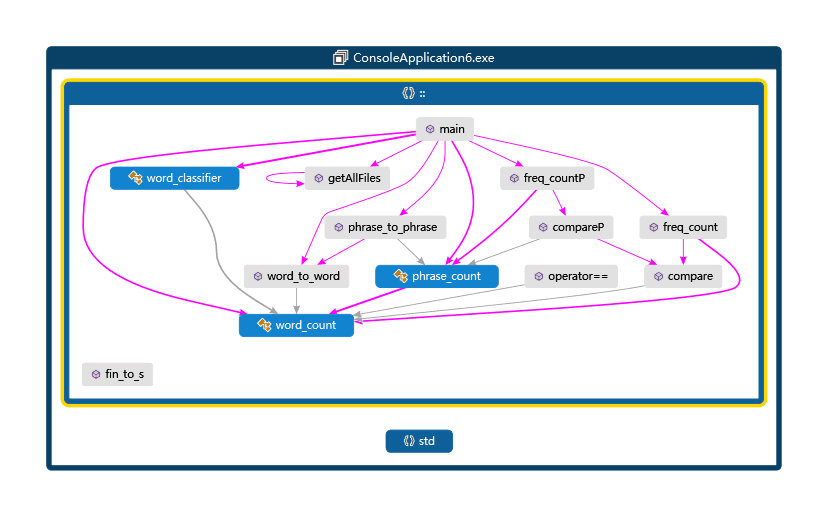
代码调用图
代码调用图的图例:(感谢刘泽@kfk的vs2015企业版的强大功能)
输出结果
因为助教给的程序是在WIndows平台上运行代码得到的结果,所以主要放出的是Windows平台下的结果,Linux平台下的结果留待以后分析。
我的结果
The number of character is:173669785
The number of line is:2278666
The number of word is:16639829
The top 10 words is:
HAVE 107383
WITH 158745
CLASS 192004
THIS 152454
THEY 145945
SPAN 116118
THAT 259186
SAID 208861
HARRY 184732
SPAN CLASS 62861
REFERENCE INTERNAL 26668
SPAN SPAN 41286
HREF LEAP 22569
THAT GOOD 61427
INTERNAL HREF 26668
SAID HARRY 24981
CLASS SPAN 23146
SAID HERMIONE 19193
CLASS REFERENCE 31289
Use Time :36
助教的结果
char_number :173654417
line_number :2278666
word_number :16629955
the top ten frequency of word :
THAT 259186
SAID 208861
CLASS 192004
HARRY 184732
WITH 158745
THIS 152454
THEY 145945
Span 116118
HAVE 107383
FROM 105494
the top ten frequency of phrase :
Span CLASS 62861
THAT GOOD 61427
Span Span 41286
CLASS Reference 31289
Reference INTERNAL 26668
INTERNAL href 26668
SAID HARRY 24981
CLASS Span 23146
href LEAP 22569
SAID HERMIONE 19193
结果对比
可以看到的是,行数的结果正确,字符和单词数的误差在一万个左右,跟总体来相比误差在0.1%以内,Top10的单词和词组的频率也是一模一样,只不过没有正序输出。
测试结果
我生成了10个测试样例,用来测试一些特殊情况。
当然,能够测试本身就说明在平台下已经可以做到命令行参数是单个文件或者文件夹了。
下面是对其的展示和分析:
1.pptx
测试结果:
Linux平台:
The number of character is:184816
The number of line is:1565
The number of word is:1718
The top 10 words is:
SLIDELAYOUTS 48
RELSPK 38
RELS 114
SLIDES 48
SLIDE5 48
NOTESSLIDE10 40
NOTESSLIDES 40
XMLPK 46
SLIDELAYOUT3 48
STEVT 36
SLIDES SLIDE2 24
NOTESSLIDES NOTESSLIDE5 20
SLIDELAYOUTS RELS 24
SLIDELAYOUTS SLIDELAYOUT12 24
SLIDES RELS 24
RELS SLIDE5 24
RELSPK SLIDELAYOUTS 13
RELS NOTESSLIDE10 20
NOTESSLIDES RELS 20
RELS SLIDELAYOUT3 24
Use Time :0
Windows平台:
The number of character is:52
The number of line is:1
The number of word is:2
The top 10 words is:
CONTENT 1
TYPES 1
CONTENT TYPES 1
Use Time :13
看起来很尴尬的答案,我感觉是编码方式有不同,然后在Win平台下读到了某个-1(在汉字或其他码字编码里)
1.txt
文件内容:
Good123 AREE Good456 AREE214 yesh
特性:普通的英文单词文件
Win平台:
The number of character is:33
The number of line is:1
The number of word is:5
The top 10 words is:
GOOD123 2
AREE 2
YESH 1
GOOD123 AREE 2
AREE GOOD456 1
AREE214 YESH 1
Use Time :4
Linux平台:
The number of character is:33
The number of line is:1
The number of word is:5
The top 10 words is:
GOOD123 2
AREE 2
YESH 1
GOOD123 AREE 2
AREE GOOD456 1
AREE214 YESH 1
Use Time :0
PS:不含英文的txt文件真是良心啊
2.txt
文件特性:空文件,看看效果
Win平台:
The number of character is:0
The number of line is:0
The number of word is:0
The top 10 words is:
Use Time :0
Linux平台:
The number of character is:0
The number of line is:0
The number of word is:0
The top 10 words is:
Use Time :0
分析:说明两个平台对空文件都能适应
8.txt
文件内容:
翘课购房款签到表来开会多花费了可分类尽快不考虑呢情况你嚄很浪费和库布里克冰冷的空气不卡的我翻了翻和
发
asf
efwf
2过3
跟4gfdgdsvsdvv去污粉3
跟65和K(……》《……》&。……*(。?&
¥JH/qQs>kFAHRH3%$t^%u5jREB zx.
V
GF
F
G3H4hg%wg?
5.J58
J4.5Fz
S
u
$
特性:共有19行,和很多汉字。
Win平台:
The number of character is:90
The number of line is:19
The number of word is:4
The top 10 words is:
EFWF 1
GFDGDSVSDVV 1
KFAHRH3 1
JREB 1
EFWF GFDGDSVSDVV 1
GFDGDSVSDVV KFAHRH3 1
KFAHRH3 JREB 1
Use Time :0
Linux平台:
The number of character is:90
The number of line is:19
The number of word is:4
The top 10 words is:
EFWF 1
GFDGDSVSDVV 1
KFAHRH3 1
JREB 1
EFWF GFDGDSVSDVV 1
GFDGDSVSDVV KFAHRH3 1
KFAHRH3 JREB 1
Use Time :0
令人惊讶,中文的问题居然也不大,只不过这些都什么破玩意。。。。
1.pdf
Linux平台:
The number of character is:1174015
The number of line is:16897
The number of word is:15033
The top 10 words is:
TYPE 566
RECT 232
ENDOBJ 993
LENGTH 340
STREAM 234
LINK 232
ANNOT 232
FILTER 234
SUBTYPE 431
GOTO 233
GOTO BORDER 232
XOBJECT SUBTYPE 139
RECT ENDOBJ 232
ENDSTREAM ENDOBJ 198
SUBTYPE LINK 232
BORDER RECT 232
ENDOBJ ENDOBJ 215
TYPE ANNOT 232
ENDOBJ TYPE 524
FILTER FLATEDECODE 226
Use Time :1
Windows平台:
The number of character is:859
The number of line is:20
The number of word is:28
The top 10 words is:
TYPE 1
XOBJECT 2
TEXT 1
STREAM 1
PROCSET 1
IMAGEI 1
FLATEDECODE 1
FORMTYPE 1
LENGTH 1
PTEX 3
TYPE XOBJECT 1
XOBJECT SUBTYPE 1
XOBJECT STREAM 1
SHADING XOBJECT 1
PROCSET TEXT 1
IMAGEI SHADING 1
FLATEDECODE FORMTYPE 1
FORMTYPE LENGTH 1
LENGTH PTEX 1
PTEX FILENAME 1
Use Time :0
分析:看到这种结果我感觉真的伤不起。。。看起来Liunux平台下的编码更适合,至少上面的答案感觉更加合理一些,至少没有莫名其妙的遇到文件结束符而结束遍历。
1.php
文件特性:随便找的自己写过的php文件,既有中午又有英文
Windows平台:
The number of character is:1539
The number of line is:45
The number of word is:130
The top 10 words is:
INLINE 6
HTML 3
HREF 8
GLASS 3
ECHO 10
BOOK 4
INFO 4
CLASS 6
DISPLAY 6
STYLE 11
STYLE DISPLAY 6
HEIGHT AUTO 2
INFO HREF 3
ECHO TABLE 2
DISPLAY INLINE 6
ADMIN STYLE 2
STYLE HEIGHT 3
GLASS STYLE 3
SYSTEM EXCELSIOR 2
CLASS GLASS 3
Use Time :0
Linux平台:
The number of character is:1539
The number of line is:45
The number of word is:130
The top 10 words is:
INLINE 6
HTML 3
HREF 8
GLASS 3
ECHO 10
BOOK 4
INFO 4
CLASS 6
DISPLAY 6
STYLE 11
STYLE DISPLAY 6
HEIGHT AUTO 2
INFO HREF 3
ECHO TABLE 2
DISPLAY INLINE 6
ADMIN STYLE 2
STYLE HEIGHT 3
GLASS STYLE 3
SYSTEM EXCELSIOR 2
CLASS GLASS 3
Use Time :0
分析: 只要是能够是两个平台上都用文本文档打开而不会出乱码的文件,得到的结果都含有沁人心脾的味道。
1.css
文件特性: 类似于1.php,随便找了个模板库里的。
Windows平台下:
The number of character is:6590
The number of line is:320
The number of word is:534
The top 10 words is:
COLOR 26
TEXT 23
BACKGROUND 22
HSLA 33
BORDER 27
WIDTH 21
SHADOW 22
FONT 26
GLASS 16
MARGIN 20
SHADOW HSLA 22
RGBA TEXT 11
FONT SIZE 13
MARGIN AUTO 14
SIZE FONT 13
OVERFLOW HIDDEN 11
FAMILY AVENIR 13
TEXT SHADOW 11
FONT FAMILY 13
BORDER RADIUS 12
Use Time :0
Linux平台:
The number of character is:6590
The number of line is:320
The number of word is:534
The top 10 words is:
COLOR 26
TEXT 23
BACKGROUND 22
HSLA 33
BORDER 27
WIDTH 21
SHADOW 22
FONT 26
GLASS 16
MARGIN 20
SHADOW HSLA 22
RGBA TEXT 11
FONT SIZE 13
MARGIN AUTO 14
SIZE FONT 13
OVERFLOW HIDDEN 11
FAMILY AVENIR 13
TEXT SHADOW 11
FONT FAMILY 13
BORDER RADIUS 12
Use Time :0
分析:效果不错。
jieshi.docx
文件特性:类似于pptx,属于会爆乱码的文件。
Linux平台下:
The number of character is:4791
The number of line is:63
The number of word is:68
The top 10 words is:
CONTENT 2
TYPES 2
RELS 6
WORD 14
DOCUMENT 4
DOCPROPS 4
CORE 2
THEME 4
STYLES 2
XMLPK 9
XMLPK WORD 5
XMLPK DOCPROPS 2
WORD STYLES 2
RELS WORD 2
WORD RELS 2
WORD WEBSETTINGS 2
WORD SETTINGS 2
WORD DOCUMENT 2
WORD FONTTABLE 2
THEME THEME1 2
Use Time :0
Windows平台下:
The number of character is:96
The number of line is:3
The number of word is:2
The top 10 words is:
CONTENT 1
TYPES 1
CONTENT TYPES 1
Use Time :0
分析:这种文件,我都已经不抱希望了,没有办法按照合适的方式解码的话,两个平台的结果大相径庭是很显然的。
当然,Linux下的结果还是看起来好一点。
toefl文件夹
文件特性:一个装toefl资料的文件夹,里面有一个rar和四个pdf
Linux平台:
The number of character is:2671446
The number of line is:37968
The number of word is:22789
The top 10 words is:
TYPE 784
ENDSTREAM 440
LEFT 405
STREAM 440
GROUP 360
RIGHT 405
FONT 379
LENGTH 453
ENDOBJ 1011
PAGE 342
FILTER FLATEDECODE 273
TYPE GROUP 180
ENDOBJ TYPE 203
TYPE PAGE 180
ENDOBJ FILTER 217
LENGTH STREAM 327
PROCSET TEXT 180
PARENT RESOURCES 180
FLATEDECODE LENGTH 244
ENDSTREAM ENDOBJ 440
Use Time :0
Windows 平台下:
The number of character is:3121
The number of line is:54
The number of word is:141
The top 10 words is:
TYPE 13
TRUE 3
ENDOBJ 10
DEVICERGB 3
STREAM 4
FLATEDECODE 4
IMAGE23 4
GROUP 6
FILTER 4
PAGES 6
ENDOBJ TYPE 6
LANG STRUCTTREEROOT 3
TRUE ENDOBJ 3
LENGTH STREAM 3
MARKINFO MARKED 3
PAGES LANG 3
STRUCTTREEROOT MARKINFO 3
TYPE CATALOG 3
KIDS ENDOBJ 3
FILTER FLATEDECODE 4
Use Time :1
分析:显然Linux平台下的结果看起来是更加符合这个文件里面含有的东西和字数。
11.txt
文件内容:
文件特性: 专门用来测试单词和词组的保存
Linux平台下:
The number of character is:62
The number of line is:1
The number of word is:7
The top 10 words is:
TEST123 5
TESTAFS 1
TEST123TEST324 1
TEST123 TEST3456 2
TEST3456 TESTAFS 1
TESTAFS TEST13 1
TEST13 TEST123TEST324 1
TEST123TEST324 TEST123 1
Use Time :0
Windows平台下:
The number of character is:62
The number of line is:1
The number of word is:7
The top 10 words is:
TEST123 5
TESTAFS 1
TEST123TEST324 1
TEST123 TEST3456 2
TEST3456 TESTAFS 1
TESTAFS TEST13 1
TEST13 TEST123TEST324 1
TEST123TEST324 TEST123 1
Use Time :0
分析:并没有什么问题~
总结: 设计了11个测试样例,其中发现在Win平台下,许多文件的编码格式会导致读取出现严重问题,因此,觉得助教选择最终的测试平台为linux ubuntu 是更加正确的选择。
在可以用ASCII方式编解码及可以用文本文档或gedit打开的文件中,两个平台的结果都是一致的,而词组和单词的样例测试也证明了这一点。
实验代码:
#include <fstream> #include<string> #include <vector> #include <sstream> #include <iostream> #include <stdio.h> #include <vector> #include <sstream> #include<functional> #include <time.h> #include<unordered_map> using namespace std; class word_count; void getAllFiles(string path, vector<string>& files); int fin_to_s(string &str, vector<string> &files, int i); class word_classifier { public: string* str; //string* temp;// string* num_rear; int num; word_classifier(); ~word_classifier(); int judge(char c, word_count* word);// //void classify(char c);// void clear(); void set(word_count* word); }; class word_count { public: //string* temp;// string* str;// string* num;// int num_rear;// int str_count;// int flag;// int size;// string* word;// word_count* next_ptr; word_count(); ~word_count(); }; class phrase_count { public: word_count* phrase1; word_count* phrase2; int phr_count;// int flag;// phrase_count* next_ptr; phrase_count(); ~phrase_count(); }; void word_to_word(word_count* word, word_count* word1); int freq_count(word_count* &arr1, word_count* temp, int flag); int compare(word_count* word, word_count* word1, int& flag); void phrase_to_phrase(phrase_count* phrase, phrase_count* phrase1);// int freq_countP(phrase_count* &arr1, phrase_count* temp, int flag);// int compareP(phrase_count* phrase, phrase_count* phrase1, int& flag1, int &flag2);// #ifdef WIN32 #include <io.h> void getAllFiles(string path, vector<string>& files) { long hFile = 0; struct _finddata_t fileinfo; string p; if ((hFile = _findfirst(p.assign(path).append("\*").c_str(), &fileinfo)) != -1) { do { if ((fileinfo.attrib & _A_SUBDIR)) { if (strcmp(fileinfo.name, ".") != 0 && strcmp(fileinfo.name, "..") != 0) { files.push_back(p.assign(path).append("\").append(fileinfo.name)); getAllFiles(p.assign(path).append("\").append(fileinfo.name), files); } } else { files.push_back(p.assign(path).append("\").append(fileinfo.name)); } } while (_findnext(hFile, &fileinfo) == 0); _findclose(hFile); } } #endif #ifdef __linux__ #include <dirent.h> void getAllFiles(string path, vector<string>& files) { string name; DIR* dir = opendir(path.c_str()); dirent* p = NULL; while ((p = readdir(dir)) != NULL) { if (p->d_name[0] != '.') { string name = path + "/" + string(p->d_name); files.push_back(name); //cout << name << endl; if (p->d_type == 4) { getAllFiles(name, files); } } } closedir(dir); } #endif int fin_to_s(string &str, vector<string> &files, int i) { ifstream infile; infile.open(files[i]); infile >> str; infile.close(); return 0; } void word_to_word(word_count* word, word_count* word1) { // *(word1->str) = *(word->str); *(word1->num) = *(word->num); word1->num_rear = word->num_rear; // word1->str_count = word->str_count; // word1->flag = word->flag; word1->size = word->size; *(word1->word) = *(word->word); word1->next_ptr = word->next_ptr; } word_classifier::word_classifier() { // num = 0; str = new string(); num_rear = new string(); //temp = new string(); } word_classifier::~word_classifier() { // delete str; delete num_rear; } void word_classifier::set(word_count* word) { // string stri; //word->temp = temp; stri = *str + *num_rear; *(word->str) = stri; *(word->word) = *str; word->str_count = 1; word->size = num; word->num = num_rear; word->num_rear = num - num_rear->size();// return; } void word_classifier::clear() { // num = 0; str->clear(); num_rear->clear(); } int word_classifier::judge(char c, word_count* word) { // if (c >= 'a'&&c <= 'z') c = c - 32;// if (c >= '0'&&c <= '9' || c <= 'Z'&&c >= 'A') { //* if (c >= '0'&&c <= '9') { // ** if (num < 4) { // *** clear(); return 0; } else { // num_rear->append(1, c); num++; return 2; } } else { // if (num_rear->empty()) { str->append(1, c); num++; return 2; } else { str->append(*num_rear); num += num_rear->size(); str->append(1, c); num_rear->clear(); return 2; } } } else { if (num < 4) { clear(); return 0; } else { set(word); clear(); return 1; } } } word_count::word_count() { str = new string(); num = new string(); word = new string(); next_ptr = NULL; size = 0; str_count = 0; num_rear = 0; flag = 0; } word_count::~word_count() { delete str; } bool operator==(const word_count& word1, const word_count& word2) { return (*(word1.word) == *(word2.word)) && (word1.num_rear == word2.num_rear); } int freq_count(word_count* &arr1, word_count* temp, int flag) { word_count* arr = arr1; if (arr == NULL) { // arr = new word_count(); arr->str_count = -1; } if (arr->next_ptr == NULL) { // arr->next_ptr = temp; flag = 1; temp->flag = 1; } else { // if (temp->flag == 1) return 0;// word_count* parent = arr; word_count* change = NULL; arr = arr->next_ptr; int i = 0;// int t = temp->str_count;// int result = -100;// int flag_equal = -1;// // while (i < 10 && arr->next_ptr != NULL) { // if (t > arr->str_count) { //) * flag_equal = -1; if (change == NULL) change = parent;// ** else { //** int j = change->str_count - arr->str_count; if (j>0) { //change ** change = parent; } else if (j == 0) { //j int k = compare(change, arr, flag); if (k == -1) change = parent; } //else } }//end if else if (t == arr->str_count) { // if (change == NULL) { // result = compare(arr, temp, flag); if (result == -1) { // change = parent; flag_equal = 1;// }//end if //result=0, } else { // if (flag_equal == 1) { // result = compare(change, temp, flag); if (result == -1) { // change = parent; }//end if }//end if //flag_equal!=1, }//end else }//end else if i++; parent = arr; arr = arr->next_ptr; }//end while if (i<10) { // arr->next_ptr = temp; temp->flag = 1; }//end if else if (i == 10) { //10 if (change != NULL) { //change temp->next_ptr = change->next_ptr->next_ptr; change->next_ptr->flag = 0; temp->flag = 1; change->next_ptr = temp; }//end if }//end else if }//end else }//end freq_count int freq_countP(phrase_count* &arr1, phrase_count* temp, int flag) { phrase_count* arr = arr1; if (arr == NULL) { arr = new phrase_count(); arr->phr_count = -1; } if (arr->next_ptr == NULL) { arr->next_ptr = temp; flag = 1; temp->flag = 1; } else { if (temp->flag == 1) return 0; phrase_count* parent = arr; phrase_count* change = NULL; arr = arr->next_ptr; int i = 0;// int t = temp->phr_count;// int para1, para2 = 0;// int result = -100;// int flag_equal = -1; while (i < 10 && arr->next_ptr != NULL) { // if (t > arr->phr_count) { // * flag_equal = -1; if (change == NULL) change = parent;// ** else { // ** int j = change->phr_count - arr->phr_count; if (j>0) { // ** change = parent; } else if (j == 0) { // int k = compareP(change, arr, para1, para2); if (k == -1) change = parent; } //else } }//end if else if (t == arr->phr_count) { // if (change == NULL) { // result = compareP(arr, temp, para1, para2); if (result == -1) { // change = parent; flag_equal = 1;// }//end if //result=0, } else { // if (flag_equal == 1) { // result = compareP(change, temp, para1, para2); if (result == -1) { // change = parent; }//end if }//end if }//end else }//end else if // i++; parent = arr; arr = arr->next_ptr; }//end while if (i<10) { // arr->next_ptr = temp; temp->flag = 1; }//end if else if (i == 10) { if (change != NULL) { // temp->next_ptr = change->next_ptr->next_ptr; change->next_ptr->flag = 0; temp->flag = 1; change->next_ptr = temp; }//end if }//end else if }//endelse }//end freq_count phrase_count::phrase_count() { phrase1 = new word_count(); phrase2 = new word_count(); next_ptr = NULL; phr_count = 0; } phrase_count::~phrase_count() { delete phrase1; delete phrase2; } void phrase_to_phrase(phrase_count* phrase, phrase_count* phrase1) { phrase1->flag = phrase->flag; phrase1->next_ptr = phrase->next_ptr; phrase1->phr_count = phrase->phr_count; word_to_word((phrase->phrase1), (phrase1->phrase1)); word_to_word((phrase->phrase2), (phrase1->phrase2)); } int compare(word_count* word, word_count* word1, int& flag) { // int w0 = word->num_rear, w1 = word1->num_rear;
个人作业项目报告(三)输出结果及测试样例的结果(附代码)
flag = 0; string s0(*(word->str), 0, w0), s1(*(word1->str), 0, w1); if (s0 < s1) return -1;// else if (s0 > s1) return 1;// else { if (word->num < word1->num) flag = -1; else if (word->num > word1->num) flag = 1; return 0; } }//end compare int compareP(phrase_count* phrase, phrase_count* phrase1, int& flag1, int &flag2) { // int s1, s2 = 0; s1 = compare(phrase->phrase1, phrase1->phrase1, flag1); if (s1<0) { return -1; } else if (s1 > 0) { return 1; } else { s2 = compare(phrase->phrase2, phrase1->phrase2, flag2); if (s2 < 0) { return -1; } else if (s2 > 0) { return 1; } else { return 0; } } }//end compareP int main(int argc, char* argv[]) { unordered_map<string, word_count> wordmap;//Hash table for word unordered_map<string, phrase_count> phrasemap;//hash table for phrase vector<string> files; string path; if (argv[1] == NULL) { path.append("C:/test/11.txt"); } else { path.append(argv[1]); } time_t start, stop; start = time(NULL); if (path.find(".") != string::npos) {// if the path is a file path files.push_back(path); } else { getAllFiles(path, files); //get all file paths } int size = files.size();//length of file int con = 1;//parameter; int line_count = 0;//count of line int char_count = 0;//count of character int word_all_count = 0;//count of word word_classifier classifier_word;//char-word analyzer word_count* word_temp = NULL; word_count* word_temp1 = NULL; word_count* arr = new word_count(); word_count* word_test = NULL;//using for pointing to word_count in H_table; string str_test;//used to store *(word_temp->word) int flag = 0; //flag of judging word int phrase_all_count = 0;//count of phrase phrase_count* phrase_temp = NULL; phrase_count* arrp = new phrase_count(); phrase_count* phrase_test = NULL;//using for pointing to phrase_count in H_table; word_temp = new word_count(); word_temp1 = new word_count(); phrase_temp = new phrase_count(); int phr_flag = 0;//fag of phrase,judging if should get phrase char c = 0, optr = 0;//optr is a copy of c ifstream infile;//ptr of file for (int i = 0; i < size; i++) { //going to all files infile.open(files[i],ios::in); //judge if the path is a folder or document if (infile.fail()) { continue;}// fail,meaning a folder else { //get the length of file,and store in FileSize int begin = infile.tellg(); int end = begin; int FileSize = 0; infile.seekg(0, ios_base::end); end = infile.tellg(); infile.seekg(0, ios_base::beg); FileSize = end - begin; //end of getting file if (FileSize != 0) { line_count += 1; for (int j = 0; j <= FileSize; j++) { //operation in each File //get a char and count infile.get(c); if (32 <= c&&c <= 126) char_count = char_count + 1; if (c == ' ') line_count = line_count + 1; optr = c; c = 0;// clear c,avoiding mistakes //end of counting char and line flag = classifier_word.judge(optr, word_temp); //judging if the word is ok if (flag == 1) { //get a word, flag = 0; //cout << *(word_temp->str) << endl; word_all_count += 1; str_test = *(word_temp->word); if (wordmap.find(str_test) == wordmap.end()) { //if don't exist word_to_word(word_temp, &wordmap[str_test]); word_test = &wordmap[str_test]; freq_count(arr, word_test, 1); } else { //if exist wordmap[str_test].str_count++; word_test = &wordmap[str_test]; //change the rear con = (*(word_test->num) > *(word_temp->num)); if (con == 1) { //word_temp has a smaller rear *(word_test->num) = *(word_temp->num); *(word_test->str) = *(word_test->word) + *(word_test->num); } freq_count(arr, word_test, 1); } if (phr_flag == 0) { phr_flag = 1; word_to_word(word_test, word_temp1); } else if (phr_flag == 1) { phrase_temp->phrase2 = word_temp; phrase_temp->phrase1 = word_temp1; str_test = *(word_temp1->word) + *(word_temp->word); if (phrasemap.find(str_test) == phrasemap.end()) { //if don;t exist phrase_to_phrase(phrase_temp, &phrasemap[str_test]); phrasemap[str_test].phr_count = 1; phrase_test = &phrasemap[str_test]; freq_countP(arrp, phrase_test, 1); word_to_word(word_temp, word_temp1); } else { //if exist phrasemap[str_test].phr_count++; phrase_test = &phrasemap[str_test]; freq_countP(arrp, phrase_test, 1); word_to_word(word_temp, word_temp1); } if (optr == 0) phr_flag = 0; } }//end if else }//end for 2 infile.get(optr); if(infile.eof())infile.close(); }//end if }//end else }//end for1 string dist = "Result.txt"; ofstream ofn(dist); ofn << "The number of character is:" << char_count << endl; ofn << "The number of line is:" << line_count << endl; ofn << "The number of word is:" << word_all_count << endl; word_count* ptr_temp = arr; phrase_count* ptr_tempp = arrp; word_count* q = arr; phrase_count*qp = arrp; int i = 0, j = 0;// ofn << "The top 10 words is:" << endl; while (ptr_temp->next_ptr != NULL&&i<10) { //print the top 10 word ptr_temp = ptr_temp->next_ptr; ofn << *(ptr_temp->str) + ' '; ofn << ptr_temp->str_count << endl; i++; } i = 0; while (ptr_tempp->next_ptr != NULL&&i<10) { //print the top 10 phrase ptr_tempp = ptr_tempp->next_ptr; ofn << *(ptr_tempp->phrase1->str) + ' ' + *(ptr_tempp->phrase2->str) + ' '; ofn << ptr_tempp->phr_count << endl; i++; } stop = time(NULL); ofn << "Use Time :" << stop - start << endl; infile.close(); ofn.close(); }//end main