在本地新建一个目录:
然后在里面写入内容
vim wordcount.txt
内容如下:
hello,world,hadoop
hive,sqoop,flume,hello
kitty,tom,jerry,world
hadoop
上传到HDFS
hdfs dfs -mkdir /wordcount
hdfs dfs -put wordcount.txt /wordcount/
出现文件

下面是在IDEA上运行的代码:
import java.io.IOException; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static void main(String[] args) throws IOException,ClassNotFoundException,InterruptedException { Job job = Job.getInstance(); job.setJobName("WordCount"); job.setJarByClass(WordCount.class); job.setMapperClass(doMapper.class); job.setReducerClass(doReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path in = new Path("hdfs://192.168.58.128:9000/wordcount/wordcount.txt"); Path out = new Path("hdfs://192.168.58.128:9000/wordcount_out"); // Path in = new Path("hdfs://192.168.58.128:9000/wordcount/wordcount.txt"); // Path out = new Path("hdfs://192.168.58.128:9000/wordcount_out"); FileInputFormat.addInputPath(job,in);//读取并自动分成键值对。 FileOutputFormat.setOutputPath(job,out); System.exit(job.waitForCompletion(true)?0:1); } public static class doMapper extends Mapper<Object,Text,Text,IntWritable>{ public static final IntWritable one = new IntWritable(1); public static Text word = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException,InterruptedException { String line =value.toString(); String[] split = line.split(","); for (String words:split){ word.set(words); context.write(word,one); } } } public static class doReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ private IntWritable result = new IntWritable(); @Override protected void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{ int sum = 0; for (IntWritable value : values){ sum += value.get(); } result.set(sum); context.write(key,result); } } }
成功之后可以在HDFS上看到新的文件夹wordcount_out
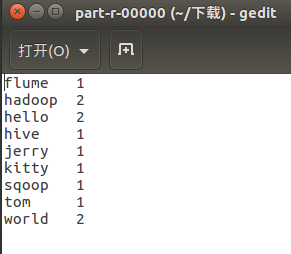
里面的part-r-00000文件会显示单词统计的结果
下载下来后可以看到