词频统计 SPEC
此作业的要求参见:https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206
代码托管:https://e.coding.net/zhangbj/wf/wf.git
1. 功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
效果截图:


重点难点:
(1)文件读取
/**传入txt路径读取txt文件 * @param txtPath * @return 返回读取到的内容 */ public static String readTxt(String txtPath) { File file = new File(txtPath); if(file.isFile() && file.exists()){ try { FileInputStream fileInputStream = new FileInputStream(file); InputStreamReader inputStreamReader = new InputStreamReader(fileInputStream); BufferedReader bufferedReader = new BufferedReader(inputStreamReader); StringBuffer sb = new StringBuffer(); String text = null; while((text = bufferedReader.readLine()) != null){ sb.append(text); sb.append(' '); //增加换行符 } return sb.toString(); } catch (Exception e) { e.printStackTrace(); } }else{ System.out.println("File not exist"); } return null; }
(2)文本处理分割,次数统计
①首先将所有大写换小写,用非单词符来做分割,分割出来的就是一个个单词。
②用Map键值对来存储单词与相应的次数。
③使用set集合,利用set的不可重复性,统计单词总数,则不会出现重复现象。
content = content.toLowerCase();//将所有大写换小写 String[] words = content.split("\W+");//用非单词符来做分割,分割出来的就是一个个单词 length = words.length; HashMap<String, Integer > hashMap = new HashMap<String,Integer>(); Set<String> set = new HashSet<>();//keySet将Map中所有的键存入到set集合中 for(String word : words){ if(word != " "){ if(set.contains(word)){ // 如果这个单词已经存在,单词次数加1,重新存放 Integer number = hashMap.get(word); number++; hashMap.put(word, number); //重新放一个相同的key,会自动覆盖value }else{ hashMap.put(word, 1);//在map,set中存放此单词 set.add(word); } } } sum = set.size();//单词总数 System.out.println("total " + sum + " words");
2.功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
效果截图:
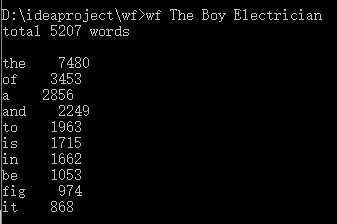
重点/难点:
(1)拼接含空格的文件名称,循环参数时,通过空格连接,注意最后使用trim去除文件名末尾的空格。(此代码为本程序主函数中的功能判断选择)
if (length > 0) { if (length == 1) { if("-s".equals(args[0])) { //判断是否为重定向输入 Scanner scanner = new Scanner(System.in); String content = scanner.nextLine(); countBigTxt(content); }else{ path = basicPath + directoryPath + args[0]; File file = new File(path); if (file.isDirectory()) { List<File> files = getFiles(file); for (File subFile : files) { String content = readTxt(subFile.getAbsolutePath()); if (content.length() > 0) { System.out.println(subFile.getName()); countBigTxt(content); System.out.println("----"); } } } else { path = basicPath + directoryPath + args[0] + ".txt"; flag = true; //是文件 } } } else if (length > 1) { flag = true; //是文件 String fileName = ""; int i = 0, j; if("-s".equals(args[0])){ i = 1; } for (j = i; j < length; j++) { //拼接含空格的文件 fileName = fileName + args[j]; fileName = fileName + " "; } fileName = fileName.trim(); //去末尾空格 if("-s".equals(args[0])){ path = basicPath + directoryPath + fileName; }else{ path = basicPath + directoryPath + fileName + ".txt"; } } if (flag) { String content = readTxt(path); if (content.length() > 0) { countBigTxt(content); } } }
3.功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。因为单词量巨大,只列出出现次数最多的10个单词。
效果截图:
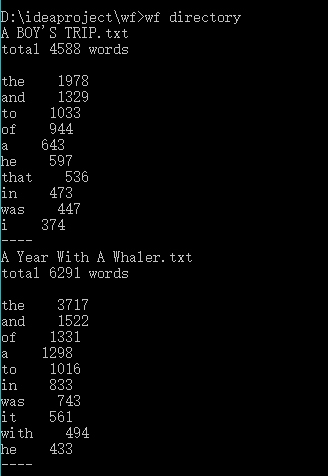
重点/难点 :
(1) 判断输入的是文件名还是目录。若是目录,则读取目录下的全部内容,分别进行统计。
/**读取文件夹下所有文件名 * @param file */ public static List<File> getFiles(File file){ List<File> files = new ArrayList<>(); File[] subFiles = file.listFiles(); for(File f : subFiles){ files.add(f); } return files; }
if(file.isDirectory()){ List<File> files = getFiles(file); for (File subFile : files){ String content = readTxt(subFile.getAbsolutePath()); if(content.length() > 0) { System.out.println(subFile.getName()); countBigTxt(content); System.out.println("----"); } } }else if(file.isFile()){ flag = true; //是文件 }
}
(2)列出出现次数最多的10个单词 将map根据其中每个value值大小进行从大到小排序。使用Collections.sort函数,重写compare方法。
List<Map.Entry<String, Integer>> list = new ArrayList<>(hashMap.entrySet()); //按照value值,从大到小排序 Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() { @Override public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) { return o2.getValue() - o1.getValue(); } }); int i = 0; for (Map.Entry s : list) { i++; System.out.println(s.getKey()+" "+s.getValue()); if(i >= 10) break; }
4.功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
答:
效果截图:
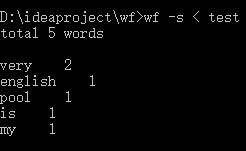
重点难点:
学习重定向输入。当为重定向时,则不会进行输入等待,会直接将文件中的内容作为输入,从而实现重定向输入。
if("-s".equals(args[0])) { //判断是否为重定向输入 Scanner scanner = new Scanner(System.in); String content = scanner.nextLine(); countBigTxt(content); }
代码及版本控制:代码托管 https://e.coding.net/zhangbj/wf/wf.git
功能5 此功能为选做题,如果完成正确得30经验值,如果不做得0经验值,不会倒扣分数。"可变的参数就是(1)几个字母和(2)排行前多少
答:
效果截图:

重点难点:若不指定输出单词字母个数与单词个数要求,则wordNum默认为0,top默认为10。若指定有值,则在排序后输出时判断单词是否是指定的wordNum值,且输出指定的单词个数。
if("-w".equals(args[0]) && "-t".equals(args[2]) && "-s".equals(args[4])){ //-w wordNum -t top -s fileName i = 5; wordNum = Integer.parseInt(args[1]); top = Integer.parseInt(args[3]); }
for (Map.Entry s : list) { if(wordNum != 0){ if(s.getKey().toString().length() == wordNum){ i++; System.out.println(s.getKey()+" "+s.getValue()); } }else{ i++; System.out.println(s.getKey()+" "+s.getValue()); } if(i >= top) break; }
| 功能 | 预计花费时间(min) | 实际花费时间(min) | 时间差(min) | 原因 |
| 功能1 | 100min | 194min | +94min |
①由于对单词定义考虑太多,多次变换单词分割方法 ②对正则表达式不熟悉 |
| 功能2 | 60min | 92min | +32min |
①修改统计单词数量的方法,由最初for循环判断是否重复,改为使用Set集合。 ②拼接空目录 |
| 功能3 | 60min | 98min | +38min | ①做完此功能后,第一次尝试进行将jar转为exe文件,耗费很多时间 |
| 功能4 | 80min | 42min | -38min |
①读明白题意,耗费时间 ②学习重定向输入,编码调试 |
| 功能5 | 30min | 23min | -7min |
①有前面的基础,此步骤仅需要增加参数与判断即可 |