基于gtid搭建主从MySQL
一、GTID的使用
想让主从之间使用gtid的方式同步数据,需要我们在配置文件中开启mysql对gtid相关的配置信息
找到my.cnf ,在mysqld模块中加入如下的配置。(主库从库都这样)
# on表示开启,OFF表示关闭
gtid-mode = ON
# 下面的两个变量必须开启,否则MySQL拒绝启动
log-slave-updates = 1
log-bin = MySQL-bin
# 必须开启,否则MySQL不启动,因为MySQL的SQL和gtid
# 许多MySQL的SQL和GTID是不兼容的。比如开启ROW 格式时,CREATE TABLE … SELECT
# 在binlog中会形成2个不同的事务,GTID无法唯一。
# 另外在事务中更新MyISAM表也是不允许的。
enforce_gtid_consistency = 1 #
log-bin-index = MySQL-bin.index
对主库来说依然需要创建一个用于同步数据的账号
mysql> grant replication slave on *.* to MySQLsync@"10.123.123.213" identified by "MySQLsync123";
Query OK, 0 rows affected, 1 warning (0.00 sec)
对从库中执行如下命令:即可完成主从同步
CHANGE MASTER TO
MASTER_HOST='10.123.123.123',
MASTER_USER='MySQLsync',
MASTER_PASSWORD='MySQLsync123',
MASTER_PORT=8882,
MASTER_AUTO_POSITION = 1;
这种自动找点对方式,相对于之前使用bin-log+position找点就显得及其方便了。
省去了手动查看master执行到那个binlog,以及binlog的position。
做了如上的配置后,还是可以继续使用fileName和position找点,但是不推荐这样做了,如果非要这样做,设置MASTER-AUTO-POSITION=0
假设我们想在现有的主从集群上新加一个从库,如果这个主库已经运行很久了,binlog肯定曾经被purge过,所以如果主库中原来的数据不重要,不介意主从数据不一致,在从库中执行:
reset master;
# 缺失的GTID集合设置为purged ,执行这个命令请确保从库:@@global.gtid_executed为空
set global gtid_purged = ‘主库中曾经purge过的gtid记录’
# 然后通过MASTER_AUTO_POSITION=1完成自动找点
如果介意主从数据强一致可以考虑使用可以热备份的工具从主库拷贝数据到从库,完成数据的同步再在从库执行如上set global gtid_purged = 'xxx'
热备份工具如:xtrabackup , 它可以拷贝物理文件和redolog来支持热备份
二、GTID的简介
GTID (global transcation identifier)
GTID是MySQL5.6版本中添加进来的新特性 ,通过GTID取代同步模式1中手动查找fileName和position, 实现了自动找点。
比如一条update有语句进入MySQL之后经历如下过程:
1. 写undolog
2. 写redolog(prepare)
3. 写binlog
4. 写redolog(commit)
MySQL5.6之后加入了GTID新特性后,update语句经历如下过程
1. 写undolog # 回滚
2. 写redolog(prepare)# 保证提交的不会丢失
3. 写一个特殊的Binlog Event,类型为GTID_Event,指定下一个事务的GTID
4. 写binlog # 主从同步事物使用
5. 写redolog(commit)
这个GTID的作用就是用于去唯一的标示一个事物的id。
主从之间,之所以能完成数据的同步,是因为从库会dump主库记录的binlog, 主库将自己成功执行过的事物都写在binlog用于给从库回放。当我们在mysql的配置文件中将上面的配置都打开时,主库在记录binlog的同时在binlog中会混杂着gtid的信息,这个gtid和当前事物唯一对应。
当从库向主库发送同步数据当请求时:bin-log和gtid都会传送到slave端,slave在回放日志同步数据时,同样会使用gtid写bin-log,这样主库和从库之间的数据,就通过GTID强制性的关联并且保持同步了。
下图中浅色的背景是一条完整的binlog,从binlog的记录中可以发现,gtid也写在binlog中,当前事物提交commit后,还会为下一个事物生成一个gtid待使用。
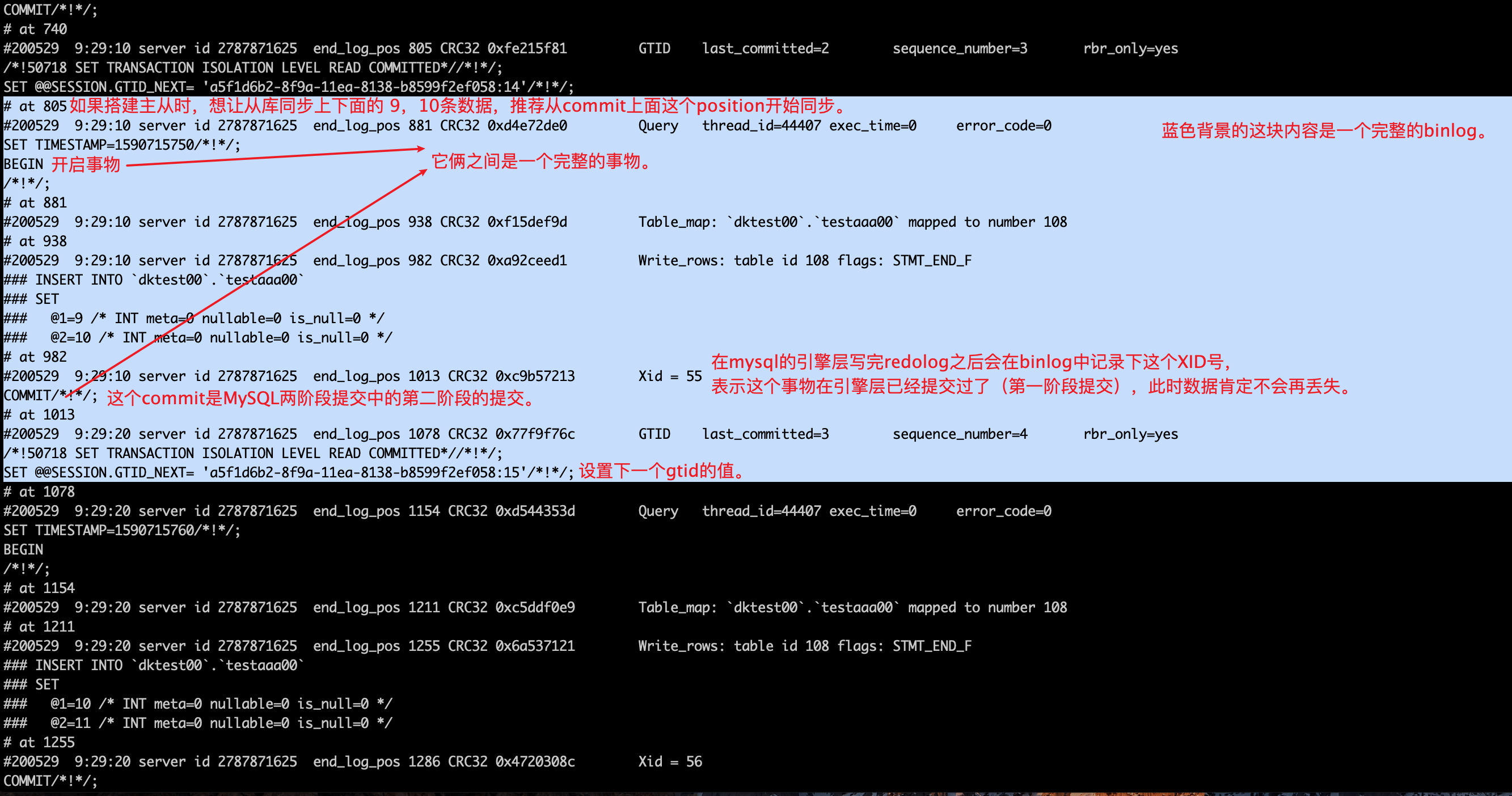
三、GTID的构成
gtid由两部分组成,server_uuid:transaction_id
-
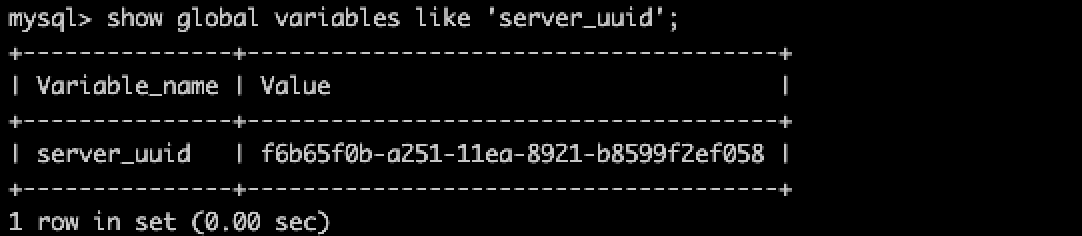
server_uuid是一个只读变量,保存在
MySQL/var/auto.cnf, 也可以通过命令查看show global variables like 'server_uuid';第一种查看方式:
cat auto.cnf
第二种查看方式:
transaction_id是事物id, 一般他会递增。
四、查看GTID的执行情况
在主库中查看gtid的执行情况:

如果不出意外的话,从库中的gtid执行情况和主库是一样的。
这时如果我们往主库插入一条信息,主库的gtid_executed则会变成:
f6b65f0b-a251-11ea-8921-b8599f2ef058:1-5
同样去从库中查看,从库的gtid信息和主库是一样的。
4.1 gtid_executed
它既可以是一个global类型的变量,也可以是一个session级别的变量。是只读的,记录着曾经执行过的gtid集合。比如:f6b65f0b-a251-11ea-8921-b8599f2ef058:1-5 表示曾经执行过1~5共五个事物。
global和session之间的区别:如果在global级别下,我们打开一个会话然后设置值,关掉这个窗口,打开一个新的窗口,依然能看在上一个被关闭的窗口设置的值。 如果在session级别下,打开一个窗口A设置值,然后打开一个新的窗口重新查看是看不到在绘画A中修改过的值的。
4.2 gtid_own
它既可以是一个global类型的变量,也可以是一个session级别的变量。是只读的,它记录的是当前实例正在执行的gtid,以及对应的线程id。
4.3 gtid_purged
它是一个全局的变量,purge就是丢弃的意思,而bin-log是实现主从之间的数据同步,主要是起到一个中间者的作用,主从数据同步之后,binlog其实就可以被清除了,线上的日志文件被清理最勤的日志文件恐怕就binlog,可能每隔几个小时或者1天清理一次。
这个gtid_purged所装载的就是被丢弃的bin-log对应的gtid集合, gtid_purged是gtid_executed的子集,是不能被随意更改的,只有在@@global.gtid_executed为空的情况下才能修改这个值。
认识了上面的几个变量后:整理一下整个流程:
-
开启GTID模式后,我们指定MASTER_AUTO_POSITION=1。然后
start slave时,从库会计算Retrieved_Gtid_Set和Executed_Gtid_Set的并集(通过show slave status可以查看),然后把这个GTID并集发送给主库。主库将从库请求的GTID集合和自己的gtid_executed比较,把从库GTID集合里缺失的事务全都发送给从库。从库再拿着这些gtid在自己本地回放事物,同步数据。 -
gtid是有幂等性的,从库碰到原来使用过的gtid会直接跳过。
-
如果从库缺失的GTID已经被主库pruge了,那么从库报1236错误,IO线程中断。
此外,从库的Retrieved_Gtid_Set 和 Executed_Gtid_Set在哪里查看呢?
通过show slave status 查看
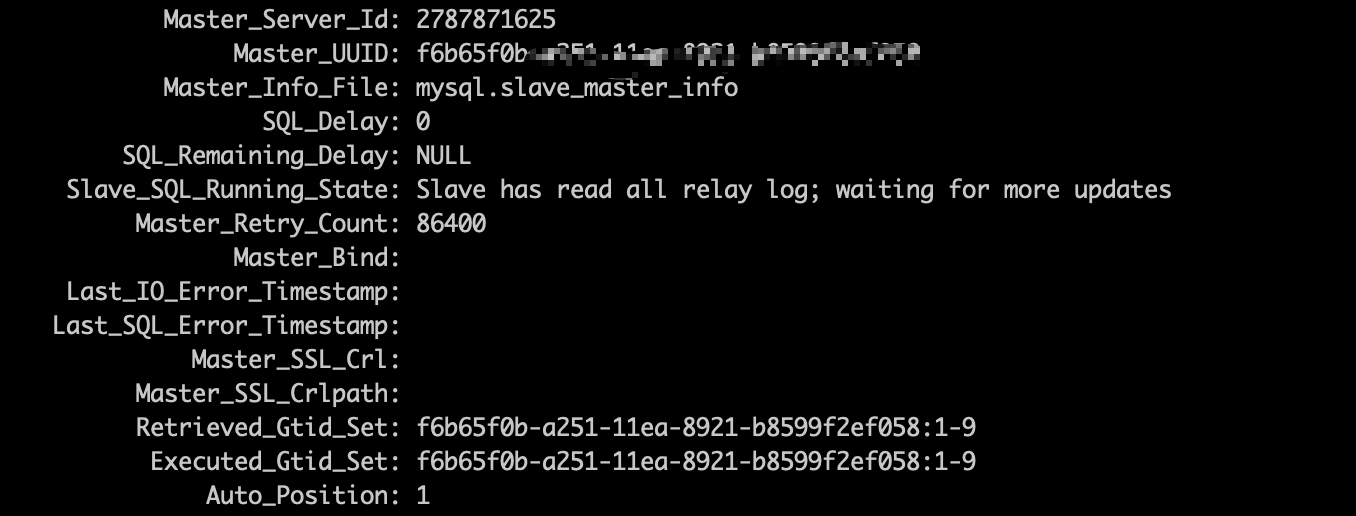
再看这张图:
这张图是从库的gtid相关信息:
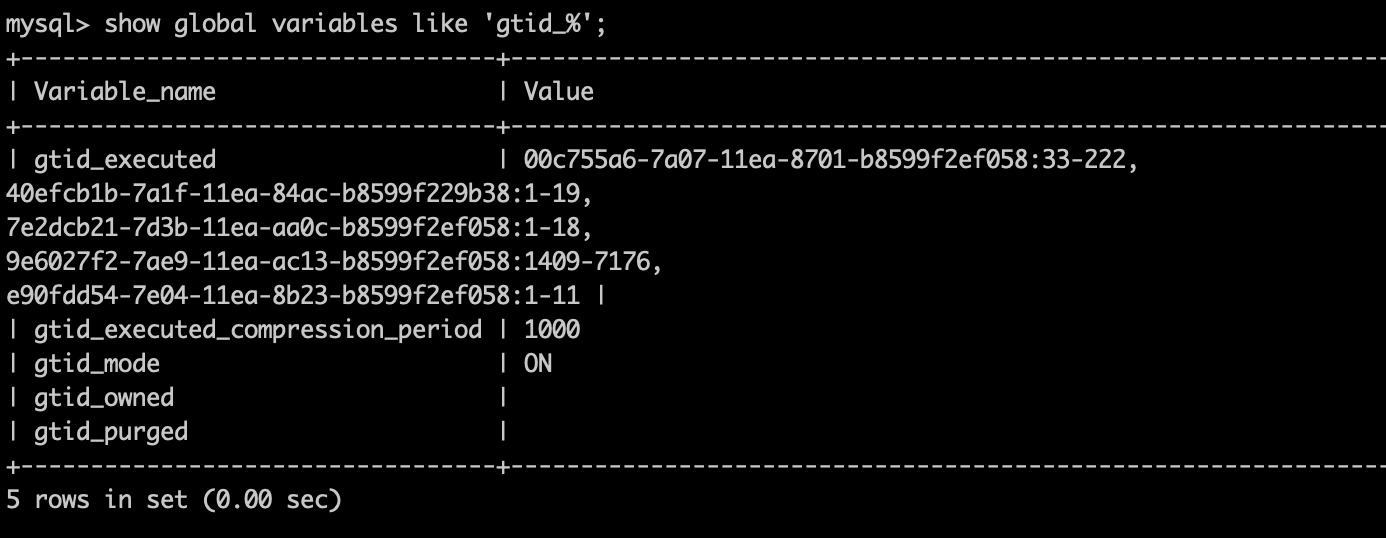
从张图乍一看gtid的信息是比较乱的:
server_uuid后缀为058结尾的是从库同步的主库数据时产生的。
server_uuid后缀以b38(从库自己的server_uuid)结尾的记录,其实是我直接在从库insert数据产生的。
五、MySQL的幂等性
默认情况下MySQL幂等级别是:strict , 表示严格模式。 举个例子,在这种情况下:假设id为主键,假设数据库中已经存在了一条id=1 ,value = 1 的数据,我们重复的插入id=1 , value=2的新数据mysql会爆出 主键冲突的错误。
如果我们将幂等模式调整成:idemptent ,再往MySQL中插入一条id=1,value = 2的数据,此时不会爆出主键冲突,这条新数据会将原来value = 1 覆盖成value=2。
开启主从的模式下从库的: slave_exec_mode 参数一般会被设置成:idemptent , 这样可以保证从库中的数据和主库中的数据保持一致。 并且不会发生这种问题:比如主库中没有id = 100的数据,故主库中可以顺利写入id=100的数据, 从库中有id=100的数据,但是因为开启幂等模式,从库不会爆出主键冲突的错误而中断主从关系,而是使用主库binlog中的新值去覆盖当前存在的旧值。
六、拓展:
假设存在这样一种场景:
有一对主从正常运行保持数据同步状态。然后意外发生了:从库在回放主库binlog时有一个gtid对应的事物执行失败了。具体一点,比如主库现在 excuted_gtid = 1-20 , 然后从库回放到第10条事物时还没问题,但是回放到第11条事物时因为数据对不起来,执行失败了,紧接着断开了主从同步到关系。
如果是使用 binlog+position 实现的主从同步,我们可以设置 sql_slave_skip_counter 让从库跳过失败的事物完成再恢复同步关系。
但是使用gtid构建的主从同步就不能skip事物了,它是自动找点的。
并且你通过show variables like '%gtid%' 可以看一下gtid的信息, gtid_next是原子自增的。
mysql> show variables like '%gtid%' ;
+----------------------------------+------------------------------------------+
| Variable_name | Value |
+----------------------------------+------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_next | AUTOMATIC |
| gtid_owned | |
| gtid_purged | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-9 |
| session_track_gtids | OFF |
+----------------------------------+------------------------------------------+
8 rows in set (0.01 sec)
查看主库的执行状态:也能看到gtid的序号是连续的。
mysql> show master status;
+------------------+----------+--------------+------------------+------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+------------------------------------------+
| mysql-bin.000006 | 194 | | | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-9 |
+------------------+----------+--------------+------------------+------------------------------------------+
所以如果出现了上面的情景,可以像下面这样做:
# 第gtid == 11 出问题了,就跳过它
set global sql_slave_skip_counter = 11;
# 执行begin commit 不会让现有的gtid+1,仅仅是交一个空事物,占据这个gtid=11的位置
BIGIN;COMMIT;
七、实验:
小实验1:
可以做一个小实验:
先往主库中写入一条数据,然后刷新日志落盘
mysql> INSERT INTO `xxx`.`yyy` (`id` , `val`) VALUES (NULL , '123');
Query OK, 1 row affected (0.01 sec)
mysql> flush logs;
Query OK, 0 rows affected (0.00 sec)
mysql> show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000005 | 506 |
| mysql-bin.000006 | 194 |
+------------------+-----------+
2 rows in set (0.00 sec)
退出mysql查看所有的日志:

然后我们手动执行 rm -rf mysql-bin.00000*
再登陆mysql查看gtid_pured的变化情况:(你会发现,当我手动删除主库的binlog时,gtid_purged中没有任何记录)
mysql> show global variables like 'gtid%';
+----------------------------------+------------------------------------------+
| Variable_name | Value |
+----------------------------------+------------------------------------------+
| gtid_executed | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-7 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+----------------------------------+------------------------------------------+
5 rows in set (0.00 sec)
当然上面手动rm -rf删除日志的方式是在开玩笑,真实的purged操作如下:
mysql> show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000005 | 506 |
| mysql-bin.000006 | 194 |
+------------------+-----------+
2 rows in set (0.00 sec)
mysql> purge binary logs to 'mysql-bin.000006';
Query OK, 0 rows affected (0.00 sec)
mysql> show binary logs;
+------------------+-----------+
| Log_name | File_size |
+------------------+-----------+
| mysql-bin.000006 | 194 |
+------------------+-----------+
1 row in set (0.00 sec)
mysql> show global variables like 'gtid%';
+----------------------------------+------------------------------------------+
| Variable_name | Value |
+----------------------------------+------------------------------------------+
| gtid_executed | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-9 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-9 |
+----------------------------------+------------------------------------------+
5 rows in set (0.00 sec)
命令中的purge binary logs to 'xxx' 是通过mysql的机制去删除binlog。删除的范围是 mysql-bin00000x之前的所有binlog,而不包含 mysql-bin00000x。
小实验2:
假设我现在有AB两台主从MySQL,两台都开启gtid, 我先通过gtid 完成主从之间的同步关系,插入几条数据后,主从的gtid值都为 1-10 。
然后我开始搞事情:断开主从,先往主库写入一条数据(gtid=11)。
mysql> INSERT INTO `dktest00`.`testaaa00` (`id` , `val`)VALUES (NULL , '123');
Query OK, 1 row affected (10.00 sec)
mysql> show master status;
+------------------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------------------------------+
| mysql-bin.000006 | 732 | | | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-11 |
+------------------+----------+--------------+------------------+-------------------------------------------+
**再通过 binlog + position 完成两者都同步关系。再往主库中插入一条数据:
# set position = 732
# binlog = f6b65f0b-a251-11ea-8921-b8599f2ef058:1-11
mysql> INSERT INTO `dktest00`.`testaaa00` (`id` ,`val`)VALUES (NULL , '123');
Query OK, 1 row affected (0.00 sec)
然后我去查看从库的gtid信息:
mysql> show global variables like 'gtid%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| gtid_executed | f6b65f0b-a251-11ea-8921-b8599f2ef058:1-10:12 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | |
+----------------------------------+----------------------------------------------+
5 rows in set (0.00 sec)
我们会发现,虽然是使用position+binlog同步数据,但是只要gtid开启了,gtid就会记录曾经执行的事物的信息
那并且如果我们定位potion = 732 ,从库回放的事物就不会包含 gtid = 11, 这一点我们可以通过查看binlog作证
mysqlbinlog --no-defaults -vv /binlog的绝对路径。
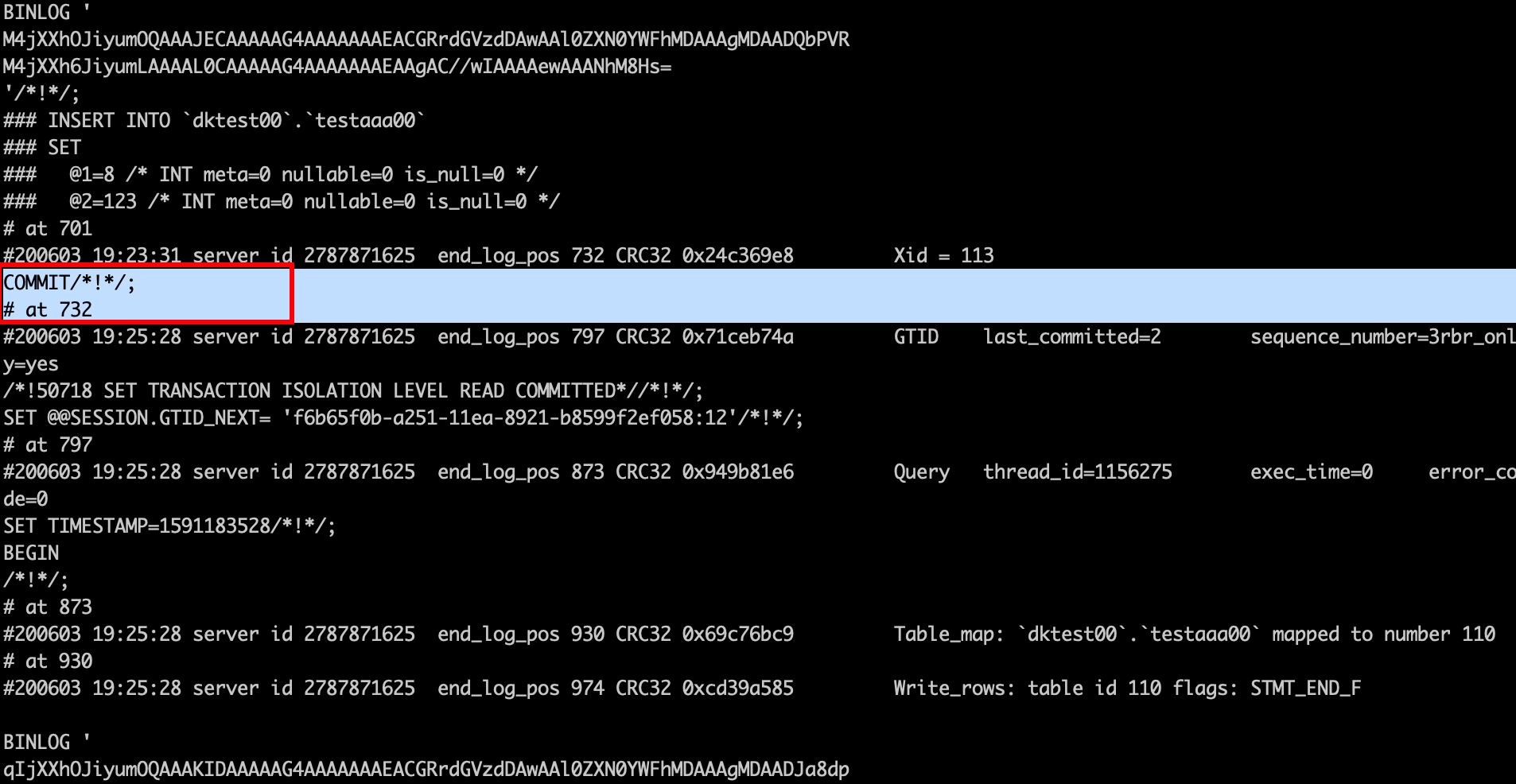
这说明啥事呢? 比如现在主库中有1,2,3条数据,然后你执行show master status; 看到这个position = 732
那这个732其实不是不包含第三条数据的。换句话说从库 从732同步数据,不会同步上第3条数据。
然后我们在此基础上继续搞事情:我们断开主从,重新设置从库position 为 732的上一个事物的位点(459),然后观察从库的 slave staus 情况。
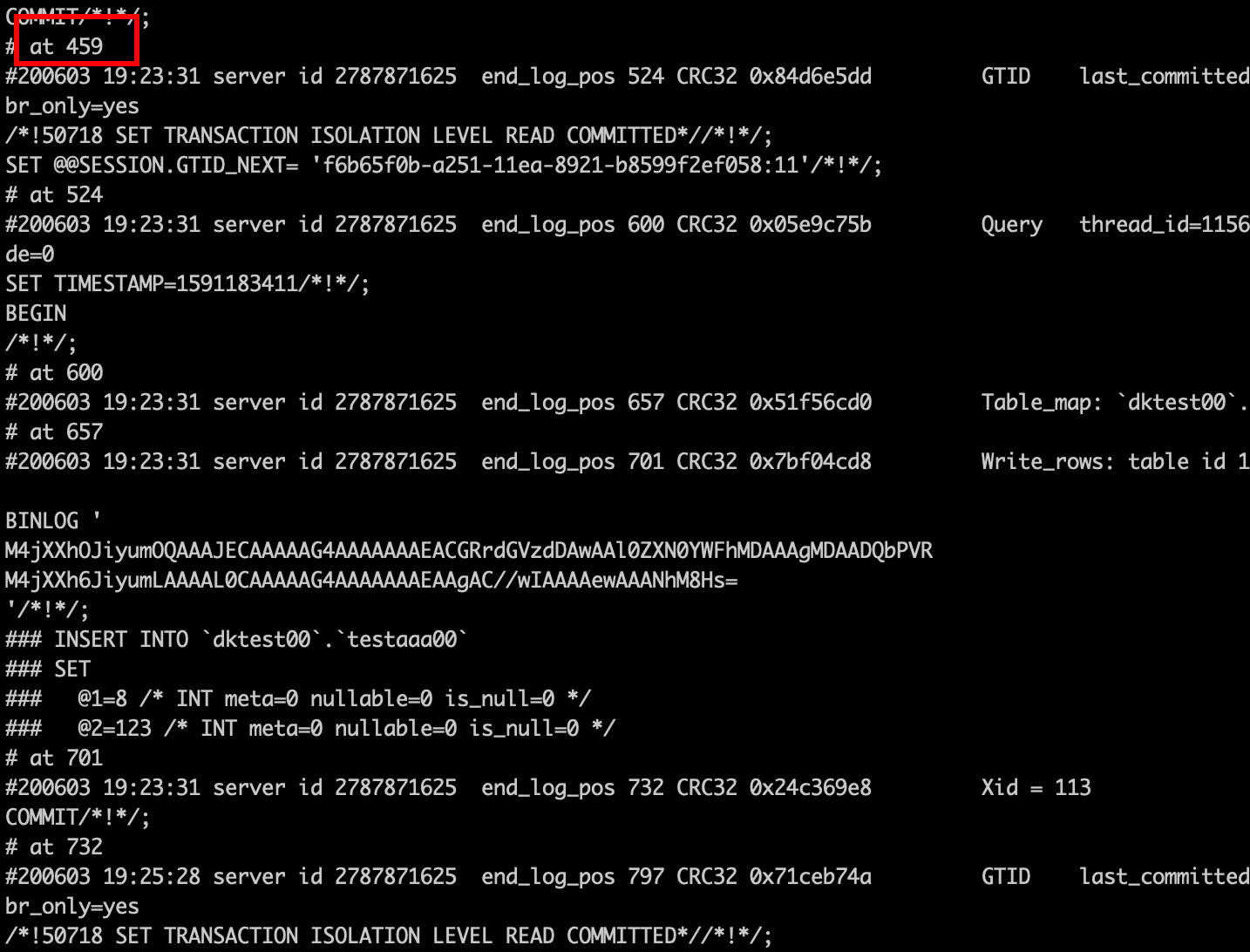
开始同步后查看从库中的数据,可以发现刚才跳过的gtid=11对应的数据已经被同步回来了。
如果我们不开启gtid的话,在最后一步的操作中会导致主从中断,因为从库的slave_exec_mode会处于严格格式,肯定会发生主键冲突。但是当我们开启了gtid,在最后一步的同步的过程中,因为开启了gtid,从库只会将刚刚会同步刚才跳过的gtid=12的数据,其他已经存在的不再重复同步。
通过命令 show variables like ‘%slave%’ 可以查看到和slave相关的所有配置信息