机器学习,如何组织数据?机器学习需要大量的训练样本、训练数据进行支持。那么这些数据来源于哪里呢?我们可以通过网络获取,也可以通过自己生成。
第三步我们开始解码,通过parse方法完成整个数据的解析,拿到单帧视频。如果大家想保存那么可以使用imwrite。
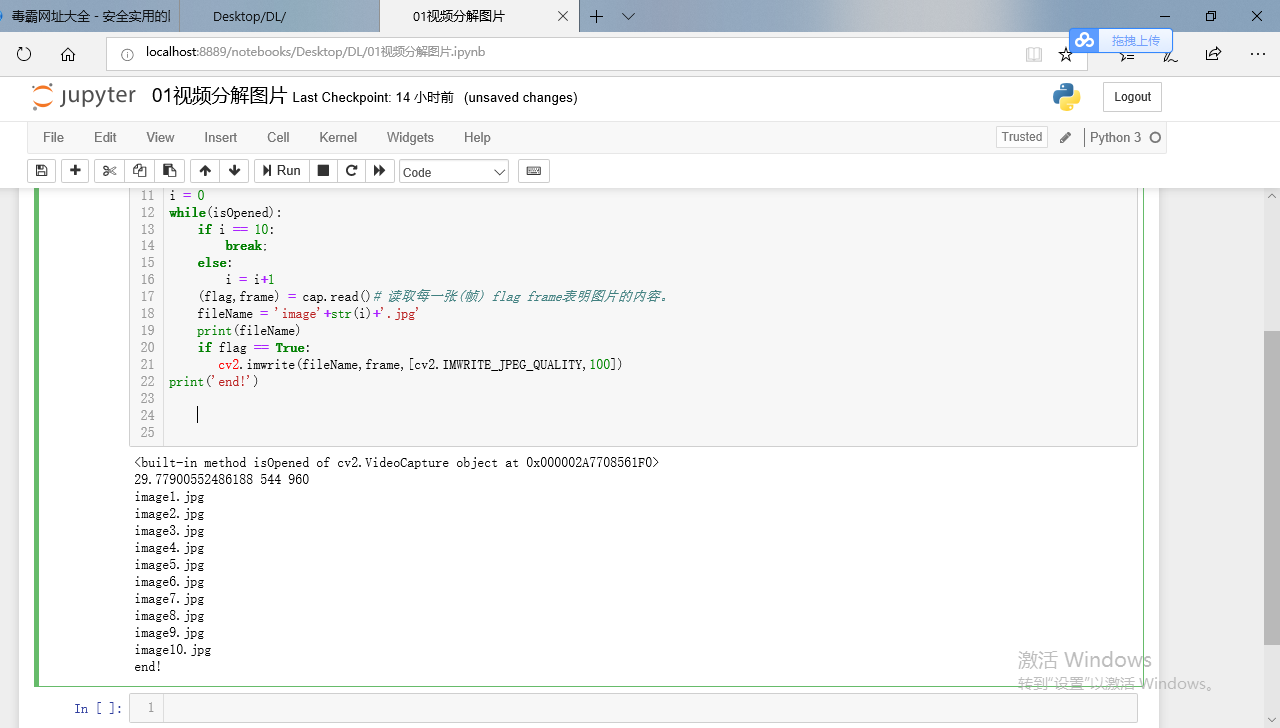
我们要捕获到一个视频,可以通过摄像头的方式,也可以通过本地文件。isOpened方法来判断它是否打开成功。第一个方法它是获取一个视频打开的句柄。帧率就是一个视频每秒钟可以为大家展示了多少张图片。我们之所以看一个图片它是连续的,实际上是因为帧率足够高。如果在一秒钟之内展示给大家足够多的图片,那么这种情况下我们可以看到一个视频是连续的。如果在一秒钟之内展示的图片个数比较少,那么这种情况下它的帧率就比较低。这个时候看到的图片就是非连续的。所以这个帧率比较的重要。它描述了就是每秒钟可以展示多少张图片。
FRAME就是帧,整个帧的宽度就是指每张图片的宽度。
我们可以看到每秒钟到底为大家展示多少张图片以及图片的宽度和高度。
i记录了我们当前总共读取了或者是保存了多少张。
图片读取进来之后它有两个参数:flag和frame。flag表明是否读取成功,frame表明图片的内容。
图片读取进来之后我们要把它保存一下。
第三个参数我们质量等级的控制。我们将质量写入100,表明质量最高。29帧代表一秒钟可以为我们展示29张图片,因此我们看起来还是比较连续的。经过研究,那么人眼最低的每秒帧分辨率是15帧。只要大家达到了15帧以上,那么视频看起来都是比较连续的。
# 视频分解图片 # 1 load 2 info 3 解码 parse 4 imshow imwrite import cv2 cap = cv2.VideoCapture("1.mp4")#我们要捕获到一个视频 获取一个视频打开cap 1 file name isOpened = cap.isOpened# 判断是否打开 只有正确打开,我们才能执行后续的操作 print(isOpened) fps = cap.get(cv2.CAP_PROP_FPS)#帧率 width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))#w h height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT)) print(fps,width,height) i = 0 while(isOpened): if i == 10: break; else: i = i+1 (flag,frame) = cap.read()# 读取每一张(帧) flag frame表明图片的内容。 fileName = 'image'+str(i)+'.jpg' print(fileName) if flag == True: cv2.imwrite(fileName,frame,[cv2.IMWRITE_JPEG_QUALITY,100]) print('end!')