1). *自主编写K-means算法 ,以鸢尾花花瓣长度数据做聚类,并用散点图显示
实现代码:
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
# 1.实现K-Means算法
iris = load_iris() #导入数据
data = iris.data[:,2].reshape(-1,1)
n = len(data) #样本总数
k = 3 #设置中心个数
dist = np.zeros([n, k+1]) #初始化距离矩阵,第k列存放得到的每个样本的类别
center=random.sample(list(data), k) #初始类中心,随机选取3个样本作为初始类中心
center_new = np.zeros([k,1]) #新的类中心
while True:
for i in range(n):
for j in range(k):
dist[i,j] = np.sqrt((data[i] - center[j])**2) #计算欧氏距离
dist[i,k] = np.argmin(dist[i,:k]) #根据最近准则进行归类
for i in range(k):
index = dist[:, k] == i #判断属于哪一类
center_new[i] = data[index].mean(axis = 0)#求新的类中心
if np.all(center == center_new): #判断新的类中心是否与上一轮的类中心相同,若相同则跳出循环
break
else:
center = center_new #更新类中心
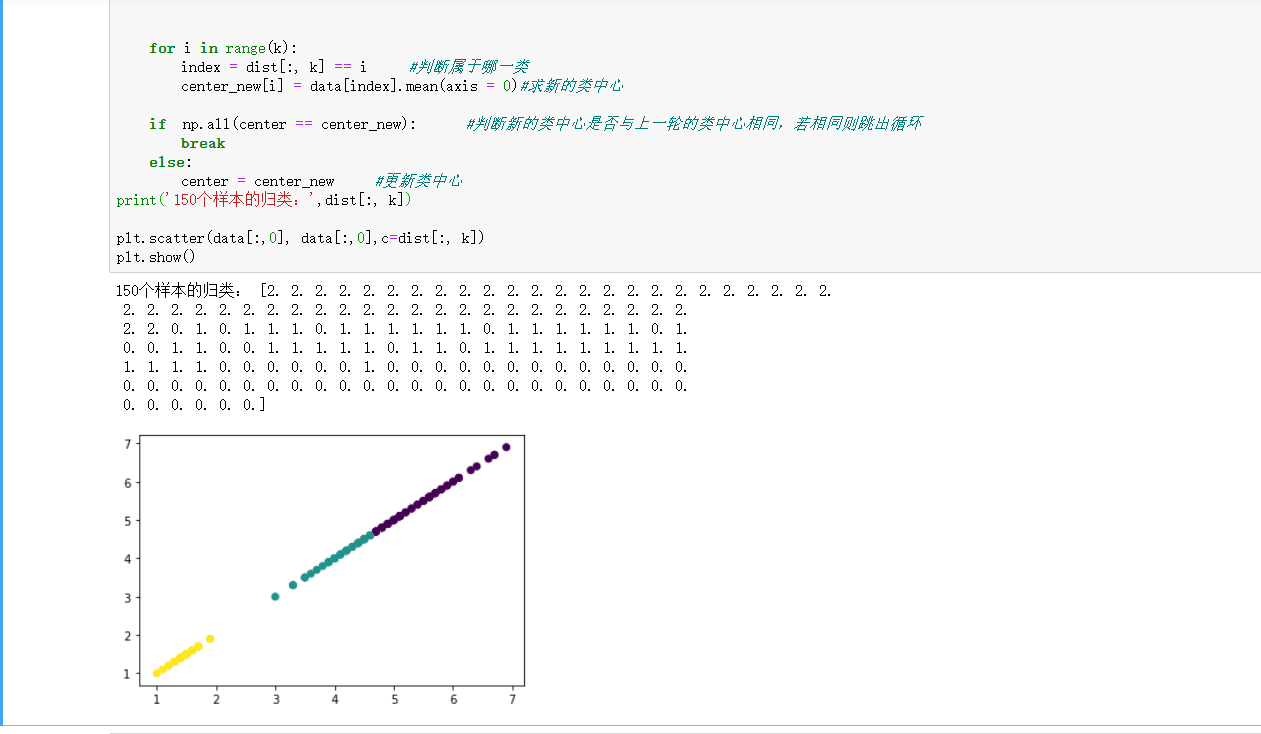
print('150个样本的归类:',dist[:, k])
plt.scatter(data[:,0], data[:,0],c=dist[:, k])
plt.show()
运行结果:
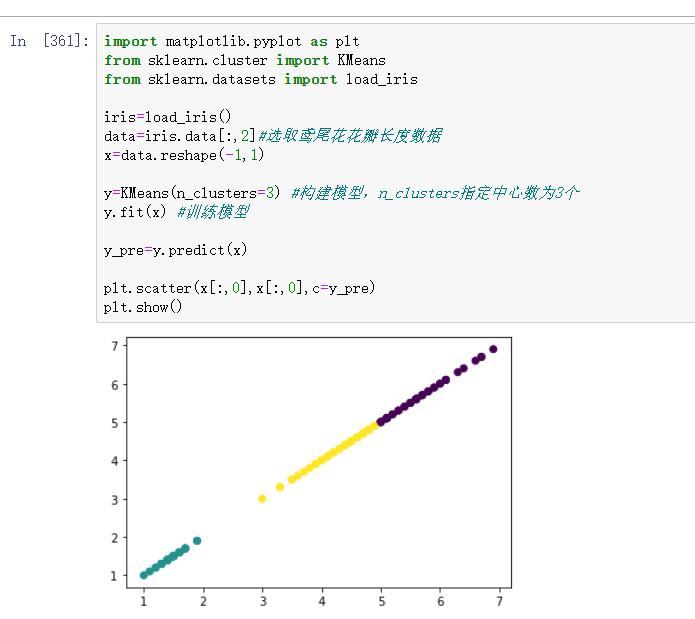
2). 用sklearn.cluster.KMeans,鸢尾花花瓣长度数据做聚类,并用散点图显示.
实现代码:
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris iris=load_iris() data=iris.data[:,2]#选取鸢尾花花瓣长度数据 x=data.reshape(-1,1) y=KMeans(n_clusters=3) #构建模型,n_clusters指定中心数为3个 y.fit(x) #训练模型 y_pre=y.predict(x) plt.scatter(x[:,0],x[:,0],c=y_pre) plt.show()
运行结果:
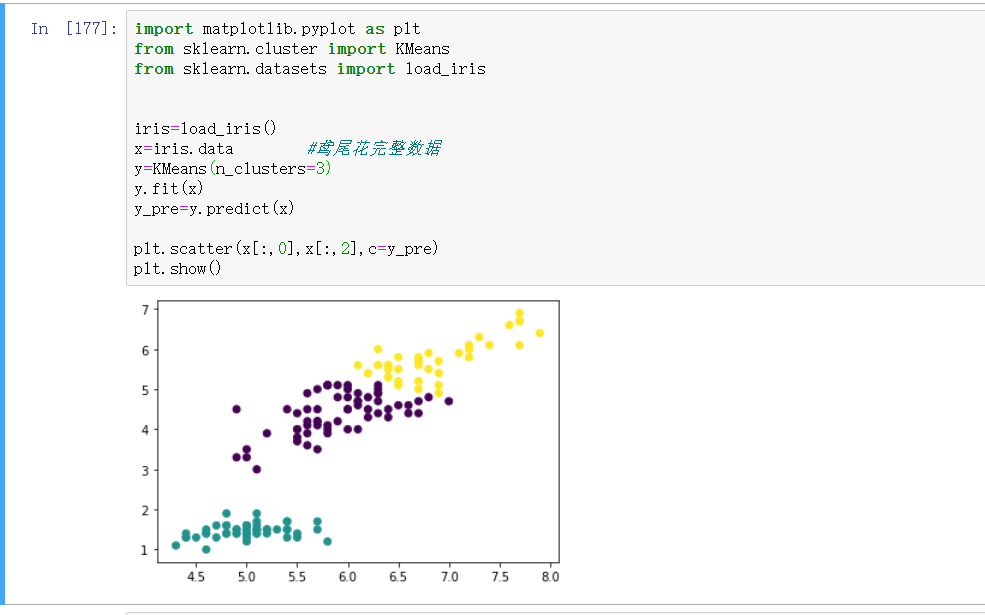
3). 鸢尾花完整数据做聚类并用散点图显示.
实现代码:
import matplotlib.pyplot as plt from sklearn.cluster import KMeans from sklearn.datasets import load_iris iris=load_iris() x=iris.data #鸢尾花完整数据 y=KMeans(n_clusters=3) y.fit(x) y_pre=y.predict(x) plt.scatter(x[:,0],x[:,2],c=y_pre) plt.show()
运行结果:
4).想想k均值算法中以用来做什么?
可用于对图像进行压缩显示;网站对网络用户进行喜好分析;工厂按制造指标对库存进行分组