Python 是一种用于进行数据分析的出色语言,主要是因为以数据为中心的 Python 包的奇妙生态系统。Pandas是使导入和分析数据更容易的软件包之一。
分析数据需要大量的过滤操作。Pandas 提供了许多过滤数据框的方法,它Dataframe.query()就是其中之一。
注意极客!通过Python 编程基础课程巩固您的基础并学习基础知识。
首先,您的面试准备通过Python DS课程增强您的数据结构概念。要开始您的机器学习之旅,请加入机器学习 - 基础课程
语法: DataFrame.query(expr, inplace=False, **kwargs)
参数:
expr:过滤数据的字符串形式的表达式。
就地:如果 True
kwargs:其他关键字参数,则在原始数据框中进行更改。返回类型:过滤后的数据框
要下载使用的 CSV 文件,请单击此处。
注意: Dataframe.query()方法仅在列名没有任何空格时才有效。所以在应用该方法之前,列名中的空格被替换为“_”
示例 #1:单条件过滤
在这个例子中,数据是根据单一条件过滤的。在应用 query() 方法之前,列名中的空格已被替换为“_”。
# importing pandas package import pandas as pd # making data frame from csv file data = pd.read_csv("employees.csv") # replacing blank spaces with '_' data.columns =[column.replace(" ", "_") for column in data.columns] # filtering with query method data.query('Senior_Management == True', inplace = True) # display data
输出:
如输出图像所示,数据现在只有高级管理为真的行。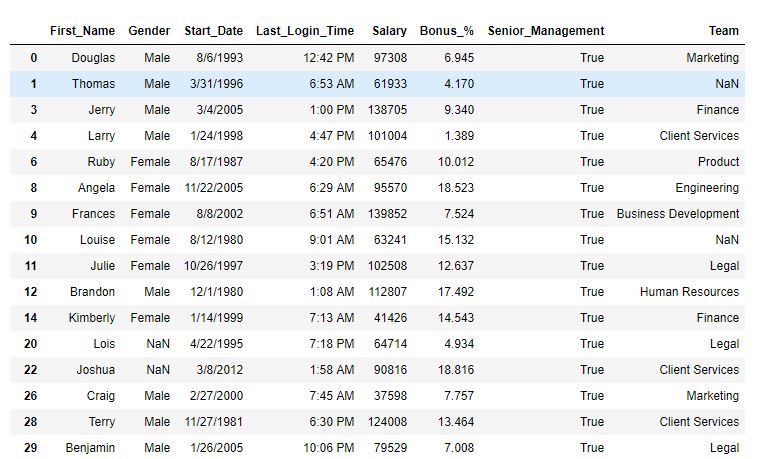
示例 2:多条件过滤
在此示例中,数据帧已在多个条件下进行过滤。在应用 query() 方法之前,列名中的空格已被替换为“_”。
# importing pandas package import pandas as pd # making data frame from csv file data = pd.read_csv("employees.csv") # replacing blank spaces with '_' data.columns =[column.replace(" ", "_") for column in data.columns] # filtering with query method data.query('Senior_Management == True and Gender =="Male" and Team =="Marketing" and First_Name =="Johnny"', inplace = True) # display data
输出:
如输出图像所示,根据应用的过滤器只返回了两行。
为什么使用查询
因为它使您能够就地创建视图和过滤器。
对于数值运算,它也比纯 python 更快。1
import pandas as pd
# using filters needs two steps
# one to assign the dataframe to a variable
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK',np.nan]
})
# another one to perform the filter
df[df['country']=='USA']
但是您可以在一个步骤中定义数据帧并对其进行查询(内存会立即释放,因为您没有创建任何临时变量)
# this is equivalent to the code above
# and uses no intermediate variables
pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK',np.nan]
}).query("country == 'USA'")
Python变量
要在查询中引用外部变量,请使用@variable_name:
import pandas as pd
import numpy as np
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK',np.nan],
'age':[23,45,45]
})
target_age = 45
df.query('age == @target_age')
或运算符
只需使用or. 不要忘记括号。
import pandas as pd
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK', 'USA'],
'age':[23,45,45]
})
df.query("(name=='john') or (country=='UK')")
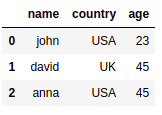 之前:源数据框
之前:源数据框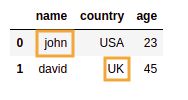 之后:只有 name
之后:只有 name'john'或 country 的行
'UK'AND 运算符
只需使用and. 不要忘记括号。
import pandas as pd
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK', 'USA'],
'age':[23,45,45]
})
df.query("(country=='USA') and (age==23)")
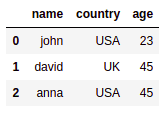 包含所有行的源数据框
包含所有行的源数据框 之后:只有一行有
之后:只有一行有country=
'USA'和age =
23多重条件
- 示例: AND 运算符
df.query((col1 == 1) and (col2 == 2))
- 示例: OR 运算符
df.query((col1 == 1) or (col2 == 2))
数组中的值
将值放入 python 数组中并使用in @myvar:
import pandas as pd
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK', 'USA'],
'age':[23,45,45]
})
names_array = ['john','anna']
df.query('name in @names_array')
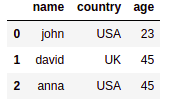 源数据框
源数据框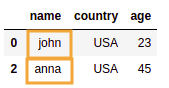 名称所在的行
名称所在的行 ['john', 'anna']不在数组中
将值放入 python 数组中并使用not in @myvar:
import pandas as pd
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK', 'USA'],
'age':[23,45,45]
})
invalid_array = ['anna']
df.query('name not in @invalid_array')
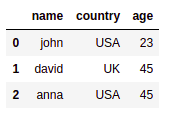 源数据框:所有行
源数据框:所有行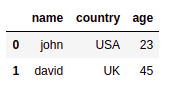 名称不在的选定行
名称不在的选定行 ['anna']转义列名
要转义特殊字符(例如空格),请将列名称括在反引号中:'`'
df = pd.DataFrame({
'name':['john','david','anna'],
'country of birth':['USA','UK', 'USA'],
'age':[23,45,45]
})
df.query('`country of birth` == "UK"')
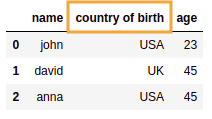 Source dataframe: one of the column
Source dataframe: one of the columnnames has spaces in it
 Selected rows where
Selected rows wherecountry of origin equals 'UK'Is null
To filter the dataframe where a column value is NULL, use .isnull()
import pandas as pd
import numpy as np
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK',np.nan]
})
df.query('country.isnull()')
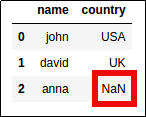 Original Dataframe
Original Dataframe Equivalent to:
Equivalent to:"where country is NULL"
Is not null
Use .notnull()
import pandas as pd
import numpy as np
df = pd.DataFrame({
'name':['john','david','anna'],
'country':['USA','UK',np.nan]
})
df.query('country.notnull()')
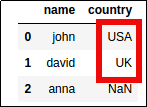 Original Dataframe
Original Dataframe Equivalent to:
Equivalent to:"where country is NOT NULL"
Like
Although like is not supported as a keyword in query, we can simulate it using col.str.contains("pattern"):
import pandas as pd
df = pd.DataFrame({
'col1':['foo','bar','baz','quux']
})
df.query('col1.str.contains("ba")')
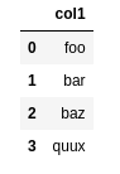 Source dataframe
Source dataframe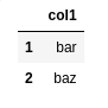 Result: filter where
Result: filter where col1 matches "ba"1 It uses numexpr under the hood: https://github.com/pydata/numexpr