简介
这个学期上完了虚拟化与云计算这门课程,涉及到了大数据的一些实验,由于Hadoop的单机伪分布式配置在网上还是非常的杂碎,所以我自己写了个方便自己理解的安装教程。
环境介绍
OS: Ubuntu 20.04
JDK: OpenJdk 8
Hadoop: 3.13
过程
配置Hadoop用户
hadoop用户的创建,并且赋予root权限
useradd -m hadoop -s /bin/bash
passwd hadoop
adduser hadoop sudo
su hadoop
注意我们这里要先进行用户的登录产生配置文件才能进行以下的步骤,否则会失败。
启用SSH免密登录
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
输入指令后,我们可以测试是否成功配置免密登录。输入SSH localhost便知道。
安装JDK
鉴于目前JDK的版本号更改,本次安装基于OpenJDK,首先我们可以在清华大学的镜像站中下载JDK包,我们这里选择OpenJDK8.
解压到/usr/lib/jdk/目录下,并且更名为jdk8,方便辨识。
然后我们需要进行环境变量的修改。
输入sudo vim /etc/profile 进入vim界面。
键入以下内容:
JAVA_HOME=/usr/lib/jdk/jdk8
CLASSPATH=$JAVA_HOME/lib/
PATH=.:$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
相信vim怎么用玩过linux的人都知道。
保存退出后我们需要输入source /etc/profile来使环境变量即时生效。
测试安装配置结果
我们在终端中输入java -version可以查看版本号等配置信息

安装配置Hadoop
首先下载Hadoop,解压缩到 /usr/local/ 目录下, 本次试验中下载的版本是hadoop-3.1.3,更改目录名称为/hadoop。修改与hadoop相关的配置文件,分别是core-site.xml, hadoop-env.sh, hdsf-site.xml, mapred-site.xml, yarn-site.xml。
首先我们先把Hadoop的目录配置到环境变量中。

然后输入source /etc/profile来使环境变量即时生效。
我们先切换到/usr/local/hadoop目录下进行以下操作。
- core-site.xml配置
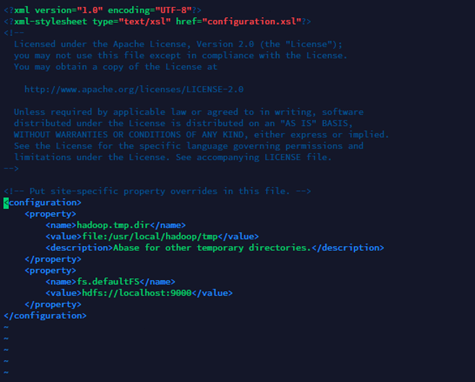
cd etc/Hadoopvim core-site.xml进入编辑界面,输入以下内容并且保存退出。
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
2. hadoop-env.sh配置
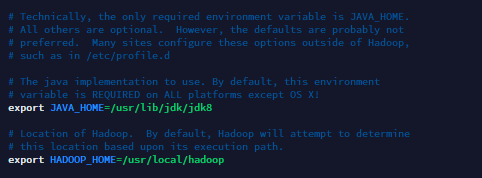
vim etc/hadoop/hadoop-env.sh
找到下面两条指令改成自己对应的目录,然后保存退出。
3. hdfs-site.xml配置
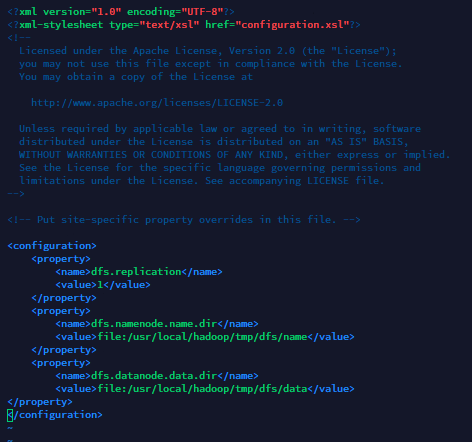
vim etc/Hadoop/hdfs-site.xml,插入以下内容并且退出。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
然后需要创建tmp, dfs, name, data目录,这里我把指令直接放出来,按照自己机器的不同进行修改即可。
cd ../../
sudo mkdir tmp
cd tmp
mkdir dfs
cd dfs
mkdir name, data
- mapred-site.xml
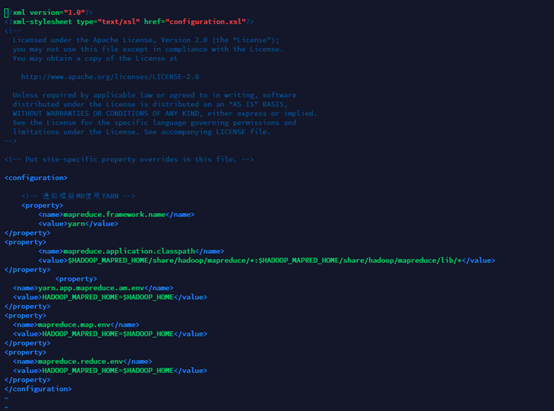
输入vim etc/Hadoop/mapred-site.xml进入编辑界面,插入以下内容。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
保存退出。
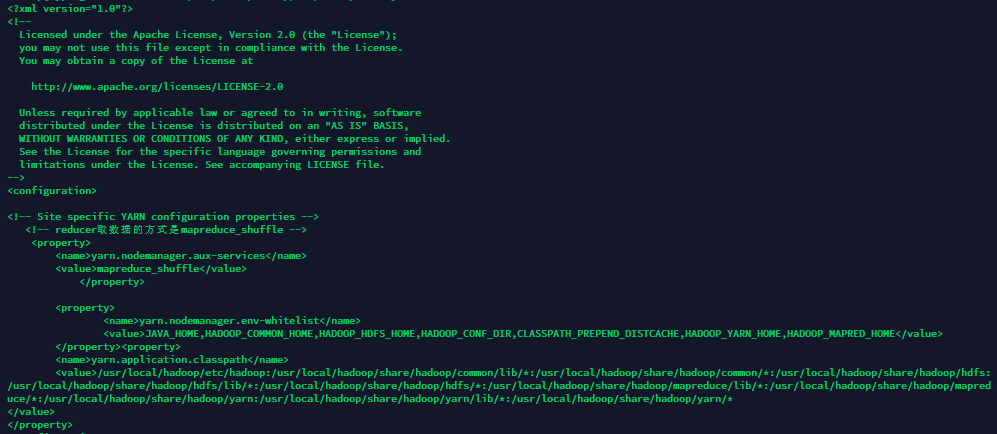
5. yarn-site.xml
如果我们不配置这个,我们会无法正常启动机器自带的wordcount等jar包。
我们输入vim etc/Hadoop/yarn-site.xml进入编辑界面,输入以下内容并保存退出即可。
<!-- Site specific YARN configuration properties -->
<!-- reducer取数据的方式是mapreduce_shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property><property>
<name>yarn.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop:/usr/local/hadoop/share/hadoop/common/lib/*:/usr/local/hadoop/share/hadoop/common/*:/usr/local/hadoop/share/hadoop/hdfs:/usr/local/hadoop/share/hadoop/hdfs/lib/*:/usr/local/hadoop/share/hadoop/hdfs/*:/usr/local/hadoop/share/hadoop/mapreduce/lib/*:/usr/local/hadoop/share/hadoop/mapreduce/*:/usr/local/hadoop/share/hadoop/yarn:/usr/local/hadoop/share/hadoop/yarn/lib/*:/usr/local/hadoop/share/hadoop/yarn/*
</value>
</property>
格式化节点
我们首次运行的时候,需要格式化存储节点,否则无法正常启动。
./bin/hdfs namenode -format
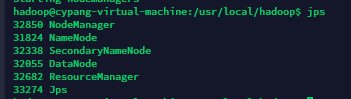
测试Hadoop配置情况
我们进入Hadoop的根目录,输入 ./sbin/start-all.sh,机器会提示正在启动,当启动结束后我们可以输入jps查看是否启动成功。
结语
至此,我们完成了Hadoop的单机伪分布式配置,虽然这只是一门普通的课程,但是是我感觉到在大学里学到最接近目前主流技术的一门课了。
参考文献
记录Ubuntu19.04安装hadoop3.2.1
在 Ubuntu16.04 上搭建 Hadoop-2.8.0 伪分布式环境