Transformer Model
性质:
1. Transformer是Seq2Seq类模型.
2. ransformer不是RNN.
3.仅依赖attention和全连接层.
准确率远高于RNN类.
各种weights:
- (weights spacespace alpha_{ij} = align(h_i, s_j)).
- Compute(k_{:i} = W_K h_i)and(q_{:j} = W_Q S_j).
- Compute weights(alpha_{:j} = Softmax(K^T q_{:j}) in mathbb{R}^m).
- Context vector:(c_j = sumlimits_{i=1}^{m}{alpha_{ij}v_{:m}}).
- Query:(q_{:j} = W_Q s_j)-- 匹配别人.
- Key:(k_{:i} = W_K h_i)-- 等待被匹配.
- Value:(V_{:i} = W_V h_i)-- 待加权平均.
- (W_Q, W_K, W_V)皆为待学习参数.
(Q-K-V)的关系其实就是:(h(P)与s(P)求对于h(P)的 attention), 三个(P)处都是不同的可学习的W.
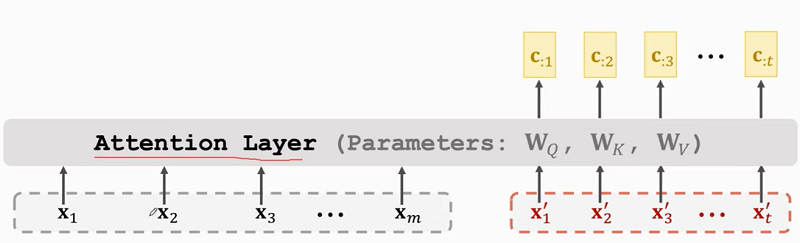
Attention Layer
Key:(k_{:i} = W_K x_i).
Value:(v_{:i} = W_V x_i).
- Queries are based on decoder's inputs(x_1^prime, x_2^prime, ..., x_t^prime).
- Query:(q_{:j} = W_Q x_j^prime).
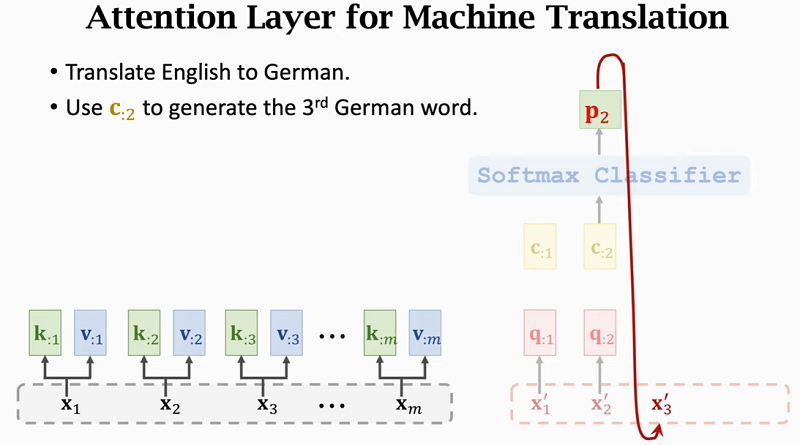
符号汇总:
- Attention layer:(C = Attn(X, X^prime)).
- Encoder's inputs:(X = [x_1, x_2, ..., x_m]).
- Decoder's inputs:(X^prime = [x_1^prime, x_2^prime, ..., x_t^prime]).
- parameters:(W_Q, W_K, W_V).
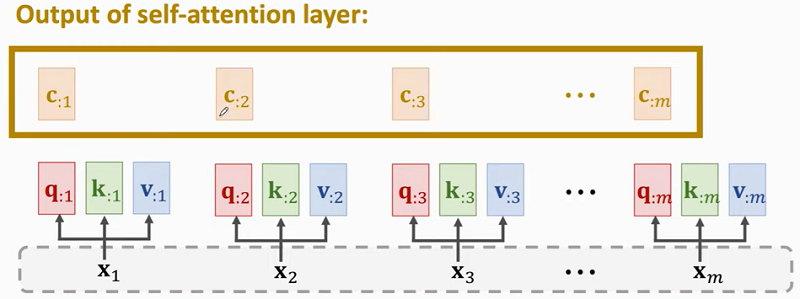
- Self-attention layer:(C = Attn(X, X)).
- RNN's inputs(X = [x_1, x_2, ..., x_m]).
- Parameters:(W_Q, W_K, W_V).
Summary:
- Attention 最初用于Seq2Seq的RNN模型.
- self-attention: 可用于所有RNN模型而不仅是Seq2Seq模型.
- Attention 可以不依赖于RNN使用.
Transformer 架构:
Single-head self-attention
Multi-head self-attention:
- l 个不共享权重的single-head self-attentions.
- 将所有single-head self-attentions的结果concat起来
- 假设single-head self-attention的输出为dxm的矩阵, 则对应multi-head 的输出shape为(ld)xm.
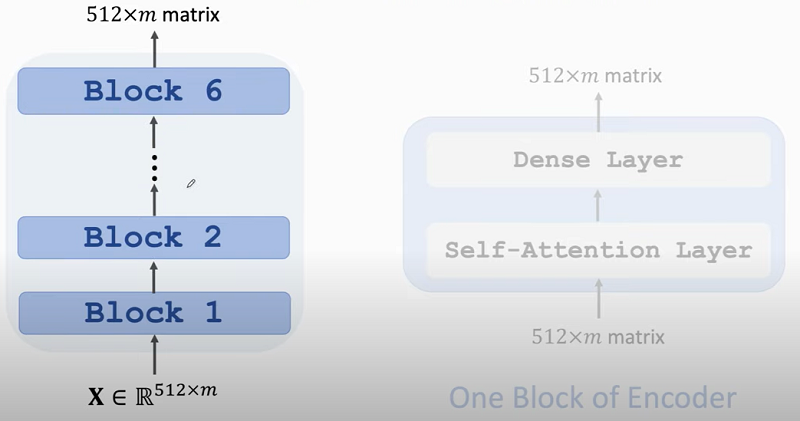
Transformer's Encoder:
- Transformer's encoder = 6 stacked blocks.
- 1 encoder block $approx$1 multi-head attention layer + 1 dense layer.
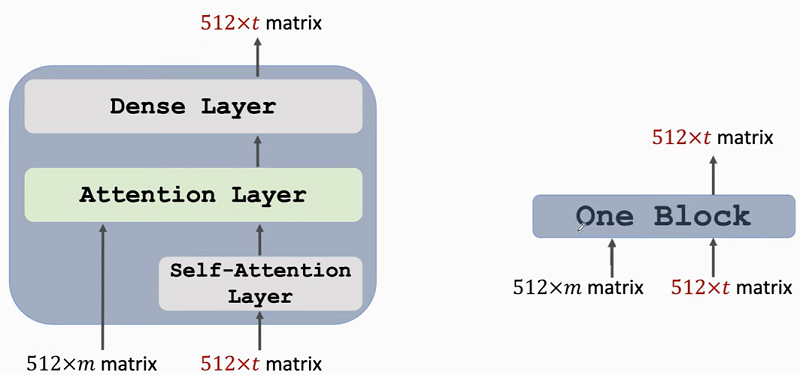
Transformer's Decoder:
- Transformer's decoder = 6 stacked blocks.
- 1 decoder block(approx)multi-head self-attention + multi-head attention + dense layer
- Input shape: (512 x m, 512 x t), output shape: 512 x t.
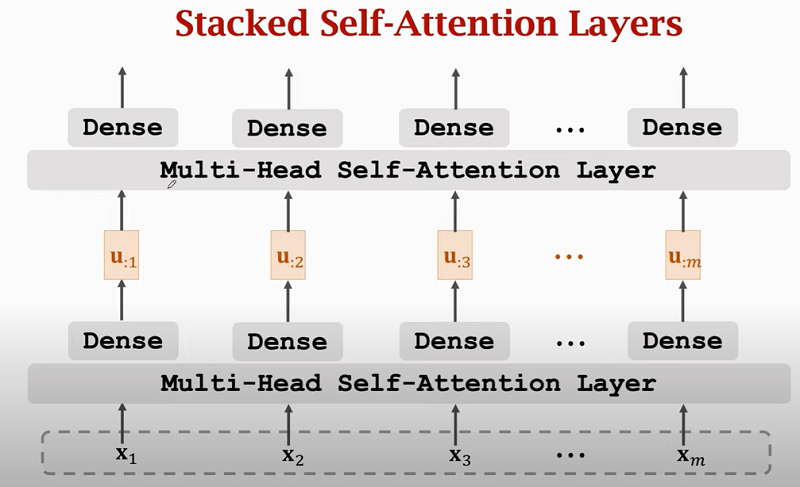
Stacked Attention

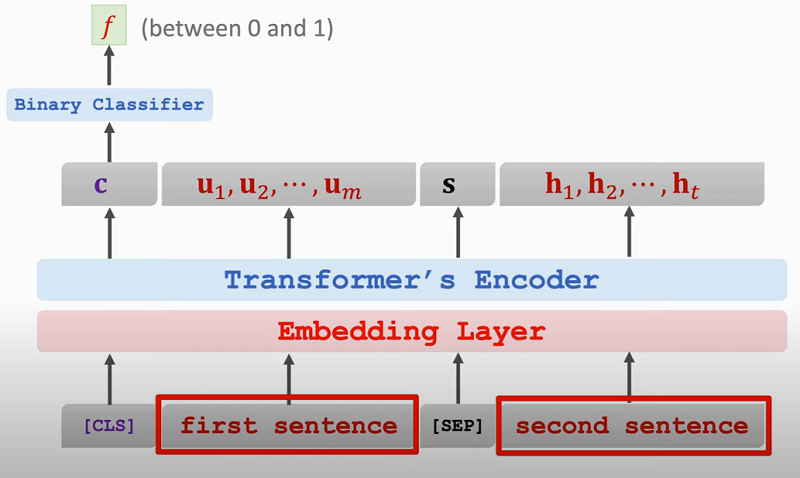
BERT
- BERT 是为了预训练Transformer 的 encoder.
- 预测mask掉的单词: 随即遮挡15%的单词:

- 预测下一个句子: 50%随机抽样句子或50%下一句, 给予false/true: