| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzu/2020SpringW |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/2020SpringW/homework/10281 |
| 这个作业的目标 | 创建熟悉使用Github,完成提交疫情统计程序 |
| 作业正文 | .... |
| 其他参考文献 | https://www.cnblogs.com/hengyumo/p/12276133.html |
| Github仓库地址 | https://github.com/abse4411/InfectStatistic-main |
一、阅读《构建之法》
1.第一章 概论
对于“程序=数据结构+算法”,第一次看到这句话在《C++ Primer Plus》前面部分,如果结合算法与数据结构这门课,自己所编写程序就是由这种结构所组成的。
但在在接下来学习中,程序不在是以专门的目的(为解决某一问题)编写时,需要不断扩展与修改,虽然写是写得出来,但是涉及到更改,程序要进行修改会带来一系列得挑战。
当人们遇到某一问题时,当然会不断地尝试,最后总结出经验教训来解决问题,这也是人能不断发展原因。
对我来说,从大一到大三也是一个不断尝试的过程。为了程序分析设计变得有条理,学习面向对象分析和设计方法;为了程序变得可扩展或者灵活,学习设计模式来改善程序;为了程序能进行版本关系,学习相关得版本控制软件... ...
其实这些不知不觉中开始步入软件工程的相关内容,只是当时还没有软件工程的概念,即使现在也没有深刻的理解。对于软件工程,我总是理解为程序生命周期的解决方案。
对于软件工程或计算机科学来说,我觉得软件工程位于计算机科学高层,因此软件工程需要计算机科学的支持。虽然没有选择计算机这个专业,但是心里还是觉得计算机科学还是比较厉害。当然,软件工程和计算机科学孰优孰劣,我是没有发言权的。
2.第二章 个人技术和流程
测试,对于一个程序验证是否符合预期和修复错误很有必要。
在早期,我接触到的最早的测试,就是编写算法题目,通过一个名为“TEST.bat”的批处理文件:
@echo off
if "%1"=="" goto loop
copy input%1.txt C.in >nul
echo Problem Test
echo Data %1
time<enter
C
time<enter
fc C.out output%1.txt
del C.in
del C.out
pause
goto end
:loop
for %%i in (0 1 2 3 4 5 6 7 8 9) do call %0 %%i
:end
通过这个批处理文件自动处理程序输入,把程序输出结果的文件与答案文件进行比较,然后最后列出程序的运行时间,以及和答案的差异,进行程序的正确检验。
之后才慢慢接触到单元测试。对于单元测试,我想就是把原本以一个程序单元换成了以程序各模块、方法等粒度更细的测试,这样做可以方便排查程序出错的范围,同时也能各个测试合格的模块组合来提高组合起来的大模块合格率。当然了,对于算法程序正确性还是需要严格的理论证明。
对于程序性能的优化,在以前无非就是改进算法或进行策略的优化。对于现在高级语言的编写来说,你的代码或部分都是调用别人写好的代码,且大部分也不能更改源代码,这是要么自己编写实现代码,或者通过性能分析工具来分析瓶颈问题选择合适策略重新优化代码。
3.第三章 软件工程师的成长
时至今日,对软件工程师还有一段很远的距离,毕竟大学大部分接触实际项目,今后还是要不断努力。
4.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 2*60 |
| Estimate | 估计这个任务需要多少时间 | 10*60 | 14*60 |
| Development | 开发 | 5*60 | 4*60 |
| Analysis | 需求分析 (包括学习新技术) | 40 | 30 |
| Design Spec | 生成设计文档 | 60 | 2*60 |
| Design Review | 设计复审 | 60 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 2*60 | 3*60 |
| Design | 具体设计 | 60 | 50 |
| Coding | 具体编码 | 4*60 | 5*60 |
| Code Review | 代码复审 | 60 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 3*60 | 2*60 |
| Reporting | 报告 | 2*60 | 3*60 |
| Test Report | 测试报告 | 2*60 | 3*60 |
| Size Measurement | 计算工作量 | - | - |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 2080 | 2480 |
二、解题思路
1.需求
实现一个命令行程序,该程序从指定文件目录下中下,读取所有命名符合规范"年-月-日.log.txt"的文件。如,一个符合规范的文件名"2020-01-22.log.txt",其中给定的文件中日期不一定连续。
这些文件出现的每行可能出现的内容符合如下列举情况:
<省> 新增 感染患者 n人
<省> 新增 疑似患者 n人
<省1> 感染患者 流入 <省2> n人
<省1> 疑似患者 流入 <省2> n人`
<省> 死亡 n人`
<省> 治愈 n人`
<省> 疑似患者 确诊感染 n人
<省> 排除 疑似患者 n人
// 该文档并非真实数据,仅供测试使用
如,一个示例文件内容:
福建 新增 感染患者 23人
福建 新增 疑似患者 2人
浙江 感染患者 流入 福建 12人
湖北 疑似患者 流入 福建 2人
安徽 死亡 2人 新疆 治愈 3人
福建 疑似患者 确诊感染 2人
新疆 排除 疑似患者 5人
// 该文档并非真实数据,仅供测试使用
注意,
// 该文档并非真实数据,仅供测试使用
该行不是需要处理的内容,或者说当遇到“//”开头行,无需进行处理,忽略即可。
现在,要求你根据常识通过命令行指定的截止日期、指定的省份或全国计算出指定类型(感染患者、疑似患者、治愈,死亡)人数的数量并输出到指定文件。
该命令可能的命令选项及参数说明如下:
-log 指定日志目录的位置,该项必会附带。
-out 指定输出文件路径和文件名,该项必会附带。
-date 指定日期,不设置则默认为所提供文件标识中最新的一天。
-type 可选择[ip: infection patients 感染患者,sp: suspected patients 疑似患者,cure:治愈 ,dead:死亡患者],使用缩写选择,如 -type ip 表示只列出感染患者的情况,-type sp cure则会按顺序【sp, cure】列出疑似患者和治愈患者的情况,不指定该项默认会列出所有情况。
-province 指定列出的省,如-province 福建,则只列出福建,-province 全国 浙江则只会列出全国、浙江,
例如,
$ java InfectStatistic list -date 2020-01-22 -log D:/log/ -out D:/output.txt
注意,java InfectStatistic表示执行主类InfectStatistic,“list”为命令
该命令表示,会到D:/log/ -out目录下,处理所有命名符合规范的文件,然后把截止2020-01-22日的情况输出到指定文件D:/output.txt。
因为没有指定-type选项你应该依次列出“感染患者 疑似患者 治愈 死亡”人数。
又由于没有指定-province选项,你应该列出文件所有有出现省份和全国的情况,即使有的省份并未出现,也要输出,可以认为该省份所有类型人数为0。如果出现要输出全国情况(-province选项指定输出中含有全国或者没有提供-province选项),全国情况这一行行必须是输出文件的第一行,同时其他省份输出按名称拼音升序排序。
一个可能的输出文件示例如下
全国 感染患者22人 疑似患者25人 治愈10人 死亡2人
福建 感染患者2人 疑似患者5人 治愈0人 死亡0人
浙江 感染患者3人 疑似患者5人 治愈2人 死亡1人
// 该文档并非真实数据,仅供测试使用
注意,
// 该文档并非真实数据,仅供测试使用
该行一定师输出文件最后一行。
给出目录下的文件标识的日期不一定是连续的。例如,某个目录有以下文件:
2020-01-20.log.txt
2020-01-22.log.txt
2020-01-23.log.txt
2020-01-27.log.txt
这时如果-date选项指定的日期为2020-01-25,可以认为2020-01-24~2020-01-25没有变化,只需处理2020-01-20.log.txt、2020-01-22.log.txt、2020-01-23.log.txt这三个个文件即可,相当于-date选项指定的日期为2020-01-23
2.实现思路
该题目处理过程比较容易理解,就是把该处理文件处理完后保存起来,最后把各个文件处理结果对应相加后提取相应结果就是答案。
所以处理过程大体分为四个步骤:
- 读入文件
- 转换数据
- 根据需求处理数据
- 输出到文件
由于是命令行方式读取参数,所以需要涉及一个能接受并处理指定参数的命令行解析器,然后把解析结果传递到处理数据的地方。我们可以假设有一个命令(该命令完成题目所需功能)。因为考虑到命令以后可能会有多个,因此可以实现这个命令管理器,注册我们我们提供的命令,然后命令管理器根据提供的命令调用指定命令,然后传递参数给该命令就行了。
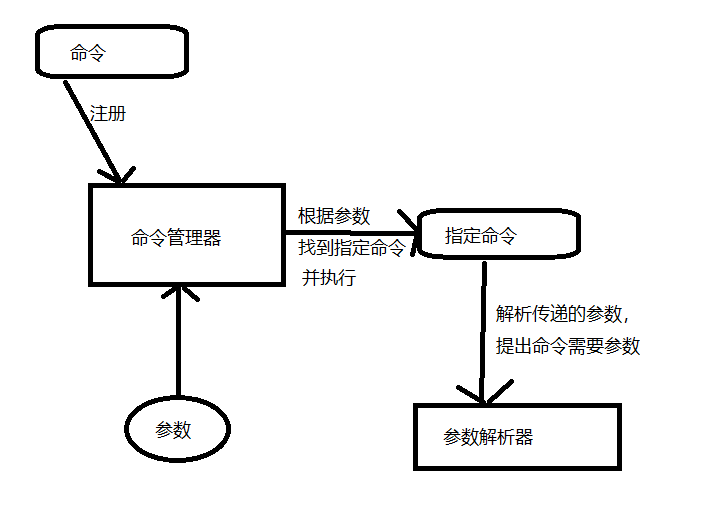
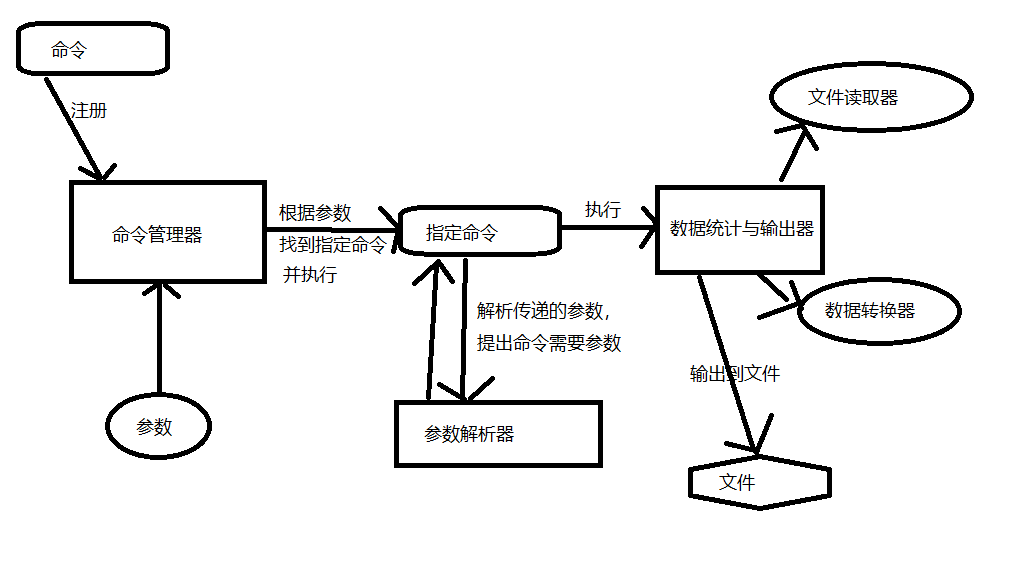
如何处理数据?我们四个步骤可以分为四个模块,不过我这里后两个步骤合并到一起了。因此三大模块如下:
- 文件读取器
- 数据转换器
- 数据统计与输出器
文件读取器负责讲指定的文件读出并转化为字符串数组。数组转换器字符串数组转换成可处理的对象,最后数据统计与输出器负责计算提取相应数据并输出。
三、实现过程
1.参数处理
参数类Parameter设计,标识一个选项和参数值:
class Parameter {
private String name;
private Object value;
}
参数读取规则类ParameterRule设计,标识选项时该选项参数是否需要,或者可以多个参数值。
class ParameterRule {
private final boolean valueRequired;
private final boolean multivalued;
}
有了以上两个类之后我们构建一个参数读取器把String[] 类型参数,转换成List
class ParameterHelper {
public static List<Parameter> resolve(final String[] args, final Map<String, ParameterRule> ruleMap) {
}
}
在转换成参数形式后,命令就可以根据需求处理了。
2.命令构建与执行
把命令抽象成一个接口,它能通过String[]类参数执行:
interface Command {
void invoke(String[] args) ;
}
提供一个命令管理器,它可以提供注册或者取消注册一个命令,当要执行命令时,根据参数带来命令名称,从已注册的命令查找、传递参数并执行。
class CommandManager {
private Map<String, Command> map;
public CommandManager() {
}
public Command register(String name, Command command) {
}
public Command unregister(String name) {
}
public void invoke(String[] args) {
}
}
命令流程顺序图如下:
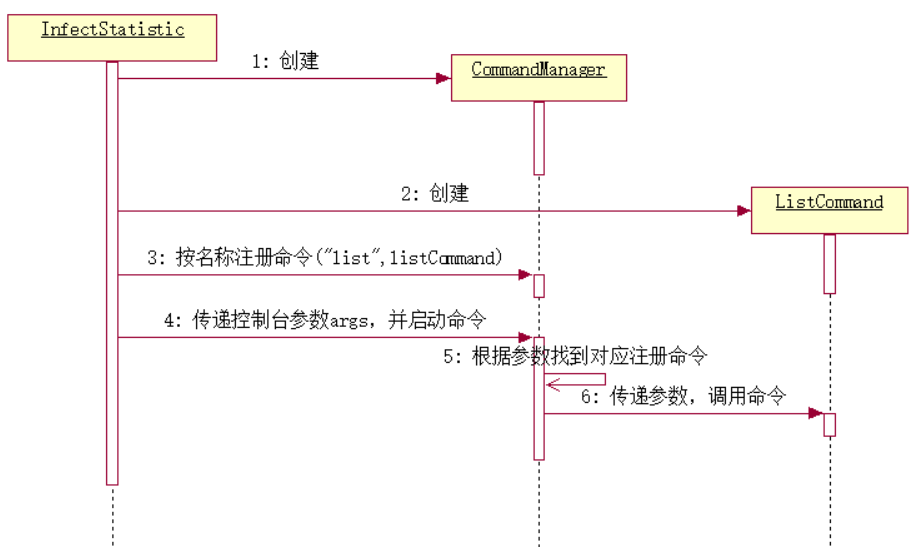
3.数据读取,转换与处理
根据之前的三个模块,设计以下三个类:
-
InfectFileReader只是简单将数据从文件读出,把文件的每一行转化成字符串,最后返回整个字符串数组。
class InfectFileReader { private final String ENCODING; public InfectFileReader() { } public InfectFileReader(String encoding) { } public String[] read(File file) { } } -
InfectDataParser类负责将InfectFileReader读出的数据转换成可处理的InfectionItem对象,一个InfectionItem对象存储了某个省份某天所有类型人数的信息,最后把所有处理对象以InfectionItem集合返回。
class InfectDataParser { protected void handleUnknownRow(String row) { } public Collection<InfectionItem> parse(String[] rows) { } protected int getNumberByAttr(String attr) { } }class InfectionItem { public String name; public int patient; public int survivor; public int suspect; public int dead; @Override public String toString() { } } -
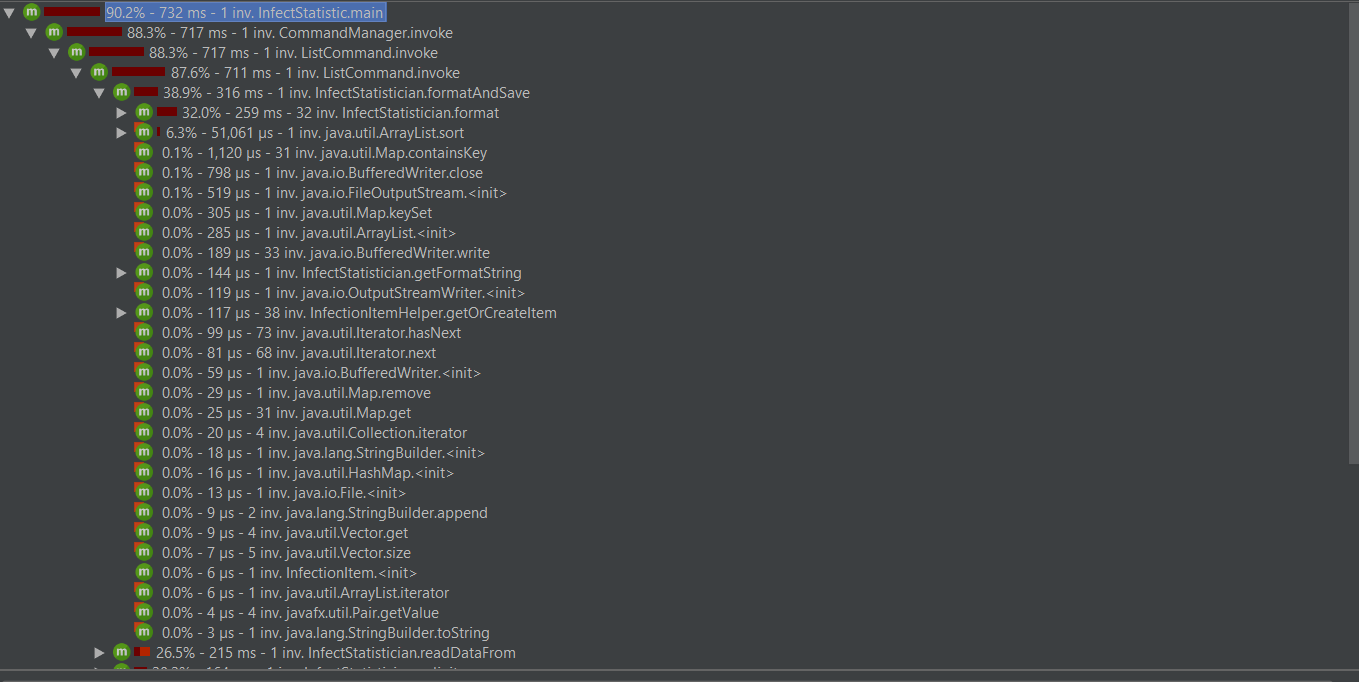
InfectStatistician类协调InfectFileReader和InfectDataParser进行文件数据处理,处理完后数据按日期归档到以前,然后可以进行数据计算和输出。
class InfectStatistician { protected Vector<Pair<LocalDate, Collection<InfectionItem>>> data; public void readDataFrom(String path, LocalDate endDate) { } private void maintainDateBound(LocalDate date) { } protected String getFormatString(Collection<String> types) { } protected String format(String format, InfectionItem item) { } public void formatAndSave(Collection<String> provinces, Collection<String> types, String fileName, String encoding) { } }readDataFrom函数处理流程

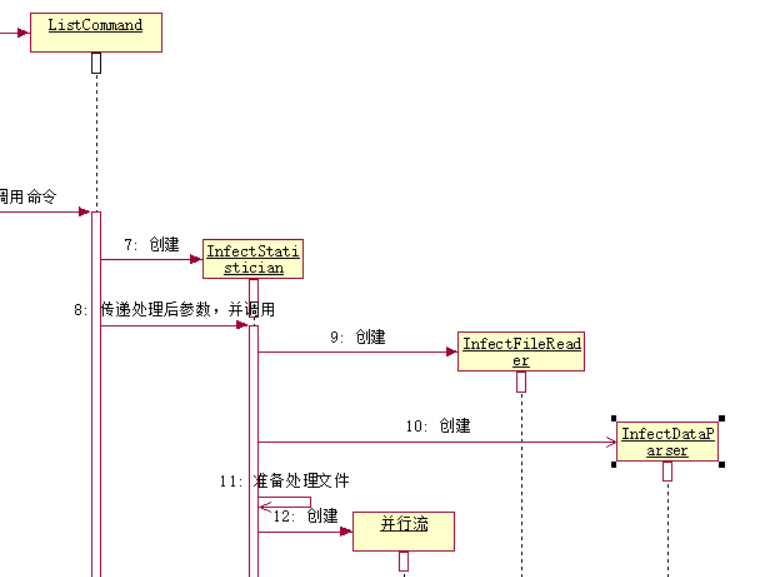
4.整合
把之前的结合起来,得到如下顺序图:
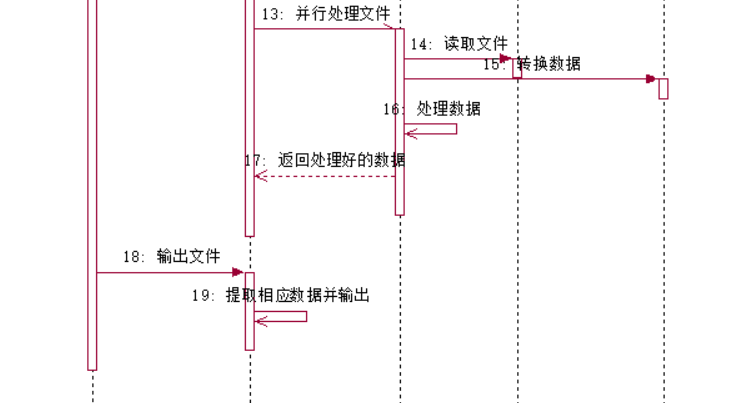
四、代码说明
-
如何转换数据?这里使用正则匹配+if-else结构(看起来有点长):
public Collection<InfectionItem> parse(String[] rows) { Map<String, InfectionItem> map = new HashMap<>(256); for (String row : rows) { String[] attrs = row.split("\s+"); if (row.matches(NEW_PATIENT)) { InfectionItem item = InfectionItemHelper.getOrCreateItem(map, attrs[0]); item.patient = item.patient + getNumberByAttr(attrs[3]); } else if (row.matches(NEW_SUSPECT)) { InfectionItem item = InfectionItemHelper.getOrCreateItem(map, attrs[0]); item.suspect = item.suspect + getNumberByAttr(attrs[3]); } else if (row.matches(SURE_PATIENT)) { InfectionItem item = InfectionItemHelper.getOrCreateItem(map, attrs[0]); int newPatient = getNumberByAttr(attrs[3]); item.suspect = item.suspect - newPatient; item.patient = item.patient + newPatient; } else if (row.matches(EXCLUDE_SUSPECT)) { InfectionItem item = InfectionItemHelper.getOrCreateItem(map, attrs[0]); item.suspect = item.suspect - getNumberByAttr(attrs[3]); } else if (row.matches(NEW_DEAD)) { InfectionItem item = InfectionItemHelper.getOrCreateItem(map, attrs[0]); int dead = getNumberByAttr(attrs[2]); item.patient = item.patient - dead; item.dead = item.dead + dead; } else if (row.matches(NEW_SURVIVOR)) { InfectionItem item = InfectionItemHelper.getOrCreateItem(map, attrs[0]); int survivor = getNumberByAttr(attrs[2]); item.patient = item.patient - survivor; item.survivor = item.survivor + survivor; } else if (row.matches(PATIENT_INFLOW)) { InfectionItem from = InfectionItemHelper.getOrCreateItem(map, attrs[0]); InfectionItem to = InfectionItemHelper.getOrCreateItem(map, attrs[3]); int num = getNumberByAttr(attrs[4]); from.patient = from.patient - num; to.patient = to.patient + num; } else if (row.matches(SUSPECT_INFLOW)) { InfectionItem from = InfectionItemHelper.getOrCreateItem(map, attrs[0]); InfectionItem to = InfectionItemHelper.getOrCreateItem(map, attrs[3]); int num = getNumberByAttr(attrs[4]); from.suspect = from.suspect - num; to.suspect = to.suspect + num; } else { handleUnknownRow(row); } } return map.values(); } 为以后处理新以后增的内容,最后调用handleUnknownRow(row)来处理switch结构无法处理行。子类重写此方法来处理新增的内容。
protected void handleUnknownRow(String row) { if (row.matches(ANNOTATION)) { return; } throw new InfectDataParseException("不能识别的内容:" + row); } -
在读取文件和转换时候用到并行流:
public void readDataFrom(String path, LocalDate endDate) throws InfectStatisticException { ready = false; File targetDir = new File(path); if (!(targetDir.exists() && targetDir.isDirectory())) { throw new InfectStatisticException(path + ":不存在或者不是一个目录"); } this.minDate = this.maxDate = null; this.endDate = endDate; File[] files = targetDir.listFiles((dir, name) -> name.matches(FILE_NAME_PATTERN)); if (files == null) { throw new InfectStatisticException(path + " 指定目录的下没有命名符合规范日志文件"); } this.data = new Vector<>(files.length); List<Pair<LocalDate, File>> dateFilePairs = new LinkedList<>(); for (int i = 0; i < files.length; i++) { try { String fileName = files[i].getName(); LocalDate date = LocalDate.parse(fileName.substring(0, fileName.indexOf('.'))); maintainDateBound(date); if (this.endDate != null && this.endDate.isBefore(date)) { continue; } dateFilePairs.add(new Pair<>(date, files[i])); } catch (DateTimeParseException e) { System.out.println(files[i].getAbsolutePath() + ":文件名中的日期无效, " + e.getMessage()); } } if (endDate != null && maxDate != null) { if (endDate.isAfter(maxDate) || endDate.isBefore(minDate)) { throw new InfectStatisticException("日期超出范围,已知范围:" + minDate + "至" + maxDate); } } InfectFileReader reader = new InfectFileReader(); InfectDataParser parser = new InfectDataParser(); dateFilePairs.parallelStream().forEach((dateFile) -> { try { Collection<InfectionItem> items = parser.parse(reader.read(dateFile.getValue())); data.add(new Pair<>(dateFile.getKey(), items)); } catch (IOException | InfectDataParseException e) { System.out.println("无法处理文件" + dateFile.getValue().getAbsolutePath() + "," + e.getMessage()); } }); ready = true; } 首先选出不超过指定日期的文件,减少不必要的读入:
for (int i = 0; i < files.length; i++) { try { String fileName = files[i].getName(); LocalDate date = LocalDate.parse(fileName.substring(0, fileName.indexOf('.'))); maintainDateBound(date); if (this.endDate != null && this.endDate.isBefore(date)) { continue; } dateFilePairs.add(new Pair<>(date, files[i])); } catch (DateTimeParseException e) { System.out.println(files[i].getAbsolutePath() + ":文件名中的日期无效, " + e.getMessage()); } } 接着并不着急处理这些文件,而是通过维护这些文件标识日期的范围与指定日期比较,如果指定日期超出范围则抛出异常,否者蔡进行下一步--读取文件:
dateFilePairs.parallelStream().forEach((dateFile) -> { try { Collection<InfectionItem> items = parser.parse(reader.read(dateFile.getValue())); data.add(new Pair<>(dateFile.getKey(), items)); } catch (IOException | InfectDataParseException e) { System.out.println("无法处理文件" + dateFile.getValue().getAbsolutePath() + "," + e.getMessage()); } }); 因为多线程的管理这里使用了线程安全的Vector,每个元素保存了一个日期以及当天的所有省份个类型人数。
五、单元测试截图和描述
-
单元测试覆盖率
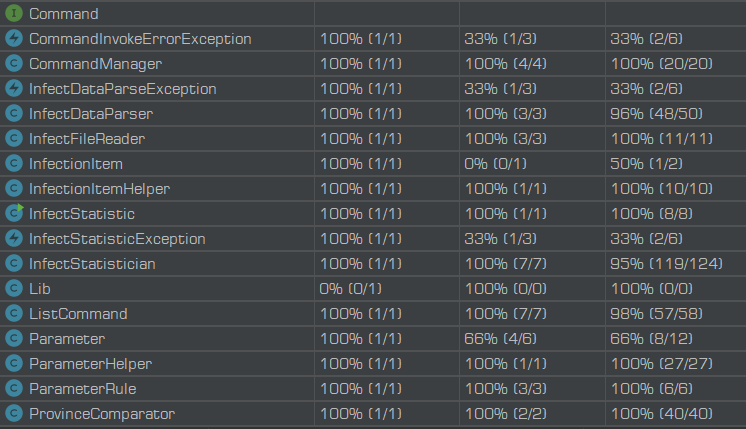
-
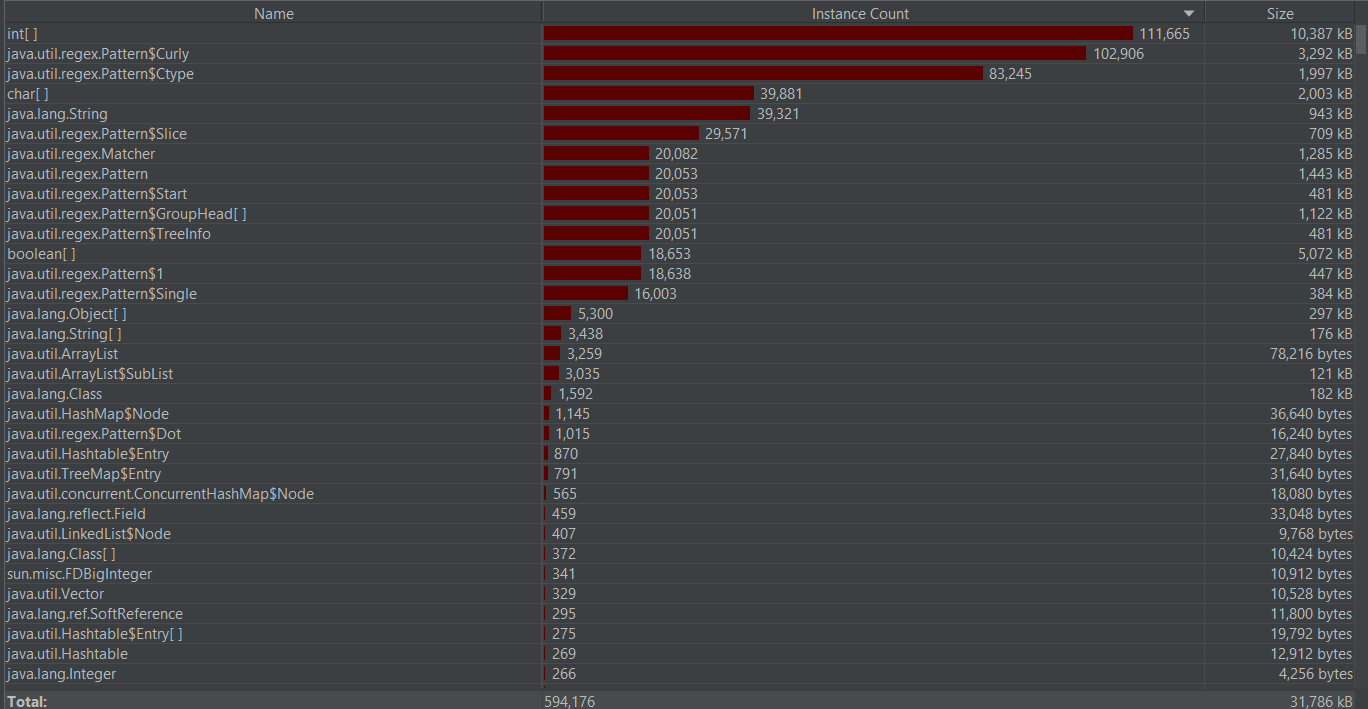
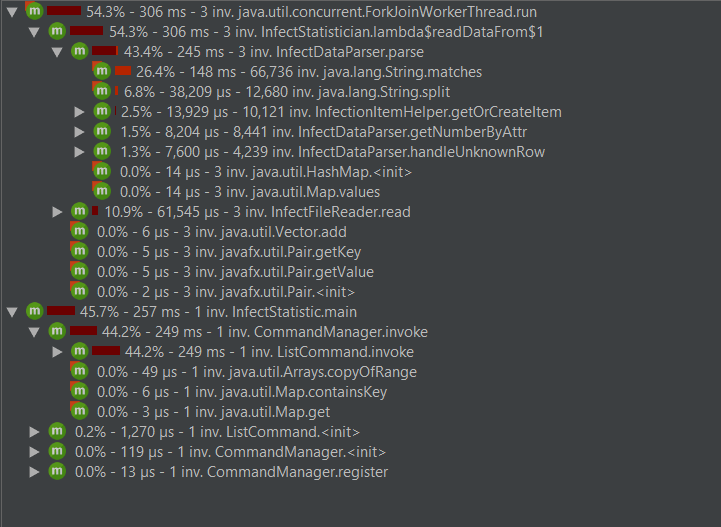
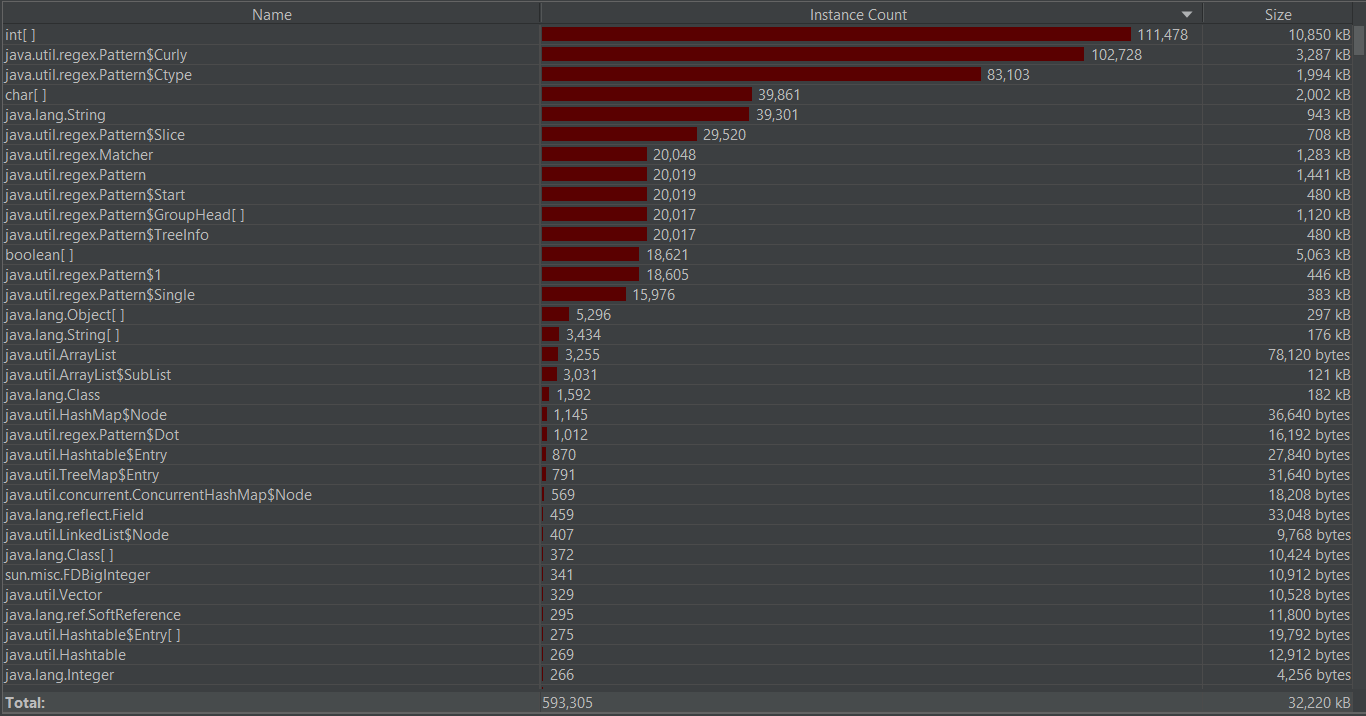
性能优化截图
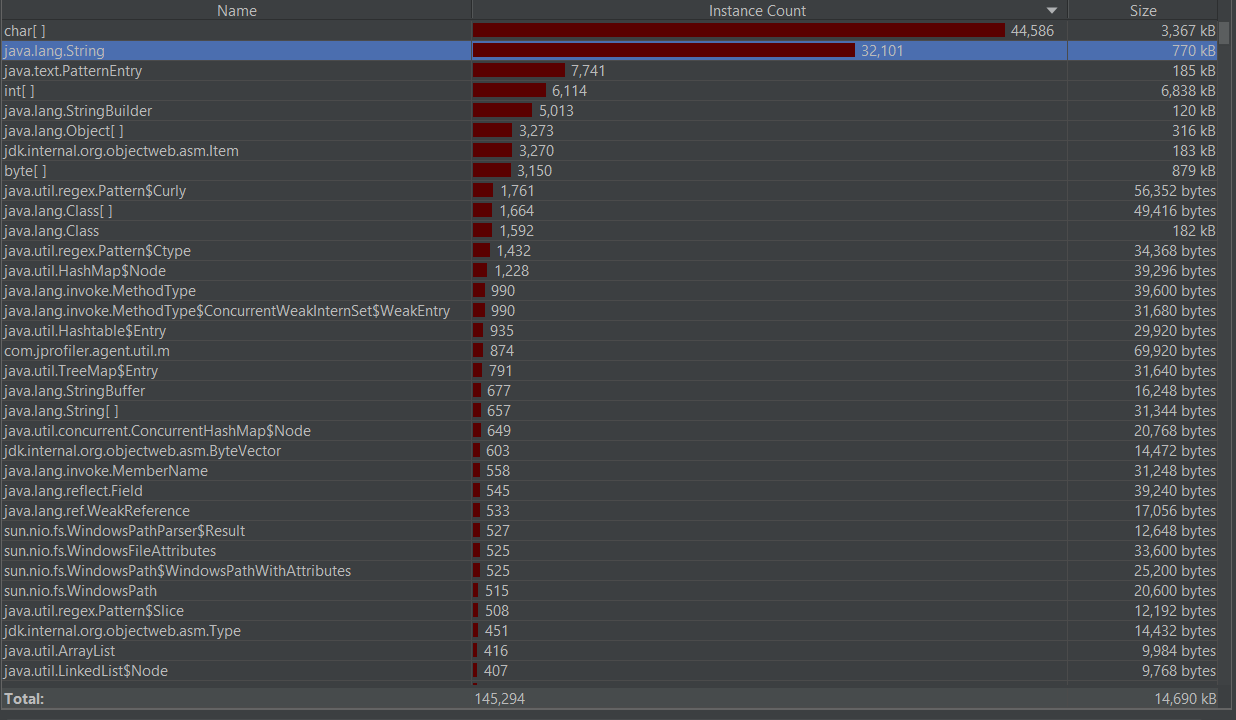
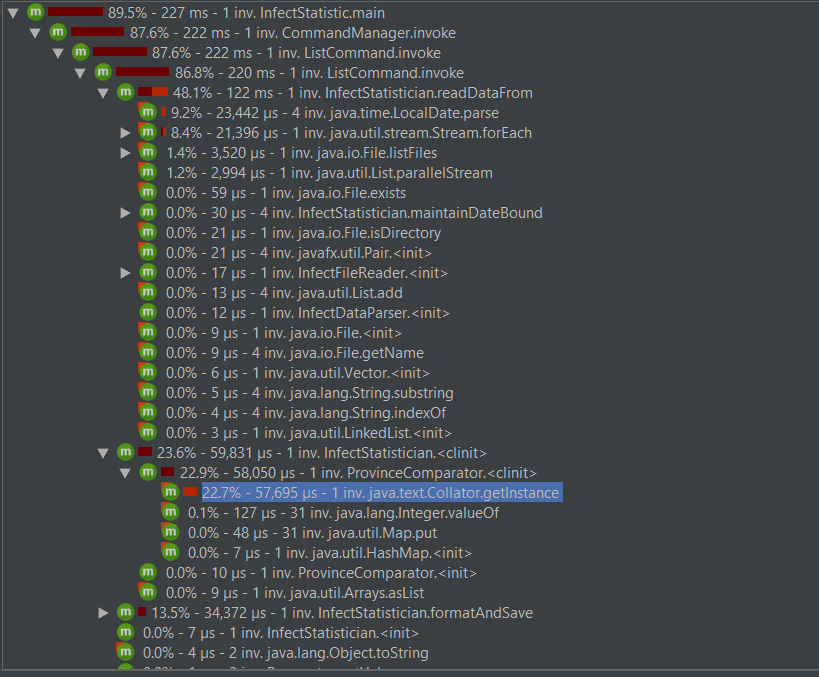
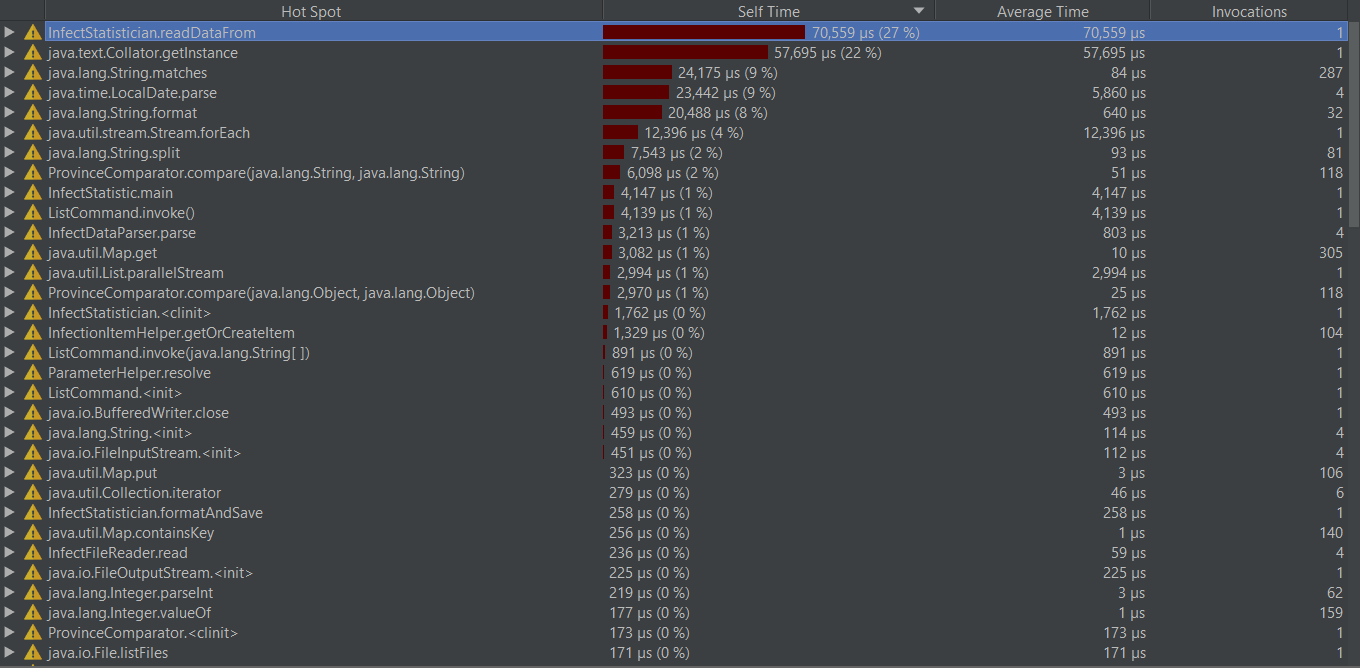
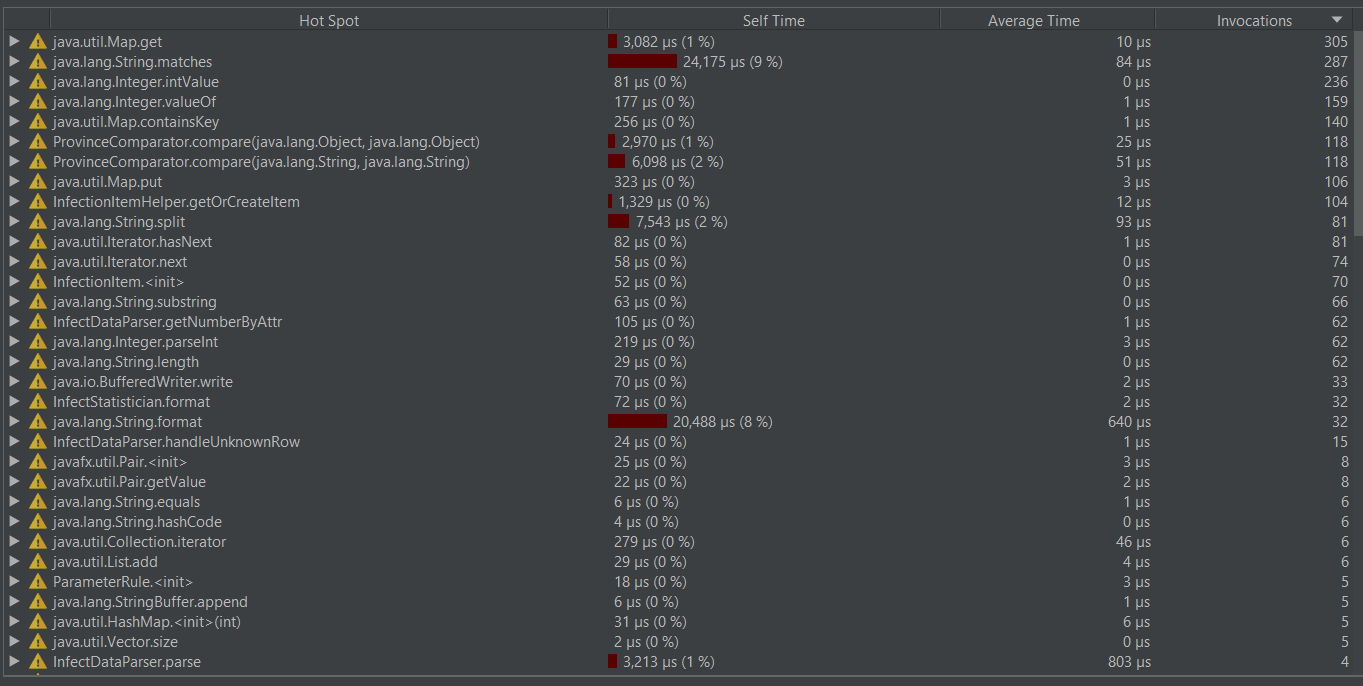
本来想把以下字符串获获取改成分隔而是按指定位置获取子串。
public Collection<InfectionItem> parse(String[] rows) {
Map<String, InfectionItem> map = new HashMap<>(256);
for (String row : rows) {
String[] attrs = row.split("\s+");
//...
}
return map.values();
}
改完后发现变成负优化了:
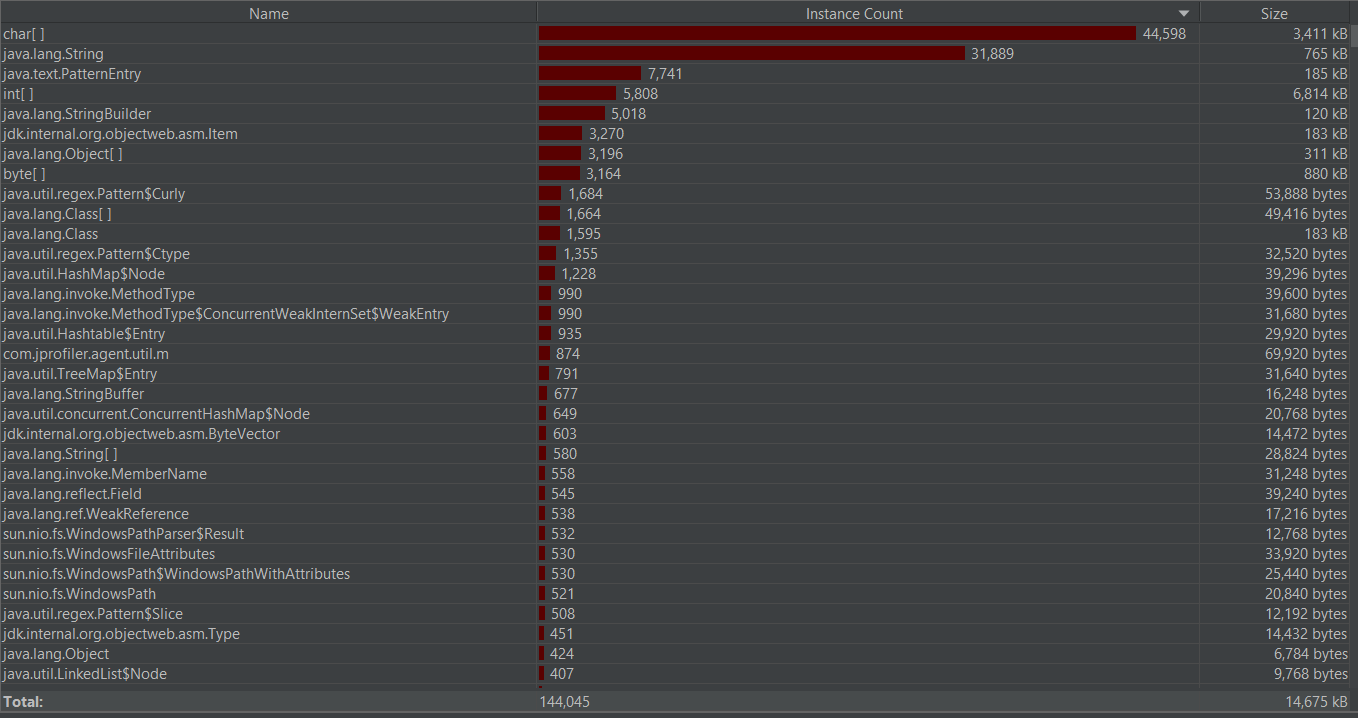
最后找到读入文件时可以把读入流换成带缓冲的读入流,当读取大量数据时,运行时间得到改善。
优化前:

优化后:
六、代码规范的链接
https://github.com/abse4411/InfectStatistic-main/blob/master/221701339/codestyle.md
git仓库链接见文章开头表格
七、心路历程与收获
从开始到作业到现在,其实完成的时间比预计的要多。这是意料之中的,同时也收获了许多新的知识。
单元测试,之前虽然有接触过,但还是没有很深入的理解。以前的单元测试只停留在跑跑几个简单的测试,并没有想到有代码覆盖率这一概念。好的单元测试对一个程序的检验很有必要。
第一次接触到性能分析工具还是在VS的自带性能探测器,对于新的工具JProfiler还有很多东西需要学习。
当一谈到代码规约,就想起了当年的程序设计实践。在学到C#之后,逐渐去学习别人的编码规范。把编码规范规范养成一个习惯,是一个好的编程素养。
在完成最后编码的时候,再来看助教提供的帮助博客,很多地方当遇到要扩展或者简化的时候,自己写的代码会变得没有那么可维护性。在讲到命令模式时,突然变得熟悉,之前在某次的作业写得时候也遇到类似的问题,反而这一次并没有及时想到,总是一个思路写下来,很少考虑到以后的事情。
通过阅读了《构建之法》前三章的内容,对于现在的自己如果要成为真正的软件工程有还需一段漫长的路要走。
学无止境,砥砺前行。
八、技术路线图相关的5个仓库
| 名称 | 链接 | 简介 |
|---|---|---|
| Spring Boot | https://github.com/spring-projects/spring-boot | Spring Boot可以轻松地创建独立的、产品级别的、基于Spring的应用程序。 |
| Spring Cloud | https://github.com/spring-projects/spring-cloud | Spring Cloud为开发人员提供了工具,以快速构建分布式系统中的一些常见模式 |
| Spring Framework | https://github.com/spring-projects/spring-framework | Spring Framework为任何类型的部署平台上的基于Java的现代企业应用程序提供了全面的编程和配置模型。 |
| Spring Security | https://github.com/spring-projects/spring-security | Spring Security是一个功能强大且高度可定制的身份验证和访问控制框架。 |
| Spring Data | https://github.com/spring-projects/spring-data | Spring Data为数据访问提供一个熟悉且一致的,基于Spring的编程模型,同时仍保留基础数据存储的特殊特征。 |