面向对象系列:
(1)多项式求导:https://www.cnblogs.com/ZhaoLX/p/OO_Derivative.html
(2)电梯(多线程):https://www.cnblogs.com/ZhaoLX/p/OO_Elevator.html
(3)地铁(JML):https://www.cnblogs.com/ZhaoLX/p/OO_Subway.html
(4)UML图:https://www.cnblogs.com/ZhaoLX/p/OO_UML.html
前言
OO三周三次作业,基于多项式求导这一问题让我们入门的面向对象的设计思想。不敢说自己真的迈进了面向对象的大门了,三次作业做得也并非尽善尽美,但愿意把自己对这三次作业的一些感悟记录下来,供沟通交流及记录学习过程之用。
补充知识:基于度量的程序结构分析
这次博客作业,要求要基于度量对自己的程序结构进行分析,上网查了些资料,现将一些和本文有关的知识记录下来:
- Class:
- OCavg:类的方法的平均循环复杂度。
- WMC:类的方法的总循环复杂度。
- Method:
- ev(G):Essential Complexity,表示方法的非结构化程度。范围为[1,v(G)],值越大则程序模块化程度越差、质量越差、维护难度越高。
- iv(G):Design Complexity,表示一个方法和其所调用的其他方法之间的耦合程度。范围为[1,v(G)],值越大则耦合程度越大,方法越难以复用和维护。
- v(G):循环复杂度或圈复杂度,可以理解为穷尽程序流程每一条路径所需要的试验次数。值越大则代码越难以测试和维护。
一、第一次作业
1、思路简述
由于第一次的设计架构比较简单,可以具体介绍每一个类、每一个方法的功能。
Expression类:
包含两个成员变量:String类型的表达式,HashMap类型的系数指数
expressionInput方法:读入表达式
expressionFormatCheck方法:表达式格式判断
termMatch方法:匹配表达式中的多项式,调用Term类的ter2Nums方法对其进行求导,将求导后多项式的系数和指数存储在HashMa中
printHashMap方法:将HashMap中保存的系数和指数按照多项式的格式进行输出
Term类
包含一个成员变量:String类型的多项式

2、基于度量的分析
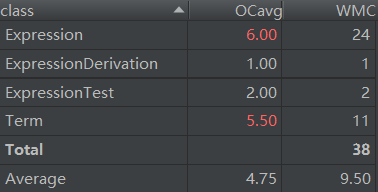
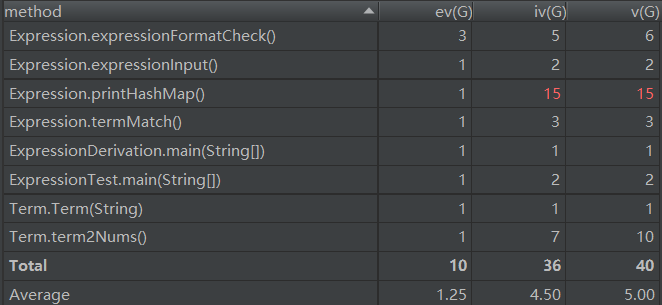
由于几乎将所有的功能都放在了Expression类和Term类中,所以两个类的复杂度比较高。
Expression类的printHashMap方法聚合了化简与输出两个功能(其实是在输出时进行化简,即输出最简形式的表达式),在化简时频繁调用HashMap的get方法和BigInteger的compareTo、equals方法,导致iv(G)和v(G)都比较高。
二、第二次作业
1、思路简述
相较第一次作业,第二次作业在架构上没有本质的改变。两次作业最大的区别在于:第一次作业每一项只包含系数与x的指数,类型均为BigInteger,可认为HashMap中的value与key;但第二次作业的每一项包含系数与x,sin(x),cos(x)的指数,如果继续使用HashMap,需要手动构建一个包含三元组的类,作为HashMap的key。基于这种想法,我写了Expo类。
Expo类:
包含三个成员变量,即x,sin(x),cos(x)三者的指数。
重写了hashCode, equals, compareTo三个方法。(compareTo方法是为了在输出时排序,使得输出美观一点的)
此外,第二次作业由于引入了三角函数,所以可利用sin(x)^2+cos(x)^2=1这一数学公式对输出结果进行化简。我的化简方法比较简单,只是在HashMap中用两重循环遍历两两组合,对于三元组(xpowEx1,sinEx1,cosEx1)及(xpowEx2,sinEx2,cosEx2),如果满足: xpowEx1 == xpowEx2 && ( (sinEx1 - sinEx2 == 2 && cosEx2 - cosEx1 == 2) || (sinEx2 - sinEx1 == 2 && cosEx1 - cosEx2 == 2) ) ,则对两者进行化简。由于^0, ^1的存在,该方法不能保证每一次化简都使得最终结果变短(只在化简结束后判断原输出与化简后输出的长度),所以最终性能分并不高。

2、基于度量的分析
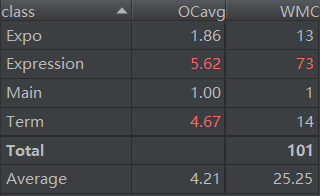

Expression类和Term类的高复杂度是第一次作业继承来的老毛病。
方法中,和输出、化简相关的方法的复杂度都比较高,可见这些部分写的还是过于面向过程了。
3、Bug分析
本次作业在互测阶段被发现了一个Bug,出现在三角函数的正则表达式中,由于缺少一个\s*导致类似 sin(x) +1 类型的输入会被判为WF。
三、第三次作业
1、思路简述
第三次作业由于加入了嵌套这一规则,使得几乎必须使用递归的方法进行处理。对于输入中的多项式、项、因子等概念,我创建了多个类,构建了树形结构来组织,示意图如下:
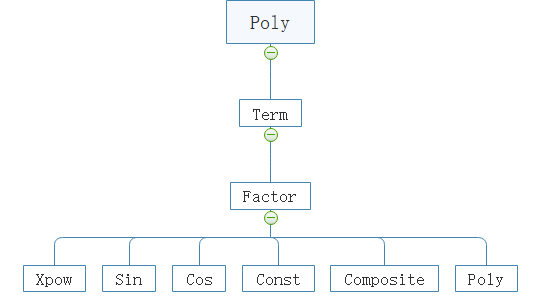
其中,Factor是一个接口,包含求导和输出两个方法,除了Term外的其它类都implement了Factor接口。这样做有以下几点考虑:
- 这些类都需要实现dericate()和print()方法,但方法细节不同
- 每个类的成员变量是不同的,比如Const类只需要只有一个BigInteger型的系数变量,但Composite类有Sin、Cos、Poly三个类型的变量
- 项求导时需要利用乘法的求导公式对包含的每一个因子进行求导,不可能每次都去判断这个因子是哪种类型,就会自然地引入多态的思想
其中,基于第三点考虑可以使用继承父类和接口两种方法来应对,但是再加上前两点的考虑,我认为不能粗暴地认为它们都是因子所以都可以继承自同一个父类,此时使用接口就成为了一个非常自然的选择。特别值得一提的是,我开始并不知道接口也可以像类一样来应用多态的思想。例如,如果要声明 ArrayList<Factor> factors; ,我开始以为这个Factor只能是一个类,在查阅资料以及和同学讨论之后,我才知道这个Factor也可以是一个接口。这也让我更加理解老师课上所说的“接口就像是一个抽象类”这句话。
读入时,我利用 [+-] 将Poly拆分成Term,利用 * 将Term拆分成Factor,利用正则表达式识别出具体为Factor中的哪一个并创建对象(当Factor为Poly或Composite时就会产生递归调用)。输入最终会被分解并存储为树的形式,顶层是输入的这个Poly,底层一定是Xpow,Sin,Cos,Const这四个基本类型。特别的是,对于Composite类型的Factor,我会将其括号内的内容视为Poly,即表达式因子,哪怕它可能仅仅是四个基本类型因子,如 x^2 ,这样能减小一定代码量,不过在运行时间、存储空间及最终输出的表达式长度上都会有较大缺陷。
求导时,Factor求导后返回Factor类型的ArrayList(其中Poly求导会返回Poly,可以认为是只有一个Poly元素的ArrayList),Term求导后返回Term类型的ArrayList。在调用Poly的求导方法时,调用Term的求导方法,Term会调用Factor的求导方法。这样对顶层Poly求导后,得到了求导结果的树状结构。
化简时,由于能力和存储结构的原因,我只考虑了两种化简情况。一是指数化简,对于^0, ^1形式的指数进行化简。二是项内因子有0或sin(0)时,直接令该方法返回字符串“0”(正常情况下应该是多个因子相乘,如 "-3*x^2*0*sin((4*x))")。其实在写第三次作业的时候就想到,一个可行的优化思路是对于最终输出中所有可以表示为四元组(系数,x指数,sin指数,cos指数)——即满足第二次作业要去——的项再重新用第二次作业的方法(HashMap)进行存储(即合并),遇到含有嵌套的项(即内部含有复合函数因子Composite或表达式因子Poly)则不进行处理直接输出。这样在代码层面几乎和第二次作业是一样的,几乎没有需要重构的部分,而且据助教所说这样在优化层面就可以领先绝大多数人。但当时出于“性能分只占5%甚至更少”的考虑,就没有做这个优化。

2、基于度量的分析
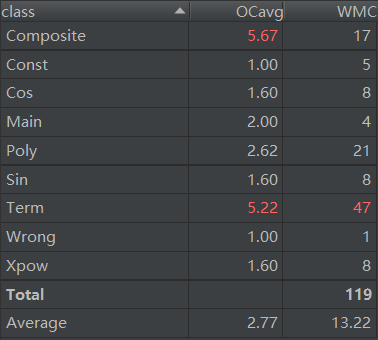
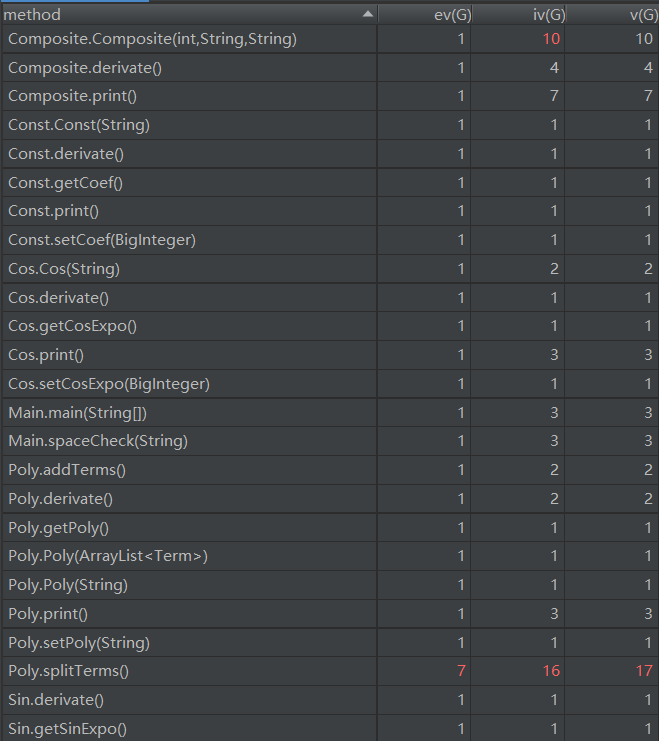
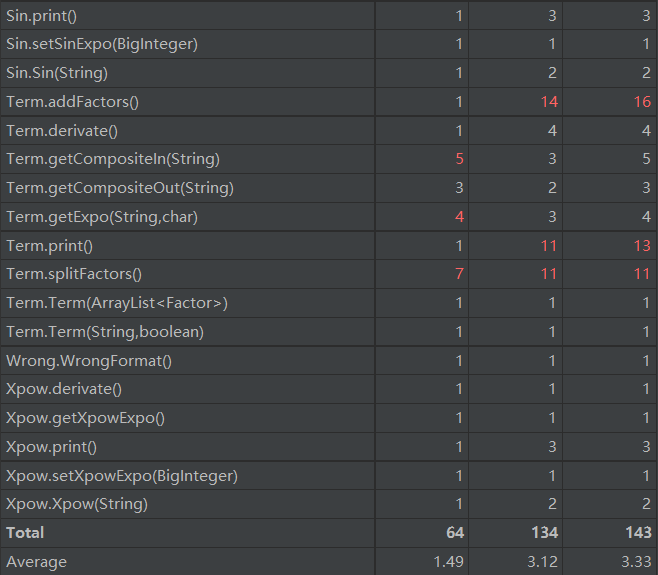
第三次作业相对来说还是比较复杂的,我将非常多的功能都聚合在了Term类当中,最终Term类总长度达到了200行。诸如addFactors, splitFactors, print等方法,由于频繁调用其他方法导致复杂度较高。另一个较为复杂的类是Composite,原因一是类内要区分是sin内复合还是cos内复合,二是求导和输出时和Poly类耦合度过高。
四、发现别人程序bug所采用的策略
互测阶段主要还是用了对拍器找bug,找到bug后读代码思考出错原因(这三次主要找到的Bug都是格式处理部分,主要集中在正则表达式中)。对拍主要分为三个部分:构造数据、测试程序、评测输出。
1、构造数据
数据的构造分为手动和自动两部分。
首先说手动构造,这个其实一般是在自测阶段构造出来用来检测自己程序的,互测阶段就顺便拿来测试别人的。我大致考虑了以下几种情况:
- 正则表达式相关:特别是空白字符,非法字符、加减号
- 合法输入截断部分或添加字符后能否正确判断
- TLE测试,特别是第三次的多层嵌套
再说自动构造,这个主要利用了Java和Python中的Xeger库,可以根据正则表达式输出合法的表达式。在正确表达式的基础上添加扰动(添加字符、删减字符、截断)来得到错误输入。针对第三次作业的输入,由于无法用一个正则表达式概括输入格式,所以需要特别的构造方式。第一种思路是:写一个函数来递归地构造。第二种思路,也就是我采用的思路是:用一个特殊字符(e.g. @)来代表表达式因子,加入到正则表达式当中,之后再将初步构造的表达式中的所有特殊字符替换为一个新构造的表达式。
2、测试程序
构造得到的输入需要输入给待测的程序,我在这里使用了在命令行中编译+运行Java程序的方法。
javac -encoding utf-8 *.java java -cp altergo/src Main < a.in > altergo.out java -cp archer/src poly.Main < a.in > archer.out
3、评测输出
评测输出时,我没有模拟评测机代值进行运算,而是直接利用sympy库中的simplify函数对两个表达式进行相等判断。
但是在讨论区看到一个shell的优雅写法,将测试程序与评测输出(评测机版本)融合在了一起,贴在这里学习一下。

五、Applying Creational Pattern
在第三次作业中,我运用了接口和递归的思想,对输入的求导式不断分解并构建所属类的实例,直到底层为常数、x的幂、sin的幂、cos的幂这四种基本形式,在这一过程中,多项式、项和因子三者的实例创建其实是紧密耦合的。如果要重构的话,我可能会使用工厂模式,将多项式、项、因子的创建分离,实现解耦。
第三次作业中,我的“项”类是没有implement“因子”接口的(具体介绍可见 三、第三次作业 )。但如果要用工厂模式实现,可以让“项”也来implement一下,这样就可以创建表达式工厂,通过表达式工厂的方法来构建起整个多项式的这棵树结构。
后记
回顾了一下三周的三次作业,感觉第二次作业为了节省思考时间和降低化简难度而延用了第一次的设计,本身无可指摘,但是这就导致第三次作业到来的时候手足无措,花了很长的时间进行架构的设计。第一次、第二次作业只用了一天多的时间就完成了,第三次作业几乎用了整整三天,最后只是草草测试了一下。不过好处是,在这个过程中,很集中地体会了面向对象的思想,对于继承和接口的认识也有了巨大的提升,这是课上听讲所无法带给我的。