实验目的
1.了解倒排索引的使用场景
2.准确理解倒排索引的设计原理
3.熟练掌握MapReduce倒排索引程序代码编写
实验原理
"倒排索引"是文档检索系统中最常用的数据结构,被广泛地应用于全文搜索引擎。它主要是用来存储某个单词(或词组)在一个文档或一组文档中的存储位置的映射,即提供了一种根据内容来查找文档的方式。由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引(Inverted Index)。
实现"倒排索引"主要关注的信息为:单词、文档URL及词频。
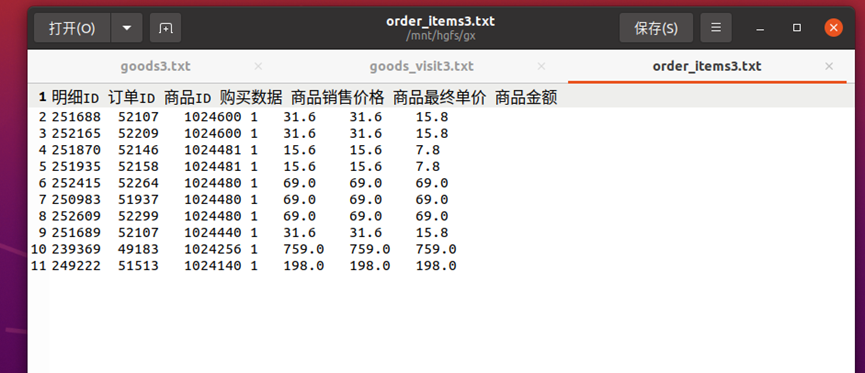
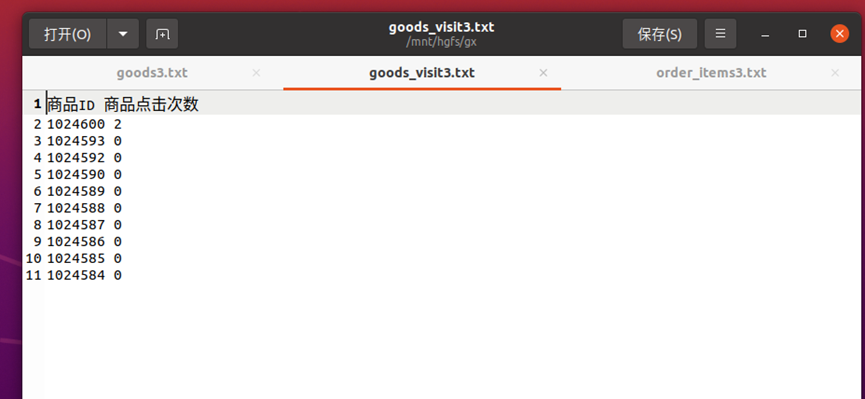
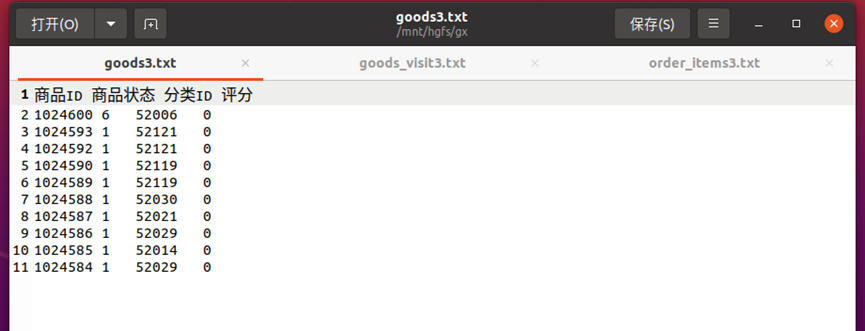
下面以本实验goods3、goods_visit3、order_items3三张表的数据为例,根据MapReduce的处理过程给出倒排索引的设计思路:
(1)Map过程
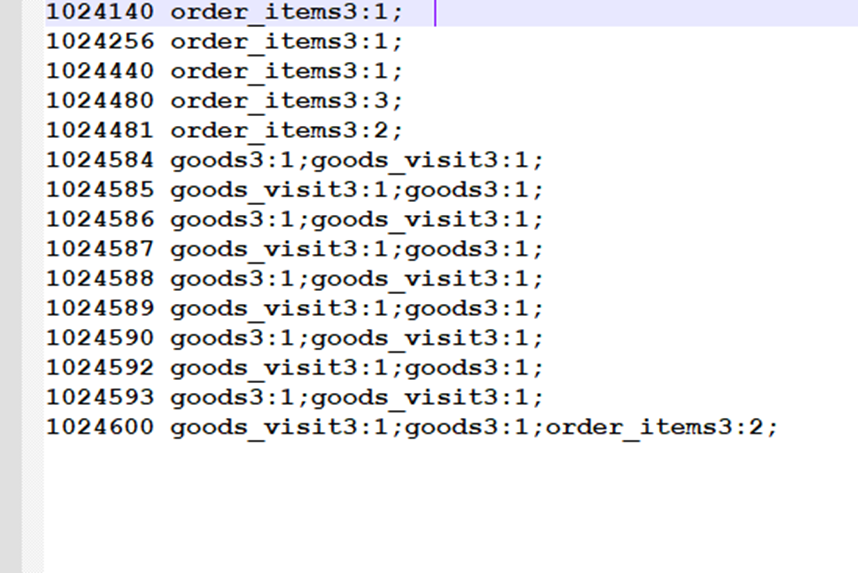
首先使用默认的TextInputFormat类对输入文件进行处理,得到文本中每行的偏移量及其内容。显然,Map过程首先必须分析输入的<key,value>对,得到倒排索引中需要的三个信息:单词、文档URL和词频,接着我们对读入的数据利用Map操作进行预处理,如下图所示:

这里存在两个问题:第一,<key,value>对只能有两个值,在不使用Hadoop自定义数据类型的情况下,需要根据情况将其中两个值合并成一个值,作为key或value值。第二,通过一个Reduce过程无法同时完成词频统计和生成文档列表,所以必须增加一个Combine过程完成词频统计。
这里将商品ID和URL组成key值(如"1024600:goods3"),将词频(商品ID出现次数)作为value,这样做的好处是可以利用MapReduce框架自带的Map端排序,将同一文档的相同单词的词频组成列表,传递给Combine过程,实现类似于WordCount的功能。
(2)Combine过程
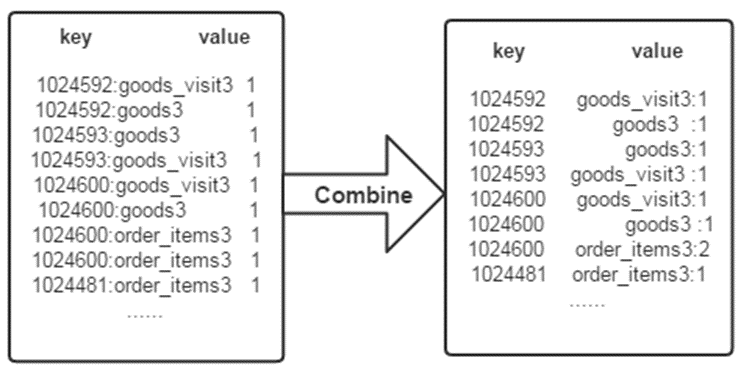
经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频,如下图所示。如果直接将下图所示的输出作为Reduce过程的输入,在Shuffle过程时将面临一个问题:所有具有相同单词的记录(由单词、URL和词频组成)应该交由同一个Reducer处理,但当前的key值无法保证这一点,所以必须修改key值和value值。这次将单词(商品ID)作为key值,URL和词频组成value值(如"goods3:1")。这样做的好处是可以利用MapReduce框架默认的HashPartitioner类完成Shuffle过程,将相同单词的所有记录发送给同一个Reducer进行处理。
(3)Reduce过程
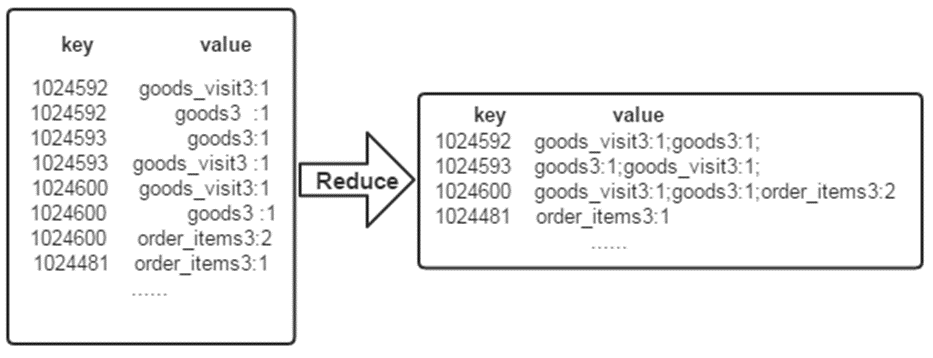
经过上述两个过程后,Reduce过程只需将相同key值的所有value值组合成倒排索引文件所需的格式即可,剩下的事情就可以直接交给MapReduce框架进行处理了。如下图所示
启动hadoop
生成文件
创建项目、写入代码

运行
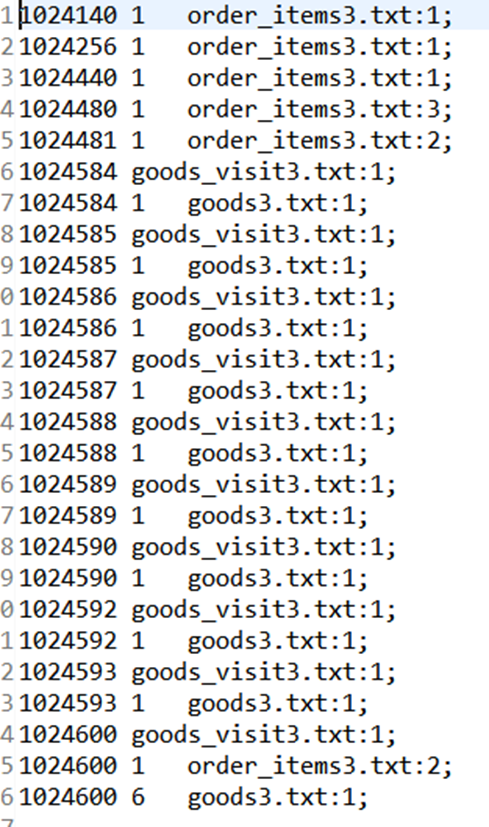
结果: