想试着模拟登陆一些网站,这次先拿学校的教务管理系统练练手,写一下登陆的流程。
1.我们登陆的url:http://222.195.8.201,但我们所填的密码不是提交到这个页面上去,检查一下页面代码

我们看到提交后post数据是提交到pass.asp页面。或者在chrome上F12点击登陆查看跳转的页面:

根据时间的顺序第一个页面就是pass.asp,确实这就是提交的页面。后面也是服务器传过来的页面。
2.登陆原理也很简单,提交表单获取cookie,然后以后利用所携带的cookie来构建请求报文访问其他的页面。
我们在首次登陆时点击提交服务器返回cookie存储在用户本机
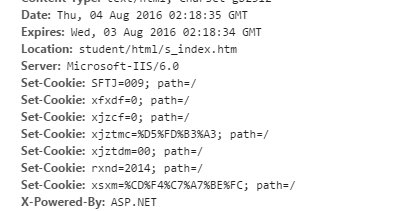
这就是我们提交表单后所得到的cookie内容,指某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据。往后在访问相同站点的其他url时请求报文就会假如cookie,服务器利用cookie来对用户进行识别,我们登陆之后点击其他页面我们查看提交报文中就含有相同的cookie。

一下就是访问其他页面返回的html

1 import urllib 2 import urllib2 3 import cookielib 4 #声明一个cookieJar对象实例来保存Cookie 5 cookie = cookielib.CookieJar() 6 #声明一个urllib2.HTTPCookieProcessor对象创建一个cookie处理器 7 handle=urllib2.HTTPCookieProcessor(cookie) 8 #构建一个opener 9 opener = urllib2.build_opener(handle) 10 11 #需要POST的数据,查看formData# 12 postdata=urllib.urlencode({ 13 'UserStyle':'student', 14 'user':'你的学号', 15 'password':'你的密码', 16 'method': 'POST' 17 }) 18 #自定义一个请求# 19 req = urllib2.Request( 20 url = 'http://222.195.8.201/pass.asp', 21 data = postdata 22 23 ) 24 #访问该链接# 25 result = opener.open(req) 26 27 #打印返回的内容# 28 print result.read() 29 #查看cookie# 30 for item in cookie: 31 print 'Cookie:Name = '+item.name 32 print 'Cookie:Value = '+item.value 33 #查看成绩一栏# 34 res=opener.open('http://222.195.8.201/student/asp/xsxxxxx.asp') 35 print res.read()
抓取到页面后剩下的就交给BeautifulSoup了