3.1 表结构和数据类型
3.1.1 表和表结构
每个数据库包含了若干个表。表是SQL Server中最主要的数据库对象,它是用来存储数据的一种逻辑结构。表由行和列组成,因此也称为二维表。表是在日常工作和生活中经常使用的一种表示数据及其关系的形式,表3.1就是用来表示学生情况的一个学生表。

下面简单介绍与表有关的几个概念:
(1)表结构。组成表的各列的名称及数据类型,统称为表结构。
(2)记录。每个表包含了若干行数据,它们是表的“值”,表中的一行称为一个记录。因此,表是记录的有限集合。
(3)字段。每个记录由若干个数据项构成,将构成记录的每个数据项称为字段。例如,表3.1中表结构为(学号,姓名,性别,出生时间,专业,总学分,备注),包含7个字段,由5个记录组成。
(4)空值。空值(NULL)通常表示未知、不可用或将在以后添加的数据。若一个列允许为空值,则向表中输入记录值时可不为该列给出具体值;而一个列若不允许为空值,则在输入时必须给出具体值。
(5)关键字。若表中记录的某一字段或字段组合能唯一标识记录,则称该字段或字段组合为候选关键字(Candidate key)。若一个表有多个候选关键字,则选定其中一个为主关键字(Primary key),也称为主键。当一个表仅有唯一的一个候选关键字时,该候选关键字就是主关键字。这里的主关键字与第1章中的主码所起的作用是相同的,都用来唯一标识记录行。
例如,在学生表中,2个及其以上记录的姓名、性别、出生时间、专业、总学分和备注这6个字段的值有可能相同,但是“学号”字段的值对表中所有记录来说一定不同,即通过“学号”字段可以将表中的不同记录区分开来。所以,“学号”字段是唯一的候选关键字,学号就是主关键字。再例如,学生成绩表记录的候选关键字是(学号,课程号)字段组合,它也是唯一的候选关键字。
3.1.2 数据类型
列的数据类型可以是SQL Server提供的系统数据类型,也可以是用户定义的数据类型。SQL Server 2008提供了丰富的系统数据类型,现将其列于表3.2中。
表3.2 系统数据类型表
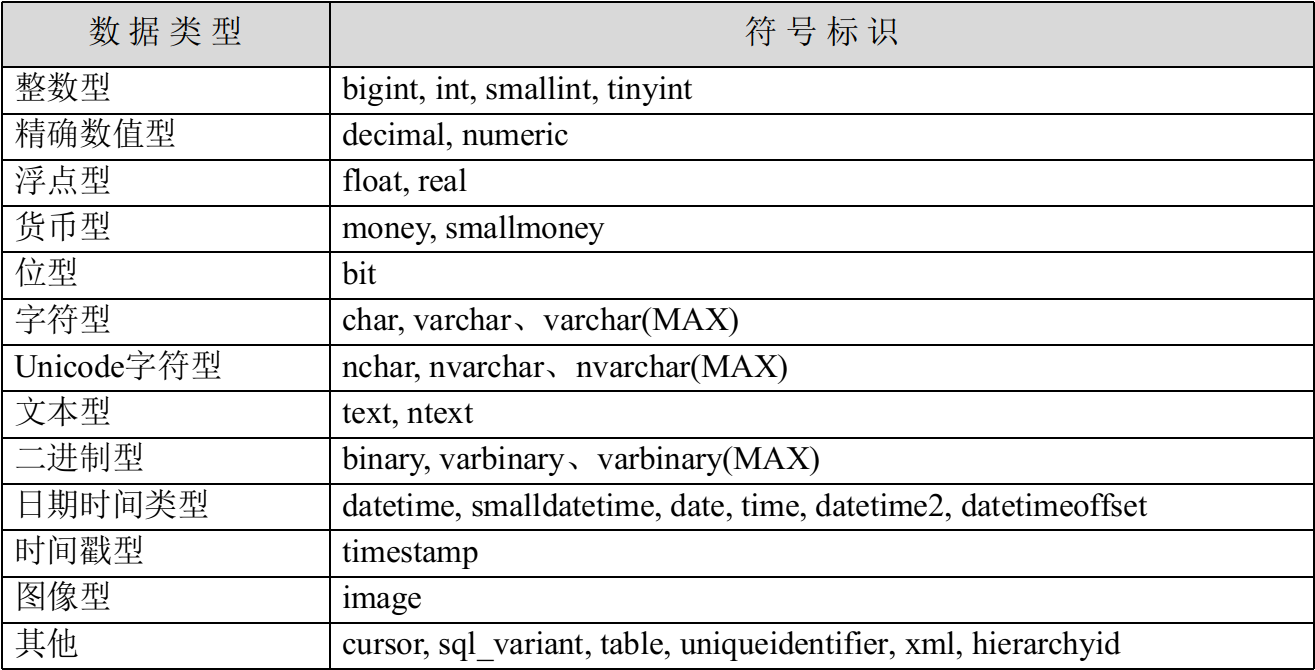
在讨论数据类型时,使用了精度、小数位数和长度3个概念,前两个概念是针对数值型数据的,它们的含义如下。
- 精度:指数值数据中所存储的十进制数据的总位数。
- 小数位数:指数值数据中小数点右边可以有的数字位数的最大值。例如,数值数据3890.587的精度是7,小数位数是3。
- 长度:指存储数据所使用的字节数。
下面分别说明常用的系统数据类型。
1.整数型
整数型包括bigint、int、smallint和tinyint,从标识符的含义就可以看出,它们的表示数范围逐渐缩小。
bigint:大整数,数范围为-263~263-1,其精度为19,小数位数为0,长度为8字节。
int:整数,数范围为-231~231-1,其精度为10,小数位数为0,长度为4字节。
smallint:短整数,数范围为-215~215-1,其精度为5,小数位数为0,长度为2字节。
tinyint:微短整数,数范围为0~255,长度为1字节,其精度为3,小数位数为0,长度为1字节。
[19/2]=10 10/2=5 [5/2]=3
2.精确数值型
精确数值型数据由整数部分和小数部分构成,其所有的数字都是有效位,能够以完整的精度存储十进制数。精确数值型包括decimal 和 numeric两类。在SQL Server 2008中,这两种数据类型在功能上完全等价。
声明精确数值型数据的格式是numeric | decimal(p[,s]),其中,p为精度,s为小数位数,s的默认值为0。例如,指定某列为精确数值型,精度为6,小数位数为3(最少保留多少位,整数少了可给小数),即decimal(6,3),那么当向某记录的该列赋值56.342 689时,该列实际存储的是56.3427。
decimal和numeric可存储–1038 +1~1038 –1 的固定精度和小数位的数字数据,它们的存储长度随精度变化而变化,最少为5字节,最多为17字节。
例如,若有声明numeric(8,3),则存储该类型数据需5字节;而若有声明numeric(22,5),则存储该类型数据需13字节。
3.浮点型
浮点型也称近似数值型。顾名思义,这种类型不能提供精确表示数据的精度,使用这种类型来存储某些数值时,可能会损失一些精度,所以它可用于处理取值范围非常大且对精确度要求不太高的数值量,如一些统计量。
有两种近似数值数据类型:float[(n)]和real,两者通常都使用科学计数法表示数据,即形为尾数E阶数,如5.6432E20,–2.98E10,1.287659E-9等。
real:使用4字节存储数据,表数范围为–3.40E + 38~3.40E + 38,数据精度为7位有效数字。
float:float型数据的数范围为–1.79E+308~1.79E+308。定义中的n取值范围是1~53,用于指示其精度和存储大小。当n在1~24之间时,实际上将定义一个real型数据,存储长度为4字节,精度为7位有效数字。当n在25~53之间时,存储长度为8字节,精度为15位有效数字。当省略n时,代表n在25~53之间。
数据定义:指对数据库对象的定义、删除和修改操作。
数据库对象主要包括数据表、视图、索引等。
数据定义功能通过CREATE、ALTER、DROP语句来完成。
按照操作对象分类来介绍数据定义的SQL语法。
5.3.1 数据表的创建和删除
数据表是关系模式在关系数据库中的实例化,是数据库中唯一用于存储数据的数据库对象,它是整个数据库系统的基础。创建数据表是数据库建立的重要组成部分,由SQL语言中的CREATE TABLE语句来完成,其语法格式如下:
CREATE TABLE [schema_name.]table_name(
column1_name data_type [integrality_condition_on_column]
[,column2_namedata_type [integrality_condition_on_column]]
…
[, integrality_condition_on_TABLE]);
所涉及参数说明如下:
tanble_name为所定义的数据表的名称,即表名。在一个数据库中表名必须唯一,而且表名应该能够概括该数据表保存数据所蕴涵的主题。
schema_name为表所属的架构的名称。自SQL Server 2008开始,每数据库对象都属于某一个架构,如果在定义时不指定架构,则使用默认架构dbo。关于架构的作用和意义将在第12章中介绍。
column1_name、column2_name表示字段名,或者称字段名。在一个表中,字段名也必须唯一,最好能够概括该字段的含义。
data_type表示数据类型。根据需要,它可以设置为上节介绍的数据类型中某一种。
integrality_condition_on_column表示字段级的完整性约束条件。这些约束条件只对相应的字段起作用,其取值如下:
NOT NULL:选取该条件时,字段值不能为空。
DEFAULT:设定字段的默认值,设置格式为:DEFAULT constant,其中constant表示常量。
UNIQUE:选取该条件时,字段值不能重复。
CHECK:用于设置字段的取值范围,格式为:CHECK(expression),其中expression为约束表达式。
PRIMARY KEY:选取该条件时,相应字段被设置为主码(主键)。
FOREIGN KEY:选取该条件时,相应字段被设置为外码(外键)。外码的设置涉及到两个表,其格式如下:
FOREIGN KEY column_name REFERENCES
foreign_table_name(foreign_column_name)
integrality_condition_on_TABLE表示表级的完整性约束条件。
与integrality_condition_on_column不同的是,integrality_condition_on_column仅仅作用于其对应的字段,而不能设置为同时作用于多个字段;integrality_condition_on_TABLE则可以作用多个字段或整个数据表。
上述的约束条件中,除了NOT NULL和DEFAULT以外,其他的约束条件都可以在integrality_condition_on_TABLE中定义,使它们同时作用多个字段。凡是涉及到多个字段的约束条件都必须在integrality_condition_on_TABLE中定义。
注意: 由两个字段组成的主码必须利用PRIMARY KEY在
integrality_condition_on_TABLE中定义。
SQL语言对大小写不敏感。
【例5.1】 表5.8给出了学生信息表(student)的基本结构。表中列出了所有的字段名及其数据类型和约束条件。
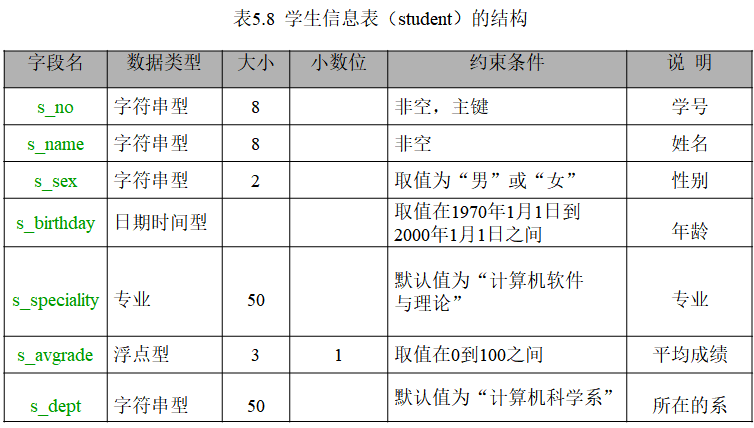
根据上述介绍的内容,我们不难构造出下列的CREATE TABLE语句,用于创建本例设定的学生信息表student:
CREATE TABLE student(
s_no char(8) PRIMARY KEY,
s_name char(8) NOT NULL,
s_sex char(2) CHECK(s_sex = '男' OR s_sex = '女'),
s_birthday smalldatetimeCHECK(s_birthday>='1970-1-1' AND
s_birthday<='2000-1-1'),
s_speciality varchar(50) DEFAULT '计算机软件与理论',
s_avgrade numeric(3,1) CHECK(s_avgrade >= 0 AND s_avgrade <= 100),
s_dept varchar(50) DEFAULT '计算机科学系'
);
本书涉及的SQL代码都是在SQL Server Management Studio(简称SSMS)中的SQL代码编辑器中执行。
【例子】 图5.1是执行上述CREATE TABLE语句来创建表student时的界面。
在以上的CREATE TABLE语句中,约束条件都是在字段级的完整性约束定义上实现的。实际上也可以在表级的完整性约束定义上实现上述的部分或全部约束条件。
下列的CREATE TABLE语句等价于上述语句:
CREATE TABLE student(
s_no char(8) ,
s_name char(8) NOT NULL,
s_sex char(2) ,
s_birthday smalldatetime,
s_speciality varchar(50) DEFAULT '计算机软件与理论',
s_avgrade numeric(3,1) CHECK(s_avgrade >= 0 AND s_avgrade <= 100),
s_dept varchar(50) DEFAULT '计算机科学系',
PRIMARY KEY(s_no),
CHECK(s_birthday>='1970-1-1' AND s_birthday<='2000-1-1'),
CHECK(s_sex ='男' OR s_sex ='女')
);
当涉及到多字段的约束条件时,则必须使用表级的完整性约束定义来实现。
如果需要将字段s_name和字段s_birthday设置为主键,则必须通过表级的完整性约束定义来实现,相应的语句如下:
CREATE TABLE student(
s_no char(8) ,
s_name char(8) NOT NULL,
s_sex char(2) CHECK(s_sex = '男' OR s_sex = '女'),
s_birthday smalldatetimeCHECK(s_birthday>='1970-1-1' AND s_birthday<='2000-1-1'),
s_speciality varchar(50) DEFAULT '计算机软件与理论',
s_avgrade numeric(3,1) CHECK(s_avgrade >= 0 AND s_avgrade <= 100),
s_dept varchar(50) DEFAULT '计算机科学系',
PRIMARY KEY(s_name, s_birthday)
);
【例5.2】 表5.9给出了导师信息表(supervisor)的基本结构,其中c_hour表示导师的工作量,其取值由其指导的学生数量s_n确定:每指导一位学生计15个课时。
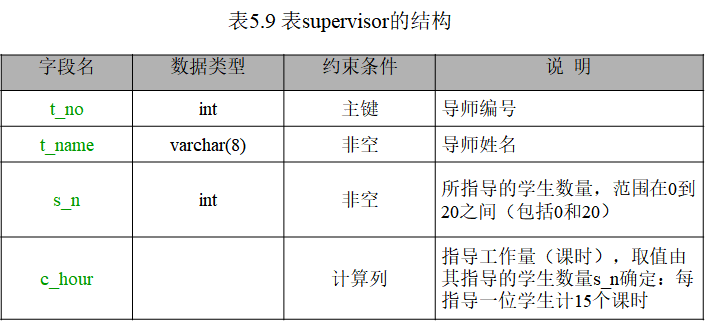
根据上述要求,用AS将c_hour定义为计算列,结果CREATE TABLE语句代码如下:
CREATE TABLE supervisor(
t_noint PRIMARY KEY,
t_namevarchar(8) NOT NULL,
s_nint NOT NULL CHECK(s_n>=0 and s_n<=20),
c_hour AS s_n*15
);
当数据表已经确认不需要时,可将其删除。删除格式如下:
DROP TABLE table1_name [,table2_name,…];
【例子】 删除以上创建的表student,可用下列的SQL语句:
DROP TABLE student;
当一个数据表被删除时,其中的数据也将全部被删除。在使用删除语句的时候要特别慎重。
5.3.2 数据表的修改
数据表的修改是指对数据表结构的修改,包括修改字段名和完整性约束条件、增加和删除字段等。这些操作主要由ALTER TABLE语句来完成。
(1)增加字段
在数据表中增加新字段的语法格式为:
ALTER TABLE table_name
ADD new_column data_type [integrality_condition]
【例5.3】 在表student中增加一个新字段——nationality(民族),其长度为20个字符。
可由下列语句完成:
ALTER TABLE student
Add nationality varchar(20);
如果要使得新增加的字段为非空,则可在上述语句后添加“NOT NULL”来完成:
ALTER TABLE student
Add nationality varchar(20) NOT NULL;
但在执行上述语句时,表student必须为空。
(2)删除字段
删除某一个字段的语法格式如下:
ALTER TABLE table_name
DROP COLUMN column_name
【例5.4】 删除表student中的字段nationality。
可以用下列语句完成:
ALTER TABLE student
DROP COLUMN nationality
(3)修改字段的数据类型
在数据表中,修改一个字段的数据类型的语法格式如下:
ALTER TABLE table_name
ALTER COLUMN column_name new_data_type
column_name为待修改的字段,new_data_type为新的数据类型。
【例5.5】 将表student中的字段s_dept的长度由原来的50改为80。
该要求可下列语句实现:
ALTER TABLE student
ALTER COLUMN s_dept varchar(80);
将字段s_no由原来的字符型改为整型,则可用下列的语句:
ALTER TABLE student
ALTER COLUMN s_no int;
