实验目的
1.了解Hadoop自带的几种输出格式
2.准确理解MapReduce自定义输出格式的设计原理
3.熟练掌握MapReduce自定义输出格式程序代码编写
4.培养自己编写MapReduce自定义输出格式程序代码解决问题的能力
实验原理
1.输出格式:提供给OutputCollector的键值对会被写到输出文件中,写入的方式由输出格式控制。OutputFormat的功能跟前面描述的InputFormat类很像,Hadoop提供的OutputFormat的实例会把文件写在本地磁盘或HDFS上。在不做设置的情况下,计算结果会以part-000*输出成多个文件,并且输出的文件数量和reduce数量一样,文件内容格式也不能随心所欲。每一个reducer会把结果输出写在公共文件夹中一个单独的文件内,这些文件的命名一般是part-nnnnn,nnnnn是关联到某个reduce任务的partition的id,输出文件夹通过FileOutputFormat.setOutputPath() 来设置。你可以通过具体MapReduce作业的JobConf对象的setOutputFormat()方法来设置具体用到的输出格式。下表给出了已提供的输出格式:
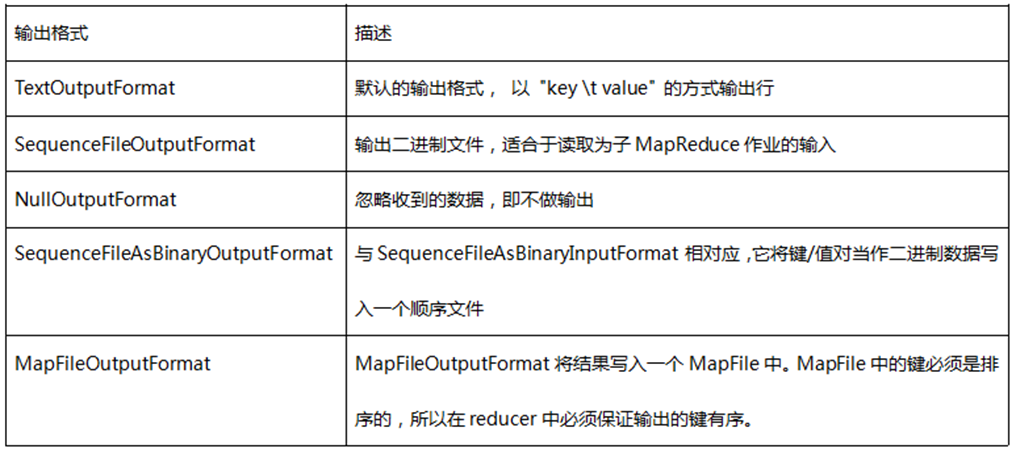
Hadoop提供了一些OutputFormat实例用于写入文件,基本的(默认的)实例是TextOutputFormat,它会以一行一个键值对的方式把数据写入一个文本文件里。这样后面的MapReduce任务就可以通过KeyValueInputFormat类简单的重新读取所需的输入数据了,而且也适合于人的阅读。还有一个更适合于在MapReduce作业间使用的中间格式,那就是SequenceFileOutputFormat,它可以快速的序列化任意的数据类型到文件中,而对应SequenceFileInputFormat则会把文件反序列化为相同的类型并提交为下一个Mapper的输入数据,方式和前一个Reducer的生成方式一样。NullOutputFormat不会生成输出文件并丢弃任何通过OutputCollector传递给它的键值对,如果你在要reduce()方法中显式的写你自己的输出文件并且不想Hadoop框架输出额外的空输出文件,那这个类是很有用的。
RecordWriter:这个跟InputFormat中通过RecordReader读取单个记录的实现很相似,OutputFormat类是RecordWriter对象的工厂方法,用来把单个的记录写到文件中,就像是OuputFormat直接写入的一样。
2.与IntputFormat相似, 当面对一些特殊情况时,如想要Reduce支持多个输出,这时Hadoop本身提供的TextOutputFormat、SequenceFileOutputFormat、NullOutputFormat等肯定是无法满足我们的需求,这时我们需要自定义输出数据格式。类似输入数据格式,自定义输出数据格式同样可以参考下面的步骤:
(1) 自定义一个继承OutputFormat的类,不过一般继承FileOutputFormat即可;
(2)实现其getRecordWriter方法,返回一个RecordWriter类型;
(3)自定义一个继承RecordWriter的类,定义其write方法,针对每个<key,value>写入文件数据;
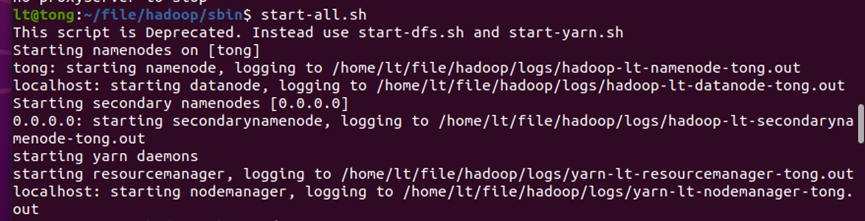
启动hadoop
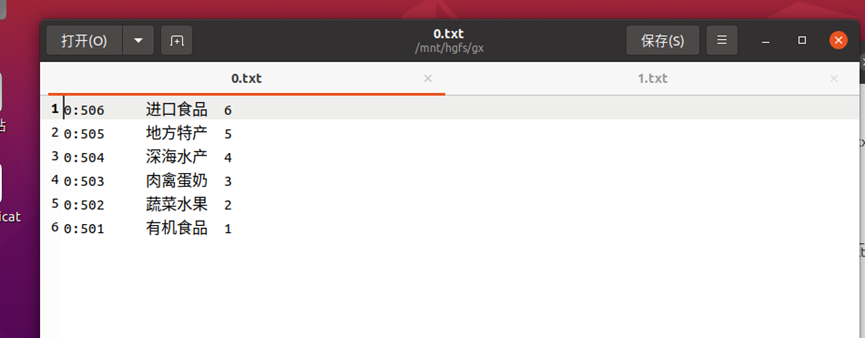
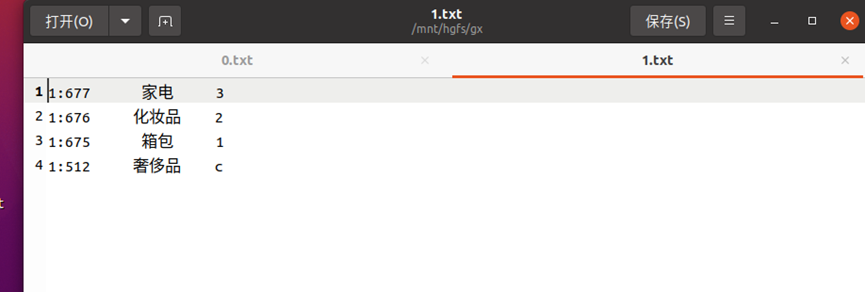
生成文件

创建项目、写入代码
运行

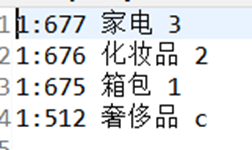
结果: