实验目的
1.准确理解MapReduce单表连接的设计原理
2.熟练掌握MapReduce单表连接程序的编写
3.了解单表连接的运用场景
4.学会编写MapReduce单表连接程序代码解决问题
实验原理
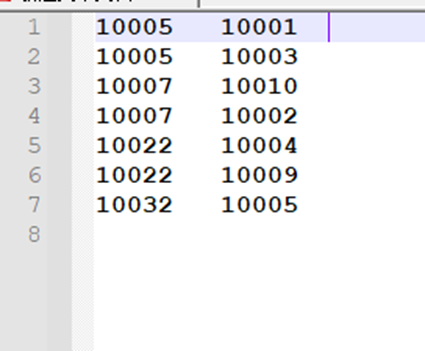
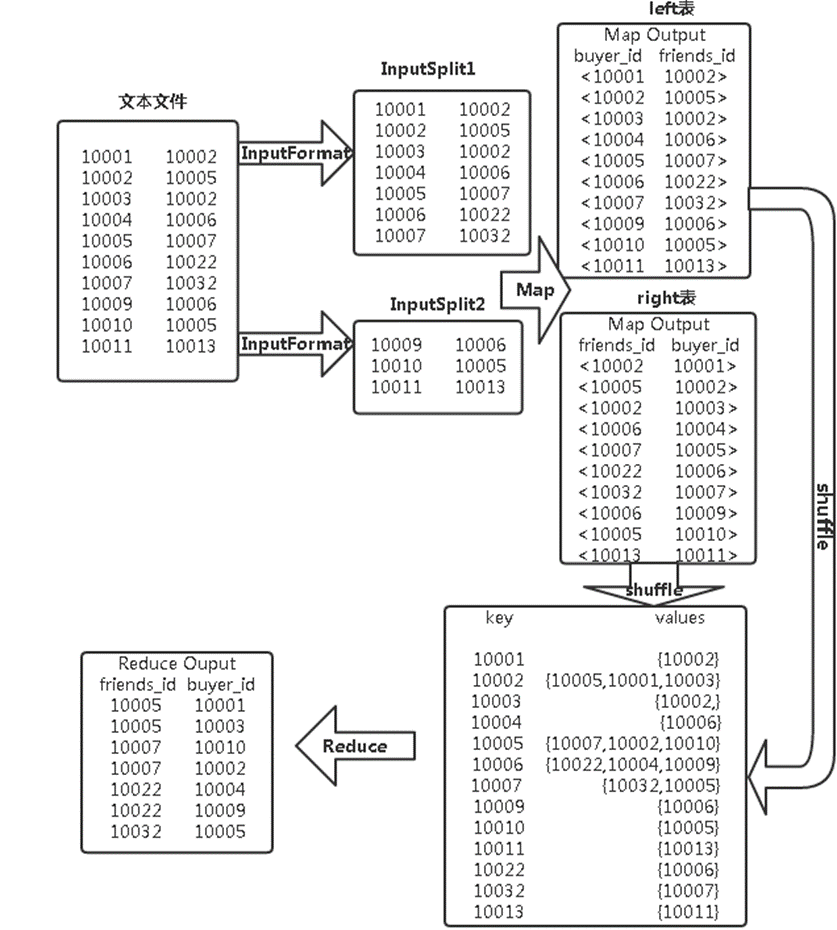
以本实验的buyer1(buyer_id,friends_id)表为例来阐述单表连接的实验原理。单表连接,连接的是左表的buyer_id列和右表的friends_id列,且左表和右表是同一个表。因此,在map阶段将读入数据分割成buyer_id和friends_id之后,会将buyer_id设置成key,friends_id设置成value,直接输出并将其作为左表;再将同一对buyer_id和friends_id中的friends_id设置成key,buyer_id设置成value进行输出,作为右表。为了区分输出中的左右表,需要在输出的value中再加上左右表的信息,比如在value的String最开始处加上字符1表示左表,加上字符2表示右表。这样在map的结果中就形成了左表和右表,然后在shuffle过程中完成连接。reduce接收到连接的结果,其中每个key的value-list就包含了"buyer_idfriends_id--friends_idbuyer_id"关系。取出每个key的value-list进行解析,将左表中的buyer_id放入一个数组,右表中的friends_id放入一个数组,然后对两个数组求笛卡尔积就是最后的结果了。
启动hadoop
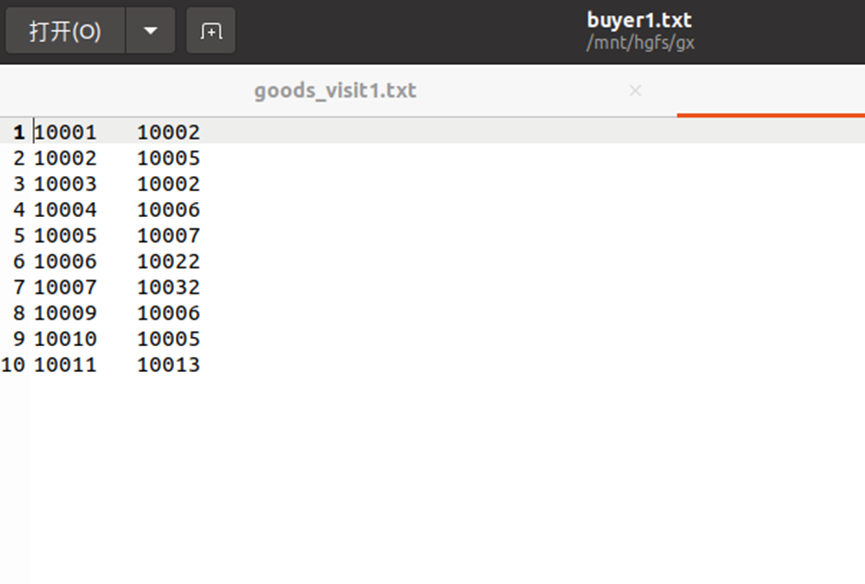
生成文件
创建项目、写入代码
运行
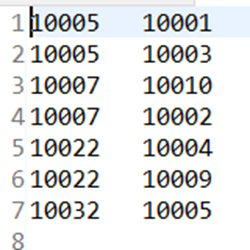
结果: