本博客的主要思路来源:树链剖分详解(洛谷模板 P3384)、OI Wiki 树链剖分
作用
简单点说,树链剖分就是将一棵树分成几条链,然后给它标号标成线性,然后处理区间问题:
- 将树的(x)点到(y)点最短路径上所有结点的值都加d
- 询问树的(x)点到(y)点的路径和
- 将以(x)为根的子树内所有值加(d)
- 询问以(x)为根的子树所有节点值之和
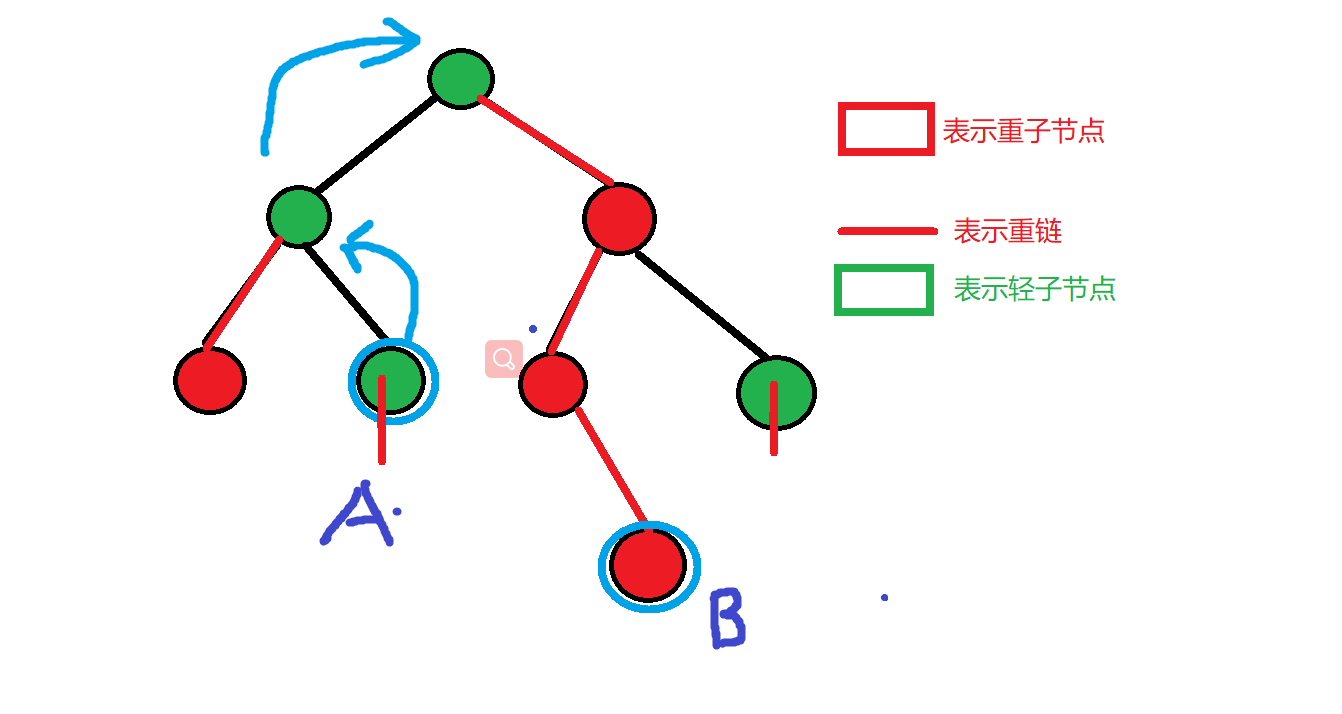
概念:
- 重儿子:对于一个结点 它的所有儿子中 以那个儿子为根的子树最大的那个儿子 就是它的重儿子
- 轻儿子:剩余的所有子节点
- 重边:从这个结点到重儿子的边叫重边
- 轻边:除去重边剩下的边
- 重链:相邻重边连起来叫重链
- 每条重链以轻儿子为起始结点
- 把落单的结点也看作一条长度为(1)的重链,所以整棵树就被剖分成了若干条重链
关于下边的预处理涉及到的变量,由以下定义。
(son[x]): (x)的重儿子的编号
(id[x]): (x)的新编号
(fa[x]): (x)的父节点
(cnt): (dfs)序
(depth[x]): 结点(x)的深度
(size[x]): 以(x)为根的子树的大小
(top[x]): (x)所在的当前链顶端的结点
预处理
第一个(dfs):
求深度,求每个结点的父亲,求子树的大小都是老生常谈了。
void dfs1(int u, int f, int deep) {
depth[u] = deep; //深度
fa[u] = f; //每个点的父亲
size[u] = 1; //以u为根的子树大小
int maxson = -1;
for (int i = h[u]; i != -1; i = ne[i]) {
int j = e[i];
if (j == f) continue;
dfs1(j, u, deep + 1);
size[u] += size[j];
if (size[j] > maxson) son[u] = j, maxson = size[j]; //处理重儿子
}
}
第二个(dfs):
找出重链的顶端的结点,为每个结点赋新的序号,即(dfs)序,
void dfs2(int u, int topf) {
id[u] = ++cnt; //u的新标号
wt[cnt] = w[u]; //新标号对应新权值
top[u] = topf; //u所在的链的顶端结点
if (!son[u]) return; //没有重儿子
dfs2(son[u], topf); //优先处理重儿子,然后处理轻儿子,这样能保证一条重链dfs序号连续
for (int i = h[u]; i != -1; i = ne[i]) {
int j = e[i];
if (j == fa[u] || j == son[u]) continue;
dfs2(j, j); //对于每一个轻儿子都有一条从它自己开始的链子
}
}
然后对于要处理的问题:
- 询问的(A)点到(B)点最短路径上路径和
我们可以将其分成两个部分:
- (res) + (A)到链的顶端的路径和,边加边跳。
- 直到(A)跳到与(B)一条链,那么直接加上它两个之间的路径和(因为一条重链DFS连续,且已经用DFS处理出来了,那么直接用线段树就可以统计这一段和),那复杂度就是(O(log^2n))
//询问两点之间最短路径上的点权之和
LL qRange(int x, int y) {
LL res = 0;
while (top[x] != top[y]) { //如果不在同一链上
if (depth[top[x]] < depth[top[y]]) swap(x, y);
LL temp = query(1, id[top[x]], id[x]); //不在一条链上加上x网上跳过程中的一路路径和
res += temp;
res %= Mod;
x = fa[top[x]]; //把x跳到x所在链顶端的那个点的上面一个点
}
//两点位于同一条链了
LL temp = 0;
if (id[x] <= id[y]) temp = query(1, id[x], id[y]); //线段树上区间肯定是l <= r
else temp = query(1, id[y], id[x]);
res += temp;
return res % Mod;
}
- 修改的(A)点到(B)点最短路径上点权值
与上面一样了,就是先边跳边更新,跳到一条链上直接更新,还是用线段树。 还是(O(log^2n))
void updRange(int x, int y, int k) {
k %= Mod;
while (top[x] != top[y]) { //如果不在同一链上
if (depth[top[x]] < depth[top[y]]) swap(x, y);
modify(1, id[top[x]], id[x], k);
x = fa[top[x]];
}
if (id[x] <= id[y]) modify(1, id[x], id[y], k);
else modify(1, id[y], id[x], k);
}
- 修改以(x)为根的子树
其实可以不太用解释了,直接看代码就明白了。
(query)与(modify)都是线段树的操作,看下边代码明白了。
LL querySon(int u) {
return query(1, id[u], id[u] + size[u] - 1);
}
void updSon(int x, int y) {
modify(1, id[x], id[x] + size[x] - 1, y);
}
那么模板代码:
// Problem: P3384 【模板】轻重链剖分/树链剖分
// Contest: Luogu
// URL: https://www.luogu.com.cn/problem/P3384
// Memory Limit: 125 MB
// Time Limit: 1000 ms
//
// Powered by CP Editor (https://cpeditor.org)
#include <bits/stdc++.h>
using namespace std;
typedef long long LL;
const int N = 1E5 + 10, M = N * 2;
int h[N], e[M], ne[M], idx;
int n, m, r, Mod;
LL w[N], wt[N]; //点权数组
int son[N], id[N], fa[N], cnt, depth[N], size[N], top[N];
/*
son[x]: x的重儿子的编号
id[x]: x的新编号
fa[x]: x的父节点
cnt: dfs序
depth[x]: 结点x的深度
size[x]: 以x为根的子树的大小
top[x]: x所在的当前链顶端的结点
*/
struct SegMentTree {
int l, r;
LL sum;
LL add;
} tr[N * 4];
/***线段树***/
void add(int a, int b) {
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
void pushup(int u) {
tr[u].sum = (tr[u << 1].sum + tr[u << 1 | 1].sum) % Mod;
}
void pushdown(int u) {
if (tr[u].add) {
tr[u << 1].add += tr[u].add;
tr[u << 1 | 1].add += tr[u].add;
tr[u << 1].sum += (tr[u << 1].r - tr[u << 1].l + 1) * tr[u].add;
tr[u << 1 | 1].sum += (tr[u << 1 | 1].r - tr[u << 1 | 1].l + 1) * tr[u].add;
tr[u << 1].sum %= Mod;
tr[u << 1 | 1].sum %= Mod;
tr[u].add = 0;
}
}
void build(int u, int l, int r) {
if (l == r) {
tr[u] = {l, r, wt[r], 0};
if (tr[u].sum > Mod) tr[u].sum %= Mod;
return;
}
tr[u].l = l, tr[u].r = r;
int mid = l + r >> 1;
build(u << 1, l, mid);
build(u << 1 | 1, mid + 1, r);
pushup(u);
}
LL query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) {
return tr[u].sum;
} else {
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
LL sum = 0;
if (l <= mid) sum = (sum + query(u << 1, l, r)) % Mod;
if (r > mid) sum = (sum + query(u << 1 | 1, l, r)) % Mod;
return sum % Mod;
}
}
void modify(int u, int l, int r, LL d) {
if (l <= tr[u].l && tr[u].r <= r) {
tr[u].sum += (LL)(tr[u].r - tr[u].l + 1) * d % Mod;
tr[u].add += d;
} else {
pushdown(u);
int mid = tr[u].l + tr[u].r >> 1;
if (l <= mid) modify(u << 1, l, r, d);
if (r > mid) modify(u << 1 | 1, l, r, d);
pushup(u);
}
}
/***线段树***/
//询问两点之间最短路径上的点权之和
LL qRange(int x, int y) {
LL res = 0;
while (top[x] != top[y]) { //如果不在同一链上
if (depth[top[x]] < depth[top[y]]) swap(x, y);
LL temp = query(1, id[top[x]], id[x]); //不在一条链上加上x网上跳过程中的一路路径和
res += temp;
res %= Mod;
x = fa[top[x]]; //把x跳到x所在链顶端的那个点的上面一个点
}
//两点位于同一条链了
LL temp = 0;
if (id[x] <= id[y]) temp = query(1, id[x], id[y]); //线段树上区间肯定是l <= r
else temp = query(1, id[y], id[x]);
res += temp;
return res % Mod;
}
//更新
void updRange(int x, int y, int k) {
k %= Mod;
while (top[x] != top[y]) { //如果不在同一链上
if (depth[top[x]] < depth[top[y]]) swap(x, y);
modify(1, id[top[x]], id[x], k);
x = fa[top[x]];
}
if (id[x] <= id[y]) modify(1, id[x], id[y], k);
else modify(1, id[y], id[x], k);
}
LL querySon(int u) {
return query(1, id[u], id[u] + size[u] - 1);
}
void updSon(int x, int y) {
modify(1, id[x], id[x] + size[x] - 1, y);
}
void dfs1(int u, int f, int deep) {
depth[u] = deep; //深度
fa[u] = f; //每个点的父亲
size[u] = 1; //以u为根的子树大小
int maxson = -1;
for (int i = h[u]; i != -1; i = ne[i]) {
int j = e[i];
if (j == f) continue;
dfs1(j, u, deep + 1);
size[u] += size[j];
if (size[j] > maxson) son[u] = j, maxson = size[j];
}
}
void dfs2(int u, int topf) {
id[u] = ++cnt; //u的新标号
wt[cnt] = w[u]; //新标号对应新权值
top[u] = topf; //u所在的链顶端
if (!son[u]) return; //没有重儿子
dfs2(son[u], topf); //优先处理重儿子,然后处理轻儿子
for (int i = h[u]; i != -1; i = ne[i]) {
int j = e[i];
if (j == fa[u] || j == son[u]) continue;
dfs2(j, j); //对于每一个轻儿子都有一条从它自己开始的链子
}
}
int main() {
scanf("%d%d%d%d", &n, &m, &r, &Mod);
for (int i = 1; i <= n; i++) {
scanf("%d", &w[i]);
}
memset(h, -1, sizeof h);;
int t = n - 1;
while (t--) {
int a, b;
scanf("%d%d", &a, &b);
add(a, b), add(b, a);
}
dfs1(r, -1, 1);
dfs2(r, r);
build(1, 1, n);
while (m--) {
int op, x; scanf("%d%d", &op, &x);
if (op == 1) {
int y, z; scanf("%d%d", &y, &z);
updRange(x, y, z);
} else if (op == 2) {
int y; scanf("%d", &y);
printf("%lld
", qRange(x, y));
} else if (op == 3) {
int z; scanf("%d", &z);
updSon(x, z);
} else if (op == 4) {
printf("%lld
", querySon(x));
}
}
return 0;
}