在本教程中,我们将向您展示如何在香港服务器www.a5idc.net的Ubuntu 20.04 LTS系统上安装Apache Hadoop。Apache Hadoop是一个开放源代码框架,用于分布式存储以及在商用硬件上运行的计算机集群上的大数据的分布式处理。库本身不依赖于硬件来提供高可用性,而是被设计用来检测和处理应用程序层的故障,因此可以在计算机集群的顶部提供高可用性服务,而每台计算机都容易出现故障。
步骤1.首先,通过apt在终端中运行以下命令来确保所有系统软件包都是最新的。
sudo apt update
sudo apt upgrade
步骤2.安装Java。
为了运行Hadoop,您需要在计算机上安装Java 8。为此,请使用以下命令:
sudo apt install default-jdk default-jre
安装后,可以使用以下命令验证Java的安装版本:
java -version
步骤3.创建Hadoop用户。
首先,使用以下命令创建一个名为Hadoop的新用户:
sudo addgroup hadoopgroup
sudo adduser —ingroup hadoopgroup hadoopuser
接下来,使用Hadoop用户登录并使用以下命令生成SSH密钥对:
su - hadoopuser
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
之后,使用以下命令验证无密码的SSH:
ssh localhost
在没有密码的情况下登录后,可以继续执行下一步。
步骤4.在Ubuntu 20.04上安装Apache Hadoop。
现在,我们下载Apache Hadoop的最新稳定版本,在撰写本文时,它是3.3.0版本:
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
tar -xvzf hadoop-3.3.0.tar.gz
接下来,将提取的目录移至:/usr/local/
sudo mv hadoop-3.3.0 /usr/local/hadoop
sudo mkdir /usr/local/hadoop/logs
我们将Hadoop目录的所有权更改为Hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
步骤5.配置Apache Hadoop。
设置环境变量。编辑 ~/.bashrc 文件,并在文件末尾添加以下数值。
nano ~/.bashrc
添加以下行:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
将环境变量应用于当前运行的会话:
source ~/.bashrc
接下来,您需要在hadoop-env.sh中定义Java环境变量,以配置YARN、HDFS、MapReduce和Hadoop相关项目设置。
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
添加以下行:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
现在,您可以使用以下命令来验证Hadoop版本:
hadoop version
步骤6.配置文件。core-site.xml
在文本编辑器中打开文件:core-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
添加以下行:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
步骤7.配置文件。hdfs-site.xml
使用以下命令打开文件进行编辑:hdfs-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
添加以下行:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
步骤8.配置文件。mapred-site.xml
使用以下命令访问文件:mapred-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
添加以下行:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
步骤9.配置文件。yarn-site.xml
在文本编辑器中打开文件:yarn-site.xml
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
添加以下行:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
步骤10.格式化HDFS NameNode。
现在,我们以Hadoop用户身份登录,并使用以下命令格式化HDFS NameNode:
su - hadoop
hdfs namenode -format
步骤11.启动Hadoop集群。
现在,使用以下命令启动NameNode和DataNode:
start-dfs.sh
然后,启动YARN资源和节点管理器:
start-yarn.sh
你应该观察输出,以确定它是否尝试在从属节点上逐个启动数据节点。使用'jps'命令检查所有的服务是否被启动。
jps
步骤12.访问Apache Hadoop。
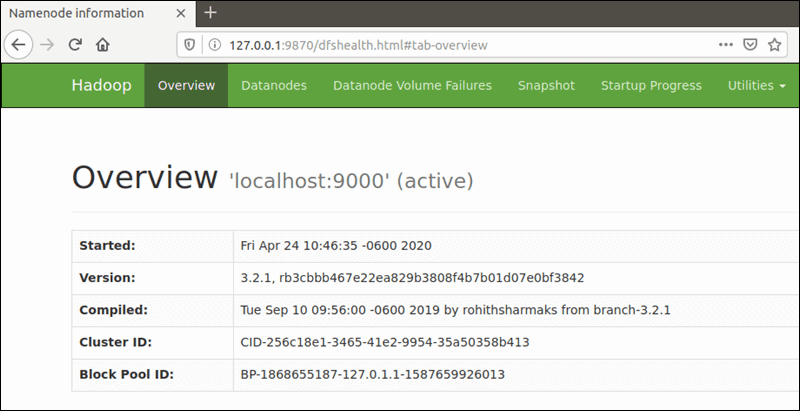
默认端口号为9870,您可以访问Hadoop NameNode用户界面:http://您的服务器-ip:9870
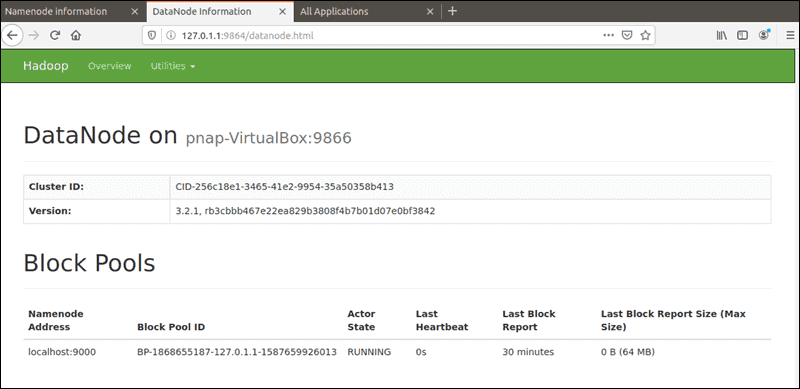
默认端口9864用于直接从浏览器访问单个DataNodes。http://your-server-ip:9864
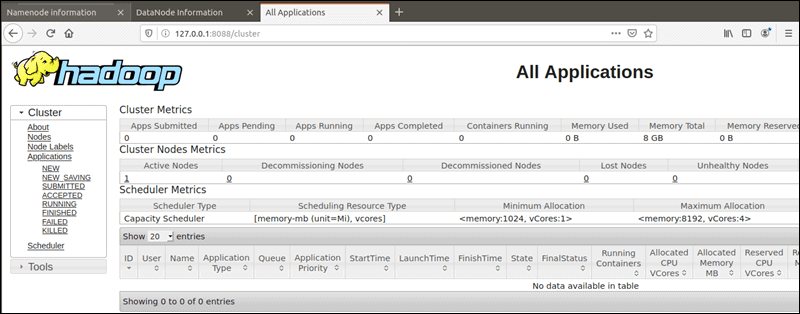
YARN资源管理器可以通过8088端口访问。http://your-server-ip:808
至此,您已成功安装Hadoop。