问题
如何访问数据集中的特定数据?
Python和Pandas如何帮助我分析数据?
目标
描述什么是基于0的索引。
使用列标题和索引位置来处理和提取数据。
使用切片从DataFrame中选择数据集。
使用标签和基于整数的索引来选择数据框中的数据范围。
在DataFrame的子集中重新分配值。
创建一个DataFrame的副本。
查询/选择使用一组使用以下运算符的标准数据的子集:
==,!=,>,<,>=,<=。使用掩码定位数据的子集。
在Python中描述BOOLEAN对象,并使用BOOLEAN操作数据。
在本课程的第一集中,我们将CSV文件读入了熊猫的DataFrame。我们学习了如何:
- 将DataFrame保存到命名对象,
- 对数据进行基本数学运算
- 计算摘要统计信息,以及
- 根据我们加载到熊猫中的数据创建图。
在本课程中,我们将探索使用以下方法访问数据的不同部分的方法:
- 索引,
- 切片,和
- 子集。
加载我们的数据
我们将继续使用上一集中使用的调查数据集。让我们重新打开并再次读取数据:
# Make sure pandas is loaded
import pandas as pd
# Read in the survey CSV
surveys_df = pd.read_csv("data/surveys.csv")
Python中的索引和切片
我们经常想使用DataFrame对象的子集。有多种方法可以完成此操作,包括:使用标签(列标题),数字范围或特定的x,y索引位置。
使用标签选择数据(列标题)
我们使用方括号[]选择Python对象的子集。例如,我们可以species_id从surveys_df DataFrame按名称命名的列中选择所有数据。有两种方法可以做到这一点:
#提示:使用我们之前看到的.head()方法来缩短输出 #方法1:使用列名选择数据的“子集” surveys_df ['species_id'] #方法2:将列名称用作“属性”; 给出相同的输出 surveys_df.species_id
我们还可以创建一个仅包含species_id列中数据的新对象, 如下所示:
#创建一个仅包含`species_id`列的对象surveys_species surveys_species = surveys_df ['species_id']
我们也可以传递一个列名列表,作为以该顺序选择列的索引。当我们需要重组数据时,这很有用。
注意:如果DataFrame中不包含列名,则会引发异常(错误)。
#从DataFrame中选择种类并绘制列 surveys_df[['species_id','plot_id']] #当您下订单时会发生什么? surveys_df[['plot_id','species_id']] #如果您请求不存在的列会发生什么? surveys_df['speciess']
Python告诉我们追溯中的错误类型,在底部说 KeyError: 'speciess'这speciess不是有效的列名(也不是相关Python数据类型字典中的有效键)。
提醒
Python语言及其模块(例如Pandas)定义了保留字,这些保留字在分配对象和变量名时不应用作标识符。的在Python保留字实例包括布尔值
True和False,运营商and,or和not,等等。https://docs.python.org/3/reference/lexical_analysis.html#identifiers提供了Python版本3保留字的完整列表 。在命名对象和变量时,避免使用内置数据结构和方法的名称也很重要。例如,列表是内置数据类型。例如,可以将单词“列表”用作新对象的标识符
list = ['apples', 'oranges', 'bananas']。但是,您将无法使用创建空列表list()或使用将元组转换为列表list(sometuple)。
提取基于范围的子集:切片
提醒
Python使用基于0的索引。
让我们提醒自己,Python使用基于0的索引。这意味着对象中的第一个元素位于位置 0。这与其他工具(例如R和Matlab)不同,后者从1开始对对象内的元素进行索引。
# Create a list of numbers:
a = [1, 2, 3, 4, 5]
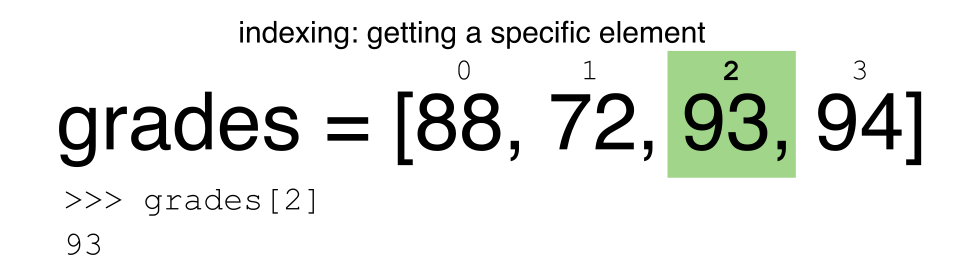
挑战-提取数据
下面的代码返回什么值?
a[0]这个怎么样:
a[5]在上面的示例中,调用
a[5]返回错误。这是为什么?关于什么?
a[len(a)]
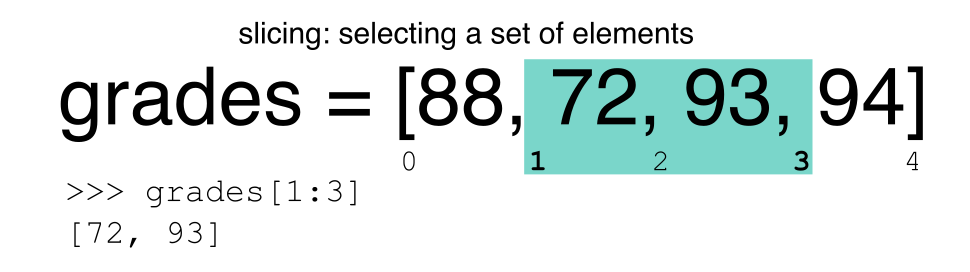
在Python中切片行的子集
使用[]运算符进行切片可从DataFrame中选择一组行和/或列。要切出一组行,请使用以下语法: data[start:stop]。在对大熊猫进行切片时,开始范围包含在输出中。停止界限是您要选择的行之后的第一步。因此,如果要选择行0、1和2,则代码应如下所示:
# Select rows 0, 1, 2 (row 3 is not selected)
surveys_df[0:3]
Python中的止损与您在Matlab和R等语言中可能使用的止损不同。
#选择前5行(行0、1、2、3、4) surveys_df [:5] #选择列表中的最后一个元素 #(切片从最后一个元素开始,并在列表的末尾结束) surveys_df [-1:]
我们还可以在DataFrame的子集中重新分配值。
但是在进行此操作之前,我们先来看一下在Python中复制对象的概念和引用对象的概念之间的区别。
在Python中复制对象与引用对象
让我们从一个例子开始:
# Using the 'copy() method' true_copy_surveys_df = surveys_df.copy() # Using the '=' operator ref_surveys_df = surveys_df
您可能会认为该代码ref_surveys_df = surveys_df创建了surveys_dfDataFrame对象的全新独特副本。但是,= 在简单语句y = x中使用运算符不会创建我们的DataFrame的副本。而是y = x创建一个新变量y,该变量引用所引用的 同一对象x。为了说明这一点的另一种方式,只有 一个对象(数据帧),都x和y参考。
相反,copy()用于DataFrame的方法将创建DataFrame的真实副本。
让我们看看当我们在引用另一个DataFrame对象的DataFrame子集中重新分配值时会发生什么:
ref_surveys_df[0:3] = 0 #将值'0'分配给DataFrame中的数据的前三行
让我们尝试以下代码:
#ref_surveys_df是使用'='运算符创建的 ref_surveys_df.head() #surveys_df是原始数据框 surveys_df.head()
这两个数据帧之间有什么区别?
当我们0为ref_surveys_df前三列分配使用 DataFrame的值时,surveys_df也会修改DataFrame。记住ref_survey_df,当我们这样做时,我们在上面创建了参考对象 ref_survey_df = surveys_df。记住surveys_df并ref_surveys_df 引用相同的确切DataFrame对象。如果其中一个更改了对象,则另一个将看到与参考对象相同的更改。
回顾和总结:
-
复制使用数据框的
copy()方法true_copy_surveys_df = surveys_df.copy() -
甲参考被使用所创建的
=操作员ref_surveys_df = surveys_df
好的,这足够了。让我们根据原始数据CSV文件创建一个全新的干净数据框。
surveys_df = pd.read_csv("data/surveys.csv")
在Python中切片行和列的子集
我们可以使用标签或基于整数的索引在行和列方向上选择特定范围的数据。
loc主要基于标签的索引。可以使用整数,但它们被解释为标签。iloc主要是基于整数的索引
要从我们的DataFrame中选择行和列的子集,我们可以使用 iloc方法。例如,我们可以选择月,日和年(如果从1开始计数,则列2、3和4),如下所示:
# iloc[row slicing, column slicing]
行切片,列切片
surveys_df.iloc[0:3, 1:4]
这给出了输出
month day year
0 7 16 1977
1 7 16 1977
2 7 16 1977
请注意,我们要求从0:3开始切片。这产生了3行数据。当您要求0:3时,实际上是在告诉Python从索引0开始并选择行0、1、2直到但不包括3。
让我们探索其他索引和选择数据子集的方法:
# 选择所有列的索引值0和10 surveys_df.loc[[0, 10], :] # What does this do? surveys_df.loc[0, ['species_id', 'plot_id', 'weight']] # 当您键入下面的代码时,会发生什么? surveys_df.loc[[0, 10, 35549], :]
注意:必须在DataFrame中找到标签,否则会得到一个KeyError。
用标签索引loc不同于用整数索引iloc。使用时loc,开始范围和停止范围都包含在内。当使用时loc,可以使用 整数,但是整数引用的是索引标签,而不是位置。例如,使用loc和选择1:4将获得与使用iloc选择1:4行不同的结果。
我们还可以使用DataFrame中的行和列位置以及iloc索引来选择特定的数据值:
dat.iloc[row, column]#iloc索引以查找特定数据元素的语法
在这个iloc例子中
surveys_df.iloc[2, 6]
给出输出
'F'
请记住,Python索引从0开始。因此,索引位置[2,6]选择DataFrame中向下3行且上方7列的元素。
挑战-范围
执行时会发生什么:
surveys_df[0:1]surveys_df[:4]surveys_df[:-1]致电时会发生什么:
surveys_df.iloc[0:4, 1:4]surveys_df.loc[0:4, 1:4]
- 这两个命令有何不同?
使用条件子集数据
我们还可以使用条件选择数据的子集。例如,我们可以选择所有年份值为2002的行:
surveys_df[surveys_df.year == 2002]
产生以下输出:
record_id month day year plot_id species_id sex hindfoot_length weight
33320 33321 1 12 2002 1 DM M 38 44
33321 33322 1 12 2002 1 DO M 37 58
33322 33323 1 12 2002 1 PB M 28 45
33323 33324 1 12 2002 1 AB NaN NaN NaN
33324 33325 1 12 2002 1 DO M 35 29
...
35544 35545 12 31 2002 15 AH NaN NaN NaN
35545 35546 12 31 2002 15 AH NaN NaN NaN
35546 35547 12 31 2002 10 RM F 15 14
35547 35548 12 31 2002 7 DO M 36 51
35548 35549 12 31 2002 5 NaN NaN NaN NaN
[2229 rows x 9 columns]
或者,我们可以选择不包含2002年的所有行:
surveys_df[surveys_df.year != 2002]
我们也可以定义一组标准:
surveys_df[(surveys_df.year >= 1980) & (surveys_df.year <= 1985)]
Python语法备忘单
当通过DataFrame的条件查询数据时,可以使用以下语法。尝试选择“调查”数据的各个子集。
- 等于:
== - 不等于:
!= - 大于,小于:
>或< - 大于或等于
>= - 小于或等于
<=
挑战-查询
在
surveys_dfDataFrame中选择包含1999年数据并且权重值小于或等于8的行的子集。您最终得到了多少行?你的邻居得到了什么?您可以
isin在Python中使用该命令根据值列表查询DataFrame,如下所示:surveys_df[surveys_df['species_id'].isin([listGoesHere])]使用该
isin函数在“调查”数据帧中查找包含特定物种的所有图。有多少记录包含这些值?
试用其他查询。创建一个查询,以查找权重值大于或等于0的所有行。
~Python中的符号可用于返回您在Python中指定的选择的相反。等于不在中。编写一个查询,以选择“调查”数据中性别不等于“ M”或“ F”的所有行。
使用口罩识别特定情况
甲掩模可以是有用的,可找到存在值的特定子集或不存在-例如,NaN时,或“不是数”的值。要了解遮罩,我们还需要了解BOOLEANPython中的对象。
布尔值包括True或False。例如,
# Set x to 5
x = 5
# What does the code below return?
x > 5
# How about this?
x == 5
当我们询问Python是否x大于5时,它返回False。这是Python所说的“不”的方法。实际上,值x是5,而5则不大于5。
要创建布尔掩码:
- 设置正确/错误标准(例如
values > 5 = True) - 然后,Python将评估对象中的每个值,以确定该值是否满足条件(正确)(错误)。
- Python创建了一个与原始对象形状相同的输出对象,但是每个索引位置都有一个
True或False值。
让我们尝试一下。让我们确定调查数据中具有空(缺失或NaN)数据值的所有位置。我们可以使用该isnull方法来执行此操作。该isnull方法将比较每个单元格的空值。如果元素的值为空,则将True在输出对象中为其分配值 。
pd.isnull(surveys_df)
输出的摘要如下:
record_id month day year plot_id species_id sex hindfoot_length weight
0 False False False False False False False False True
1 False False False False False False False False True
2 False False False False False False False False True
3 False False False False False False False False True
4 False False False False False False False False True
[35549 rows x 9 columns]
要选择存在空值的行,我们可以使用掩码作为索引来子集数据,如下所示:
surveys_df[pd.isnull(surveys_df).any(axis=1)]#要仅选择具有NaN值的行,我们可以使用'any()'方法
请注意,weight我们的DataFrame列包含许多null或NaN 值。在下一集“数据类型和格式”中,我们将探讨处理此问题的方法。
我们也可以isnull在特定的列上运行。下面的代码做什么?
# What does this do? empty_weights = surveys_df[pd.isnull(surveys_df['weight'])]['weight'] print(empty_weights)
让我们花点时间看一下上面的陈述。我们正在使用布尔对象pd.isnull(surveys_df['weight'])作为的索引surveys_df。我们要求Python选择具有NaN权重值的行。
挑战-放在一起
创建一个新的DataFrame,它仅包含具有非女性或男性性别值的观察值。将新DataFrame中的每个性别值分配给新值'x'。确定子集中的空值数量。
创建一个新的DataFrame,该数据框仅包含性别为性别或性别且权重值大于0的观察值。创建一个按重量平均堆叠的条形图,并在每个图上堆叠男性和女性值。
关键点
在Python中,可以使用索引,切片,列标题和基于条件的子集访问部分数据。
Python使用基于0的索引,其中列表,元组或任何其他数据结构中的第一个元素的索引为0。
Pandas支持常见的数据探索步骤,例如数据索引,切片和条件子集。