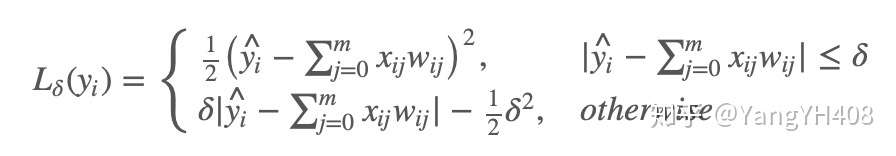
Huber损失结合了MSE和MAE的优点,对异常点不会特别敏感同时在0处也可微。但是,Huber损失的问题是我们需要不断调整超参数。
步骤四(一):正规方程(Normal Equation)
所谓正规方程,就是用解析法求参数向量w,可由线性回归损失函数推得:
使用正规方程需要注意的问题:
- 正规方程仅适用于线性回归模型,不可乱用;
- 在使用正规方程求解时无需进行特征缩放;
- 若
为奇异矩阵则无法求其逆矩阵,使用正则化的方法可以保证矩阵可逆,后文会介绍;
- 使用正规方程时应该注意当特征数量规模大于10000时,
求其逆矩阵的时间复杂度会很高,不宜用正规方程求解。
步骤四(二):梯度下降 (Gradient Descent)
为了获得更好的模型预测结果,我们要让损失函数L(w)的值尽可能小,所以我们希望回归系数w可以向减小损失函数值的方向移动,即:
由导数知识我们不难发现,要使损失函数L(w)的值减小,我们只需让回归系数向与当前位置偏导数符号相反的方向更新即可,如下图所示:
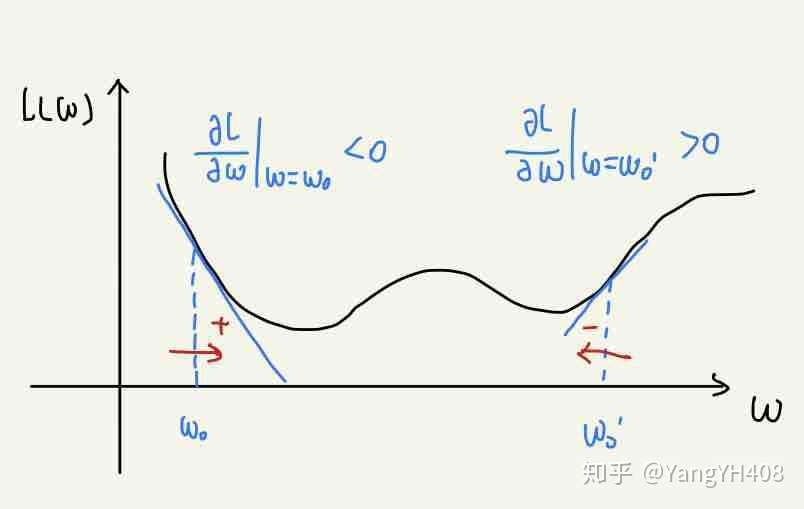
于是,我们可以得到最基本的梯度下降算法的更新步骤:
其中,超参数 代表学习速率(learning_rate),即单次更新步长。
值的选择需谨慎,如果太小更新速率太慢则很难到达;如果太大则容易直接越过极值点。
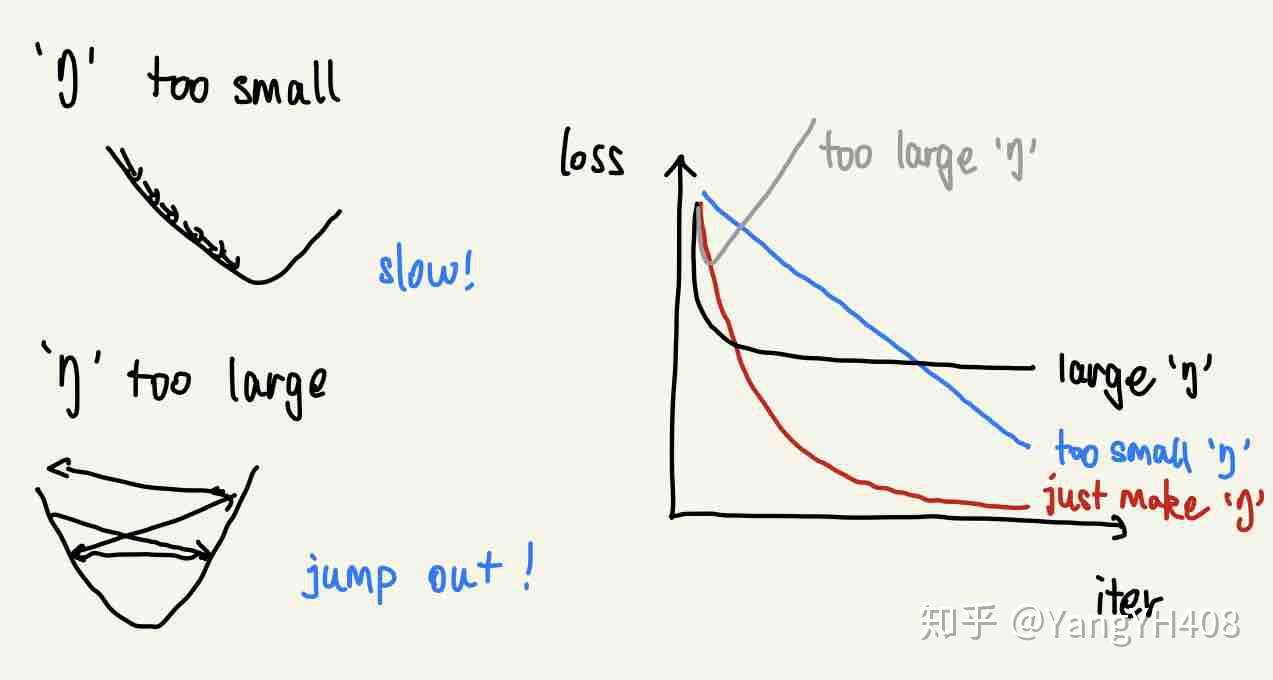
小批量梯度下降(MBGD)
- 区别于批量梯度下降(BGD)每次迭代使用全部样本更新梯度,MBGD每次只从样本中随机抽取一小批(m个)样本进行训练。
- MBGD算法描述:

动量加速梯度下降
- 动量方法用于加速学习,特别是处理高曲率、小但一致的梯度,或是带噪声的梯度。
- 速度v累计了梯度元素
,超参数
决定了之前梯度贡献的衰减率。
- 衰减率为
时对应着最大速度为普通梯度下降的
倍。
- 带动量的算法描述:

Adagrad
- 独立地适应所有模型参数的学习率,具有较大偏导的参数相应有一个较大的学习率,而具有小偏导的参数则对应一个较小的学习率。
- 缺点:从训练开始时积累梯度平方可能会导致有效学习率过早和过量的减小,即提前收敛。
- Adagrad算法描述:

- Adagrad代码实现:
# adagrad即累计平方梯度
adagrad = np.zeros([dim, 1])
eps = 1e-10
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power((np.dot(x, w) - y), 2))/471/12)
if(t % 1000 == 0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y)
adagrad += gradient ** 2
w = w - learning_rate * gradient / np.sqrt(adagrad + eps)RMSProp
- RMSProp是对Adagrad算法的改进,它使用指数衰减平均以丢弃遥远过去的历史,使其能够在找到凸碗状结构后快速收敛。
- 指数加权平均:各数值的加权而随时间而指数式递减,越近期的数据加权越重
- RMSProp算法描述:
建议初始值:

- RMSProp代码实现:
learning_rate = 0.001
rho = 0.9
eps = 1e-10
rsmp = np.zeros([dim, 1])
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power((np.dot(x, w) - y), 2))/471/12)
if(t % 100 == 0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y)
rsmp = rho * rsmp + (1 - rho) * gradient ** 2
w = w - learning_rate * gradient / np.sqrt(rsmp + eps)Adam
- Adam是对RSMProp的进一步改进,它除了引入历史梯度平方的指数衰减平均(r)外,还保留了历史梯度的指数衰减平均(s),相当于动量。
- Adam算法描述:
建议初始值:

- Adam代码实现:
adam_v = np.zeros([dim, 1])
adam_s = np.zeros([dim, 1])
rho1 = 0.9
rho2 = 0.999
learning_rate = 0.001
eps = 1e-10
for t in range(iter_time):
loss = np.sqrt(np.sum(np.power((np.dot(x, w) - y), 2))/len(x))
if(t % 1000 == 0):
print(str(t) + ":" + str(loss))
gradient = 2 * np.dot(x.transpose(), np.dot(x, w) - y)
adam_v = rho1 * adam_v + (1 - rho1) * gradient
adam_v_correct = adam_v / (1 - np.power(rho1, t+1))
adam_s = rho2 * adam_s + (1 - rho2) * gradient * gradient
adam_s_correct = adam_s / (1 - np.power(rho2, t+1))
w = w - learning_rate * adam_v_correct / (np.sqrt(adam_s_correct) + eps)回归问题错误分析
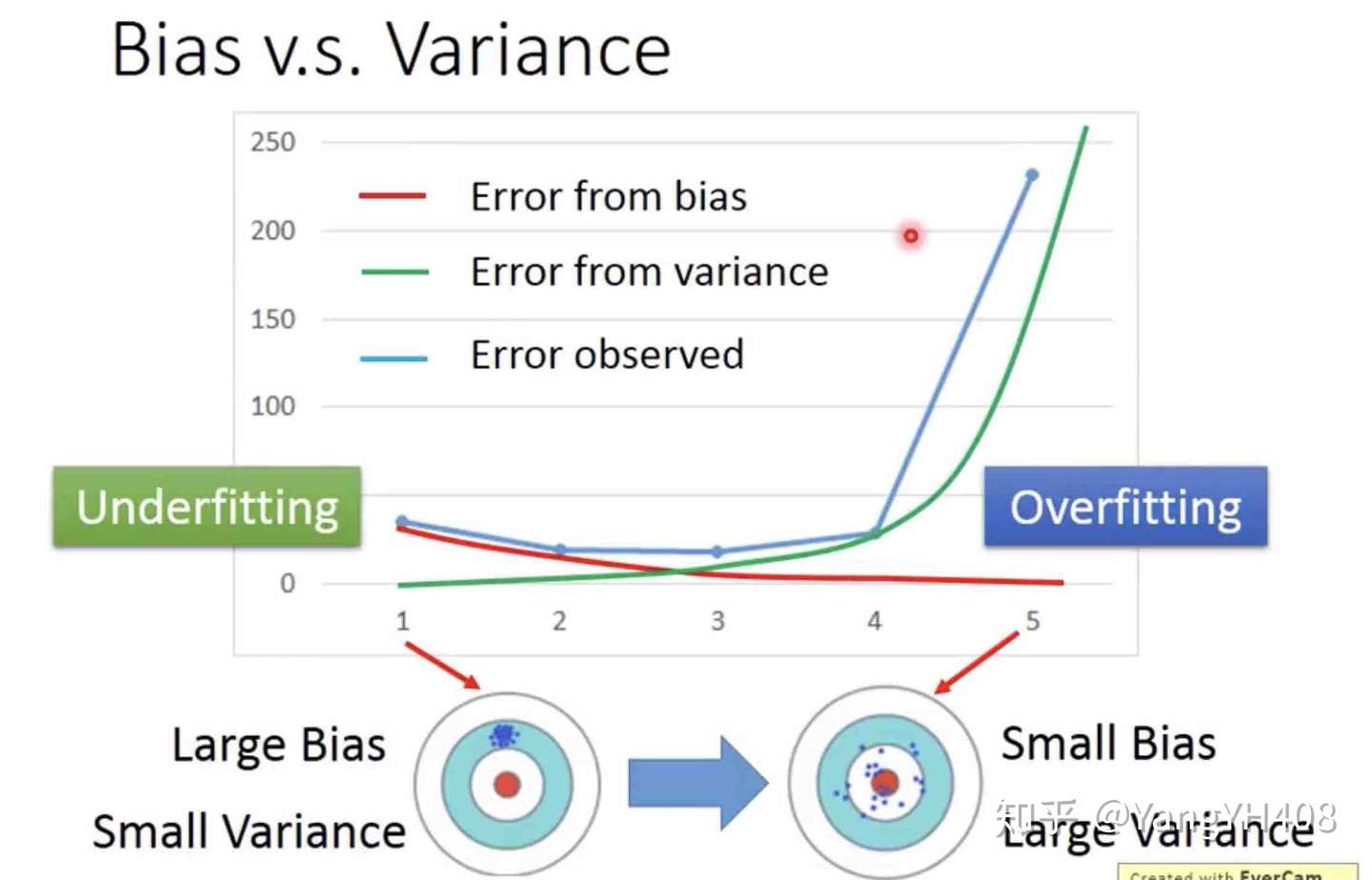
引起实际值 与预测值
之间存在误差的因素有两点,一个是偏差值(bias),另一个则是方差(varience)。而由这两类偏差引起误差的相对大小可以将错误拟合结果分为两类:欠拟合(underfitting)和过拟合(overfitting),如下图所示:
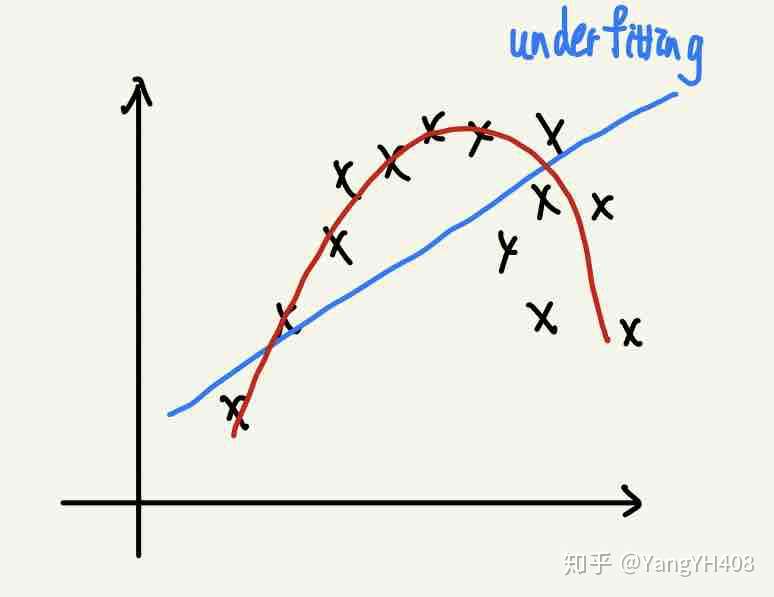
欠拟合
- 诊断:预测误差在训练集就比较大,明显由bias引起。
- 处理:
- 增加特征数量
- 选用更复杂的模型(线性模型变高次多项式模型)
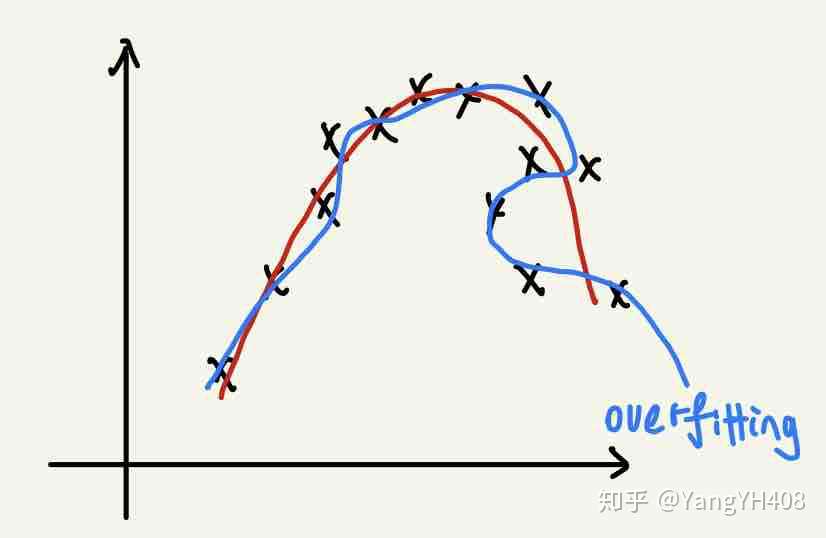
过拟合
- 诊断:预测误差在训练集较小,但在测试集中应用时显著增加,明显由varience引起。
- 处理:
- 减少特征数量
- 获取或者构造更多训练数据
- 正则化(regularization)
- 模型过于复杂,选取合适模型
正则化(regularization)
实际上,特征参数的值w越小,通常对应于越光滑的函数,也就是更加简单的函数,他们对于输入数据的变化不敏感,因此,就不易发生过拟合的问题。于是,我们考虑在损失函数内添加一项来满足尽可能将特征参数的值缩小。
其中 称为正则化项,
称为正则化参数。正则化参数的选择也要恰当,过大会导致欠拟合,过小仍会出现过拟合现象,具体值要根据实验结果确定。

对于正规方程,其正则化方法为:
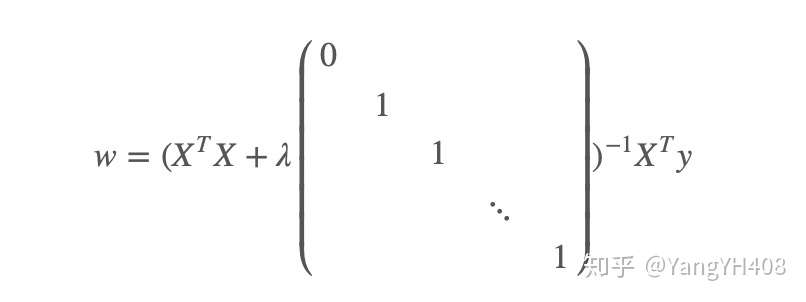
在 的情况下,可以保证括号内的矩阵一定是可逆的。(具体证明过程仍待学习)
模型选取
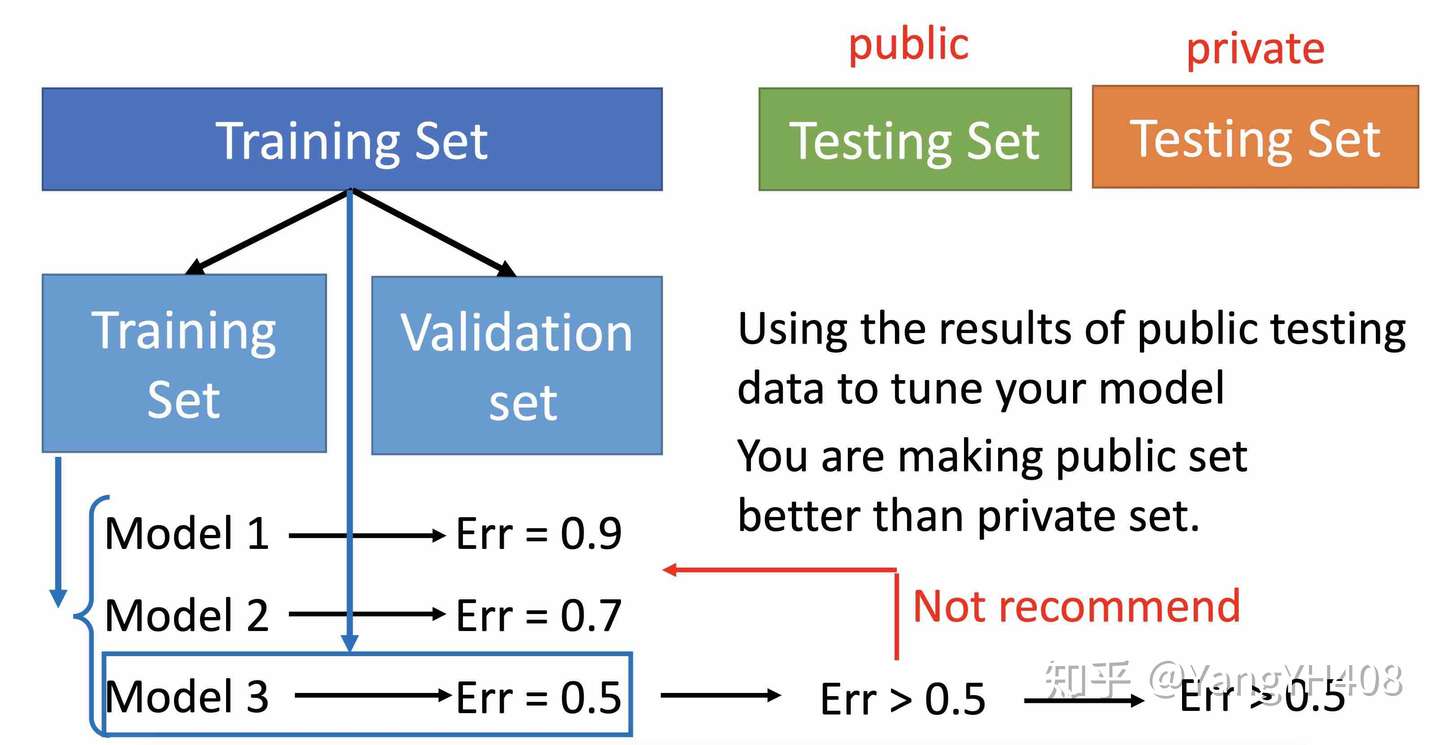
由于bias和varience两种误差是此消彼长的关系,因此我们要选择一个合适的模型平衡这两种误差之和。那么如何选择这个合适的模型呢?我们通常采用交叉验证(cross_validation)的方法。
交叉验证的具体做法为:
- 将训练集再分为子训练集和验证集;
- 用子训练集训练模型,验证集来测试模型;
- 选取测试结果最好的模型,用原训练集重新训练;
- 将训练结果应用于测试集。
import math
x_train_set = x[: math.floor(len(x) * 0.8), :]
y_train_set = y[: math.floor(len(y) * 0.8), :]
x_validation = x[math.floor(len(x) * 0.8): , :]
y_validation = y[math.floor(len(y) * 0.8): , :]=