编程模型 :无界表/动态表格
数据抽象: DataFrame/DataSet

package cn.itcast.structured import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * Author itcast * Desc 演示StructuredStreaming的Source-Socket */ object Demo01_Source_Socket { def main(args: Array[String]): Unit = { //TODO 0.创建环境 //因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ import org.apache.spark.sql.functions._ //TODO 1.加载数据 val df: DataFrame = spark.readStream .format("socket") .option("host", "master") .option("port", 9999) .load() df.printSchema() /* root |-- value: string (nullable = true) */ //df.show()// Queries with streaming sources must be executed with writeStream.start(); //TODO 2.处理数据 val ds: Dataset[String] = df.as[String] val result: Dataset[Row] = ds.flatMap(_.split(" ")) .groupBy('value) .count() .orderBy('count.desc) //TODO 3.输出结果 result.writeStream .format("console") .outputMode("complete") //TODO 4.启动并等待结束 .start() .awaitTermination() //TODO 5.关闭资源 spark.stop() } }
package cn.itcast.structured import org.apache.spark.SparkContext import org.apache.spark.sql.types.{IntegerType, StringType, StructType} import org.apache.spark.sql.{DataFrame, SparkSession} /** * Author itcast * Desc 演示StructuredStreaming的Source-File */ object Demo03_Source_File { def main(args: Array[String]): Unit = { //TODO 0.创建环境 //因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") val csvSchema: StructType = new StructType() .add("name", StringType, nullable = true) .add("age", IntegerType, nullable = true) .add("hobby", StringType, nullable = true) //TODO 1.加载数据 val df: DataFrame = spark.readStream .option("sep", ";") .option("header", "false") .schema(csvSchema)//注意:流式处理对于结构化数据哪怕是有约束也需要单独指定 .format("csv").load("data/input/persons") //.csv("data/input/persons") //TODO 2.处理数据 //TODO 3.输出结果 df.writeStream .format("console") //Complete output mode not supported when there are no streaming aggregations //.outputMode("complete") .outputMode("append") .option("truncate",false)//表示对列不进行截断,也就是对列内容全部展示 //TODO 4.启动并等待结束 .start() .awaitTermination() //TODO 5.关闭资源 spark.stop() } }


当文件夹里有新的文件出现,就马上检测到并打印输出。
实现流式数据处理。
实时监控实现WordCount
package cn.itcast.structured import org.apache.spark.SparkContext import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * Author itcast * Desc 演示StructuredStreaming的Operation */ object Demo04_Operation { def main(args: Array[String]): Unit = { //TODO 0.创建环境 //因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import spark.implicits._ //TODO 1.加载数据 val df: DataFrame = spark.readStream .format("socket") .option("host", "master") .option("port", 9999) .load() df.printSchema() /* root |-- value: string (nullable = true) */ //df.show()// Queries with streaming sources must be executed with writeStream.start(); //TODO 2.处理数据 //TODO ====DSL val ds: Dataset[String] = df.as[String] val wordsDS: Dataset[String] = ds.flatMap(_.split(" ")) val result1: Dataset[Row] = wordsDS .groupBy('value) .count() .orderBy('count.desc) //TODO ====SQL wordsDS.createOrReplaceTempView("t_words") val sql:String = """ |select value,count(*) as counts |from t_words |group by value |order by counts desc |""".stripMargin val result2: DataFrame = spark.sql(sql) //TODO 3.输出结果 result1.writeStream .format("console") .outputMode("complete") //TODO 4.启动 .start() //.awaitTermination()//注意:后面还有代码要执行,所以这里需要注释掉 result2.writeStream .format("console") .outputMode("complete") //TODO 4.启动并等待结束 .start() .awaitTermination() //TODO 5.关闭资源 spark.stop() } }



注意: 在实际开发中一般都要基于事件时间进行窗口计算, 因为事件时间更能代表事件的本质
如: 10-1 23:59:50的订单, 到10-2 00:00:10才被系统处理,如果不支持事件时间那么会出现统计错误
而在StructuredStreaming中就支持事件时间
-
基于事件时间进行窗口计算-容易出现以下问题:
数据迟到--到底计算还是不计算?----得设置一个阈值! ---Watermaker水位线/水印
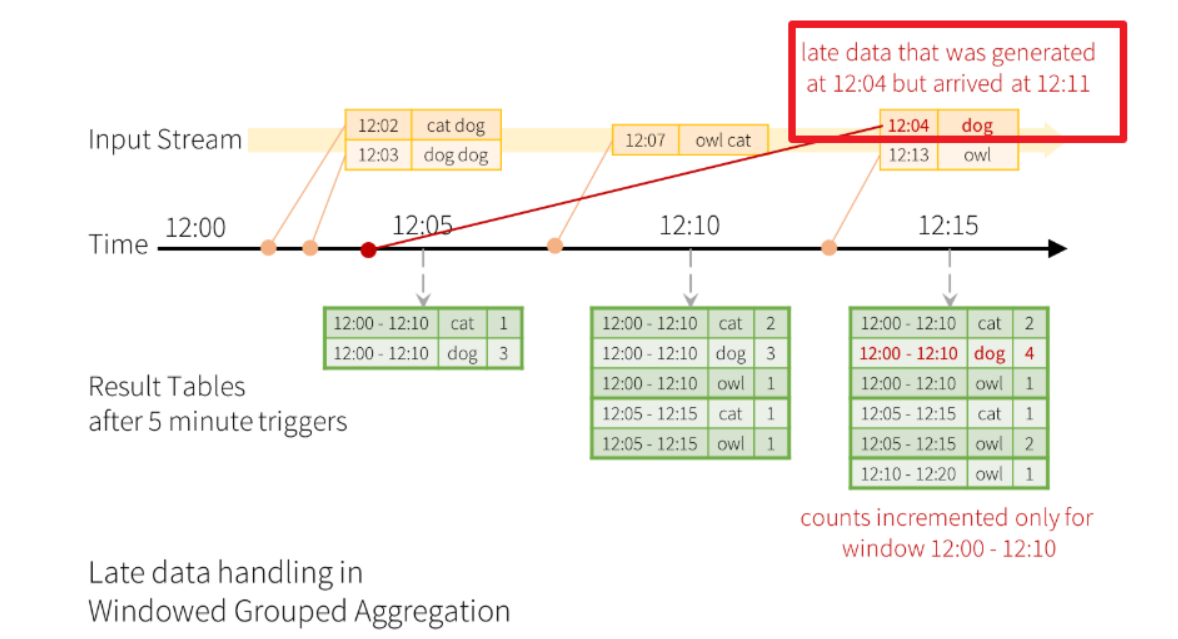
基于事件时间进行窗口计算+ Watermaker水位线/水印解决数据延迟到达问题
import spark.implicits._ val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String } // Group the data by window and word and compute the count of each group val windowedCounts = words .withWatermark("timestamp", "10 minutes") .groupBy( window($"timestamp", "10 minutes", "5 minutes"), $"word") .count()
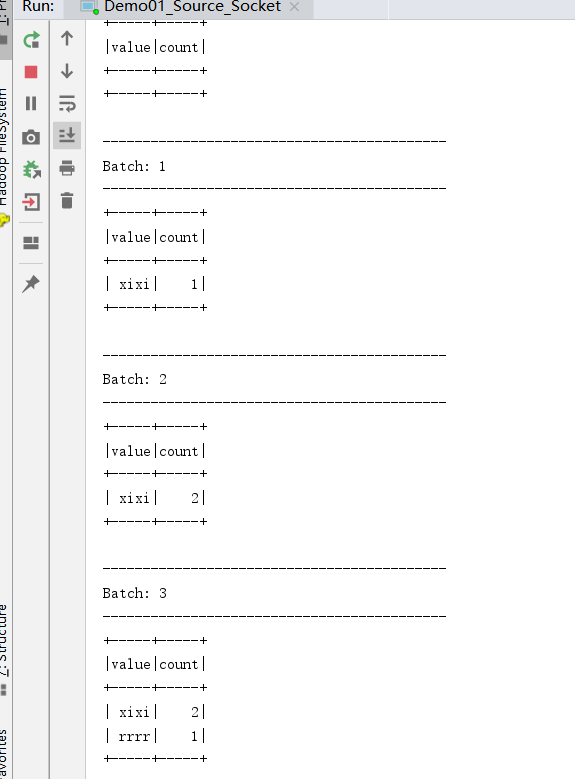
官网案例该开窗窗口长度为10 min,滑动间隔5 min,水印为eventtime-10 min,trigger为Trigger.ProcessingTime("5 minutes"),但是测试的时候用秒 每隔5s计算最近10s的数据,withWatermark设置为10s 2019-10-10 12:00:07,dog 2019-10-10 12:00:08,owl 2019-10-10 12:00:14,dog 2019-10-10 12:00:09,cat 2019-10-10 12:00:15,cat 2019-10-10 12:00:08,dog --迟到不严重,会被计算,控制台会输出 2019-10-10 12:00:13,owl 2019-10-10 12:00:21,owl 2019-10-10 12:00:04,donkey --迟到严重,不会被计算,控制台不会输出 2019-10-10 12:00:17,owl --影响结果
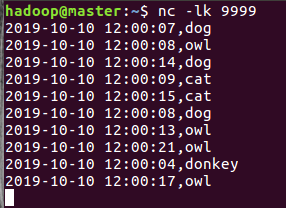
结果:
------------------------------------------- Batch: 0 ------------------------------------------- +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ 21/03/14 00:38:15 WARN ProcessingTimeExecutor: Current batch is falling behind. The trigger interval is 5000 milliseconds, but spent 7575 milliseconds 21/03/14 00:38:21 WARN ProcfsMetricsGetter: Exception when trying to compute pagesize, as a result reporting of ProcessTree metrics is stopped ------------------------------------------- Batch: 1 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|dog |1 | |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|dog |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 2 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|owl |1 | |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|owl |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 3 ------------------------------------------- +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ ------------------------------------------- Batch: 4 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|dog |2 | |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|dog |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 5 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|cat |1 | |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|cat |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 6 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|cat |1 | |[2019-10-10 12:00:15, 2019-10-10 12:00:25]|cat |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 7 ------------------------------------------- +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ ------------------------------------------- Batch: 8 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:00, 2019-10-10 12:00:10]|dog |2 | |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|dog |3 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 9 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:05, 2019-10-10 12:00:15]|owl |2 | |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|owl |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 10 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:20, 2019-10-10 12:00:30]|owl |1 | |[2019-10-10 12:00:15, 2019-10-10 12:00:25]|owl |1 | +------------------------------------------+----+-----+ ------------------------------------------- Batch: 11 ------------------------------------------- +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ ------------------------------------------- Batch: 12 ------------------------------------------- +------+----+-----+ |window|word|count| +------+----+-----+ +------+----+-----+ ------------------------------------------- Batch: 13 ------------------------------------------- +------------------------------------------+----+-----+ |window |word|count| +------------------------------------------+----+-----+ |[2019-10-10 12:00:10, 2019-10-10 12:00:20]|owl |2 | |[2019-10-10 12:00:15, 2019-10-10 12:00:25]|owl |2 | +------------------------------------------+----+-----+
df.dropDuplicates("列名1","列名2")
流式数据去重需要保存历史数据的状态才可以做的去重,而StructuredStreaming的状态管理是自动的
所以StructuredStreaming的流式数据去重和批处理一样
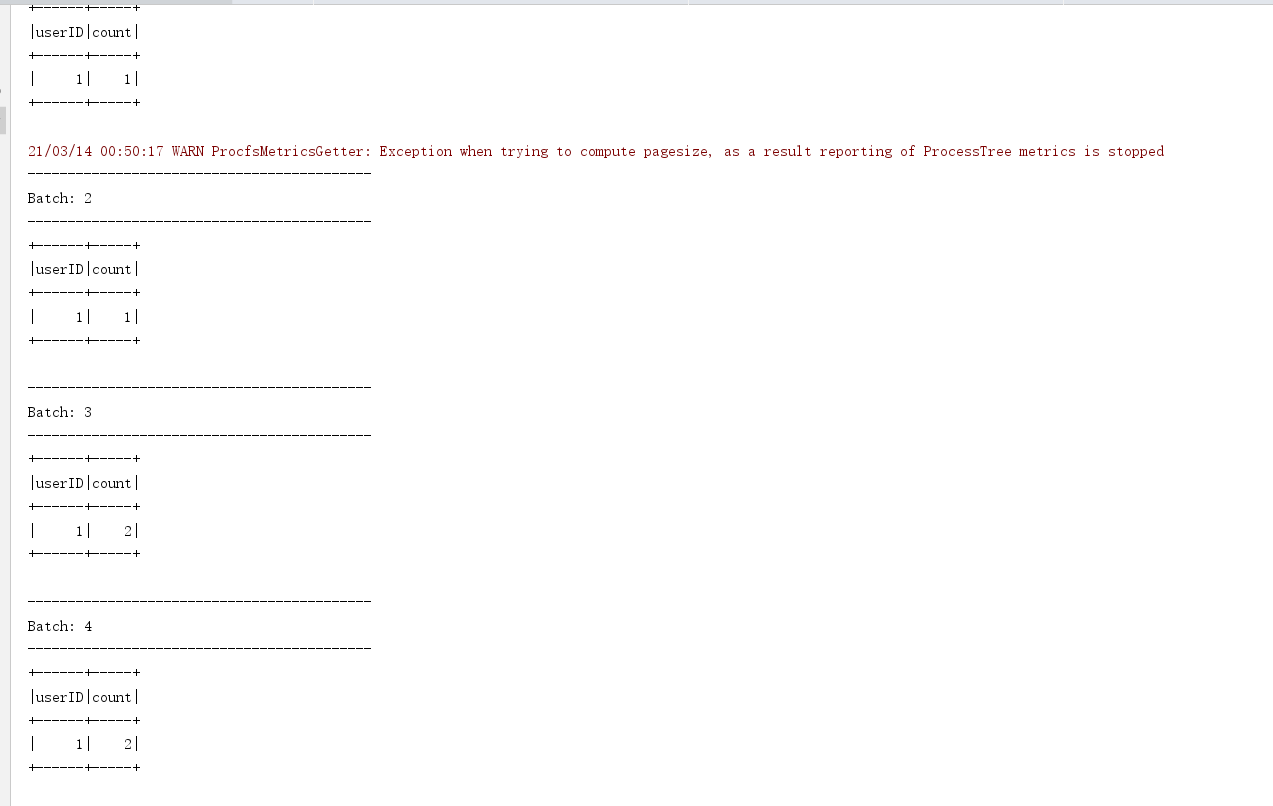
df.dropDuplicates("列名1","列名2")
{"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
{"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"}
{"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"}
{"eventTime": "2016-01-10 10:01:50","eventType": "slide","userID":"1"}
{"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"}
{"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"}
{"eventTime": "2016-01-10 10:01:50","eventType": "slide","userID":"1"}
package cn.itcast.structured import java.sql.Timestamp import org.apache.commons.lang3.StringUtils import org.apache.spark.SparkContext import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger} import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession} /** * Author itcast * Desc 演示StructuredStreaming */ object Demo12_Deduplication { def main(args: Array[String]): Unit = { //TODO 0.创建环境 //因为StructuredStreaming基于SparkSQL的且编程API/数据抽象是DataFrame/DataSet,所以这里创建SparkSession即可 val spark: SparkSession = SparkSession.builder().appName("sparksql").master("local[*]") .config("spark.sql.shuffle.partitions", "4") //本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200 .getOrCreate() val sc: SparkContext = spark.sparkContext sc.setLogLevel("WARN") import org.apache.spark.sql.functions._ import spark.implicits._ //TODO 1.加载数据 val socketDF: DataFrame = spark.readStream .format("socket") .option("host", "master") .option("port", 9999) .load() //TODO 2.处理数据:添加schema //{"eventTime": "2016-01-10 10:01:50","eventType": "browse","userID":"1"} //{"eventTime": "2016-01-10 10:01:50","eventType": "click","userID":"1"} val schemaDF: DataFrame = socketDF .as[String] .filter(StringUtils.isNotBlank(_)) .select( get_json_object($"value", "$.eventTime").as("eventTime"), get_json_object($"value", "$.eventType").as("eventType"), get_json_object($"value", "$.userID").as("userID") ) //TODO 3.数据处理 //对网站用户日志数据,按照userId和eventTime、eventType去重统计 val result: Dataset[Row] = schemaDF .dropDuplicates("userID","eventTime","eventType") .groupBy("userID") .count() result.writeStream .outputMode(OutputMode.Complete()) .format("console") .start() .awaitTermination() //TODO 5.关闭资源 spark.stop() } } //0.kafka准备好 //1.启动数据模拟程序 //2.启动Demo10_Kafka_IOT