数据库读现象
""" 数据库管理软件的“读现象”指的是当多个事务并发执行时,在读取数据方面可能碰到的问题,包括有脏读、不可重复读和幻读。 """
""" 事务T2更新了一行记录的内容,但是并没有提交所做的修改。 事务T1读取更新后的行,然后T1执行回滚操作,取消了刚才所做的修改。此时T1所读取的行就无效了,称之为脏数据。 """

在这个例子中,事务2回滚后就没有id是1,age是21的数据了。所以,事务一读到了一条脏数据。
""" 事务T1读取一行记录,紧接着事务T2修改了T1刚才读取的那一行记录并且提交了。 然后T1又再次读取这行记录,发现与刚才读取的结果不同。这就称为“不可重复”读,因为T1原来读取的那行记录已经发生了变化。 """
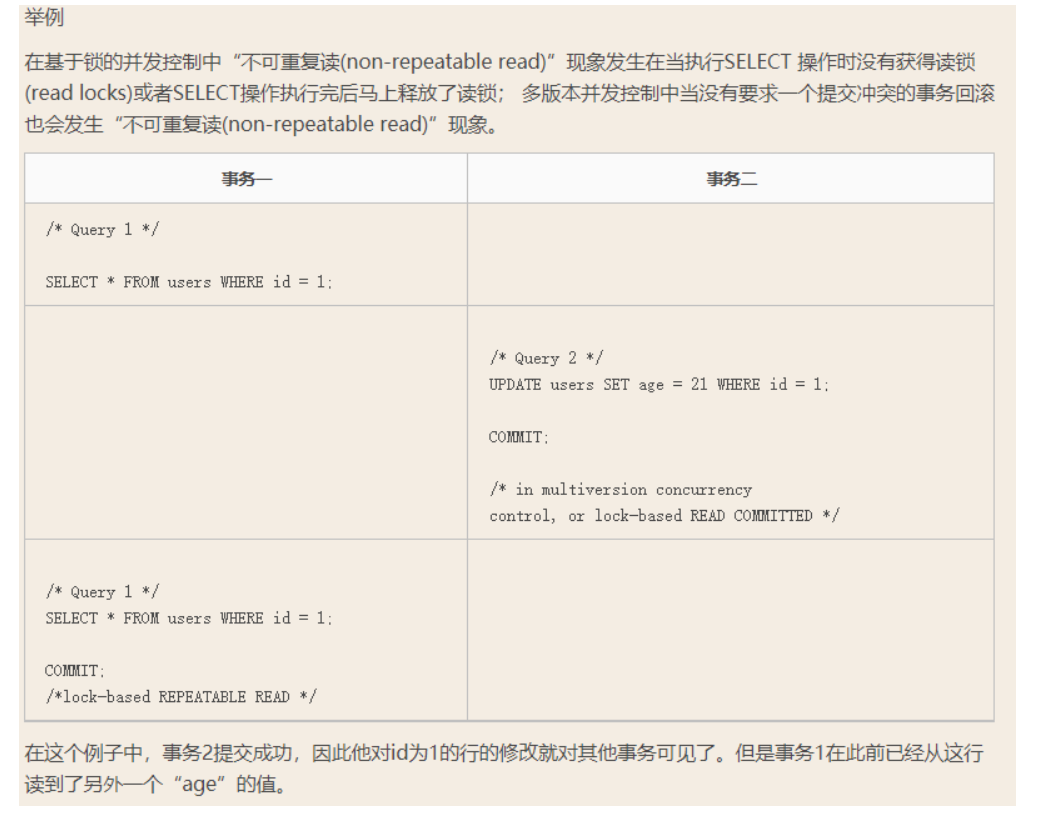
""" 幻读(phantom read)”是不可重复读(Non-repeatable reads)的一种特殊场景: 当事务没有获取范围锁的情况下执行SELECT … WHERE操作有可能会发生“幻影读(phantom read)”。 """
""" 事务T1读取或修改了指定的WHERE子句所返回的结果集。 然后事务T2新插入一行记录,这行记录恰好可以满足T1所使用的查询条件中的WHERE 子句的条件。 然后T1又使用相同的查询再次对表进行检索,但是此时却看到了事务T2刚才插入的新行或者发现了处于WHRE子句范围内,但却未曾修改过的记录。就好像“幻觉”一样,因为对T1来说这一行就像突然出现的一样。 一般解决幻读的方法是增加范围锁RangeS,锁定检锁范围为只读,这样就避免了幻读。 """

""" 其实,脏写、脏读、不可重复读、幻读,都是因为业务系统会多线程并发执行,每个线程可能都会开启一个事务,每个事务都会执行增删改查操作。
然后数据库会并发执行多个事务,多个事务可能会并发地对缓存页里的同一批数据进行增删改查操作,于是这个并发增删改查同一批数据的问题,
可能就会导致我们说的脏写、脏读、不可重复读、幻读这些问题。 所以这些问题的本质,都是数据库的多事务并发问题,那么为了解决多事务并发带来的脏读、不可重复读、幻读等读等问题,数据库才设计了锁机制、
事务隔离机制、MVCC 多版本隔离机制,用一整套机制来解决多事务并发问题,下面我们来分别介绍一下它们 """
数据库锁
什么是锁?
""" 锁是计算机协调多个进程或线程并发访问某一资源的机制 """
为何要加入锁机制?
""" 因为在数据库中,除了传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供需要用户共享的资源。 当并发事务同时访问一个共享的资源时,有可能导致数据不一致、数据无效等问题 例如我们在数据库的读现象中介绍过,在并发访问情况下,可能会出现脏读、不可重复读和幻读等读现象 为了应对这些问题,主流数据库都提供了锁机制,以及事务隔离级别的概念, 而锁机制可以将并发的数据访问顺序化,以保证数据库中数据的一致性与有效性 此外,锁冲突也是影响数据库并发访问性能的一个重要因素,锁对数据库而言显得尤其重要,也更加复杂。 """
锁的分类
按锁的粒度划分
""" 行级锁 表级锁 页级锁 """
行级锁
""" 行级锁是Mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。 """
特点
""" 开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。 """
支持引擎
""" InnoDB """
行级锁的三种算法
""" record lock:单个记录上锁 gap lock:间隙锁,锁定一个范围,但不包括记录本身 next-key lock:前面两者相加,既锁定符合条件的行,也锁定符合条件的上下各一间隙 解决幻读问题 """
行级锁分为共享锁和排他锁
""" 用法如下: 共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE 排他锁(X):SELECT * FROM table_name WHERE ... FOR UPDATE """
表级锁
""" 表级锁是MySQL中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分MySQL引擎支持。最常使用的MYISAM与INNODB都支持表级锁定。 表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁)。 """
特点
""" 开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低 """
支持引擎
""" MyISAM、MEMORY、InNoDB """
分类
表级锁定分为表共享读锁(共享锁)与表独占写锁(排他锁
使用
""" lock table 表名 read(write),表名 read(write),.....; //给表加读锁或者写锁 unlock tables; -- UNLOCK TABLES释放被当前会话持有的任何锁 """
页级锁
""" 页级锁是MySQL中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。BDB支持页级锁 """
特点
""" 开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。 """
按锁级别划分
""" 共享锁 排它锁 """
""" 与行处理相关的sql有:insert、update、delete、select,这四类sql在操作记录行时,可以为行加上锁,但需要知道的是: 1、对于insert、update、delete语句,InnoDB会自动给涉及的数据加锁,而且是排他锁(X); 2、对于普通的select语句,InnoDB不会加任何锁,需要我们手动自己加,可以加两种类型的锁,如下所示 # 共享锁(S):SELECT ... LOCK IN SHARE MODE; -- 查出的记录行都会被锁住 # 排他锁(X):SELECT ... FOR UPDATE; -- 查出的记录行都会被锁住 """
共享锁(Share Lock)
定义
""" 共享锁又称为读锁,简称S锁,顾名思义,共享锁就是多个事务对于同一数据可以共享一把锁,获准共享锁的事务只能读数据,不能修改数据直到已释放所有共享锁,所以共享锁可以支持并发读。 如果事务T对数据A加上共享锁后,则其他事务只能对A再加共享锁或不加锁(在其他事务里一定不能再加排他锁,但是在事务T自己里面是可以加的),反之亦然。 """
用法
""" SELECT ... LOCK IN SHARE MODE; 在查询语句后面增加LOCK IN SHARE MODE,Mysql会对查询结果中的每行都加共享锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,
可以成功申请共享锁,否则会被阻塞。其他线程也可以读取使用了共享锁的表,而且这些线程读取的是同一个版本的数据。 """
排他锁(eXclusive Lock)
定义
""" 排他锁又称为写锁,简称X锁,顾名思义,排他锁就是不能与其他所并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再对该行加任何类型的其他他锁(共享锁和排他锁),
但是获取排他锁的事务是可以对数据就行读取和修改。 """
用法
""" SELECT ... FOR UPDATE; 在查询语句后面增加FOR UPDATE,Mysql会对查询结果中的每行都加排他锁,当没有其他线程对查询结果集中的任何一行使用排他锁时,可以成功申请排他锁,否则会被阻塞。 特例:加过排他锁的数据行在其他事务种是不能修改数据的,也不能通过for update和lock in share mode锁的方式查询数据,但可以直接通过select ...from...查询数据,
因为普通select查询没有任何锁机制。 """
按使用方式划分
乐观锁 悲观锁
悲观锁
""" 悲观锁,正如其名,它指的是对数据被外界(包括本系统当前的其他事务,以及来自外部系统的事务处理)修改持保守态度(悲观),因此,在整个数据处理过程中,将数据处于锁定状态。 悲观锁的实现,往往依靠数据库提供的锁机制 (也只有数据库层提供的锁机制才能真正保证数据访问的排他性,否则,即使在本系统中实现了加锁机制,也无法保证外部系统不会修改数据),
现在互联网高并发的架构中,受到fail-fast思路的影响,悲观锁已经非常少见了。 """
悲观锁的流程
""" 在对任意记录进行修改前,先尝试为该记录加上排他锁(exclusive locking)。 如果加锁失败,说明该记录正在被修改,那么当前查询可能要等待或者抛出异常。 具体响应方式由开发者根据实际需要决定。 如果成功加锁,那么就可以对记录做修改,事务完成后就会解锁了。 其间如果有其他对该记录做修改或加排他锁的操作,都会等待我们解锁或直接抛出异常。 ps:行锁、表锁、读锁、写锁都是在操作之前先上排他锁 """
悲观锁的实现
""" 在MySQL中使用悲观锁,必须关闭MySQL的自动提交,set autocommit=0,因为MySQL默认使用自动提交autocommit模式,在执行完sql后会自动提交并释放锁 set autocommit=0; """
总结
""" 优点: 悲观并发控制实际上是“先取锁再访问”的保守策略,为数据处理的安全提供了保证。 缺点: (a)在效率方面,处理加锁的机制会让数据库产生额外的开销,还有增加产生死锁的机会; (b) 在只读型事务处理中由于不会产生冲突,也没必要使用锁,这样做只能增加系统负载;还有会降低了并行性,一个事务如果锁定了某行数据,其他事务就必须等待该事务处理完才可以处理那行数 """
乐观锁
""" 乐观锁( Optimistic Locking ) 相对悲观锁而言,乐观锁假设认为数据一般情况下不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,
如果发现冲突了,则让返回用户错误的信息,让用户决定如何去做。 """
乐观锁的实现
""" 1、使用版本号实现 每一行数据多一个字段version,每次更新数据对应版本号+1, 原理:读出数据,将版本号一同读出,之后更新,版本号+1,提交数据版本号大于数据库当前版本号,则予以更新,否则认为是过期数据,重新读取数据 2、使用时间戳实现 每一行数据多一个字段time 原理:读出数据,将时间戳一同读出,之后更新,提交数据时间戳等于数据库当前时间戳,则予以更新,否则认为是过期数据,重新读取数据 """
优点与不足
""" 乐观并发控制相信事务之间的数据竞争(data race)的概率是比较小的,因此尽可能直接做下去,直到提交的时候才去锁定,所以不会产生任何锁和死锁。 """
如何选择乐观锁与悲观锁
""" 在乐观锁与悲观锁的选择上面,主要看下两者的区别以及适用场景就可以了。 1、乐观锁并未真正加锁,效率高。一旦锁的粒度掌握不好,更新失败的概率就会比较高,容易发生业务失败。 2、悲观锁依赖数据库锁,效率低。更新失败的概率比较低。 随着互联网三高架构(高并发、高性能、高可用)的提出,悲观锁已经越来越少的被使用到生产环境中了,尤其是并发量比较大的业务场景。 """
按加锁方式划分
自动锁 显示锁
按操作划分
DML锁 DDL锁
""" DML锁(data locks,数据锁),用于保护数据的完整性,其中包括行级锁(Row Locks (TX锁))、表级锁(table lock(TM锁))。 DDL锁(dictionary locks,数据字典锁),用于保护数据库对象的结构,如表、索引等的结构定义。
其中包排他DDL锁(Exclusive DDL lock)、共享DDL锁(Share DDL lock)、可中断解析锁(Breakable parse locks) """ 粒度:行级< 表级 < 页级 级别越高并发越低,考虑到性能,innodb默认支持行级锁,但是只有在命中索引的情况下才锁行,否则锁住所有行,本质还是行锁, 但是此刻相当于锁表了
行级锁有三种算法:
Record lock
Gap lock
Next-key lock(默认)= Record lock+ Gap lock ------》 解决幻读问题
级别:排他、共享
排他
共享
使用方式:悲观、乐观