Kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目
Kafka的特性:
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
- 可扩展性:kafka集群支持热扩展
- 持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
Kafka的使用场景:
- 日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
- 流式处理:比如spark streaming和storm
- 事件源
- Delivery Mode : Kafka producer 发送message不用维护message的offsite信息,因为这个时候,offsite就相当于一个自增id,producer就尽管发送message就好了。而且Kafka与AMQ不同,AMQ大都用在处理业务逻辑上,而Kafka大都是日志,所以Kafka的producer一般都是大批量的batch发送message,向这个topic一次性发送一大批message,load balance到一个partition上,一起插进去,offsite作为自增id自己增加就好。但是Consumer端是需要维护这个partition当前消费到哪个message的offsite信息的,这个offsite信息,high level api是维护在Zookeeper上,low level api是自己的程序维护。(Kafka管理界面上只能显示high level api的consumer部分,因为low level api的partition offsite信息是程序自己维护,kafka是不知道的,无法在管理界面上展示 )当使用high level api的时候,先拿message处理,再定时自动commit offsite+1(也可以改成手动), 并且kakfa处理message是没有锁操作的。因此如果处理message失败,此时还没有commit offsite+1,当consumer thread重启后会重复消费这个message。但是作为高吞吐量高并发的实时处理系统,at least once的情况下,至少一次会被处理到,是可以容忍的。如果无法容忍,就得使用low level api来自己程序维护这个offsite信息,那么想什么时候commit offsite+1就自己搞定了。
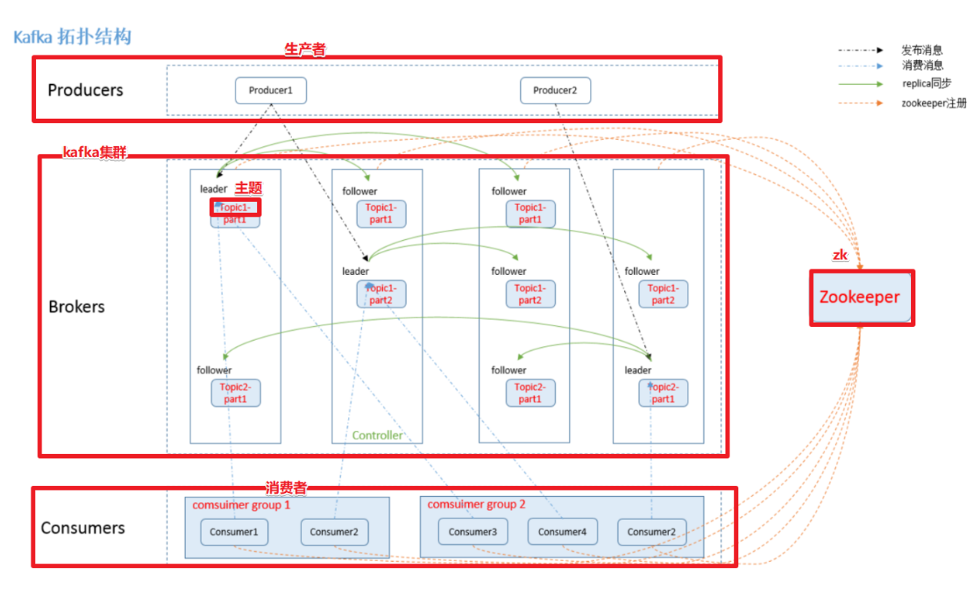
- Topic & Partition:Topic相当于传统消息系统MQ中的一个队列queue,producer端发送的message必须指定是发送到哪个topic,但是不需要指定topic下的哪个partition,因为kafka会把收到的message进行load balance,均匀的分布在这个topic下的不同的partition上( hash(message) % [broker数量] )。物理上存储上,这个topic会分成一个或多个partition,每个partiton相当于是一个子queue。在物理结构上,每个partition对应一个物理的目录(文件夹),文件夹命名是[topicname]_[partition]_[序号],一个topic可以有无数多的partition,根据业务需求和数据量来设置。在kafka配置文件中可随时更高num.partitions参数来配置更改topic的partition数量,在创建Topic时通过参数指定parittion数量。Topic创建之后通过Kafka提供的工具也可以修改partiton数量。
一般来说,(1)一个Topic的Partition数量大于等于Broker的数量,可以提高吞吐率。(2)同一个Partition的Replica尽量分散到不同的机器,高可用。
当add a new partition的时候,partition里面的message不会重新进行分配,原来的partition里面的message数据不会变,新加的这个partition刚开始是空的,随后进入这个topic的message就会重新参与所有partition的load balance
- Partition Replica:每个partition可以在其他的kafka broker节点上存副本,以便某个kafka broker节点宕机不会影响这个kafka集群。存replica副本的方式是按照kafka broker的顺序存。例如有5个kafka broker节点,某个topic有3个partition,每个partition存2个副本,那么partition1存broker1,broker2,partition2存broker2,broker3。。。以此类推(replica副本数目不能大于kafka broker节点的数目,否则报错。这里的replica数其实就是partition的副本总数,其中包括一个leader,其他的就是copy副本)。这样如果某个broker宕机,其实整个kafka内数据依然是完整的。但是,replica副本数越高,系统虽然越稳定,但是回来带资源和性能上的下降;replica副本少的话,也会造成系统丢数据的风险。
(1)怎样传送消息:producer先把message发送到partition leader,再由leader发送给其他partition follower。(如果让producer发送给每个replica那就太慢了)
(2)在向Producer发送ACK前需要保证有多少个Replica已经收到该消息:根据ack配的个数而定
(3)怎样处理某个Replica不工作的情况:如果这个部工作的partition replica不在ack列表中,就是producer在发送消息到partition leader上,partition leader向partition follower发送message没有响应而已,这个不会影响整个系统,也不会有什么问题。如果这个不工作的partition replica在ack列表中的话,producer发送的message的时候会等待这个不工作的partition replca写message成功,但是会等到time out,然后返回失败因为某个ack列表中的partition replica没有响应,此时kafka会自动的把这个部工作的partition replica从ack列表中移除,以后的producer发送message的时候就不会有这个ack列表下的这个部工作的partition replica了。
(4)怎样处理Failed Replica恢复回来的情况:如果这个partition replica之前不在ack列表中,那么启动后重新受Zookeeper管理即可,之后producer发送message的时候,partition leader会继续发送message到这个partition follower上。如果这个partition replica之前在ack列表中,此时重启后,需要把这个partition replica再手动加到ack列表中。(ack列表是手动添加的,出现某个部工作的partition replica的时候自动从ack列表中移除的)
- Partition leader与follower:partition也有leader和follower之分。leader是主partition,producer写kafka的时候先写partition leader,再由partition leader push给其他的partition follower。partition leader与follower的信息受Zookeeper控制,一旦partition leader所在的broker节点宕机,zookeeper会冲其他的broker的partition follower上选择follower变为parition leader。
- Topic分配partition和partition replica的算法:(1)将Broker(size=n)和待分配的Partition排序。(2)将第i个Partition分配到第(i%n)个Broker上。(3)将第i个Partition的第j个Replica分配到第((i + j) % n)个Broker上

kafka集群安装:
版本是2.7版本
https://mirrors.bfsu.edu.cn/apache/kafka/2.7.0/kafka_2.12-2.7.0.tgz
sudo tar -zxf /home/hadoop/下载/kafka_2.12-2.7.0.tgz -C /usr/local/ cd /usr/local sudo chown -R hadoop:hadoop ./kafka_2.12-2.7.0 cd ~ sudo vim /etc/profile
编辑添加
export KAFKA_HOME=/usr/local/kafka_2.12-2.7.0 export PATH=$PATH:$KAFKA_HOME/bin
新建目录:
mkdir /usr/local/kafka_2.12-2.7.0/logs
编辑:
sudo vim /usr/local/kafka_2.12-2.7.0/config/server.properties
如下:
broker.id=0 log.dirs=/usr/local/kafka_2.12-2.7.0/logs/ zookeeper.connect=master:2181,slave1:2181,slave2:2181,slave3:2181
分发:
cd /usr/local sudo scp -r kafka_2.12-2.7.0 hadoop@slave3:$PWD sudo scp -r kafka_2.12-2.7.0 hadoop@slave1:$PWD sudo scp -r kafka_2.12-2.7.0 hadoop@slave2:$PWD
修改拥有者同时设置环境变量
修改子节点的server.properties
broker.id
分别为
broker.id=1 broker.id=2 broker.id=3
每台节点启动zookeeper集群
cd /usr/local/zookeeper/bin/
./zkServer.sh start
在每台节点上
新开一个终端,启动kafka
cd /usr/local/kafka_2.12-2.7.0/bin kafka-server-start.sh ../config/server.properties
通过jps可查看到kafka
master新开一个终端
创建一个 topic
cd /usr/local/kafka_2.12-2.7.0/bin kafka-topics.sh --create --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181 --replication-factor 4 --partitions 4 --topic spark-kafka
##--zookeeper zookeeper服务列表配置项,使用zk集群中任意节点即可 ##--create --topic 进行topic创建指令,创建的topic名称为spark-kafka ##--partitions 指定该topic下的partition数量 ##--replication-factor 指定该topic的副本数量
获取当前集群的所有 topic:
kafka-topics.sh --list --zookeeper master:2181,slave1:2181,slave2:2181,slave3:2181
生产者向指定的topic发送数据
##生产者向指定的topic发送数据 kafka-console-producer.sh --broker-list master:9092 --topic spark-kafka
消费者从指定的topic拉取数据
##消费者从指定的topic拉取数据 kafka-console-consumer.sh --botrap-server master:9092 --topic spark-kafka --from-beginning
删除指定topic
##删除指定topic kafka-topics.sh --zookeeper master:2181 --delete --topic spark-kafka
测试:
package cn.itcast.streaming import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{Seconds, StreamingContext} /** * Author itcast * Desc 演示使用spark-streaming-kafka-0-10_2.12中的Direct模式连接Kafka消费数据 */ object SparkStreaming_Kafka_Demo01 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //the time interval at which streaming data will be divided into batches val ssc: StreamingContext = new StreamingContext(sc,Seconds(5))//每隔5s划分一个批次 ssc.checkpoint("./ckp") //TODO 1.加载数据-从Kafka val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "master:9092",//kafka集群地址 "key.deserializer" -> classOf[StringDeserializer],//key的反序列化规则 "value.deserializer" -> classOf[StringDeserializer],//value的反序列化规则 "group.id" -> "sparkdemo",//消费者组名称 //earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费 //latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费 //none:表示如果有offset记录从offset记录开始消费,如果没有就报错 "auto.offset.reset" -> "latest", "auto.commit.interval.ms"->"1000",//自动提交的时间间隔 "enable.auto.commit" -> (true: java.lang.Boolean)//是否自动提交 ) val topics = Array("spark-kafka")//要订阅的主题 //使用工具类从Kafka中消费消息 val kafkaDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //位置策略,使用源码中推荐的 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //消费策略,使用源码中推荐的 ) //TODO 2.处理消息 val infoDS: DStream[String] = kafkaDS.map(record => { val topic: String = record.topic() val partition: Int = record.partition() val offset: Long = record.offset() val key: String = record.key() val value: String = record.value() val info: String = s"""topic:${topic}, partition:${partition}, offset:${offset}, key:${key}, value:${value}""" info }) //TODO 3.输出结果 infoDS.print() //TODO 4.启动并等待结束 ssc.start() ssc.awaitTermination()//注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来 //TODO 5.关闭资源 ssc.stop(stopSparkContext = true, stopGracefully = true)//优雅关闭 } } //测试: //1.准备kafka // /export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181 // /export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic spark_kafka // /export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka //2.启动程序 //3.发送数据 //4.观察结果

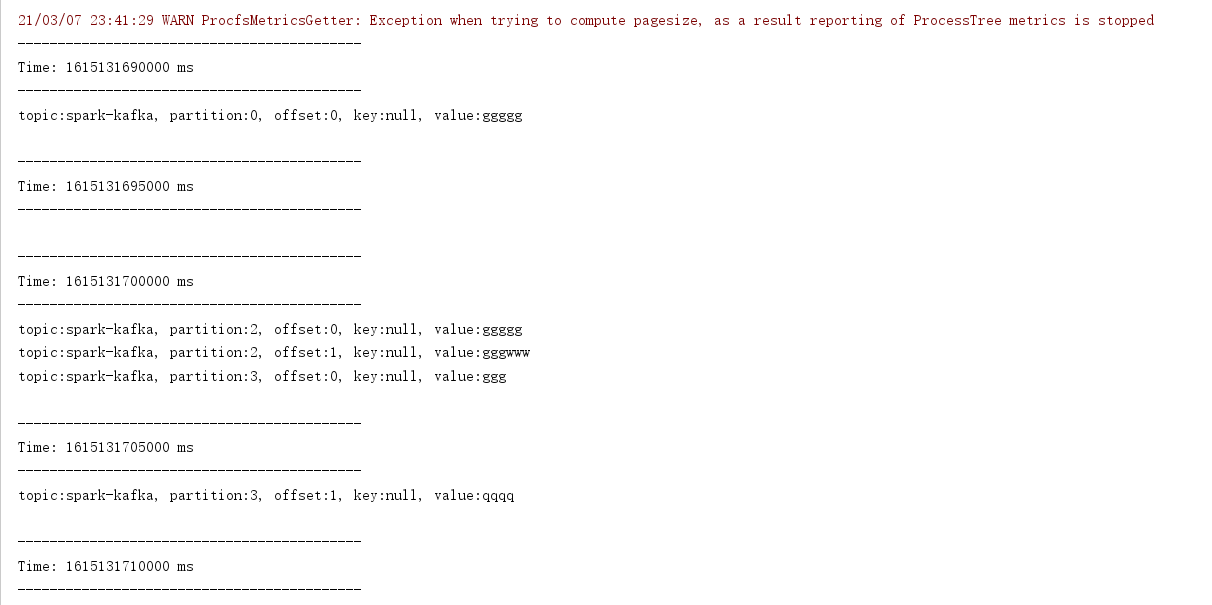
在IDEA手动停掉程序
然后再虚拟机上再次输入数据后重启程序,可以看到在那之后的数据


关闭:
先关闭kafka再关闭zookeeper
kafka-server-stop.sh stop
cd /usr/local/zookeeper/bin/
./zkServer.sh stop
package cn.itcast.streaming import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.dstream.{DStream, InputDStream} import org.apache.spark.streaming.kafka010.{CanCommitOffsets, ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies, OffsetRange} import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} /** * Author itcast * Desc 演示使用spark-streaming-kafka-0-10_2.12中的Direct模式连接Kafka消费数据+手动提交offset */ object SparkStreaming_Kafka_Demo02 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //the time interval at which streaming data will be divided into batches val ssc: StreamingContext = new StreamingContext(sc, Seconds(5)) //每隔5s划分一个批次 ssc.checkpoint("./ckp") //TODO 1.加载数据-从Kafka val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "master:9092", //kafka集群地址 "key.deserializer" -> classOf[StringDeserializer], //key的反序列化规则 "value.deserializer" -> classOf[StringDeserializer], //value的反序列化规则 "group.id" -> "sparkdemo", //消费者组名称 //earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费 //latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费 //none:表示如果有offset记录从offset记录开始消费,如果没有就报错 "auto.offset.reset" -> "latest", //"auto.commit.interval.ms"->"1000",//自动提交的时间间隔 "enable.auto.commit" -> (false: java.lang.Boolean) //是否自动提交 ) val topics = Array("spark-kafka") //要订阅的主题 //使用工具类从Kafka中消费消息 val kafkaDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //位置策略,使用源码中推荐的 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //消费策略,使用源码中推荐的 ) //TODO 2.处理消息 //注意提交的时机:应该是消费完一小批就该提交一次offset,而在DStream一小批的体现是RDD kafkaDS.foreachRDD(rdd => { if(!rdd.isEmpty()){ //消费 rdd.foreach(record => { val topic: String = record.topic() val partition: Int = record.partition() val offset: Long = record.offset() val key: String = record.key() val value: String = record.value() val info: String = s"""topic:${topic}, partition:${partition}, offset:${offset}, key:${key}, value:${value}""" println("消费到的消息的详细信息为: "+info) }) //获取rdd中offset相关的信息:offsetRanges里面就包含了该批次各个分区的offset信息 val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //提交 kafkaDS.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) println("当前批次的数据已消费并手动提交") } }) //TODO 3.输出结果 //TODO 4.启动并等待结束 ssc.start() ssc.awaitTermination() //注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来 //TODO 5.关闭资源 ssc.stop(stopSparkContext = true, stopGracefully = true) //优雅关闭 } } //测试: //1.准备kafka // /export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181 // /export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic spark_kafka // /export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka //2.启动程序 //3.发送数据 //4.观察结果


关闭程序,再输入,再开启程序

CREATE TABLE `t_offset` ( `topic` varchar(255) NOT NULL, `partition` int(11) NOT NULL, `groupid` varchar(255) NOT NULL, `offset` bigint(20) DEFAULT NULL, PRIMARY KEY (`topic`,`partition`,`groupid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
package cn.itcast.streaming import java.sql.{DriverManager, ResultSet} import org.apache.kafka.clients.consumer.ConsumerRecord import org.apache.kafka.common.TopicPartition import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.streaming.dstream.InputDStream import org.apache.spark.streaming.kafka010._ import org.apache.spark.streaming.{Seconds, StreamingContext} import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable /** * Author itcast * Desc 演示使用spark-streaming-kafka-0-10_2.12中的Direct模式连接Kafka消费数据+手动提交offset到MySQL */ object SparkStreaming_Kafka_Demo03 { def main(args: Array[String]): Unit = { //TODO 0.准备环境 val conf: SparkConf = new SparkConf().setAppName("spark").setMaster("local[*]") val sc: SparkContext = new SparkContext(conf) sc.setLogLevel("WARN") //the time interval at which streaming data will be divided into batches val ssc: StreamingContext = new StreamingContext(sc, Seconds(5)) //每隔5s划分一个批次 ssc.checkpoint("./ckp1") //TODO 1.加载数据-从Kafka val kafkaParams = Map[String, Object]( "bootstrap.servers" -> "master:9092", //kafka集群地址 "key.deserializer" -> classOf[StringDeserializer], //key的反序列化规则 "value.deserializer" -> classOf[StringDeserializer], //value的反序列化规则 "group.id" -> "sparkdemo", //消费者组名称 //earliest:表示如果有offset记录从offset记录开始消费,如果没有从最早的消息开始消费 //latest:表示如果有offset记录从offset记录开始消费,如果没有从最后/最新的消息开始消费 //none:表示如果有offset记录从offset记录开始消费,如果没有就报错 "auto.offset.reset" -> "latest", //"auto.commit.interval.ms"->"1000",//自动提交的时间间隔 "enable.auto.commit" -> (false: java.lang.Boolean) //是否自动提交 ) val topics = Array("spark-kafka") //要订阅的主题 //Map[主题分区, offset] val offsetsMap: mutable.Map[TopicPartition, Long] = OffsetUtil.getOffsetMap("sparkdemo","spark-kafka") val kafkaDS: InputDStream[ConsumerRecord[String, String]] = if(offsetsMap.size > 0){ println("MySQL中存储了该消费者组消费该主题的偏移量记录,接下来从记录处开始消费") //使用工具类从Kafka中消费消息 KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //位置策略,使用源码中推荐的 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams,offsetsMap) //消费策略,使用源码中推荐的 ) }else{ println("MySQL中没有存储该消费者组消费该主题的偏移量记录,接下来从latest开始消费") //使用工具类从Kafka中消费消息 KafkaUtils.createDirectStream[String, String]( ssc, LocationStrategies.PreferConsistent, //位置策略,使用源码中推荐的 ConsumerStrategies.Subscribe[String, String](topics, kafkaParams) //消费策略,使用源码中推荐的 ) } //TODO 2.处理消息 //注意提交的时机:应该是消费完一小批就该提交一次offset,而在DStream一小批的体现是RDD kafkaDS.foreachRDD(rdd => { if(!rdd.isEmpty()){ //消费 rdd.foreach(record => { val topic: String = record.topic() val partition: Int = record.partition() val offset: Long = record.offset() val key: String = record.key() val value: String = record.value() val info: String = s"""topic:${topic}, partition:${partition}, offset:${offset}, key:${key}, value:${value}""" println("消费到的消息的详细信息为: "+info) }) //获取rdd中offset相关的信息:offsetRanges里面就包含了该批次各个分区的offset信息 val offsetRanges: Array[OffsetRange] = rdd.asInstanceOf[HasOffsetRanges].offsetRanges //提交 //kafkaDS.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges) //提交到MySQL OffsetUtil.saveOffsetRanges("sparkdemo",offsetRanges) println("当前批次的数据已消费并手动提交到MySQL") } }) //TODO 3.输出结果 //TODO 4.启动并等待结束 ssc.start() ssc.awaitTermination() //注意:流式应用程序启动之后需要一直运行等待手动停止/等待数据到来 //TODO 5.关闭资源 ssc.stop(stopSparkContext = true, stopGracefully = true) //优雅关闭 } /* 手动维护offset的工具类 首先在MySQL创建如下表 CREATE TABLE `t_offset` ( `topic` varchar(255) NOT NULL, `partition` int(11) NOT NULL, `groupid` varchar(255) NOT NULL, `offset` bigint(20) DEFAULT NULL, PRIMARY KEY (`topic`,`partition`,`groupid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; */ object OffsetUtil { //1.将偏移量保存到数据库 def saveOffsetRanges(groupid: String, offsetRange: Array[OffsetRange]) = { val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456") //replace into表示之前有就替换,没有就插入 val ps = connection.prepareStatement("replace into t_offset (`topic`, `partition`, `groupid`, `offset`) values(?,?,?,?)") for (o <- offsetRange) { ps.setString(1, o.topic) ps.setInt(2, o.partition) ps.setString(3, groupid) ps.setLong(4, o.untilOffset) ps.executeUpdate() } ps.close() connection.close() } //2.从数据库读取偏移量Map(主题分区,offset) def getOffsetMap(groupid: String, topic: String) = { val connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/bigdata?characterEncoding=UTF-8", "root", "123456") val ps = connection.prepareStatement("select * from t_offset where groupid=? and topic=?") ps.setString(1, groupid) ps.setString(2, topic) val rs: ResultSet = ps.executeQuery() //Map(主题分区,offset) val offsetMap: mutable.Map[TopicPartition, Long] = mutable.Map[TopicPartition, Long]() while (rs.next()) { offsetMap += new TopicPartition(rs.getString("topic"), rs.getInt("partition")) -> rs.getLong("offset") } rs.close() ps.close() connection.close() offsetMap } } } //测试: //1.准备kafka // /export/server/kafka/bin/kafka-topics.sh --list --zookeeper node1:2181 // /export/server/kafka/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic spark_kafka // /export/server/kafka/bin/kafka-console-producer.sh --broker-list node1:9092 --topic spark_kafka //2.启动程序 //3.发送数据 //4.观察结果

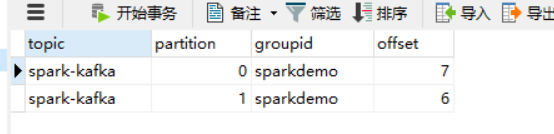
只有offset改变,它表示下一个空间