
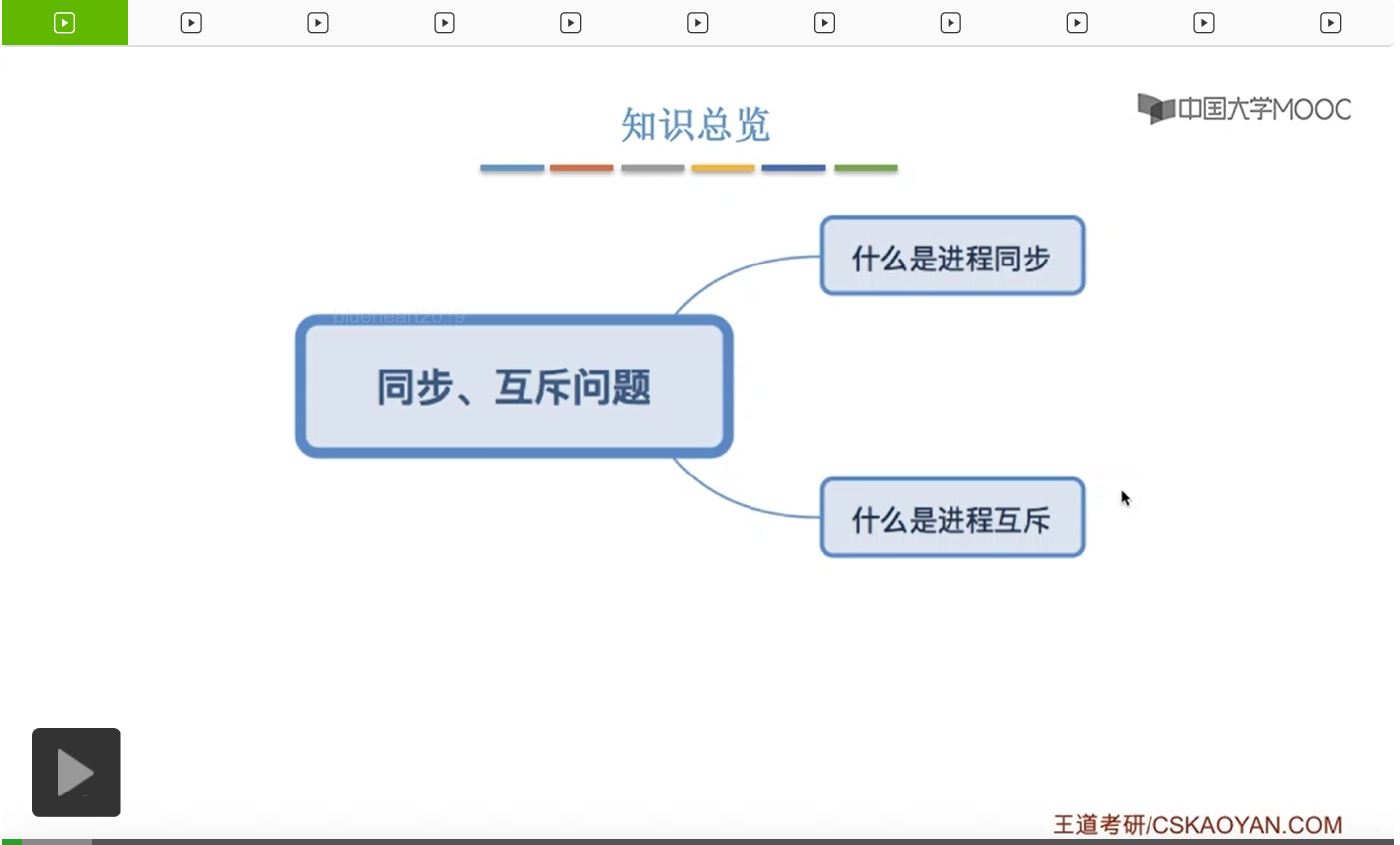

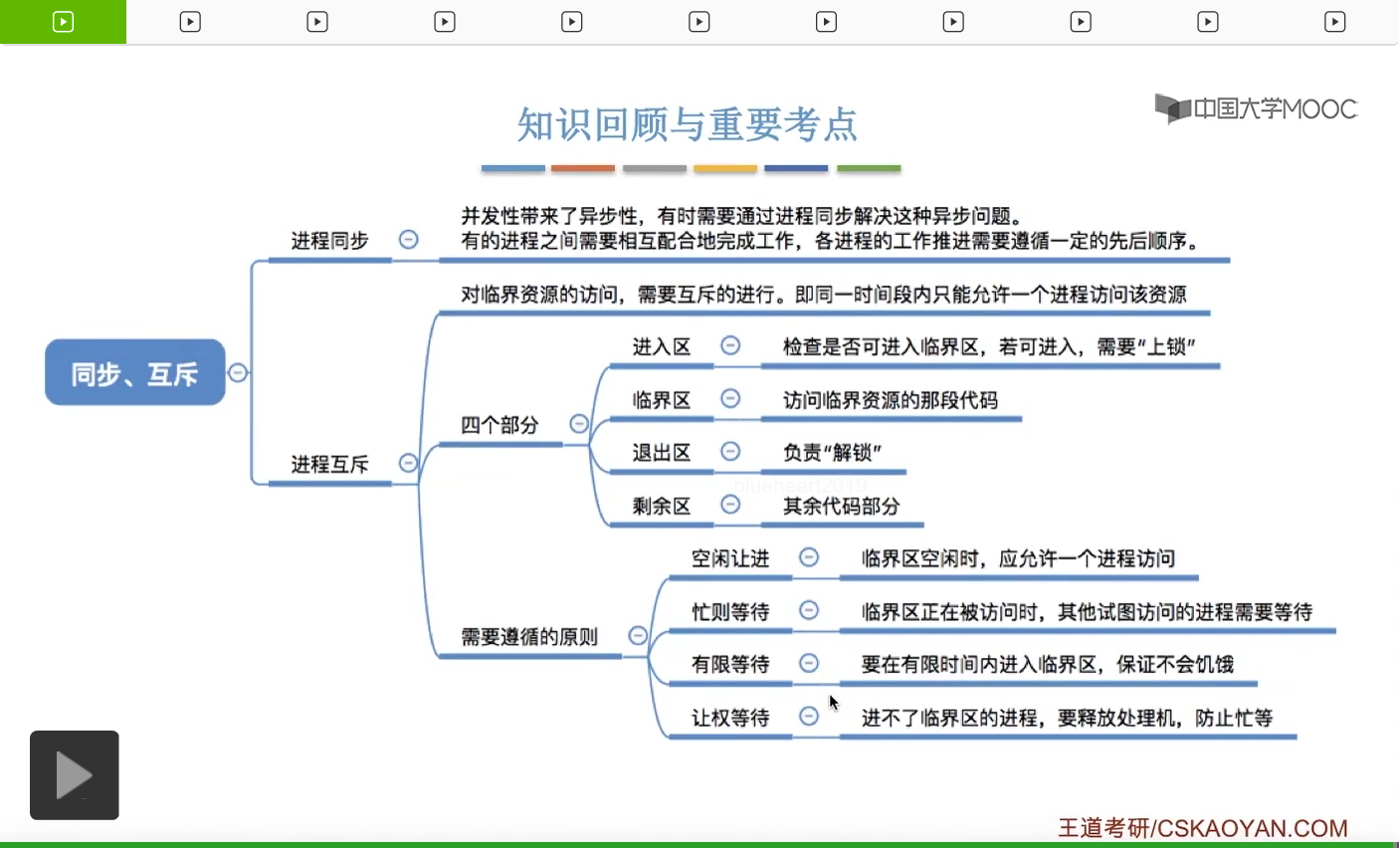

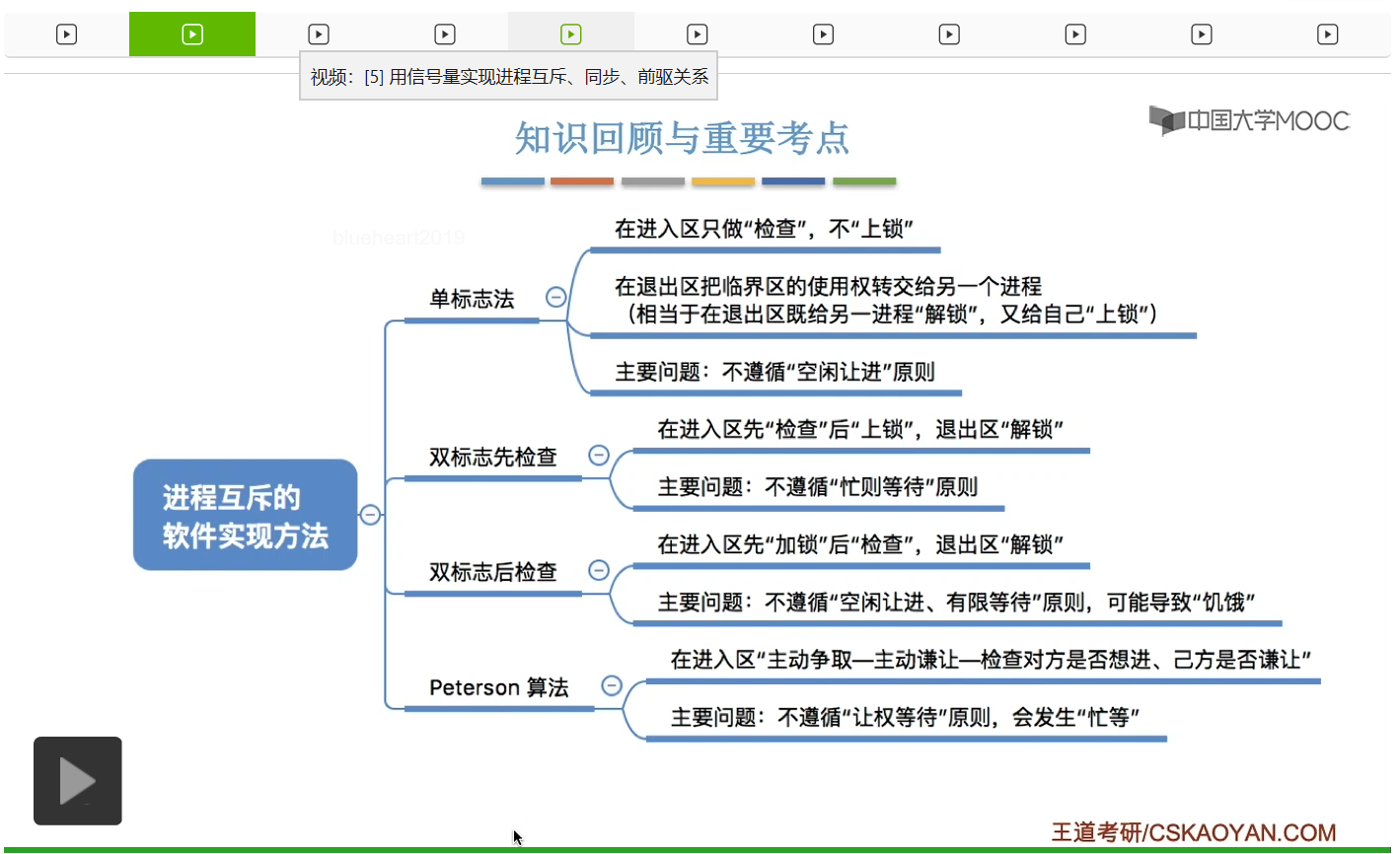
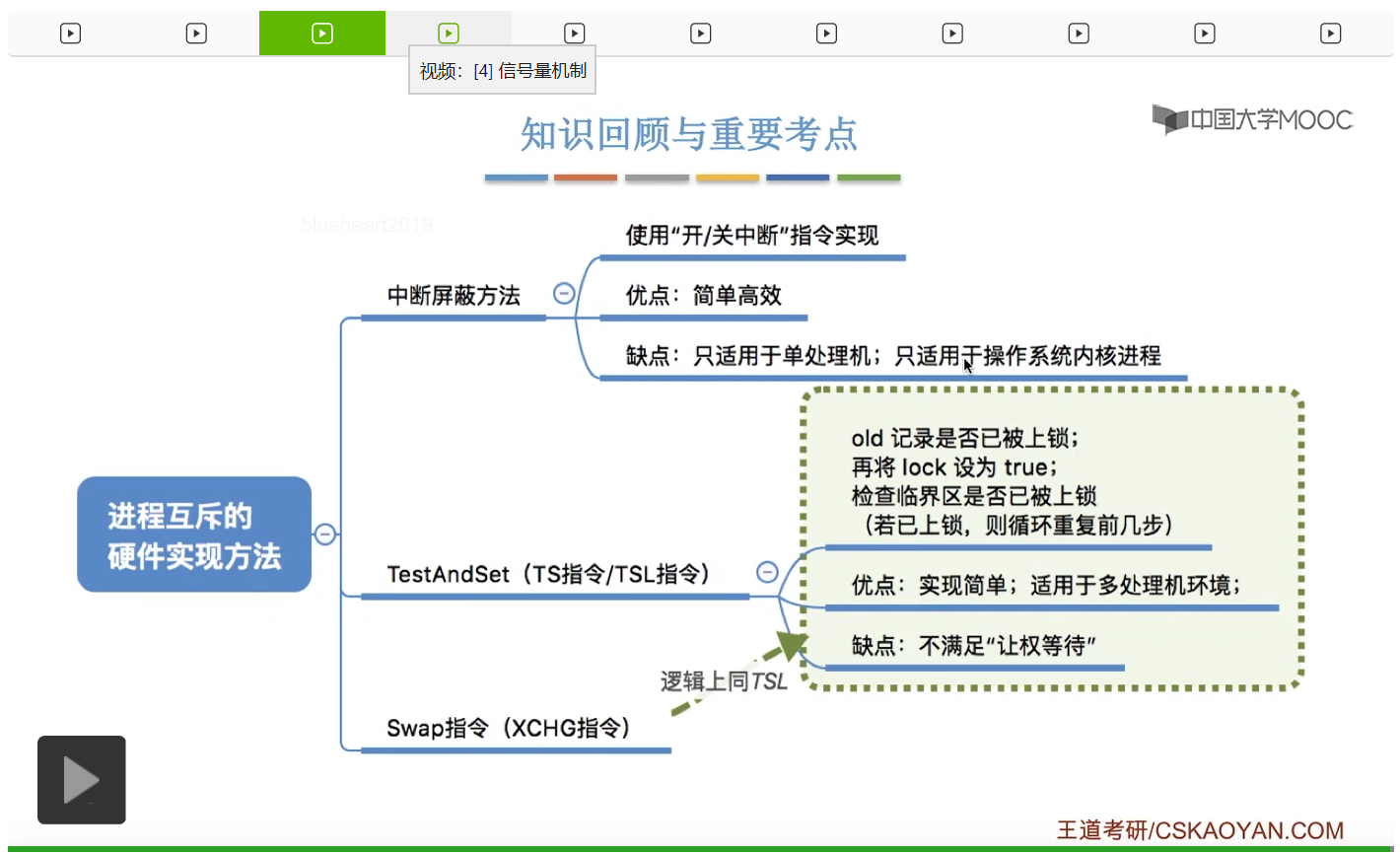
这个小节的考察频率总体来说还是很高的,经常会在选择题甚至大题当中进行考察,所以这个小节的内容十分重要。结合“实现互斥要遵循的四个原则”——空闲让进、忙则等待、有限等待、让权等待进行分析各算法存在的缺陷。



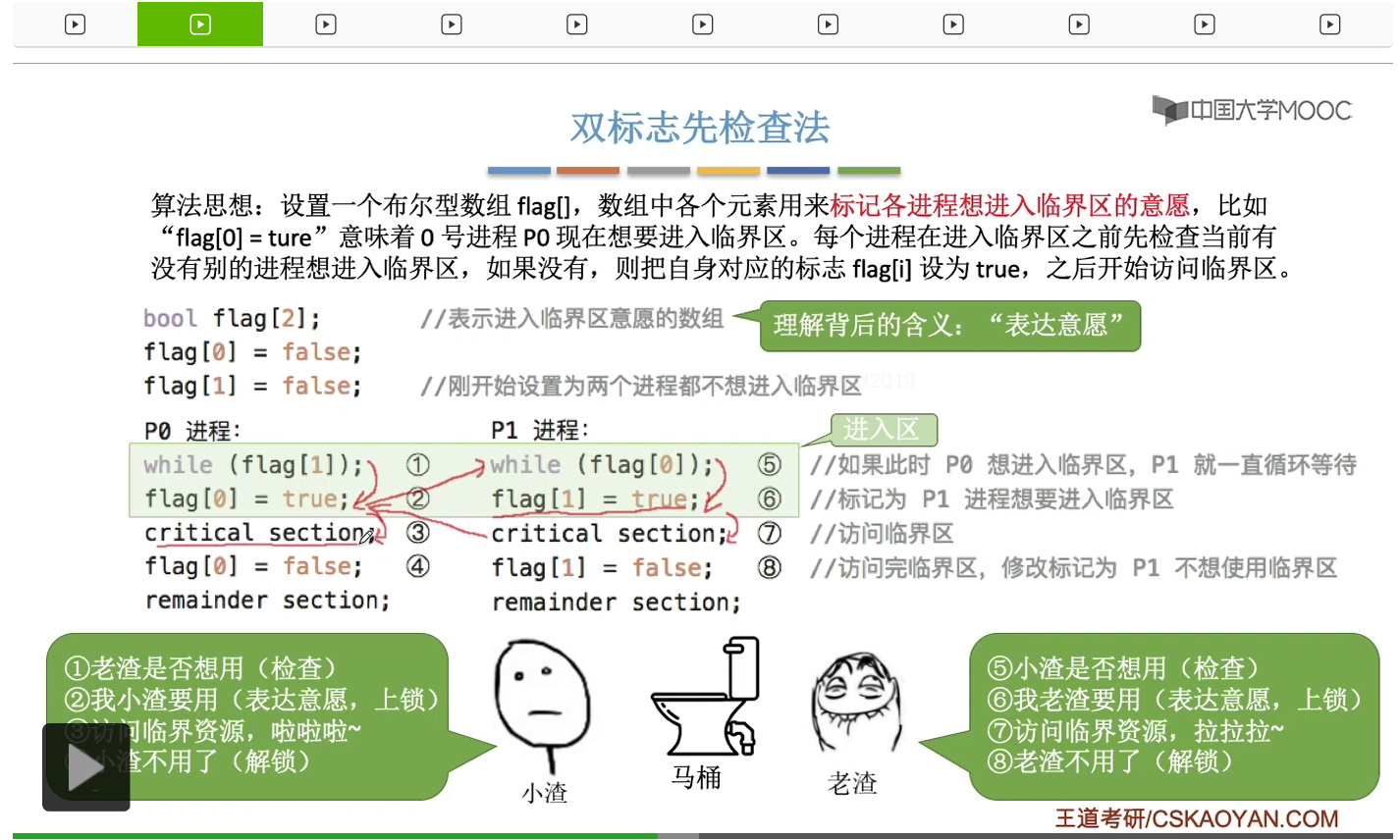
如果按①->⑤->②->⑥这样的方式来执行的话,小渣和老渣就同时开始使用马桶了,这是很奇怪的事情。










那么原语不可被中断的这个特性其实也是用这样一组指令来实现的。因为关中断指令只对执行关中断指令的那个处理机有用,所以如果此时处理机A执行了关中断指令,那么就意味着在这个处理机上面的进程不会被切换,那么这个进程就可以顺利地访问临界区。但是对另一个处理机处理机B来说,它其实还是会正常地切换进程。如果说此时另外的那个处理机上运行的进程,也需要访问这个临界区,也用这种方式的话,那么也有可能会发生两个处理机上的两个进程同时对临界区进行访问的情况,所以这是中断屏蔽方法不适用于多处理机的原因。另外一个缺点呢就是关中断和开中断这两个指令,它的权限特别大,它属于特权指令,需要在内核态下才能运行,因此这种方式只适用于操作系统内核进程,不适用于用户进程,只有操作系统内核进程才有权限执行关中断和开中断这两个指令,所以这是中断屏蔽方法。

这个地方虽然用了return,但实际硬件执行的过程当中其实就是把lock这个值放到了某一个物理寄存器里,然后再把lock这个值覆盖为true,是做了这样一个事情。为什么TestAndSet指令适用于多处理机环境,涉及到总线相关的一些特性。
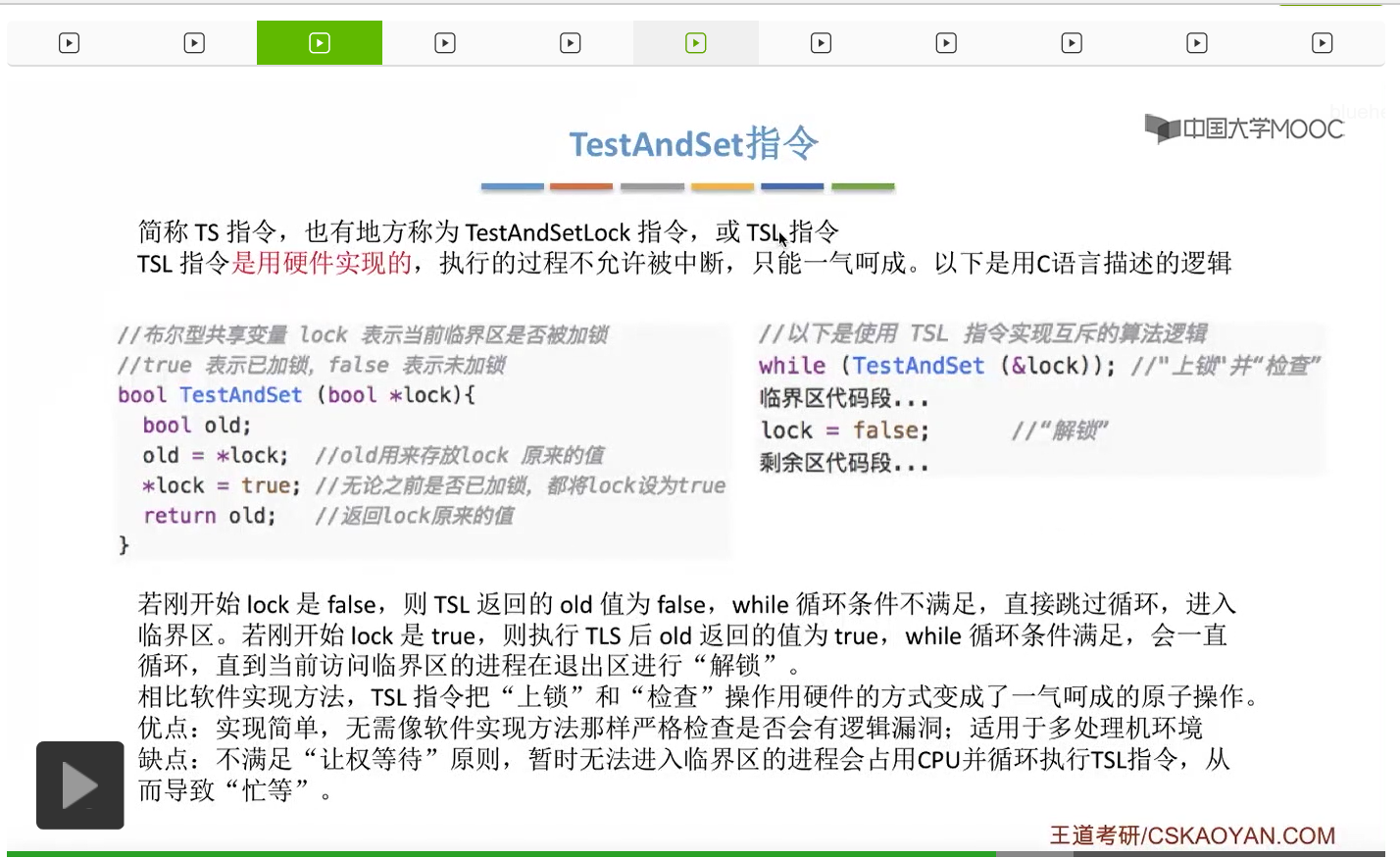
当然Swap指令和TSL指令在硬件层次可能实现的方式会不太一样,但是我们可以看到逻辑上看它们俩做的事情其实并没有太大的区别。

信号量其实我们可以把它简单地理解为它就是某一种变量,它可以是一个整数,也可以是比较复杂的记录型的这种数据结构的变量。信号量有整型信号量和记录型信号量。

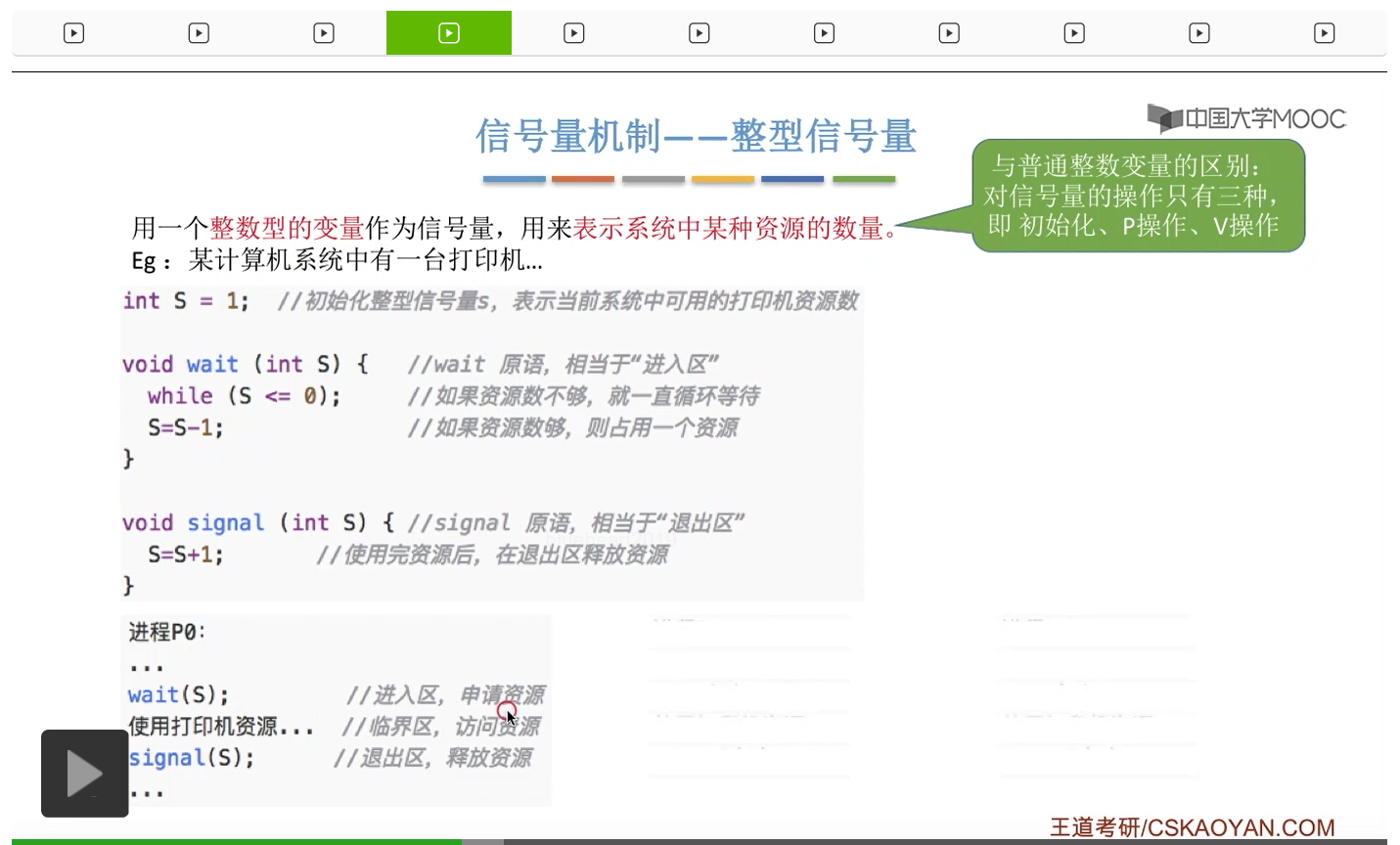
整型信号量在wait这个原语当中的这两个操作其实逻辑上来看和双标志先检查法当中先检查后上锁其实做的是一样的事情,大家可以对比着来串联一下这两个知识点。那么因为它是用一个原语来实现的检查和上锁,所以它这两个操作一气呵成,就避免了双标志先检查法那种就是两个进程同时进入临界区的问题。如果一个进程暂时进不了临界区,也就意味着它被卡在wait这个原语的这个while循环里,那么既然wait原语它是不可被中断的,那么也就意味着当前正在执行while循环的这个进程是不是一直不会被切换呢?这个地方确实是一个让人感觉不太严谨的地方。但是我们在很多经典的教材当中,其实它们都是这么写的,所以这个地方我们姑且认为它没有问题,不会导致一个进程一直占用处理机的情况吧。那在整型信号量当中其实比较容易考察的是它存在的问题这一点,经常会把这个整型信号量和记录型的信号量做对比。那么它俩的区别就在于整型信号量不满足“让权等待”,会发生忙等。


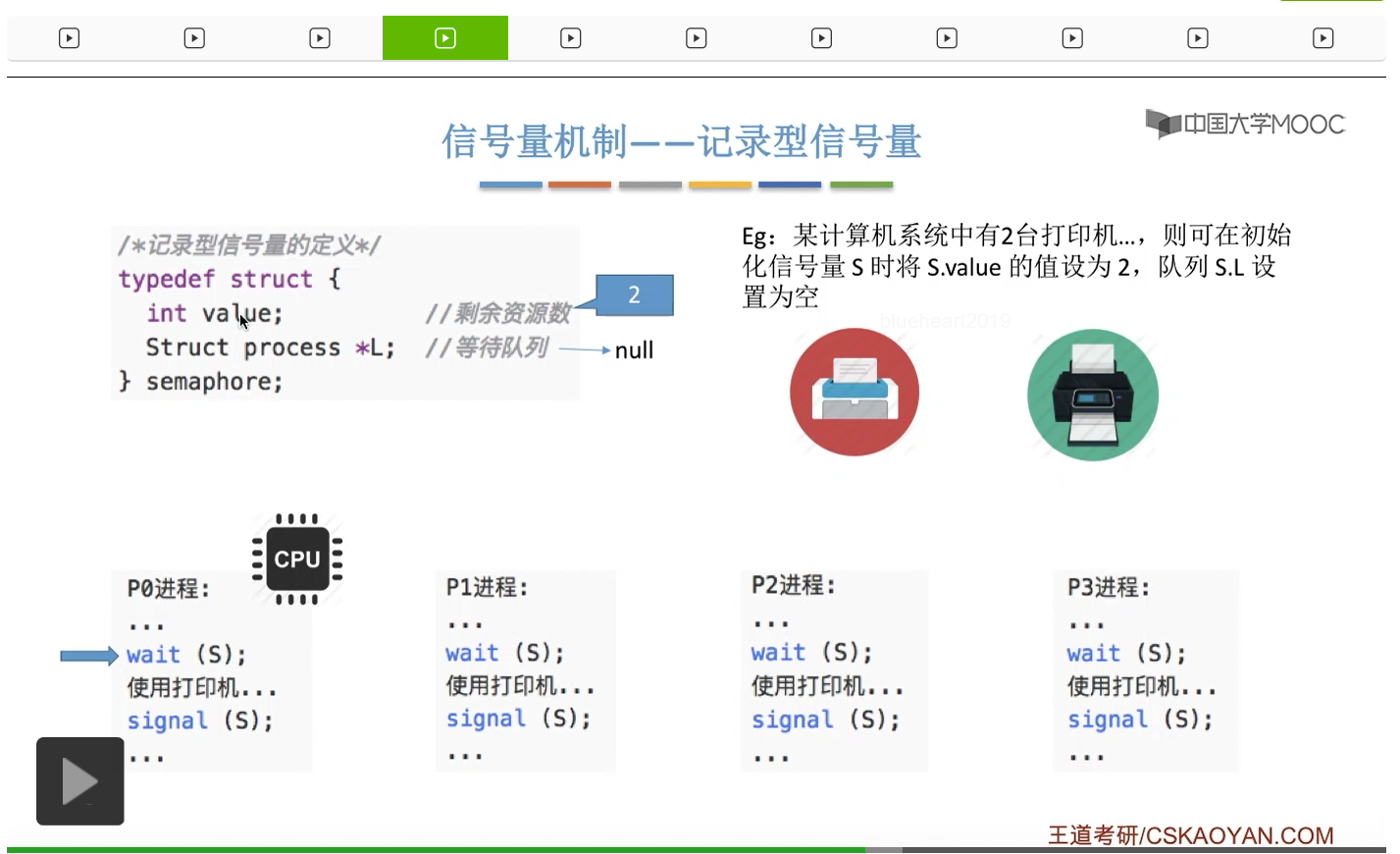
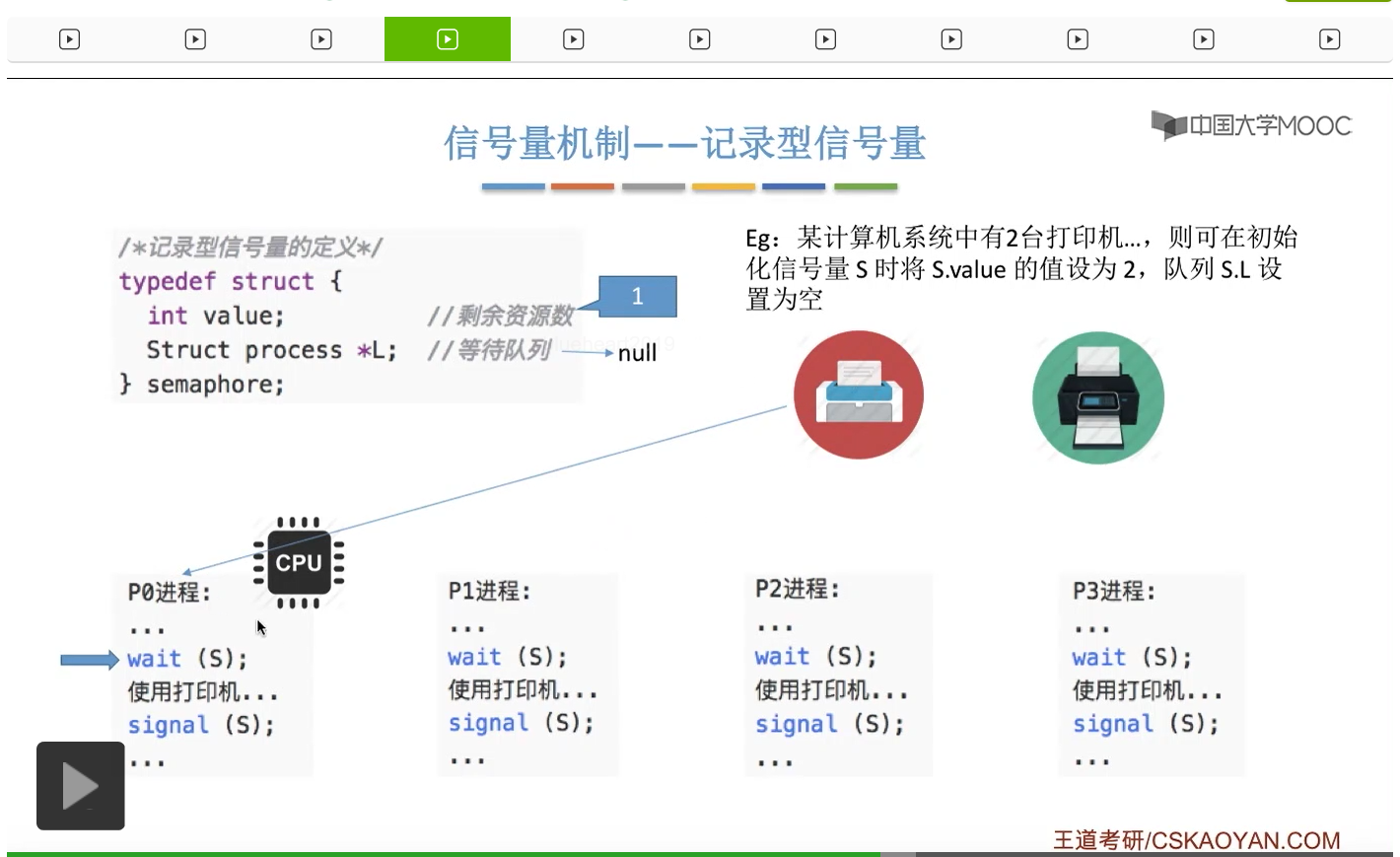
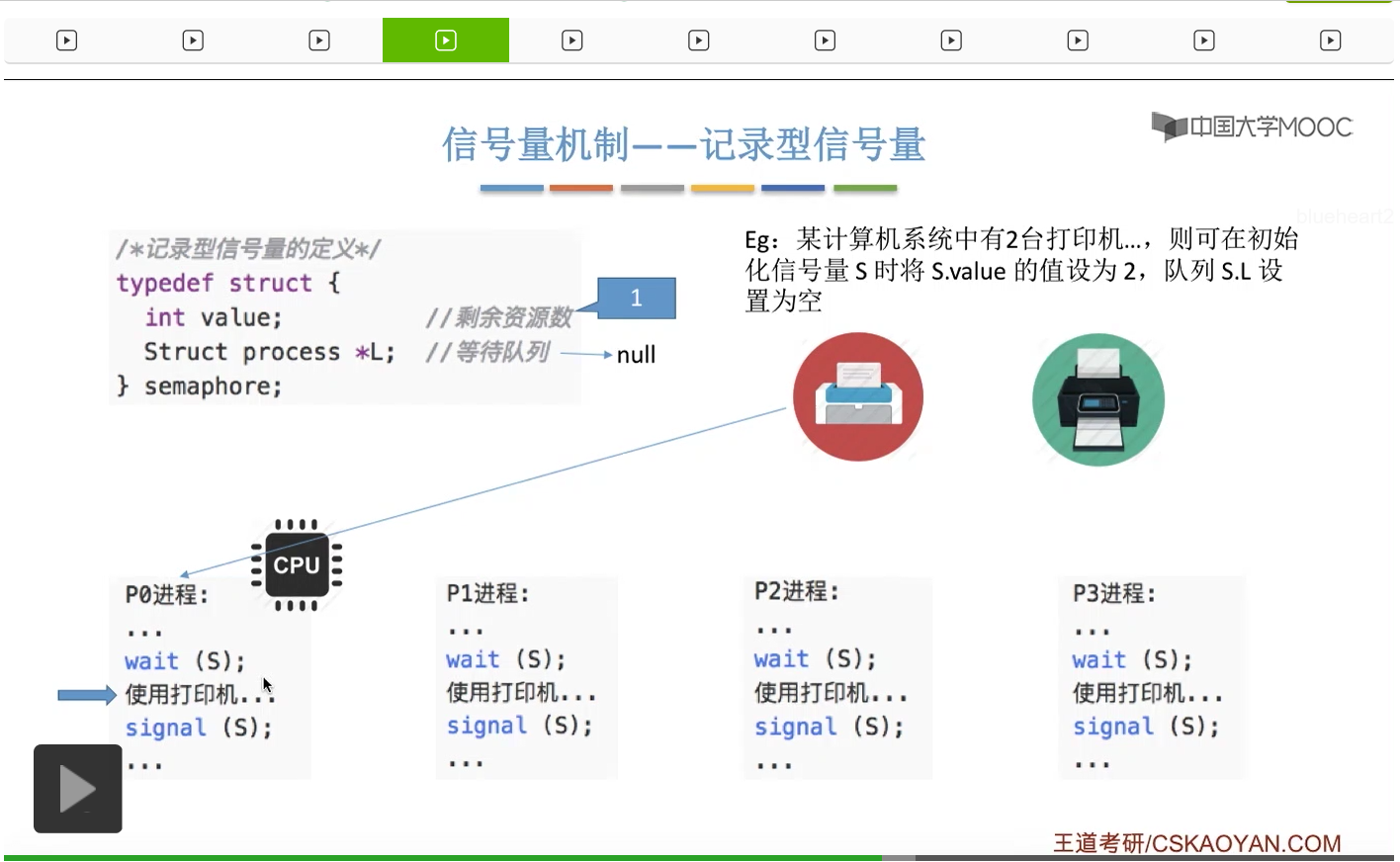
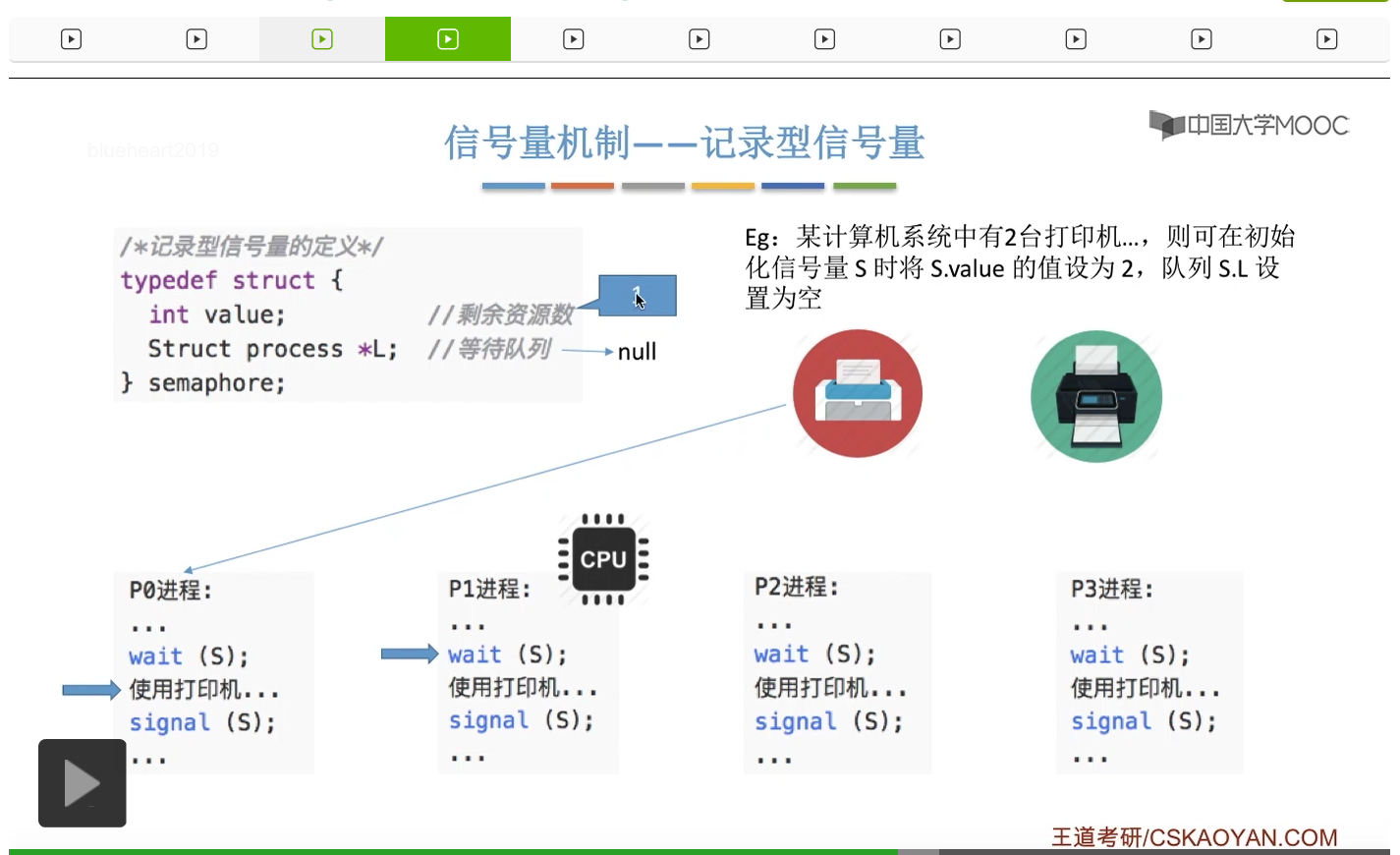
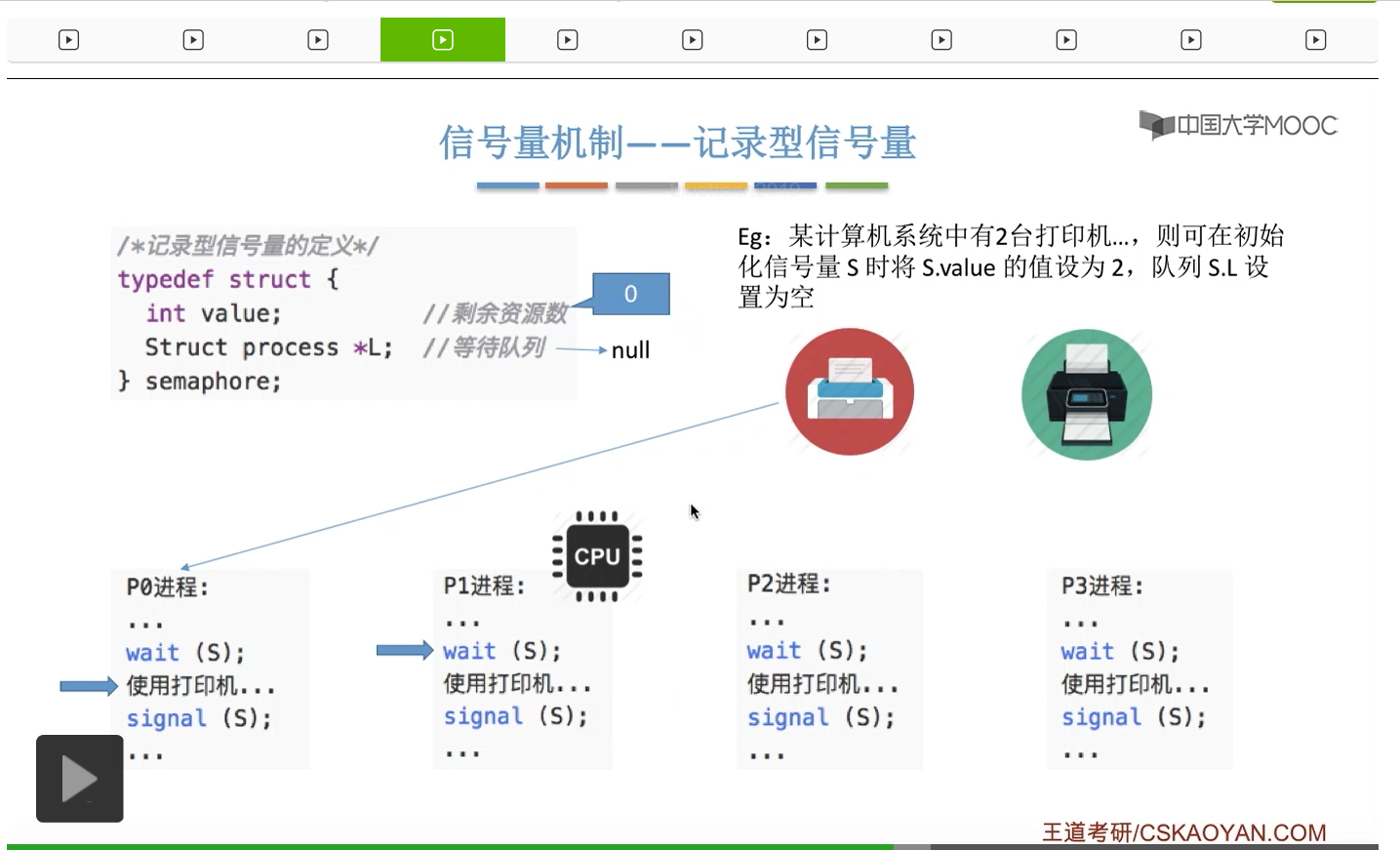
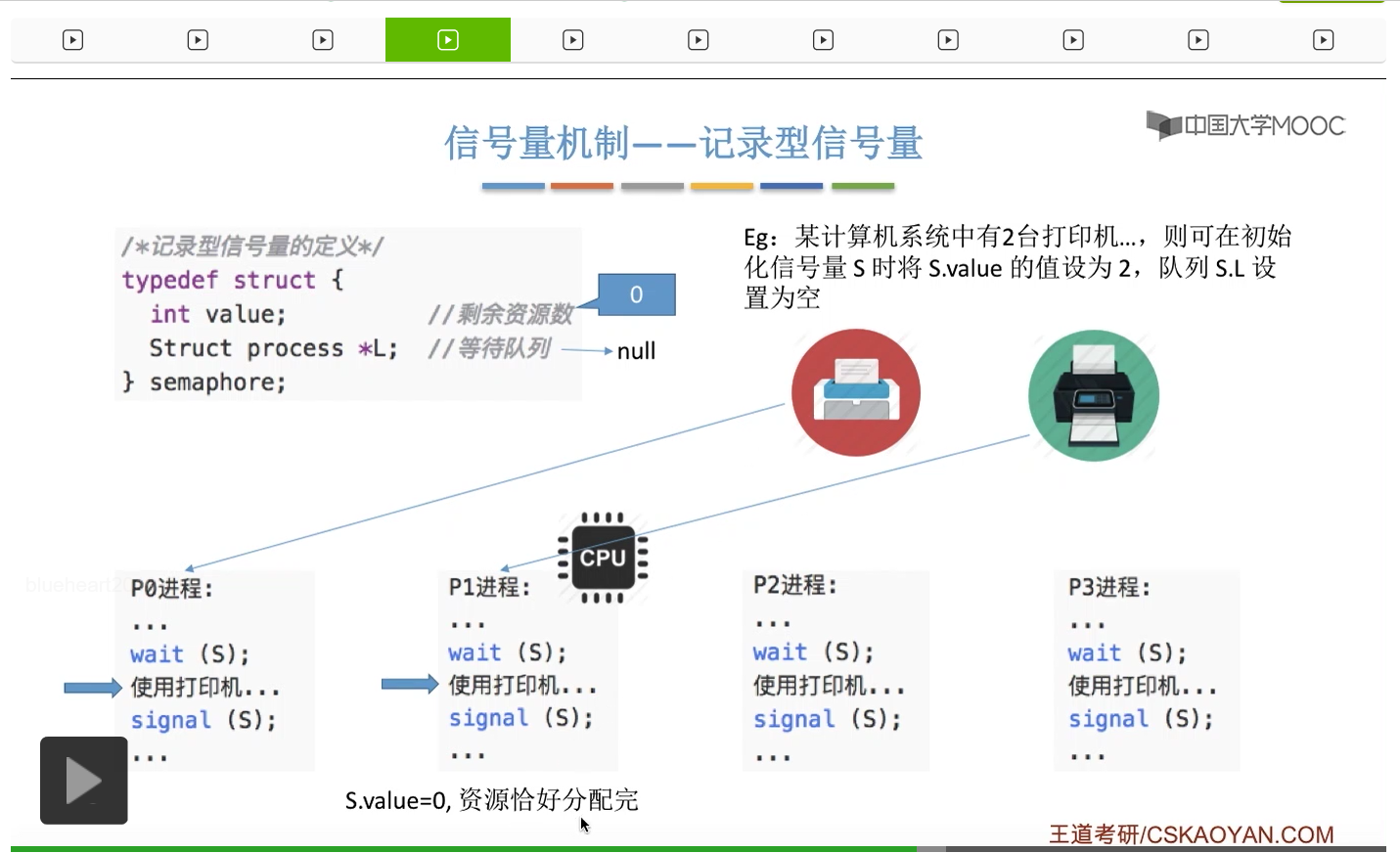
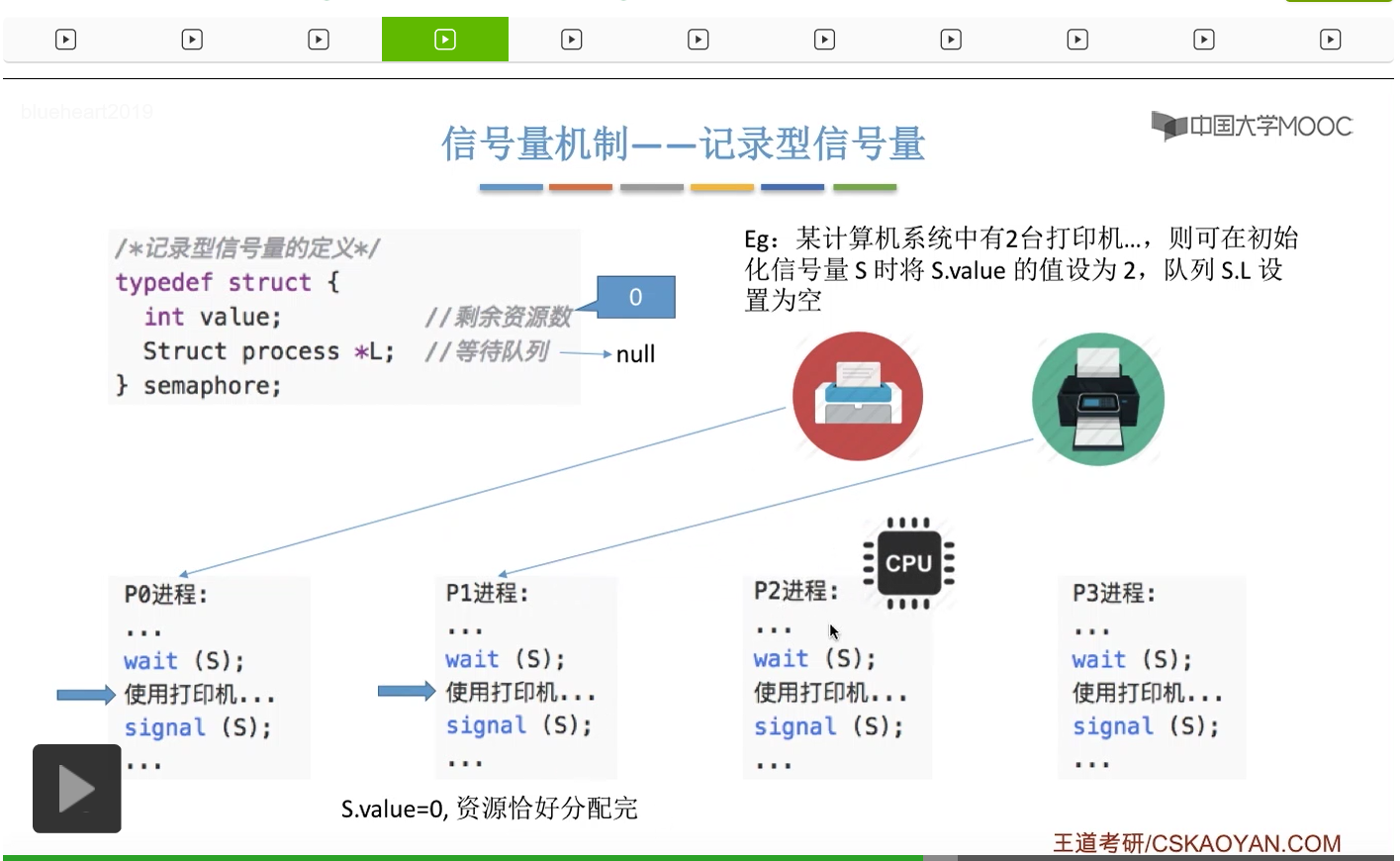
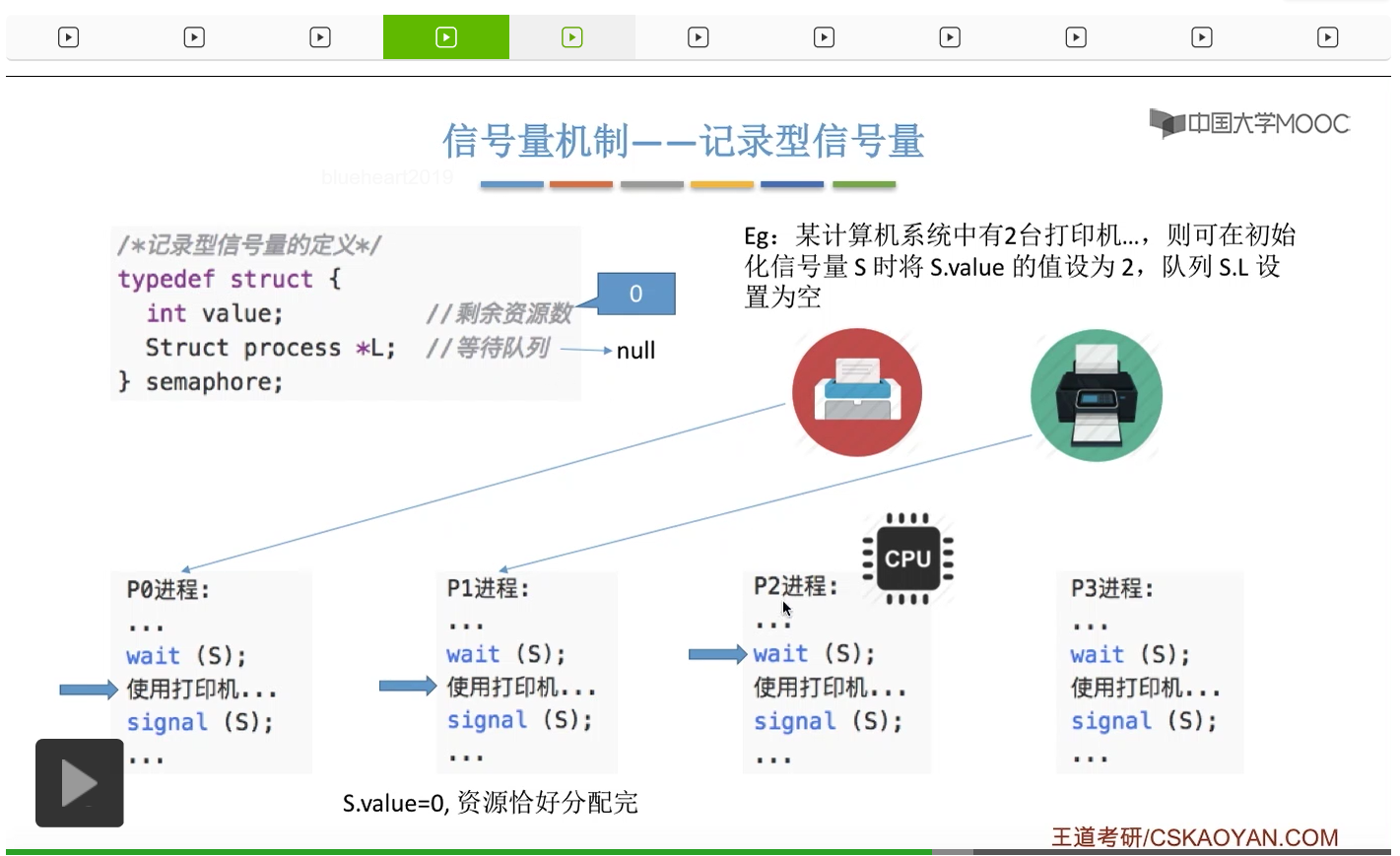
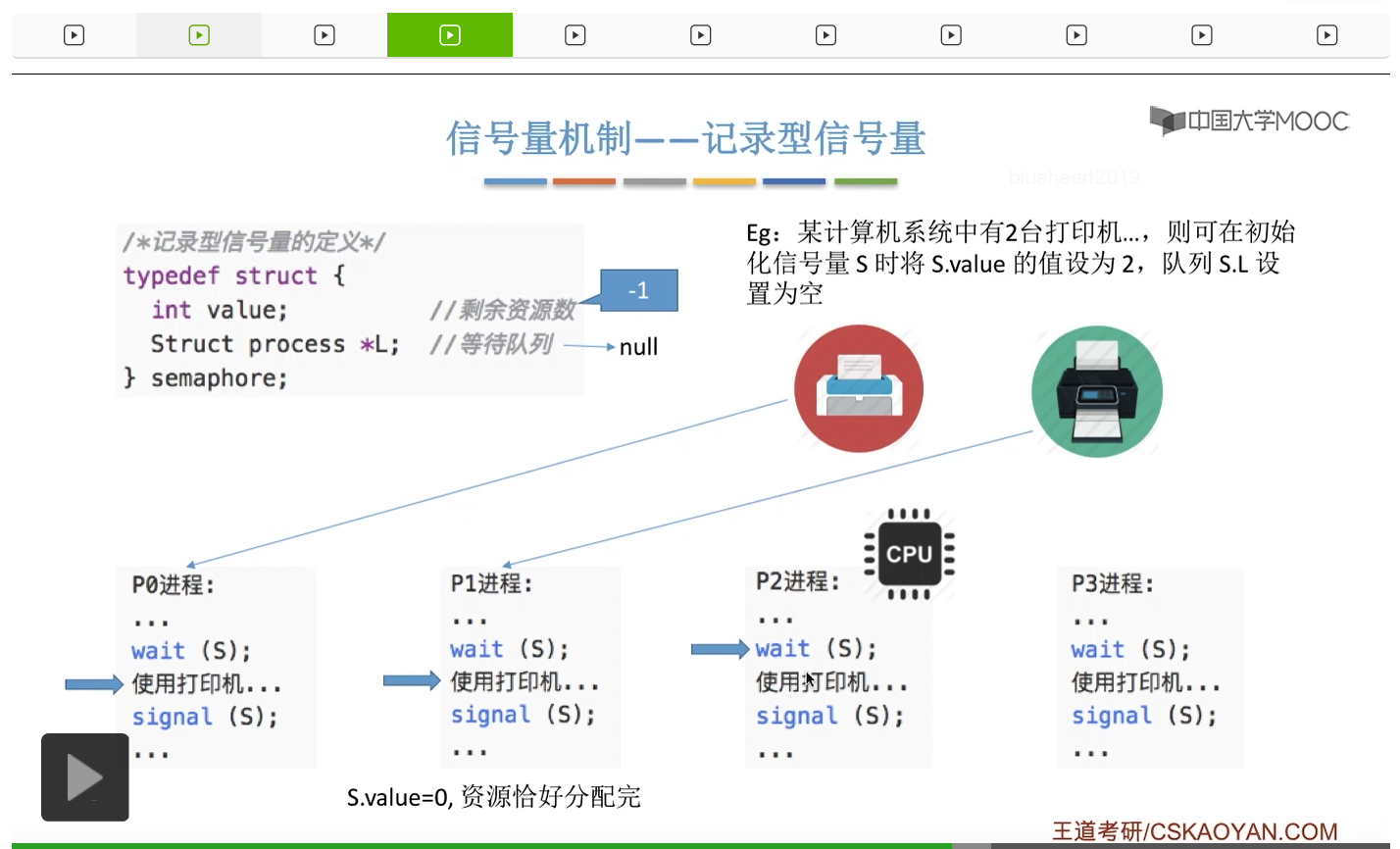
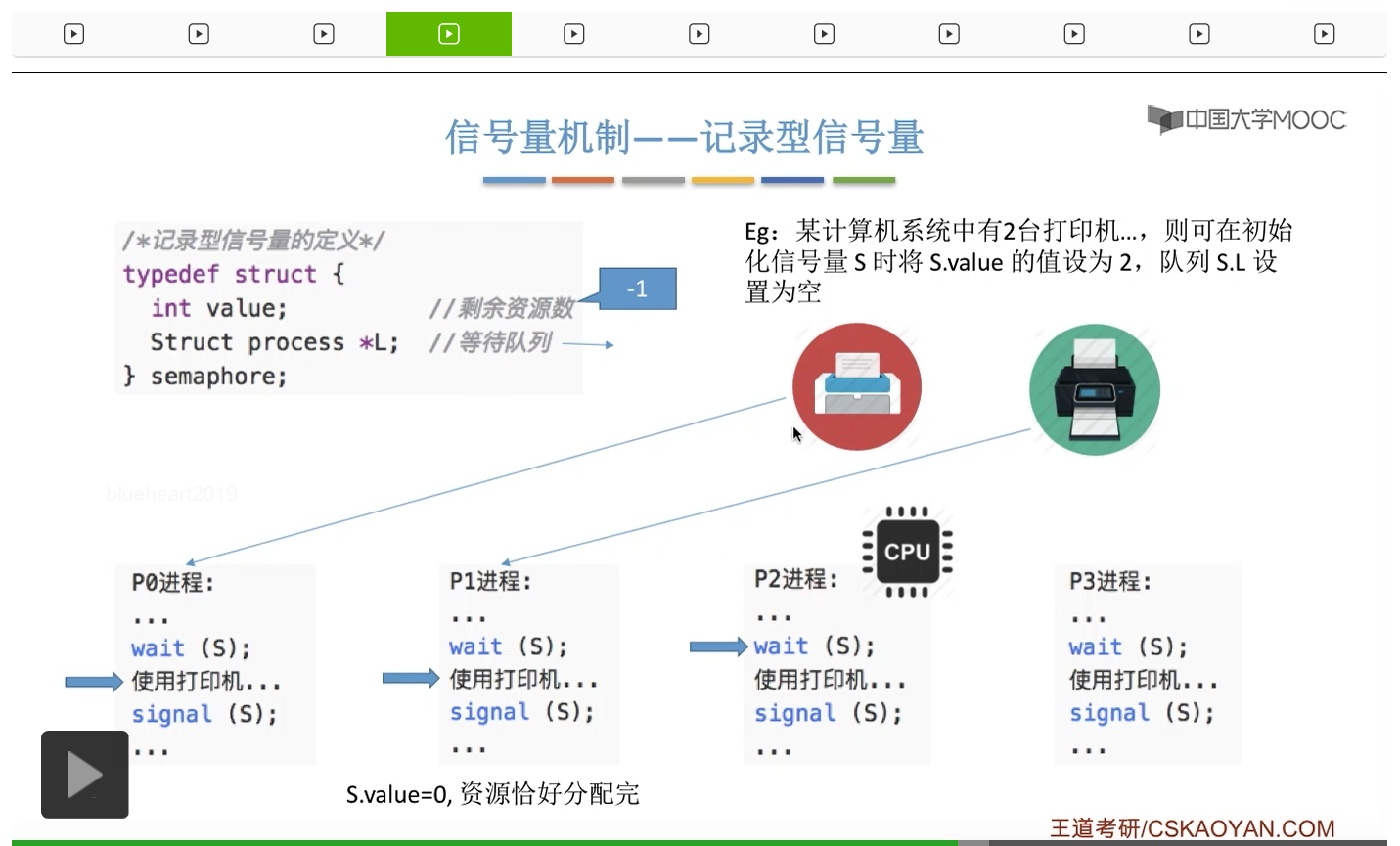
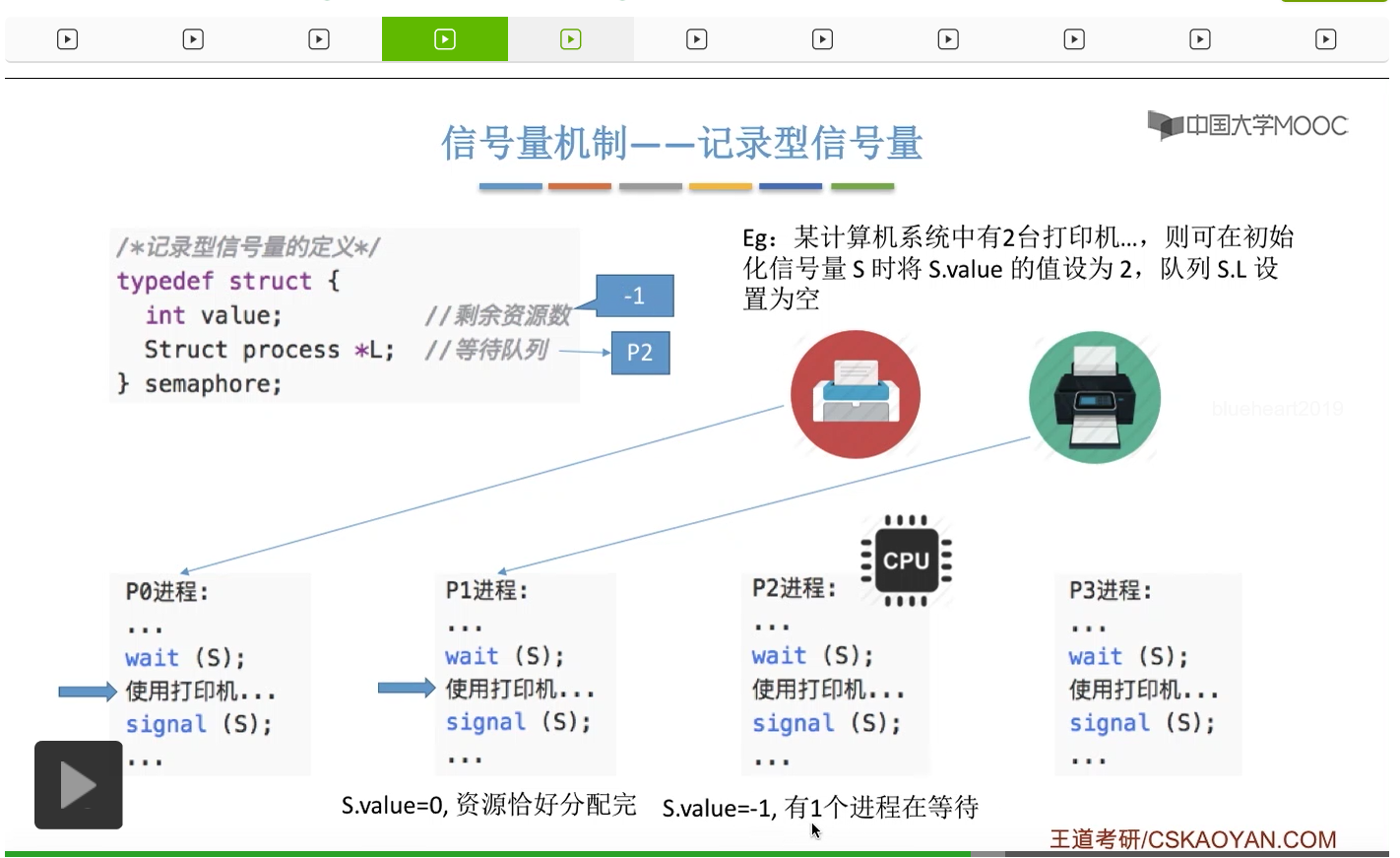
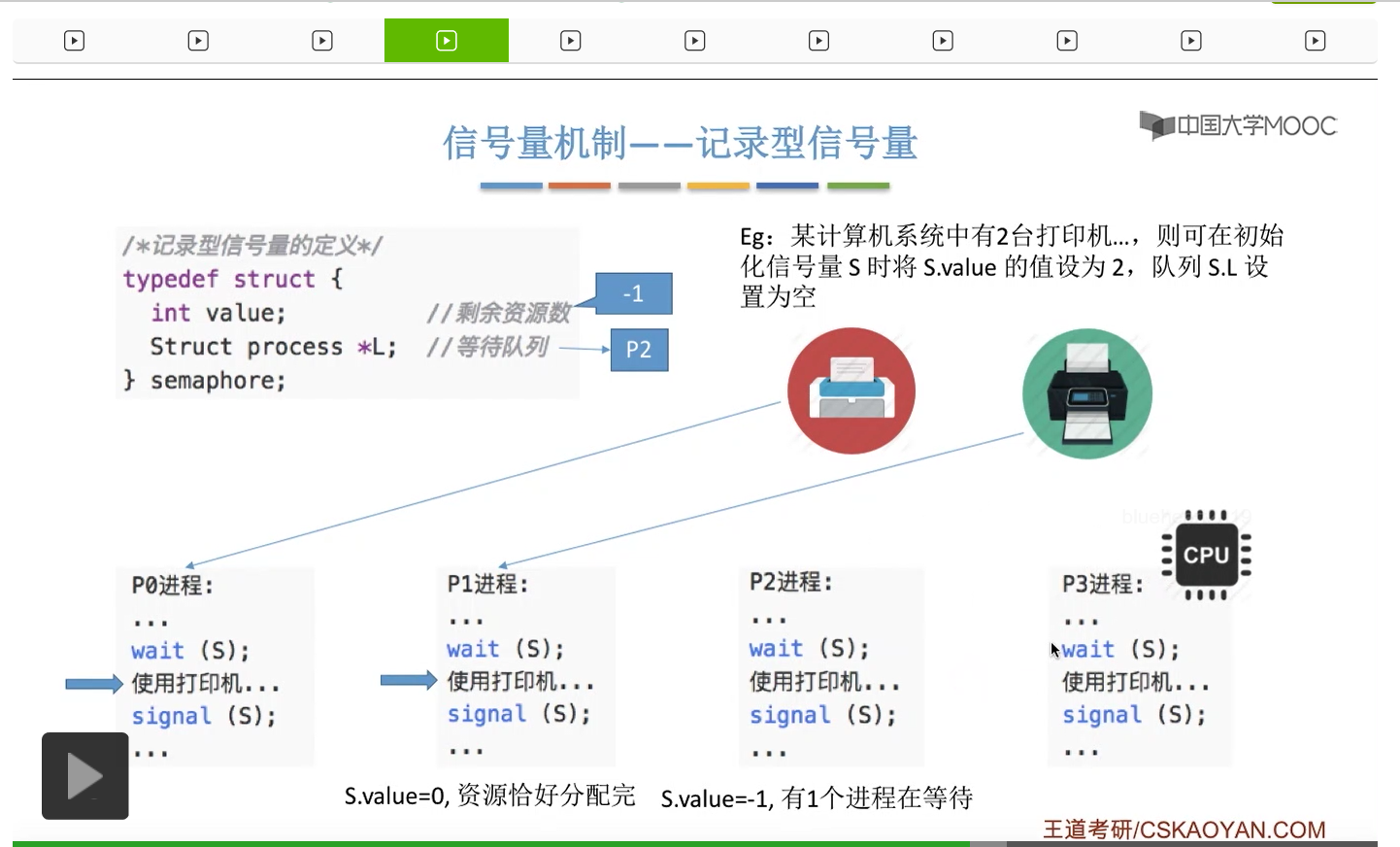
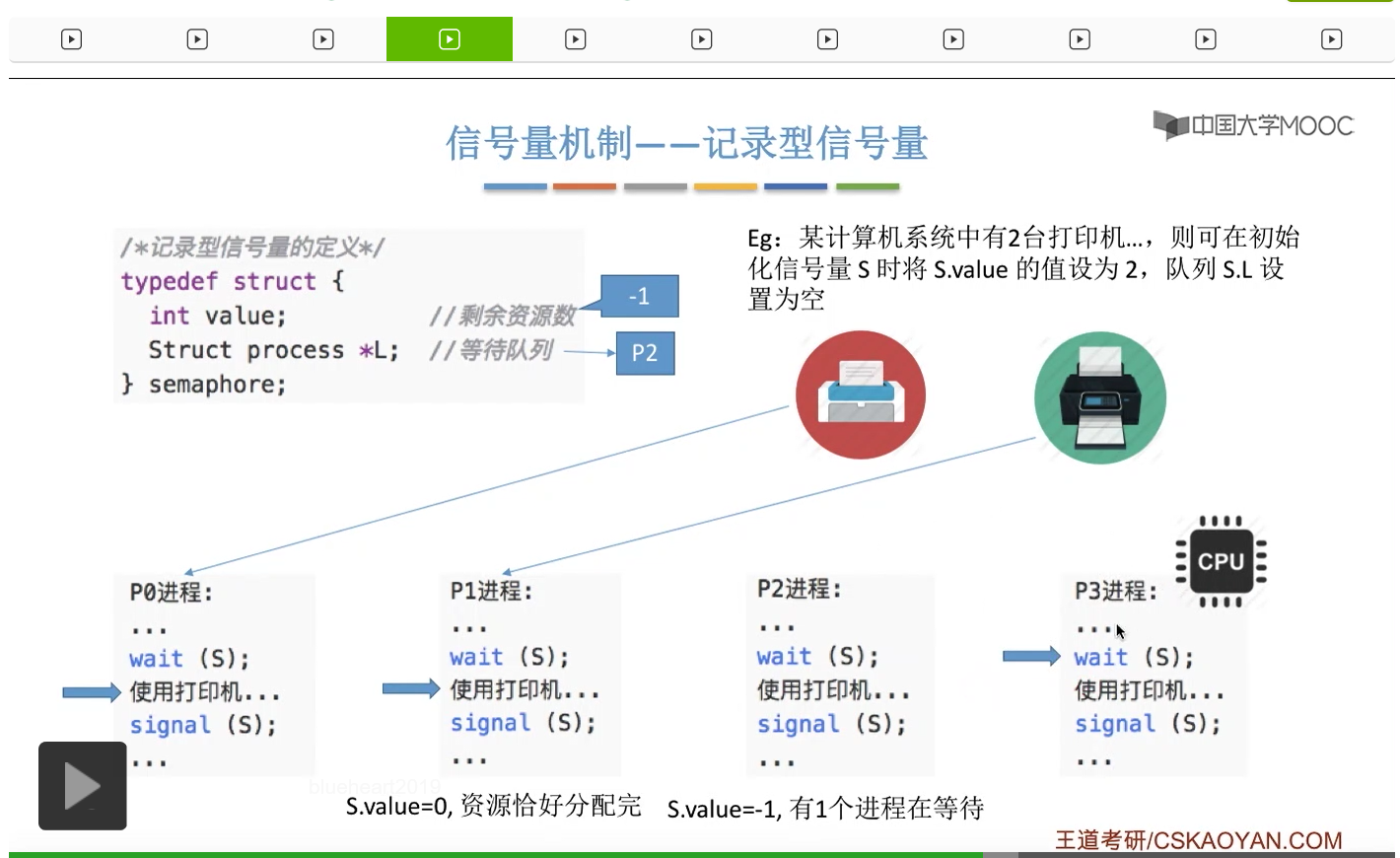
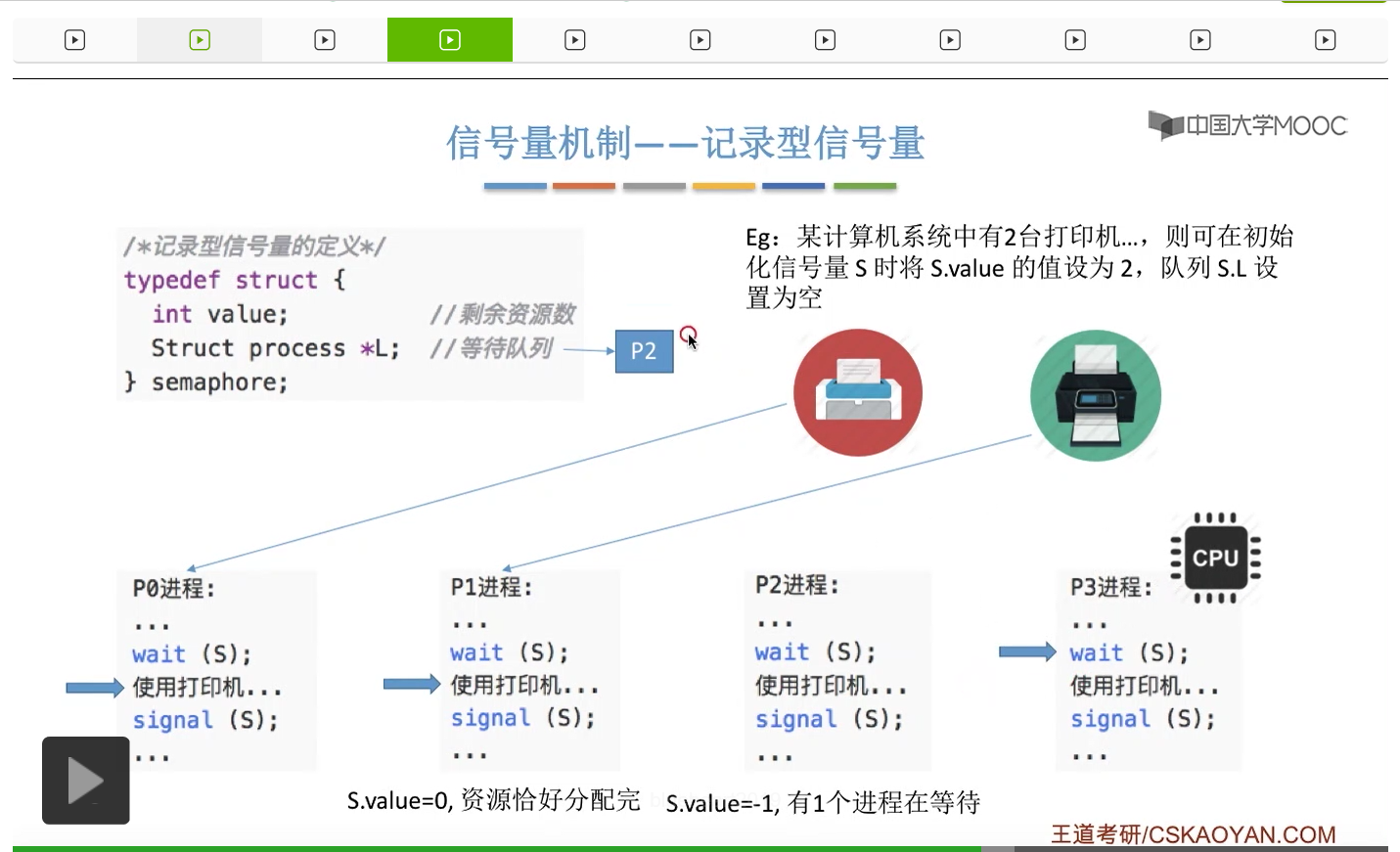
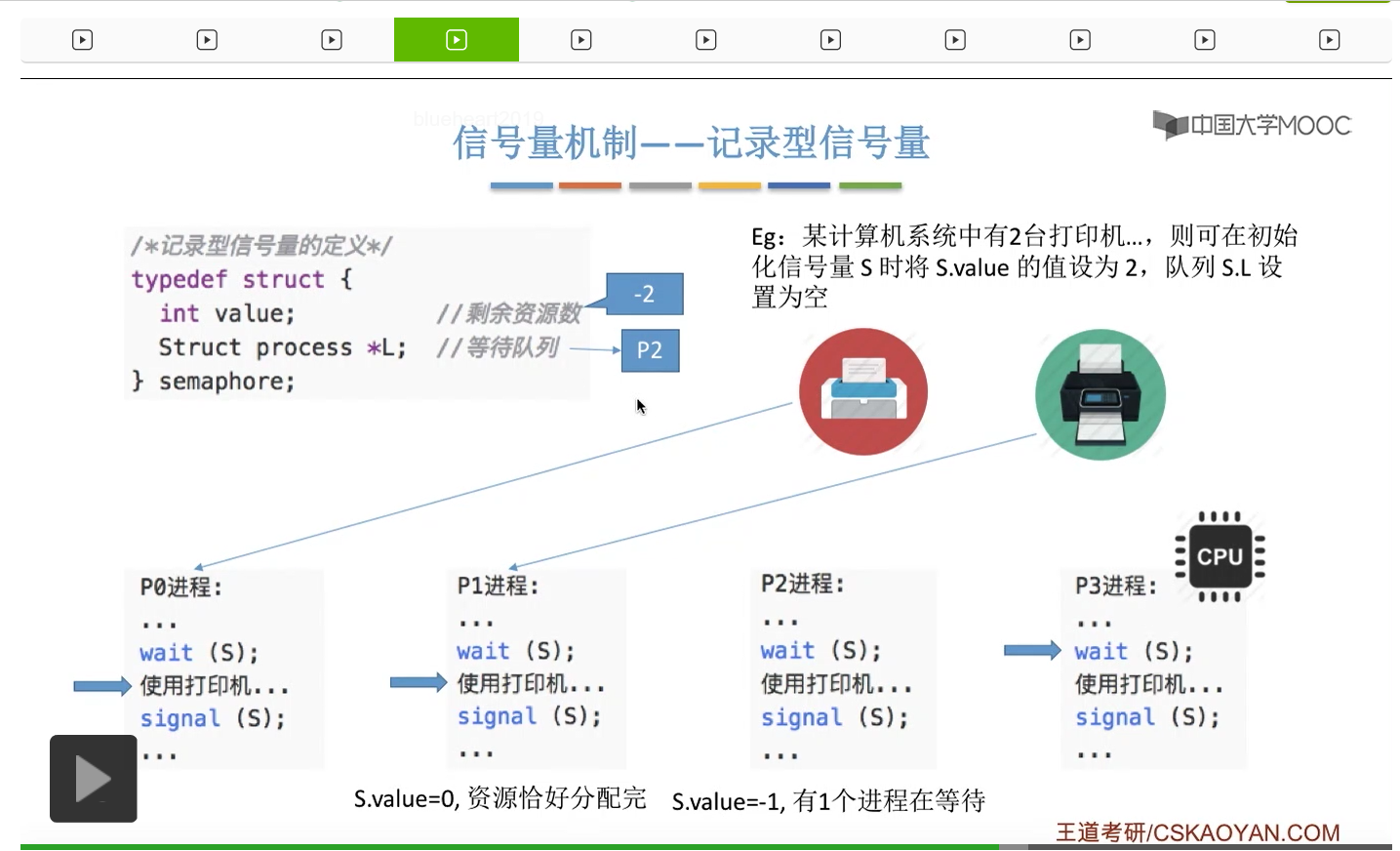
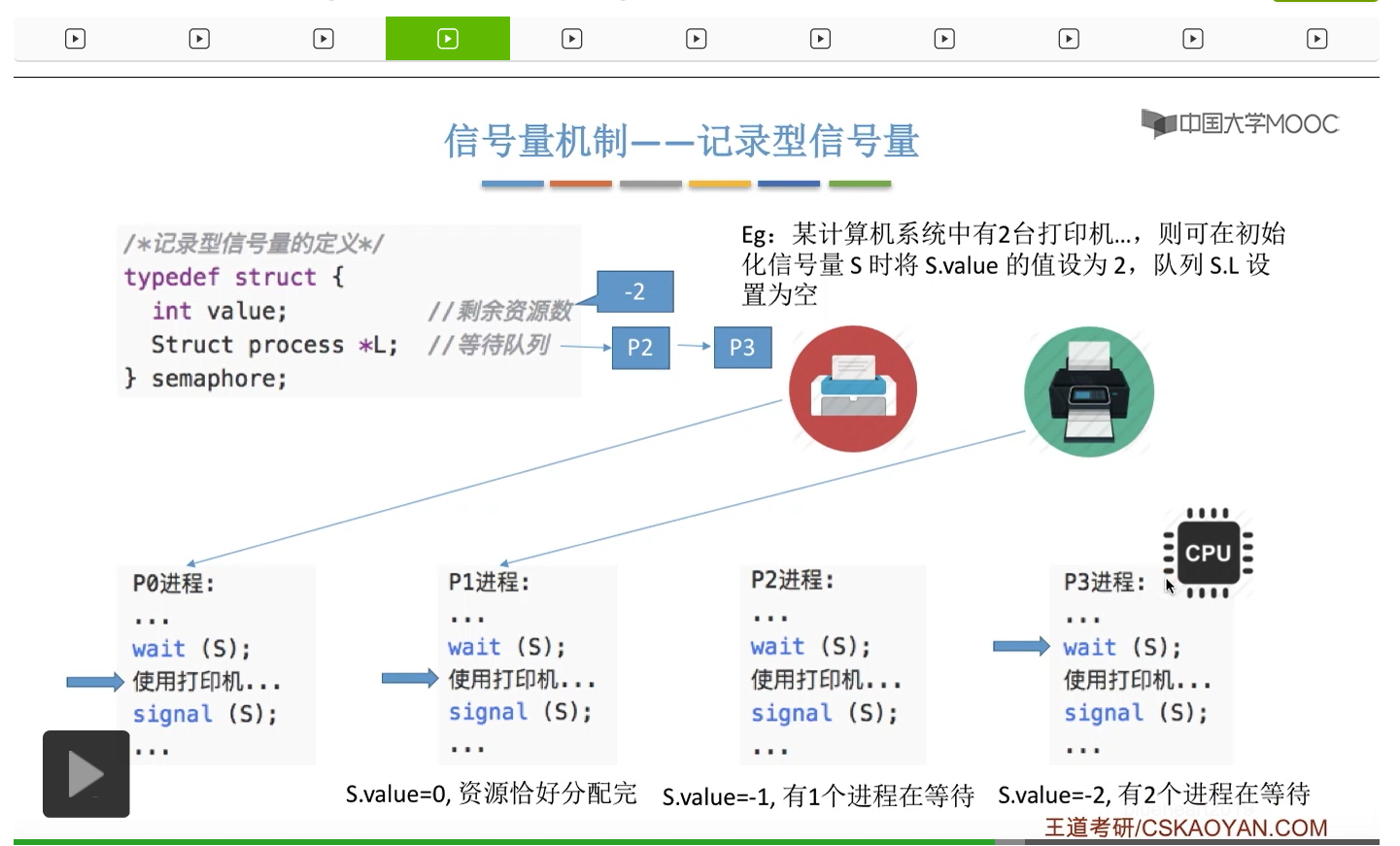
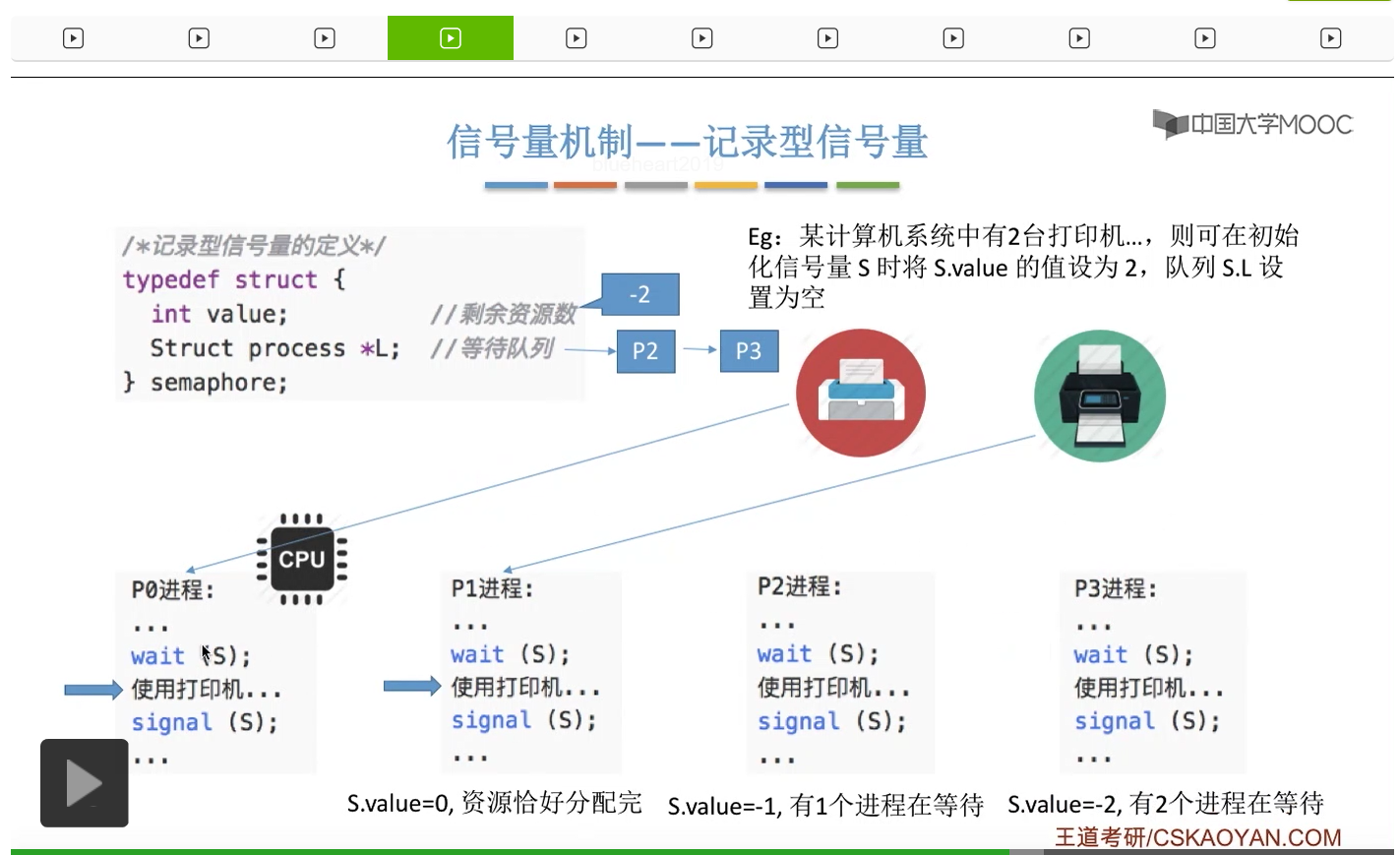
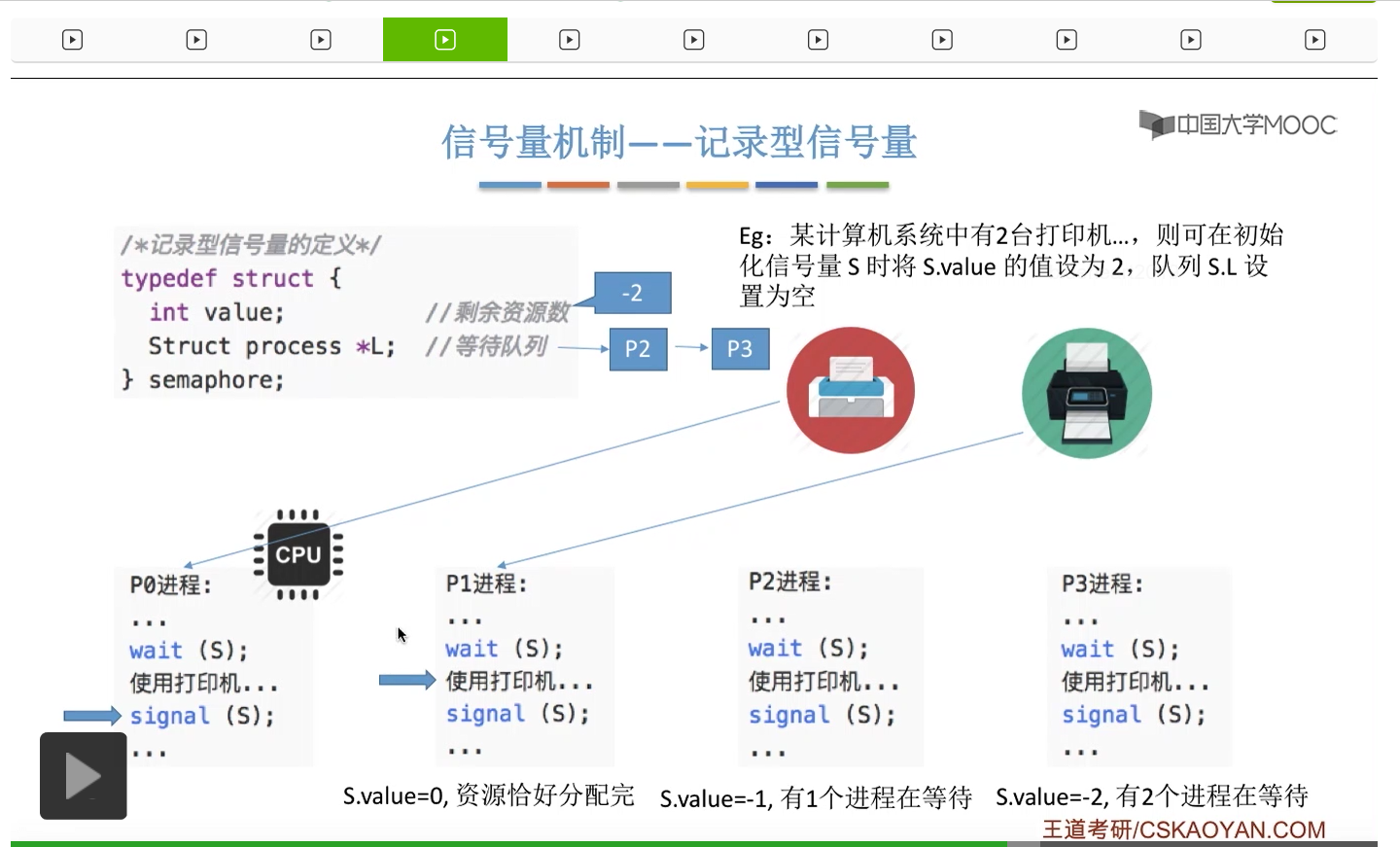
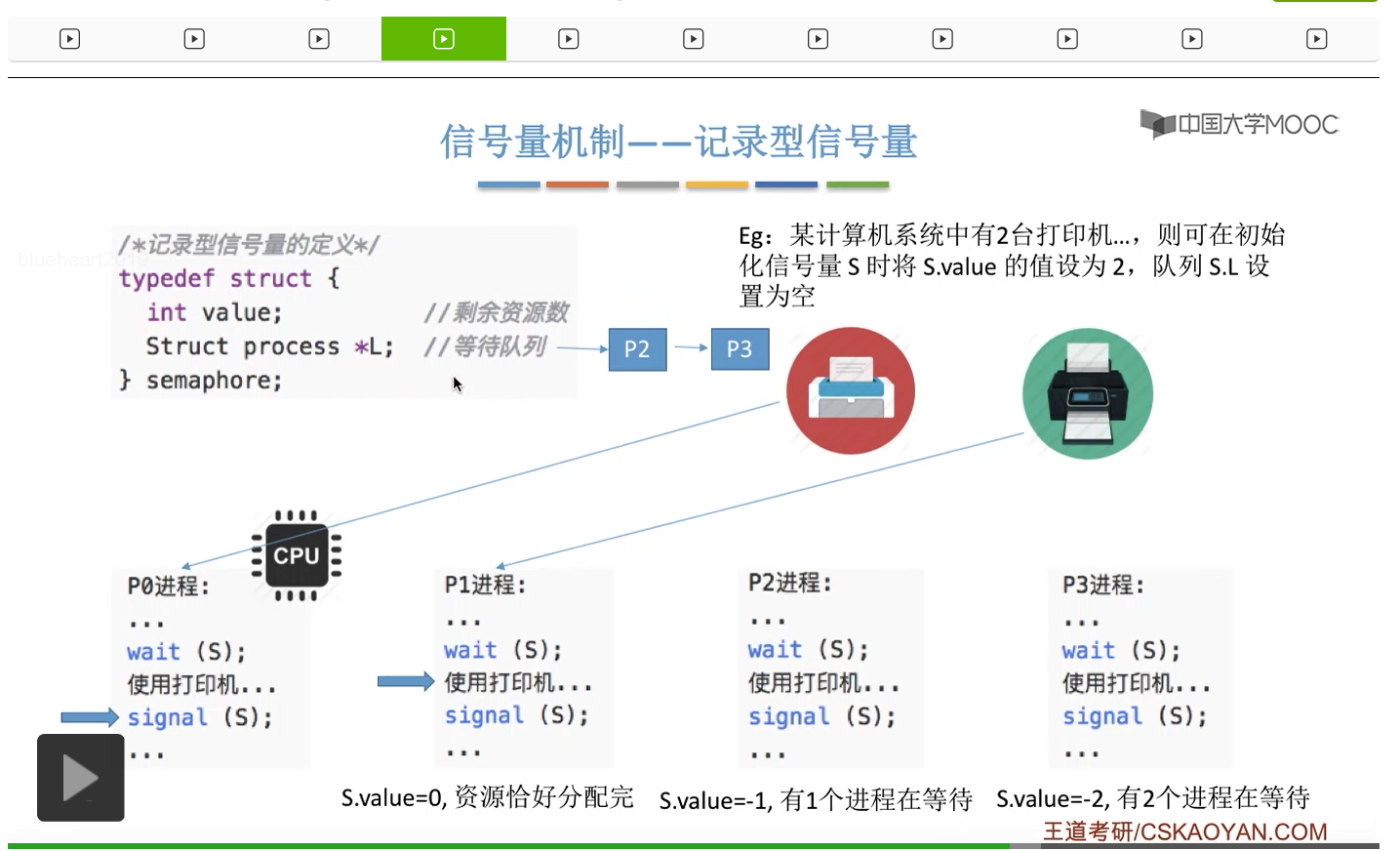
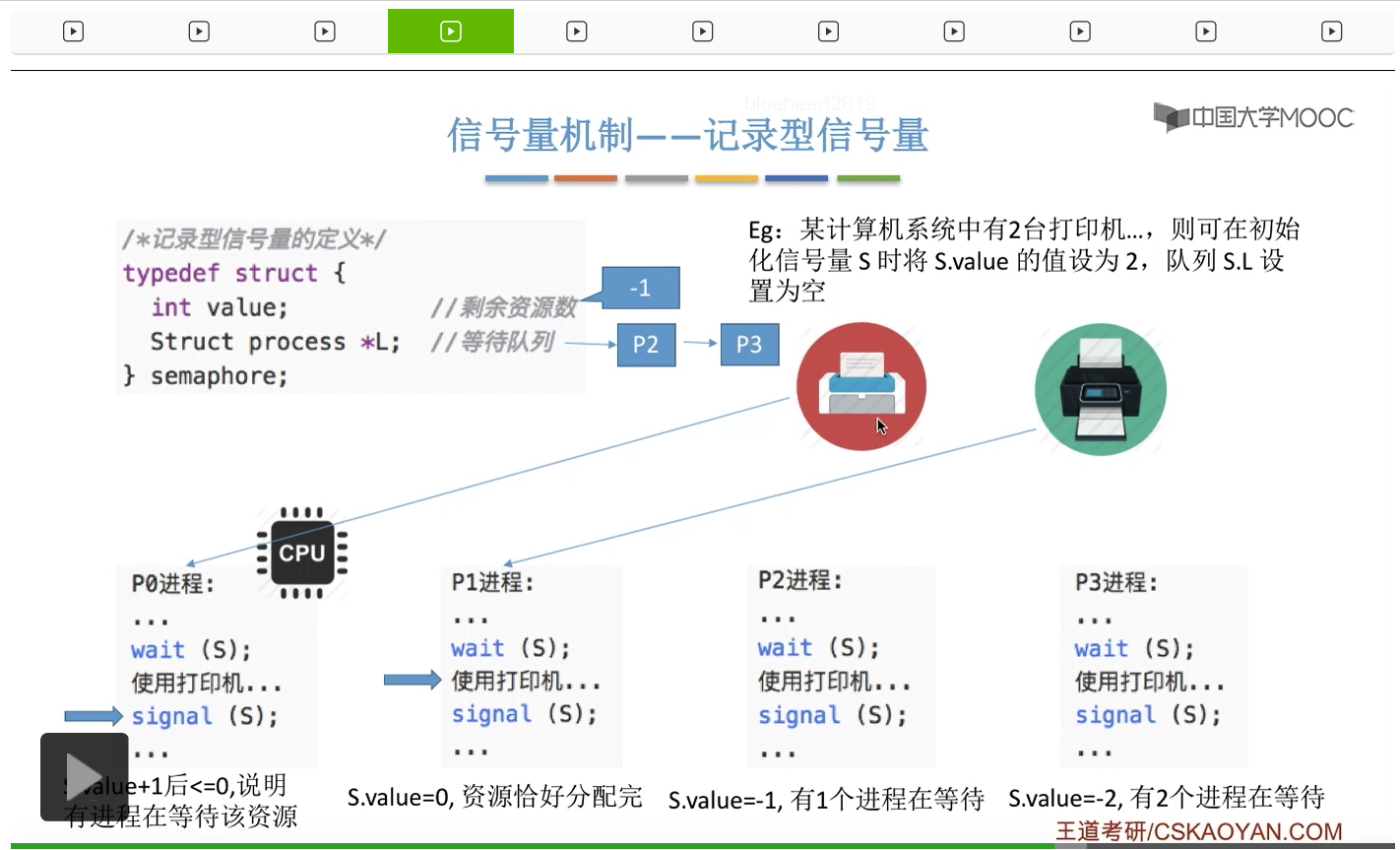
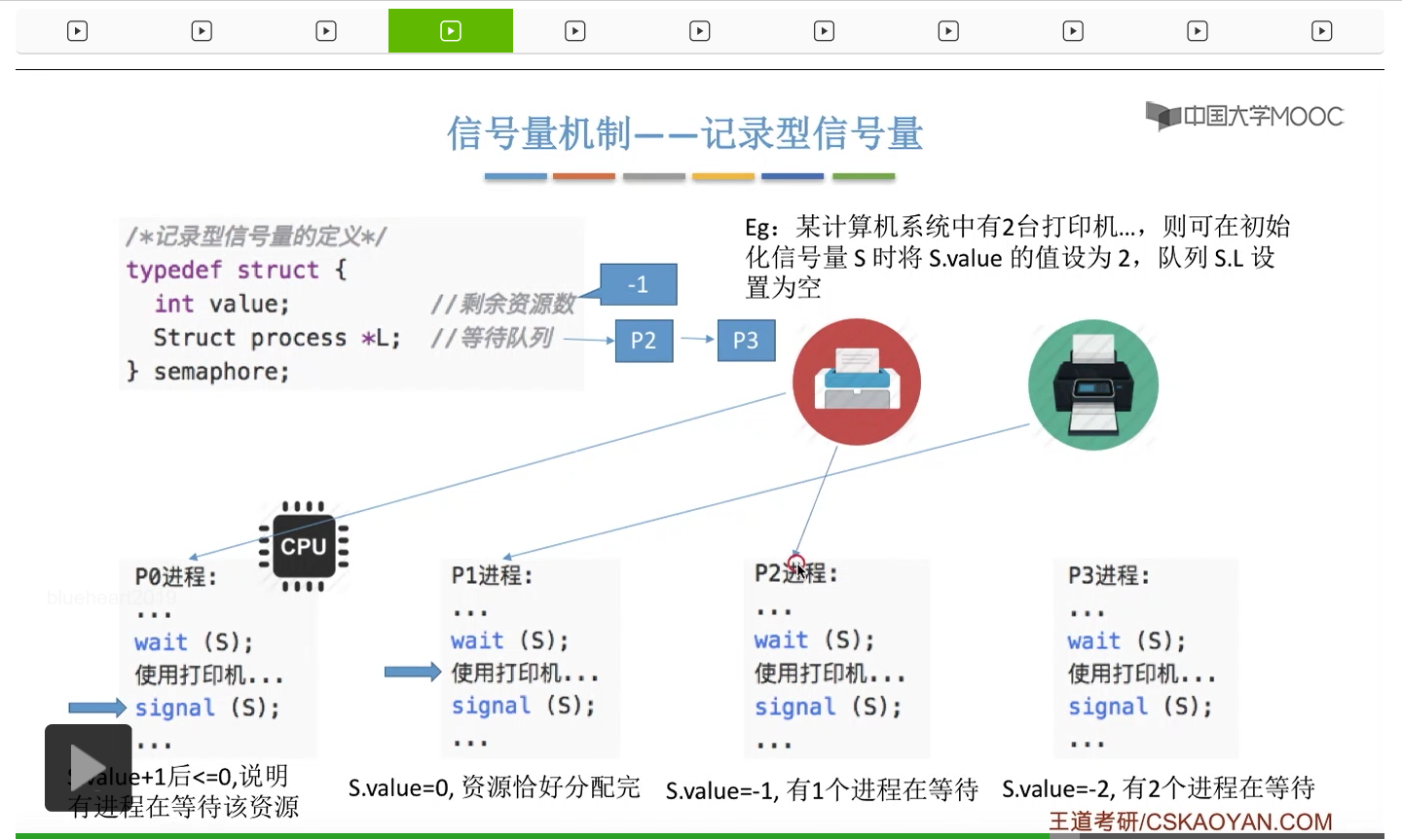
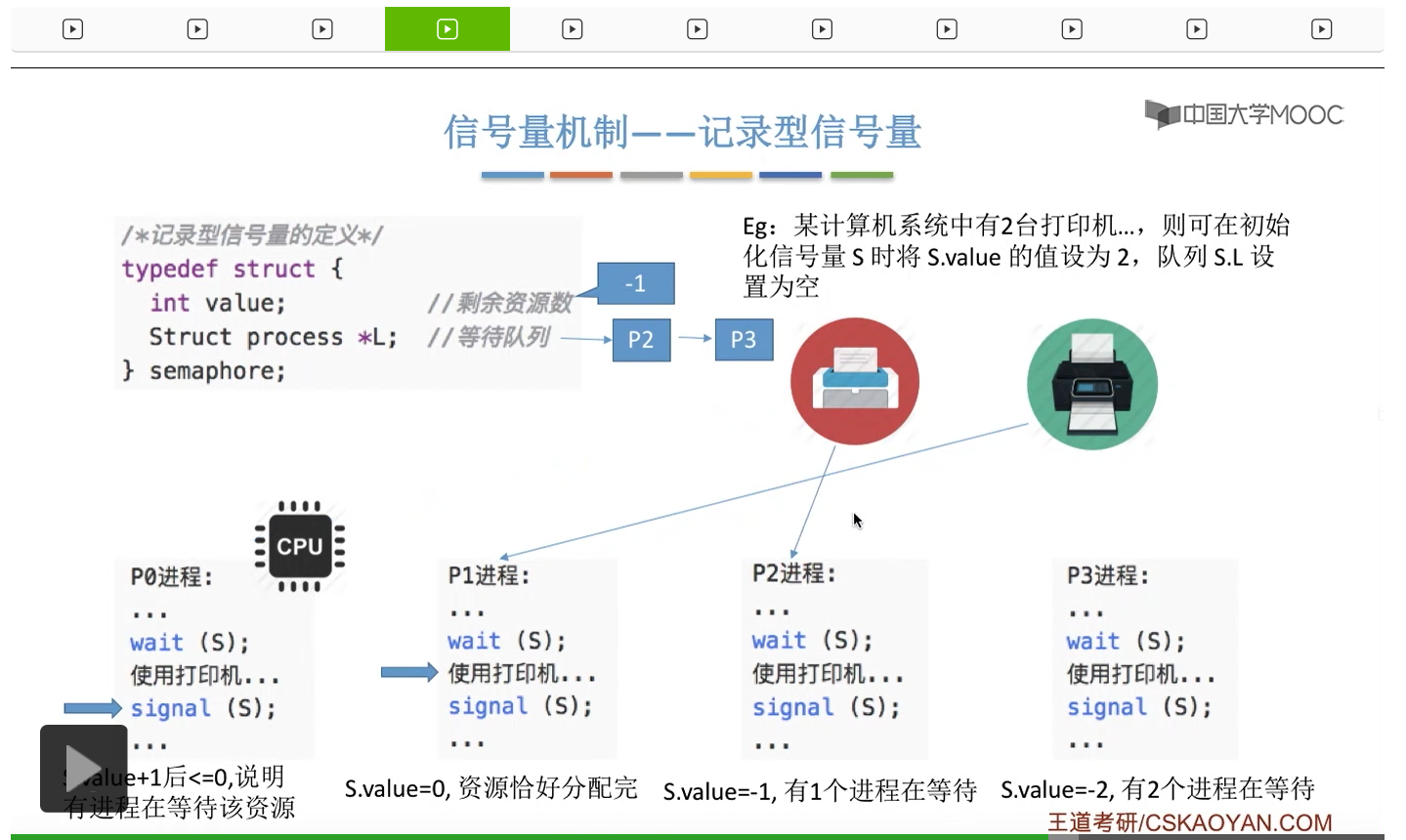
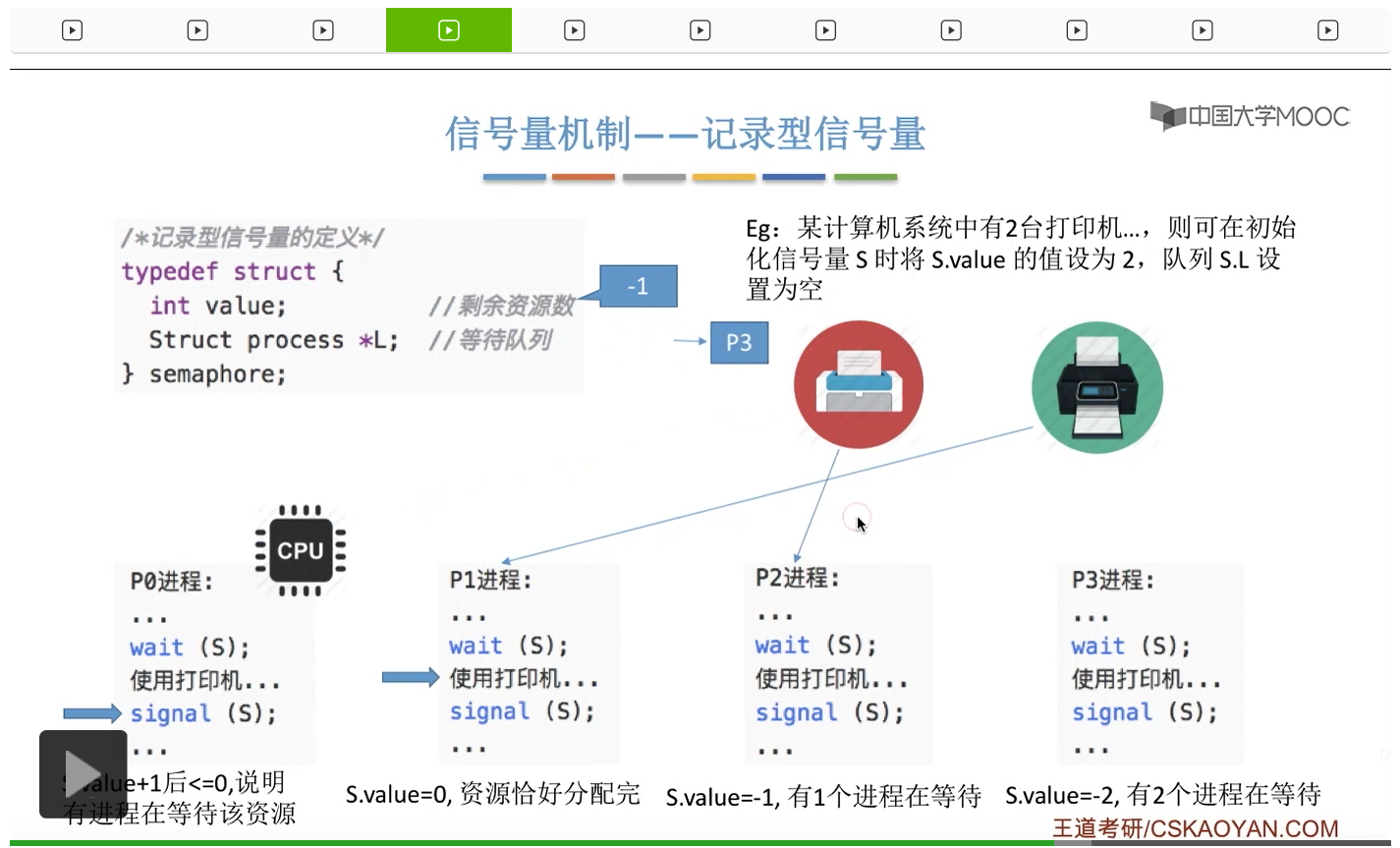
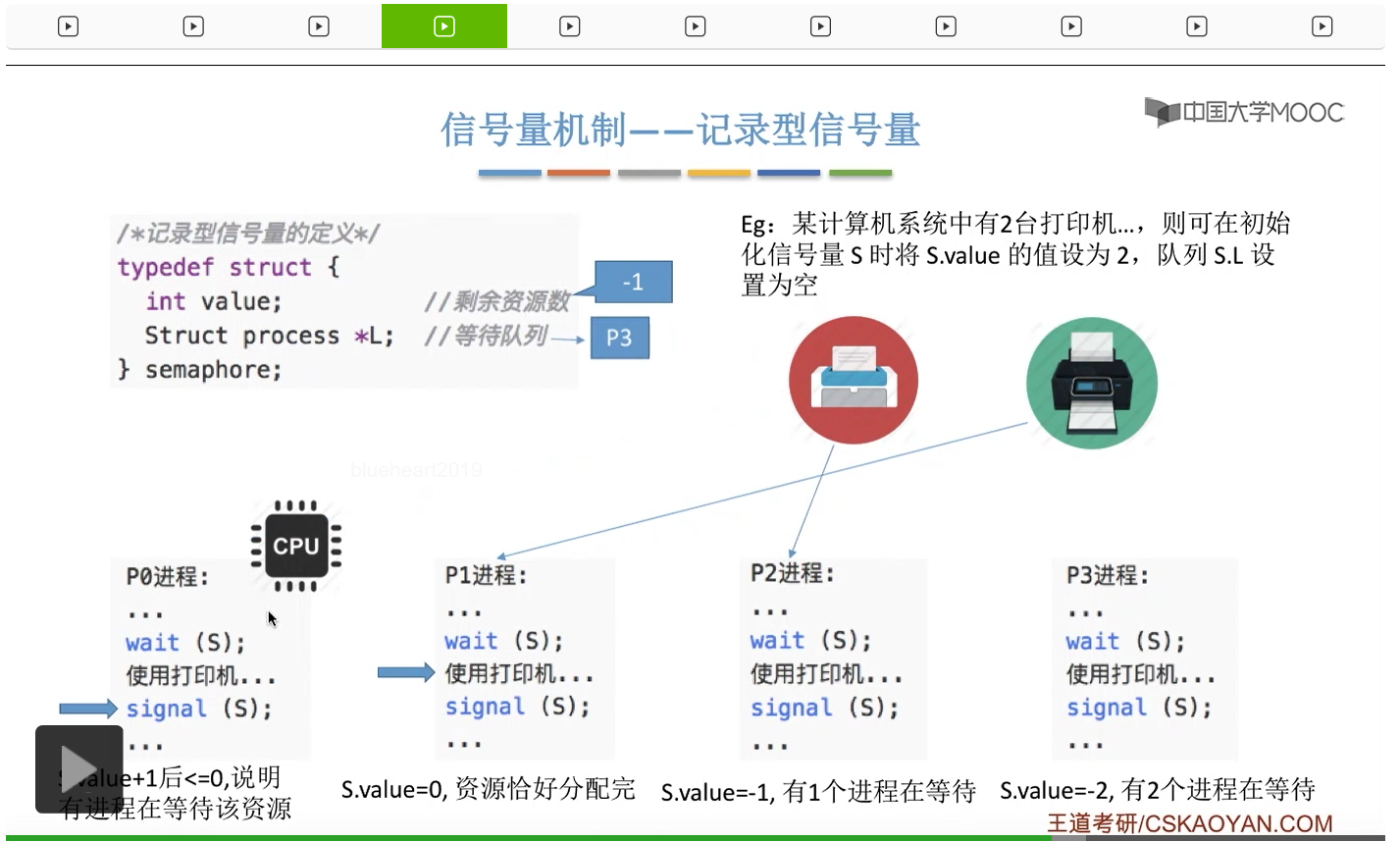
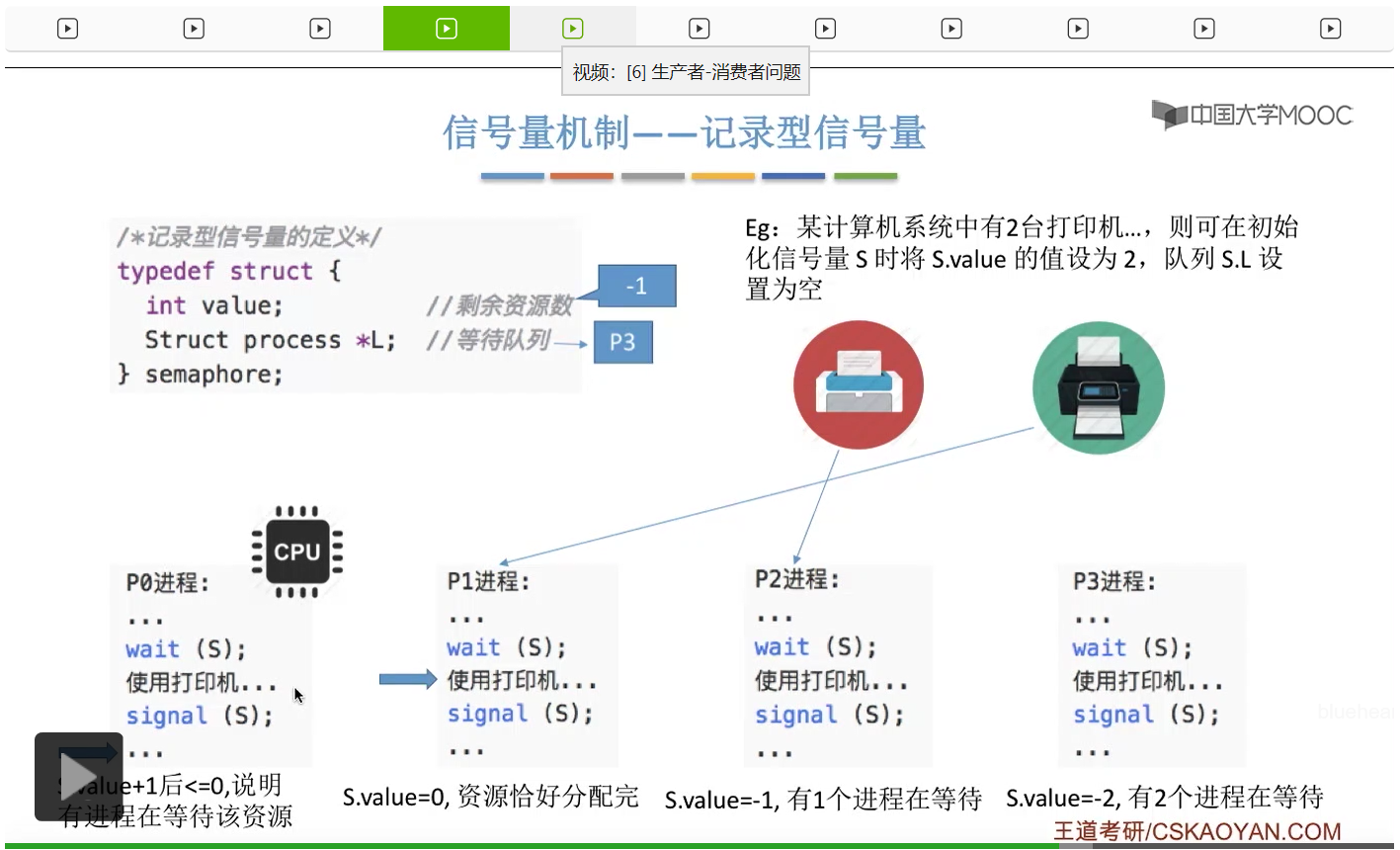
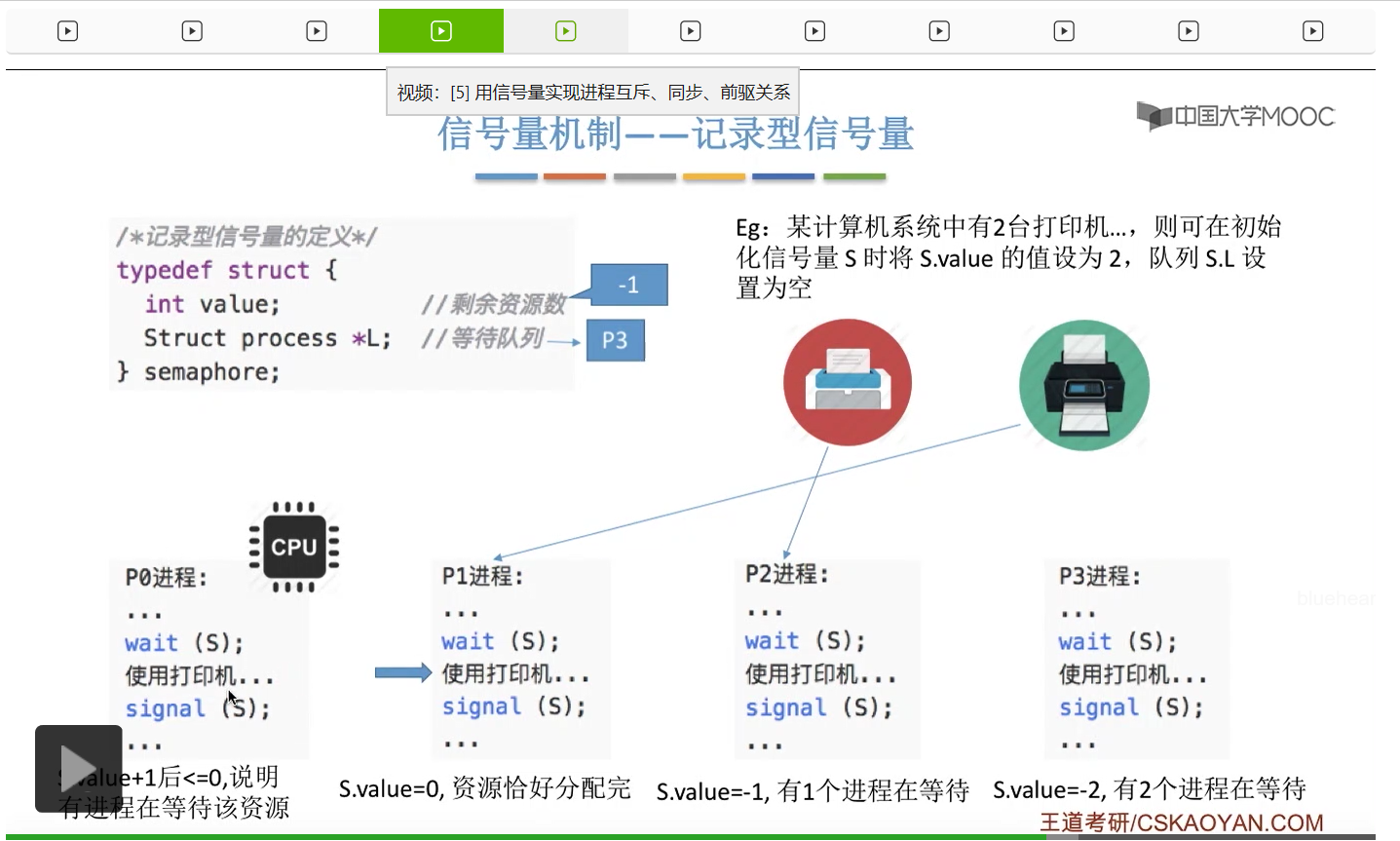
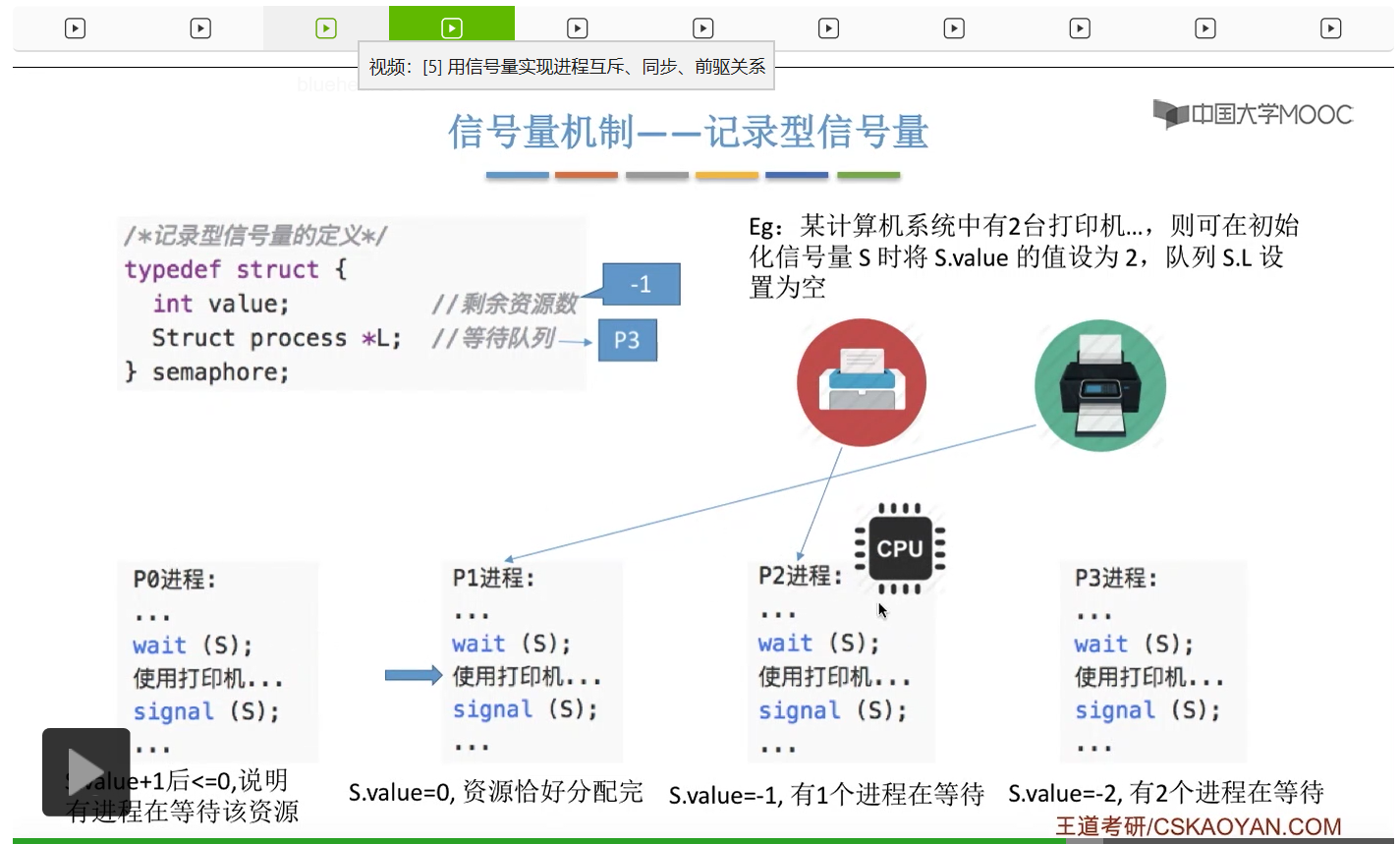
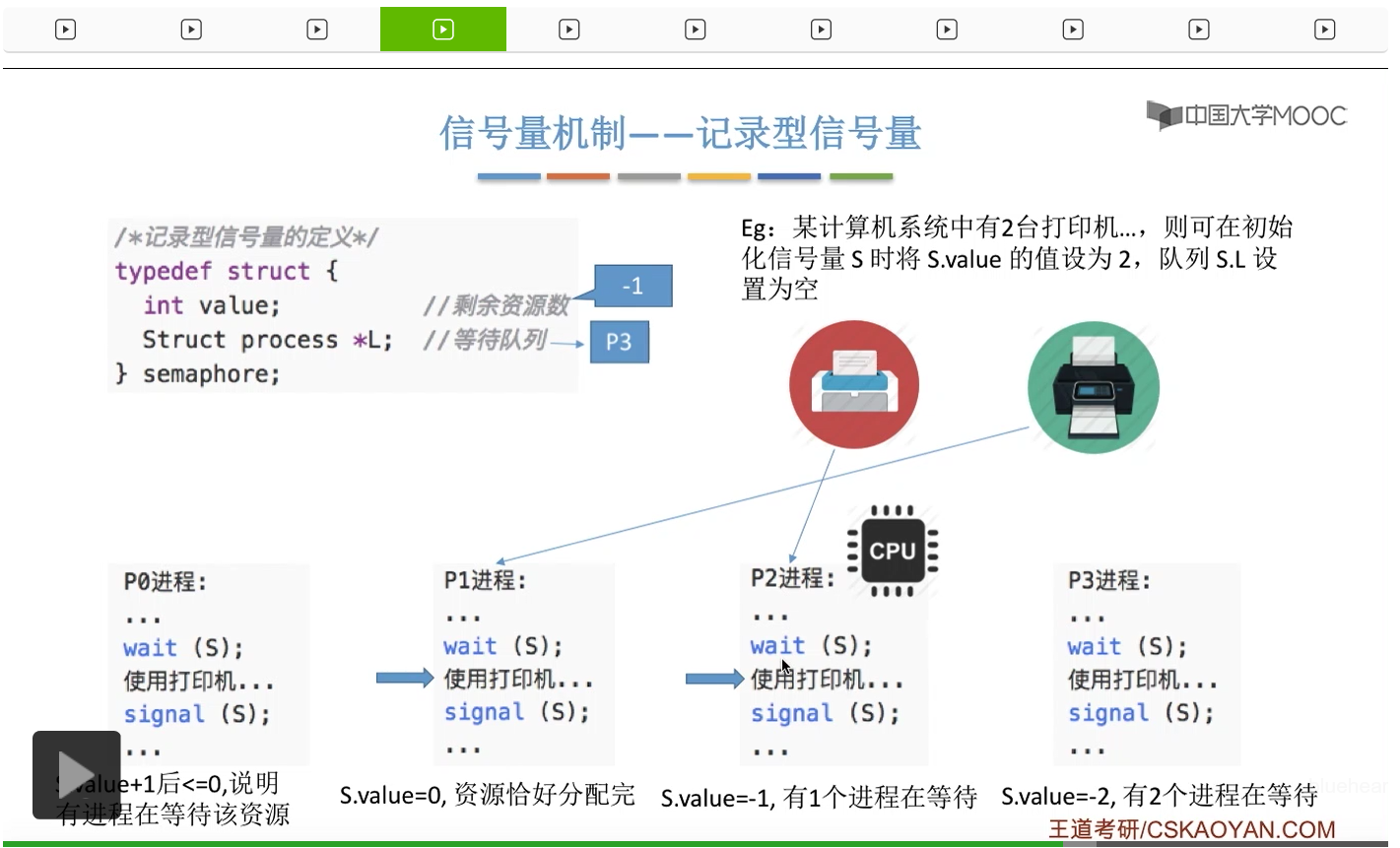

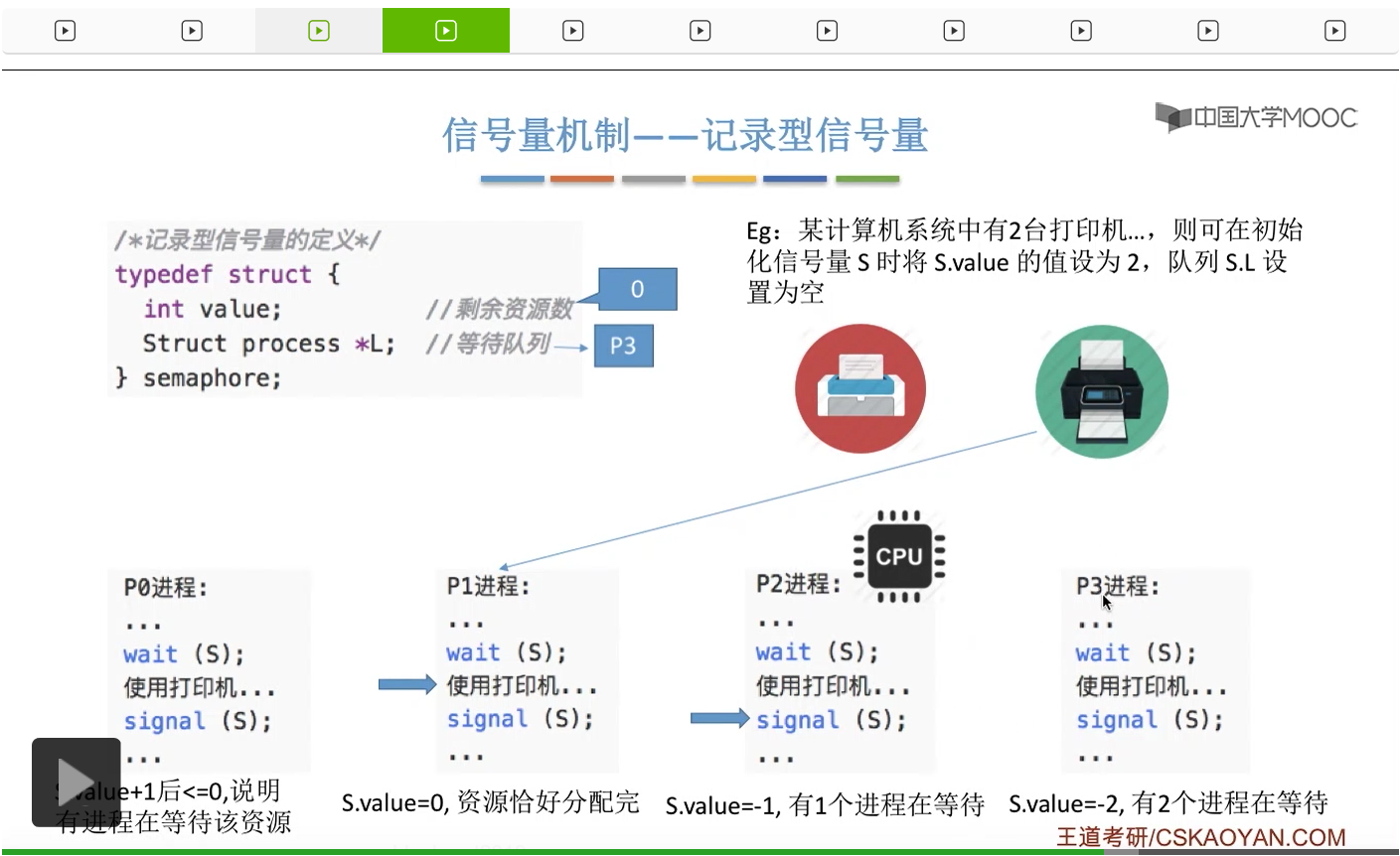
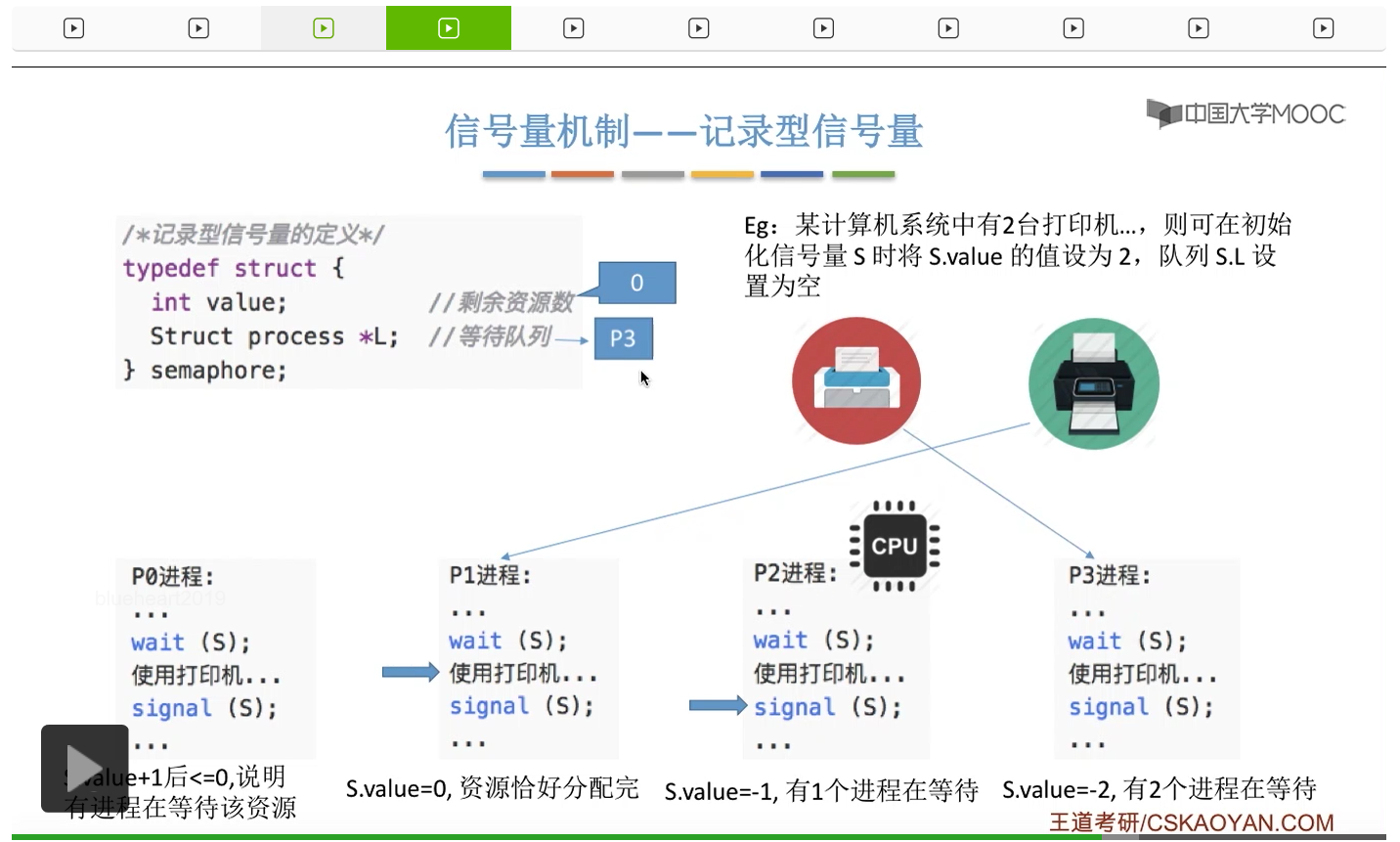
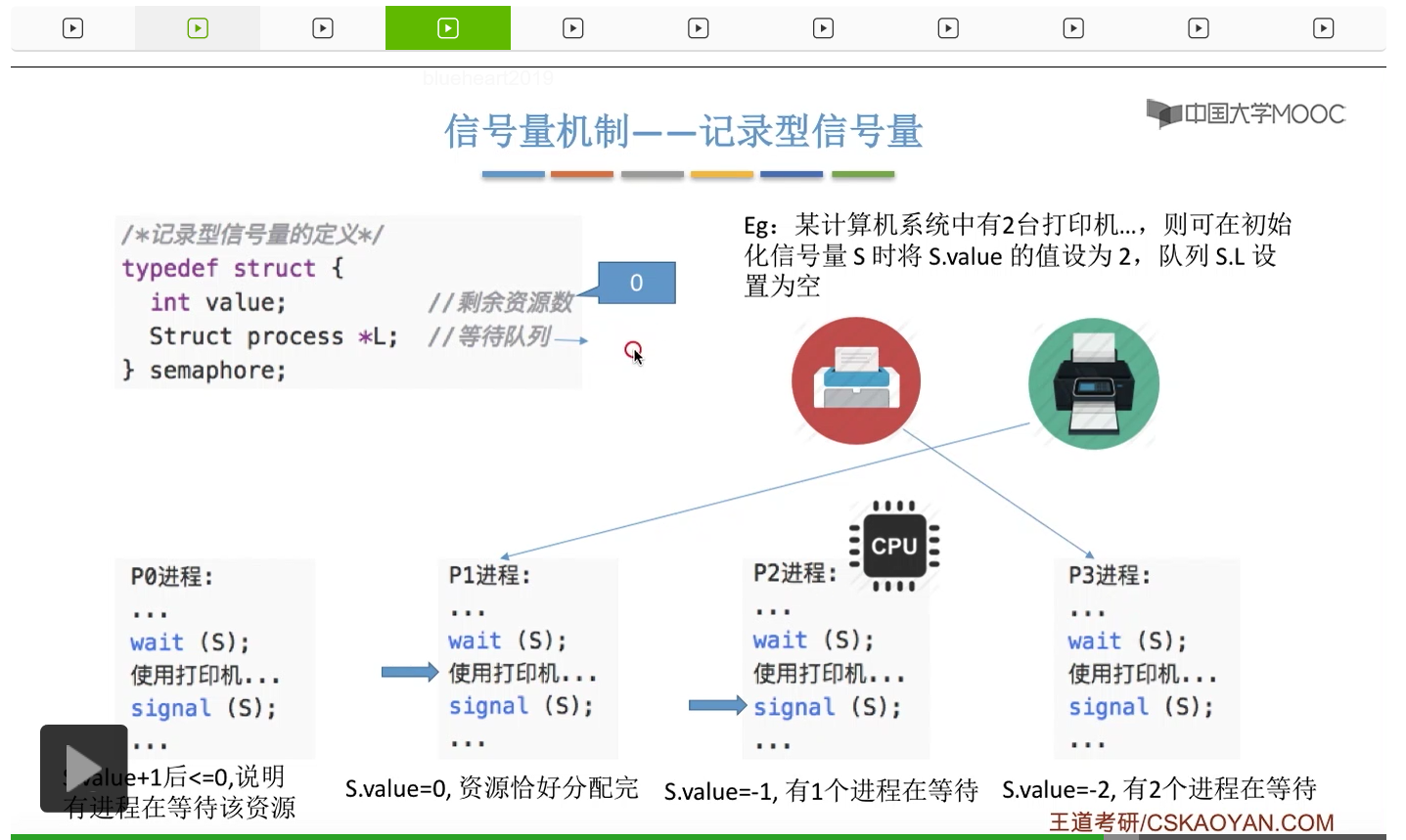
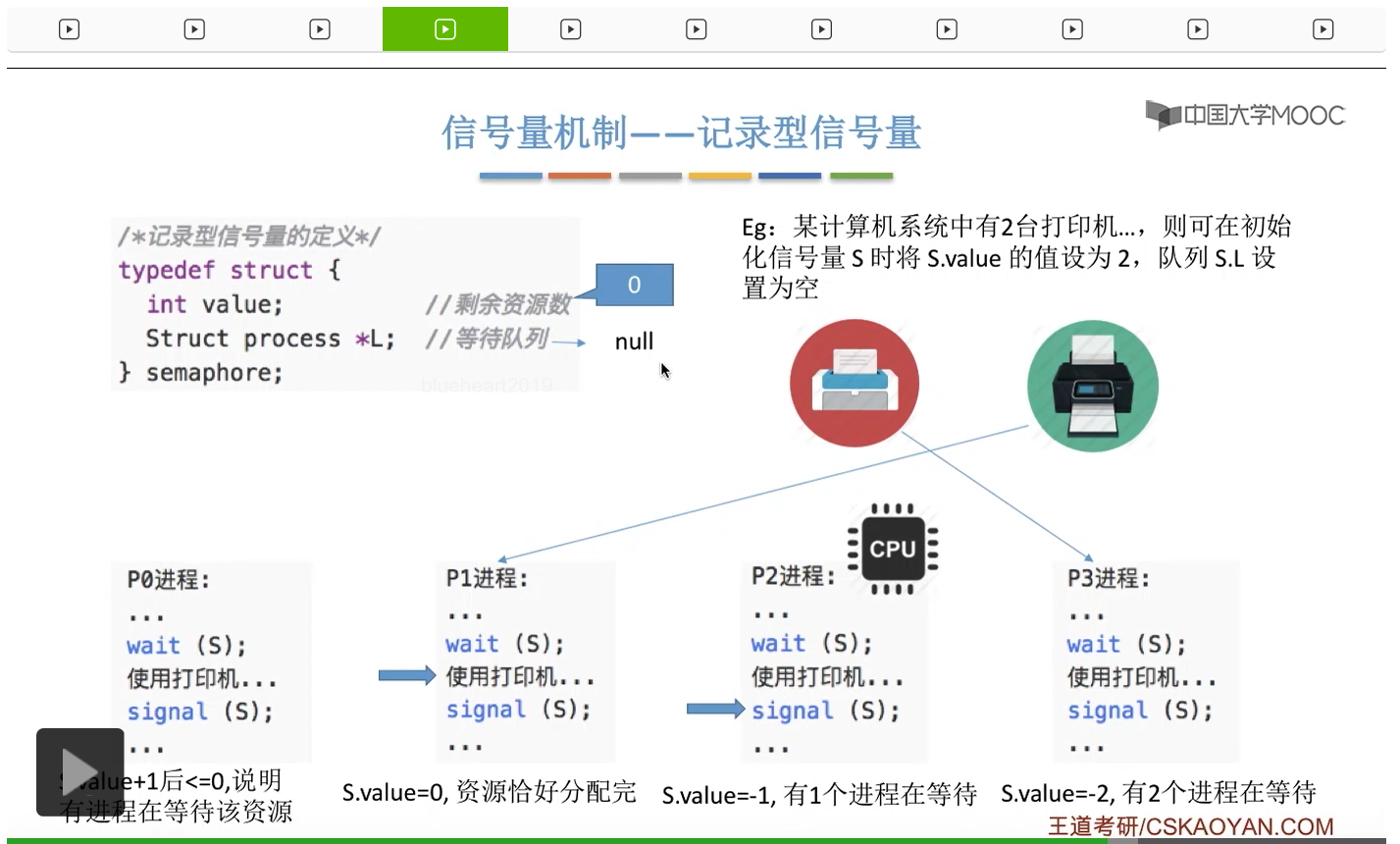
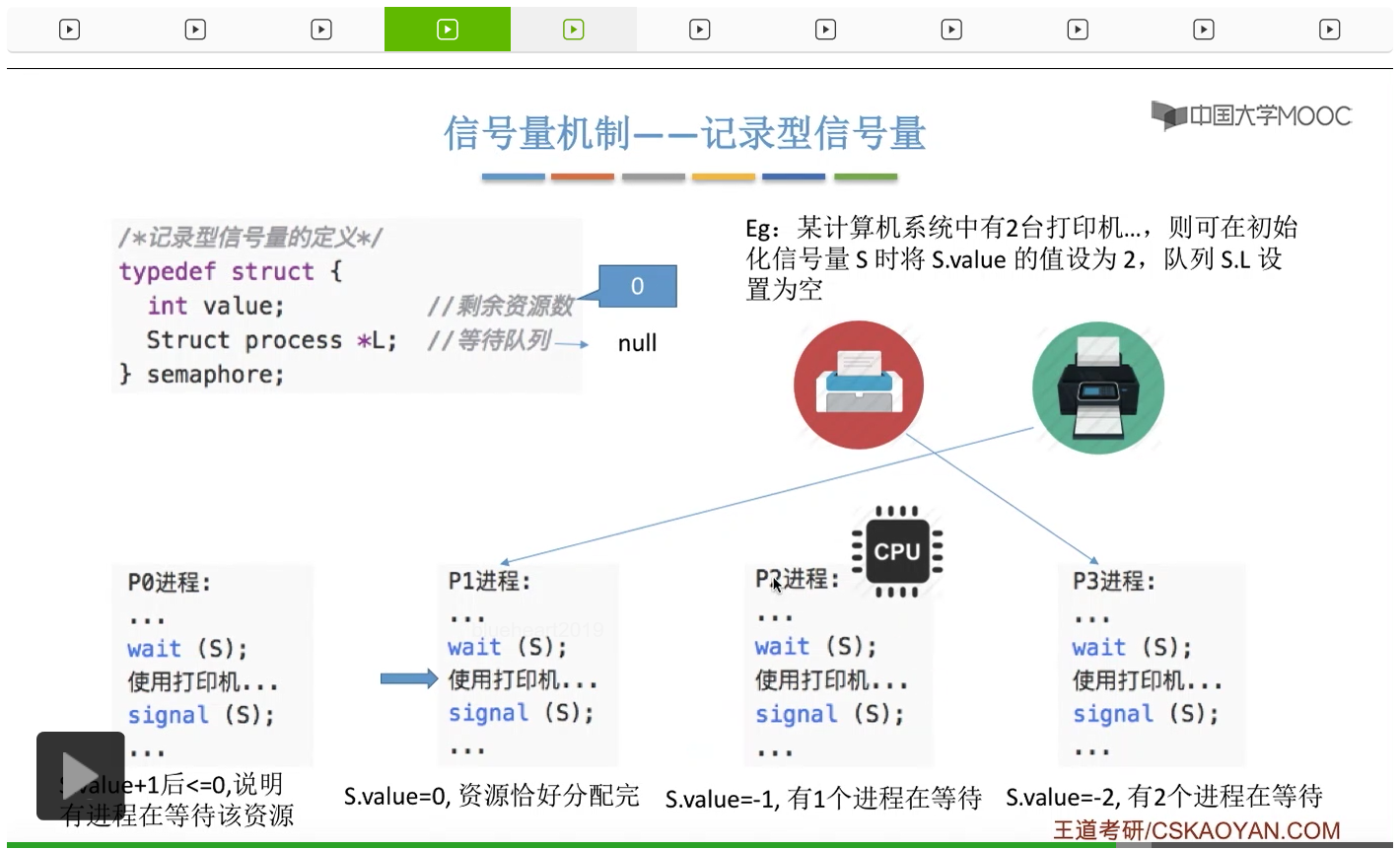
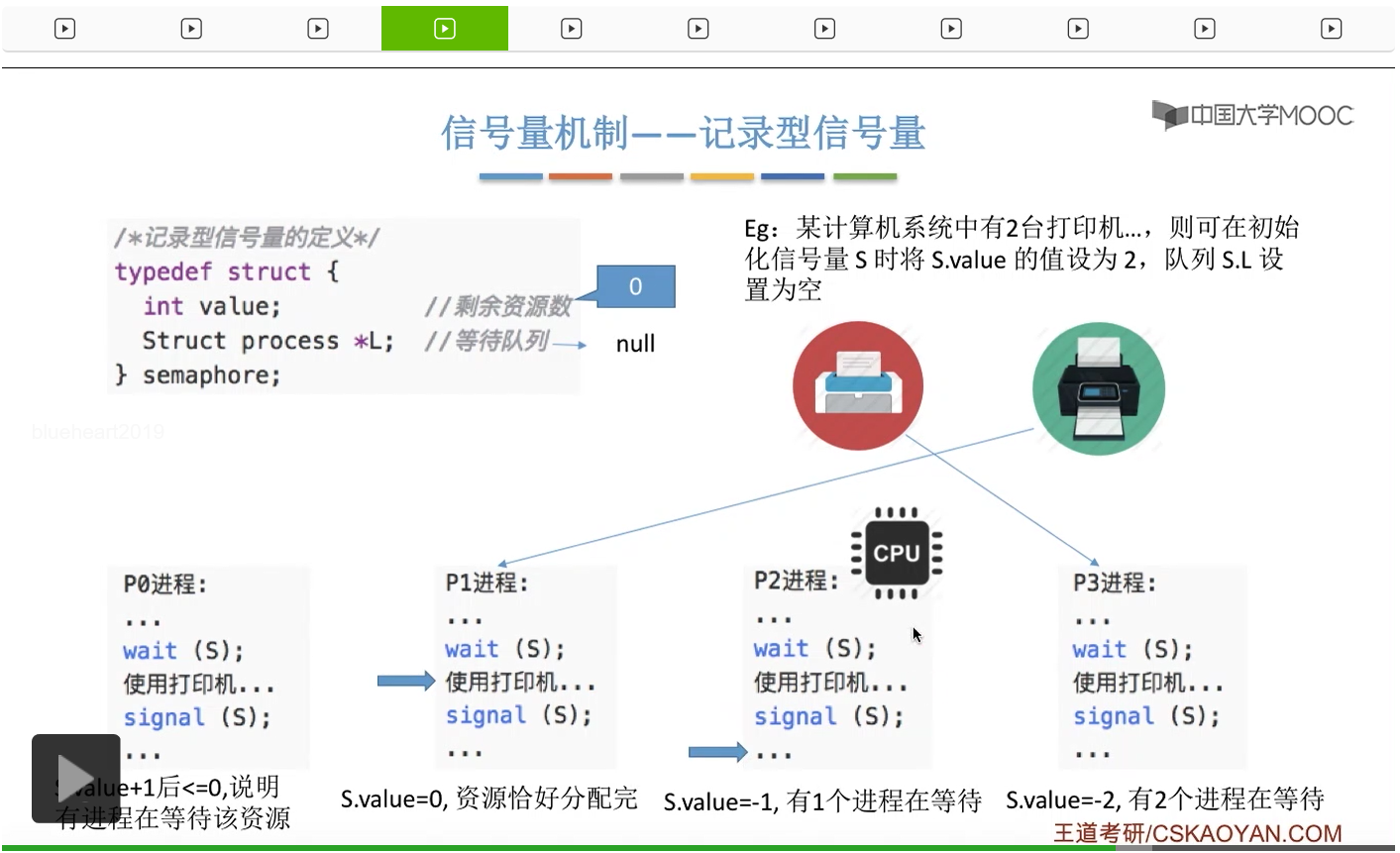
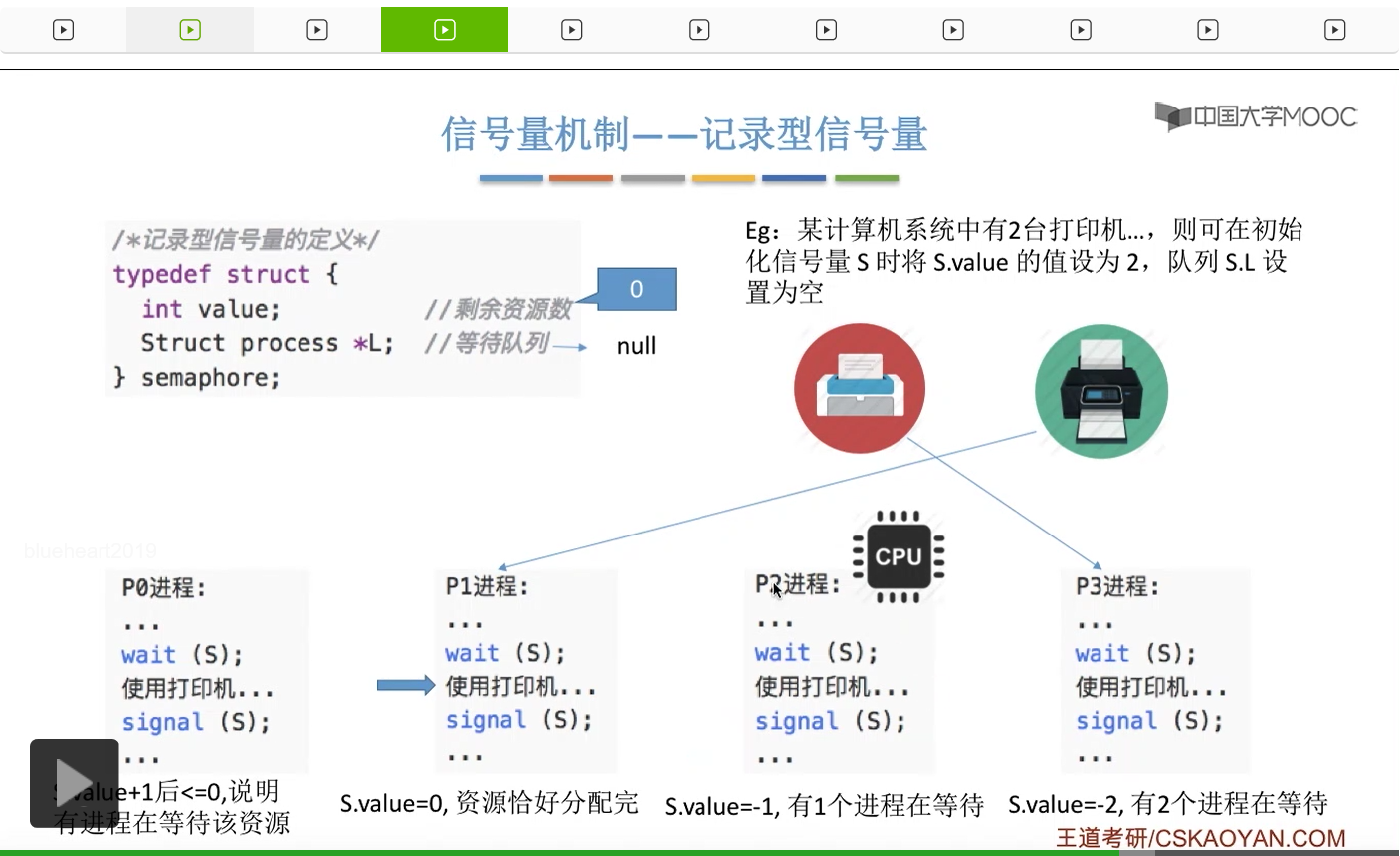
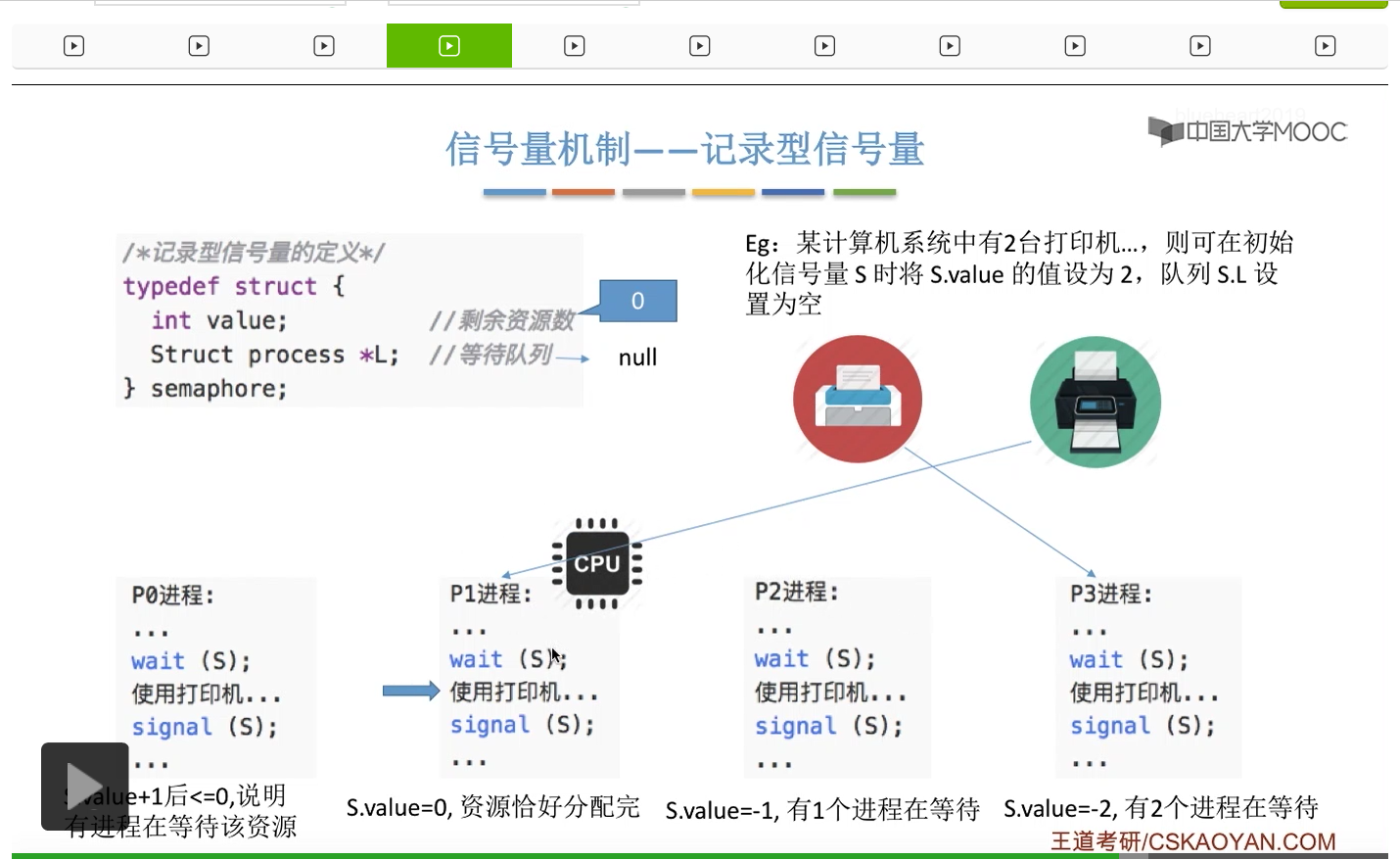
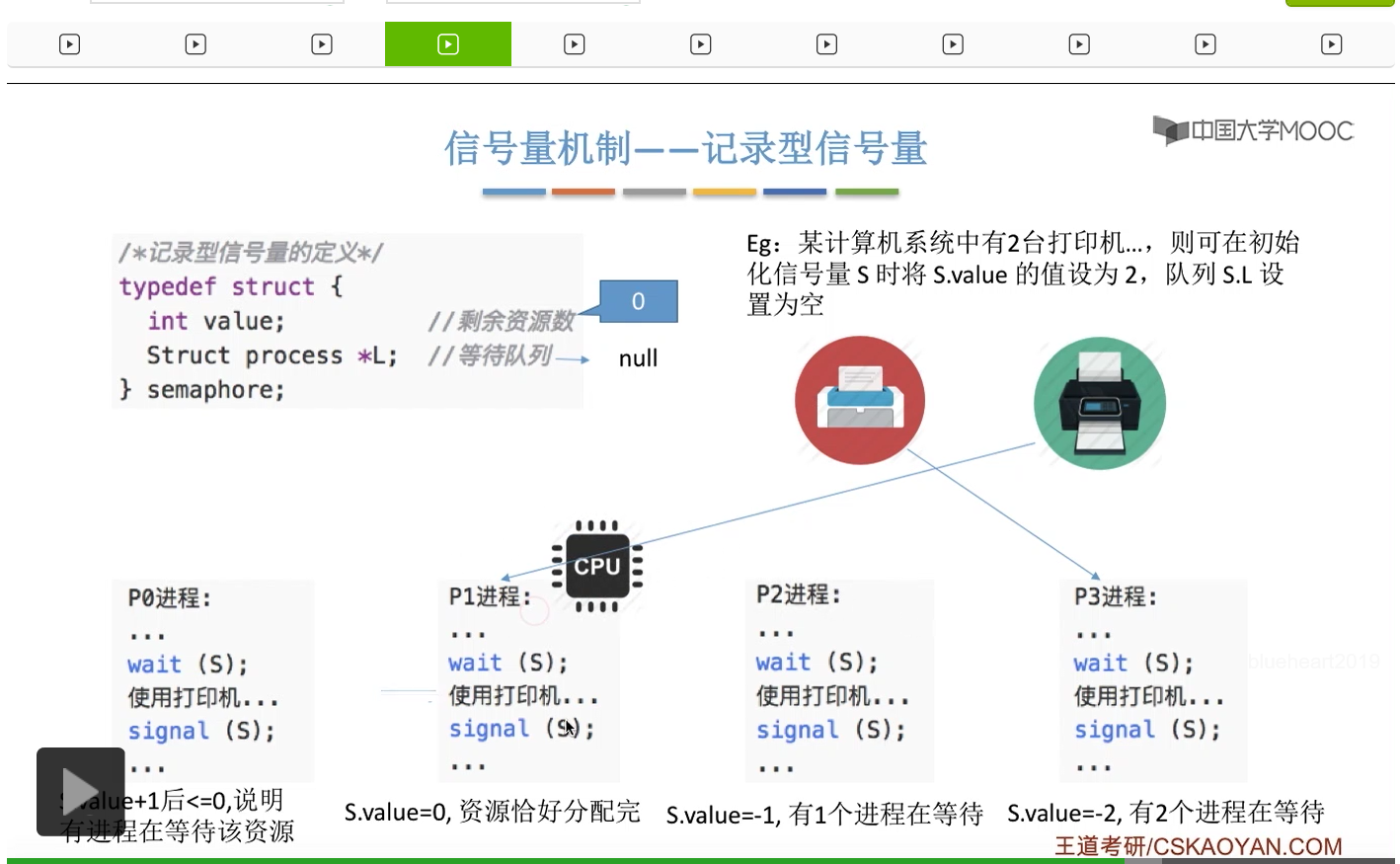
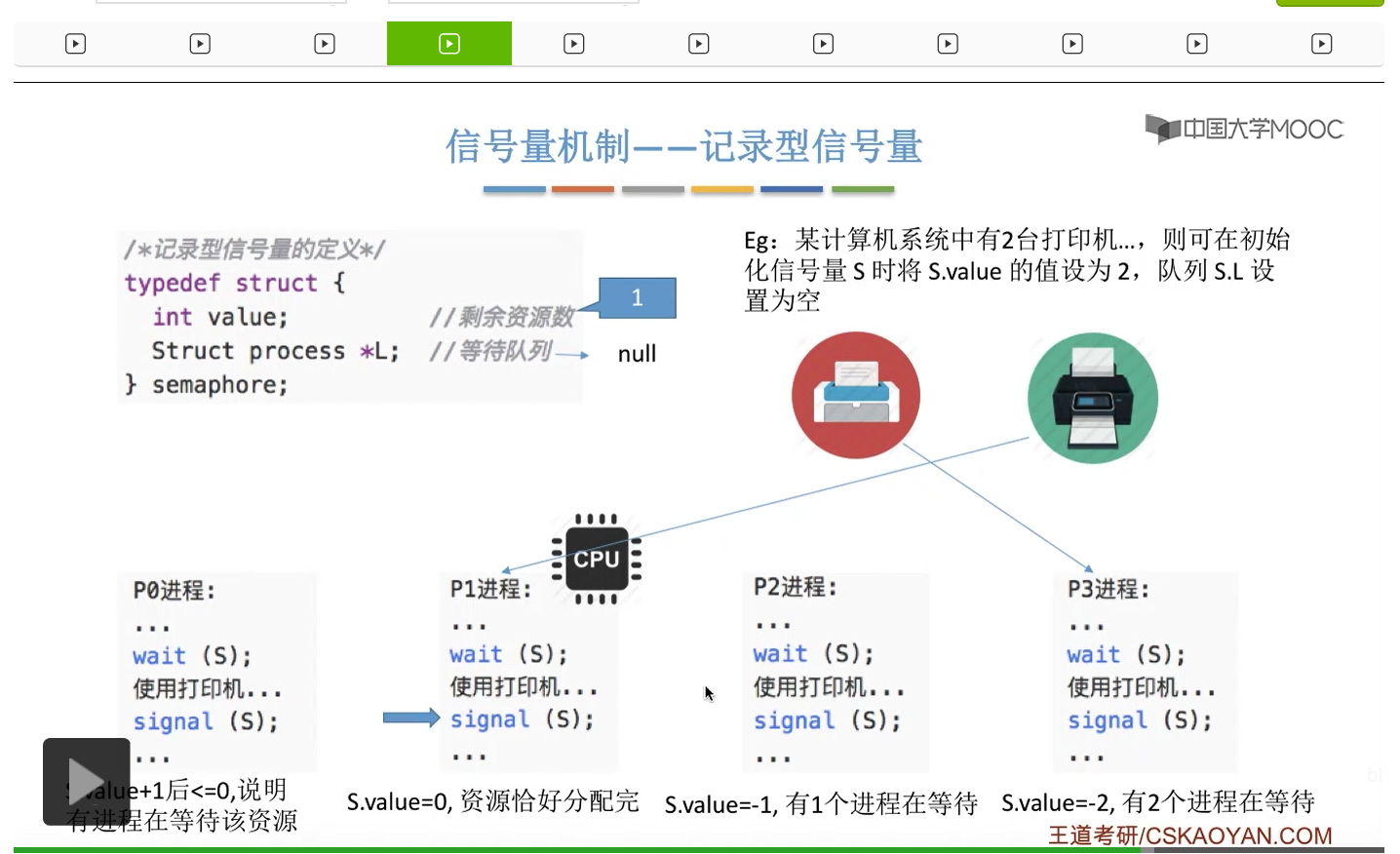
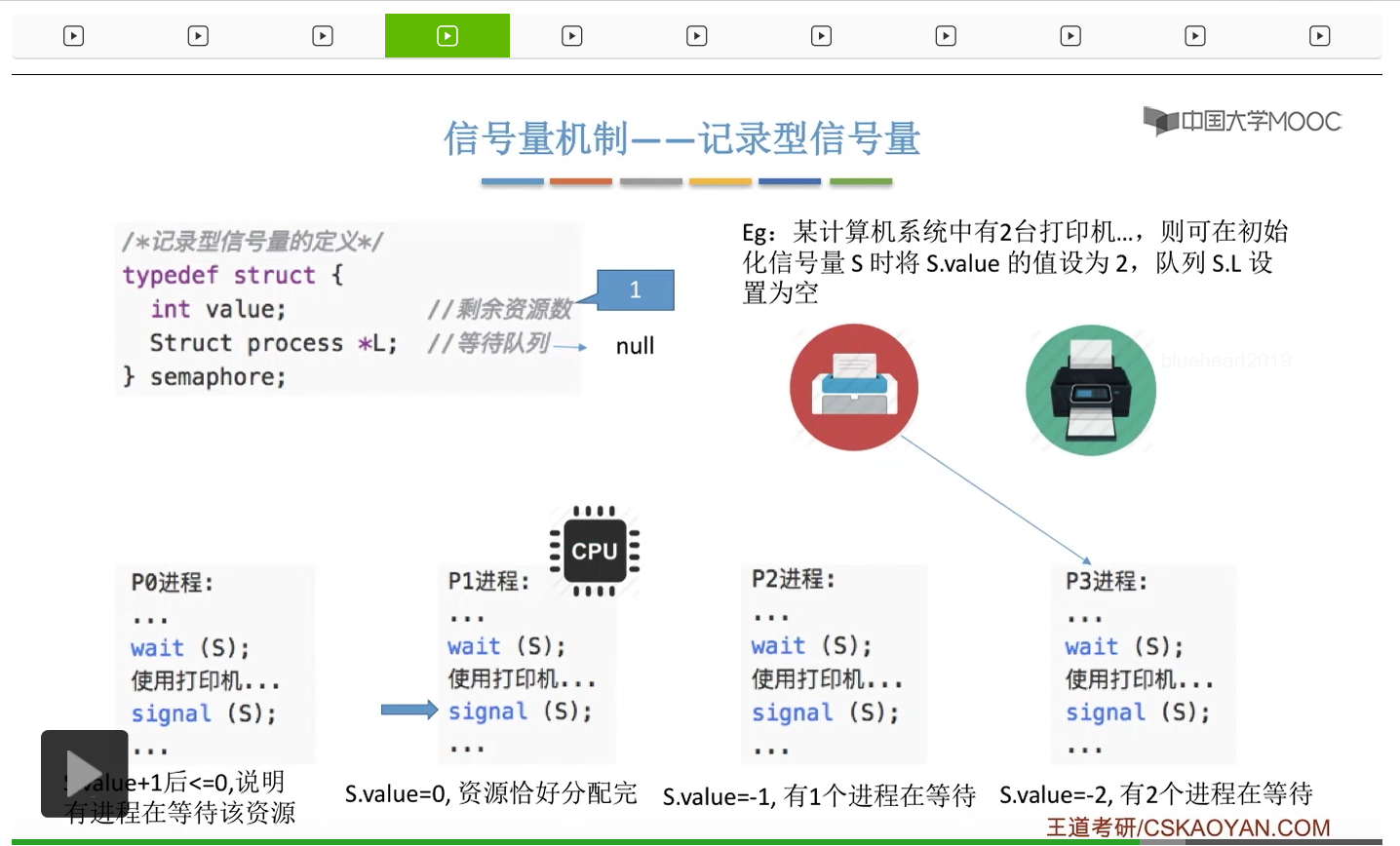
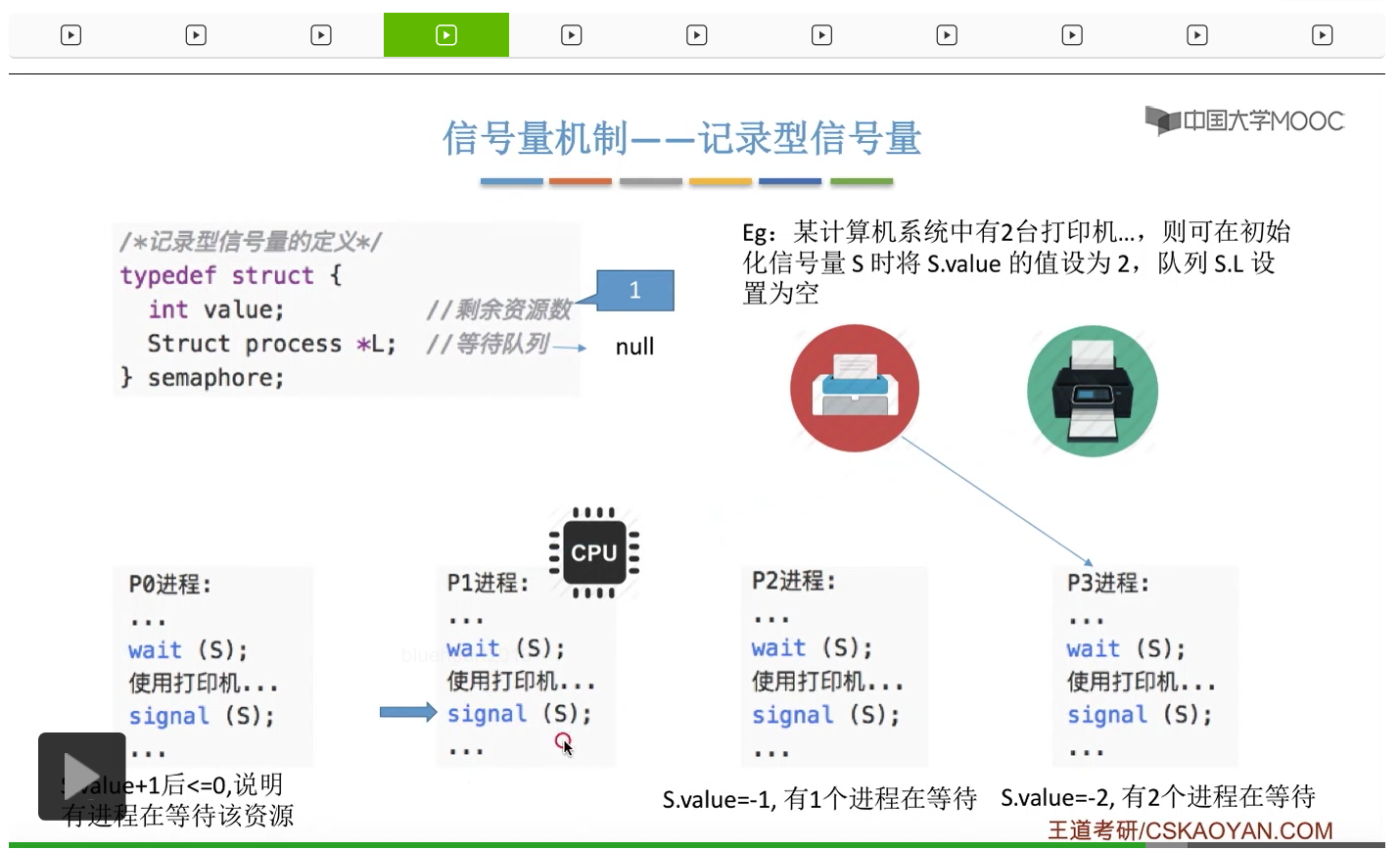
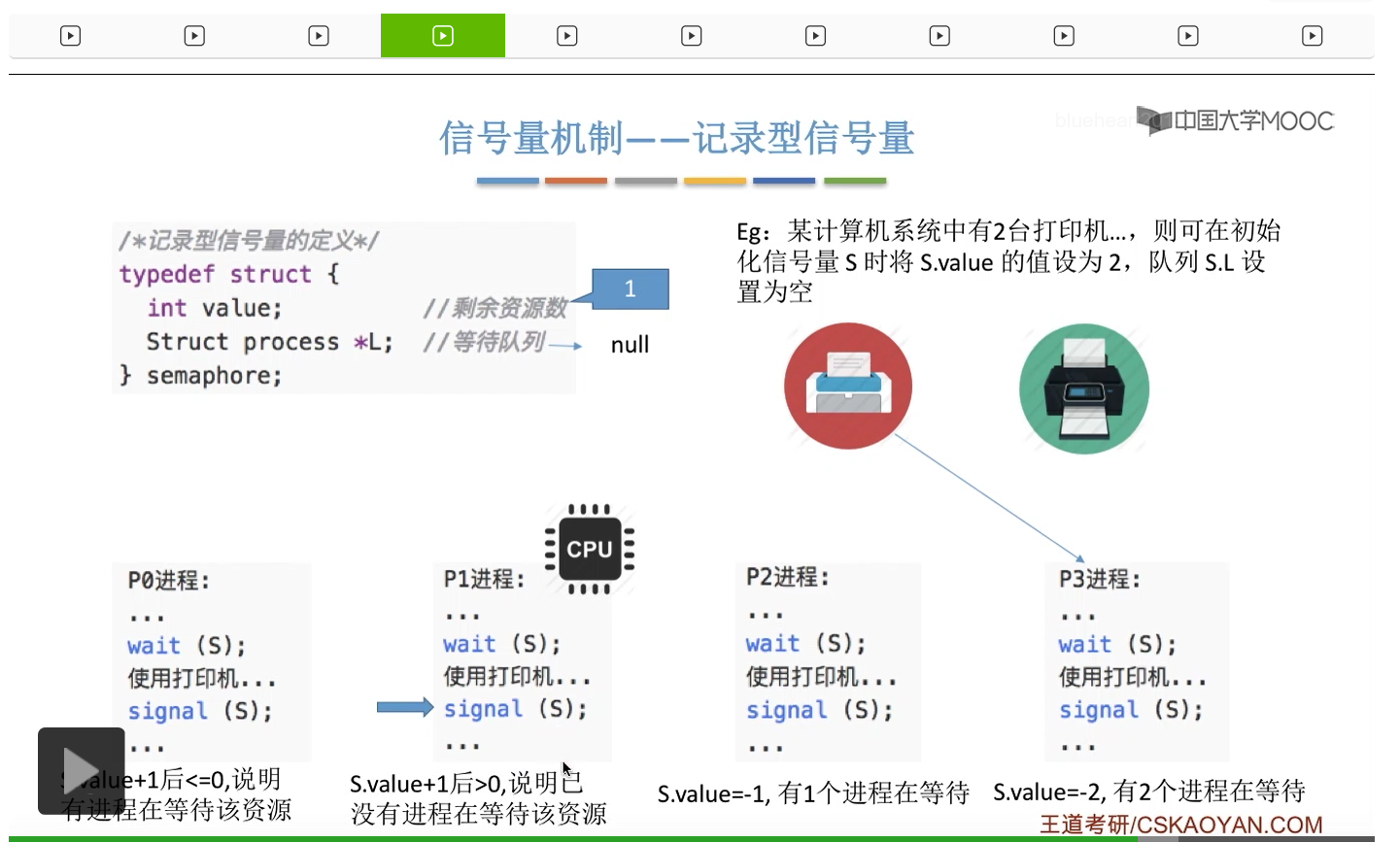
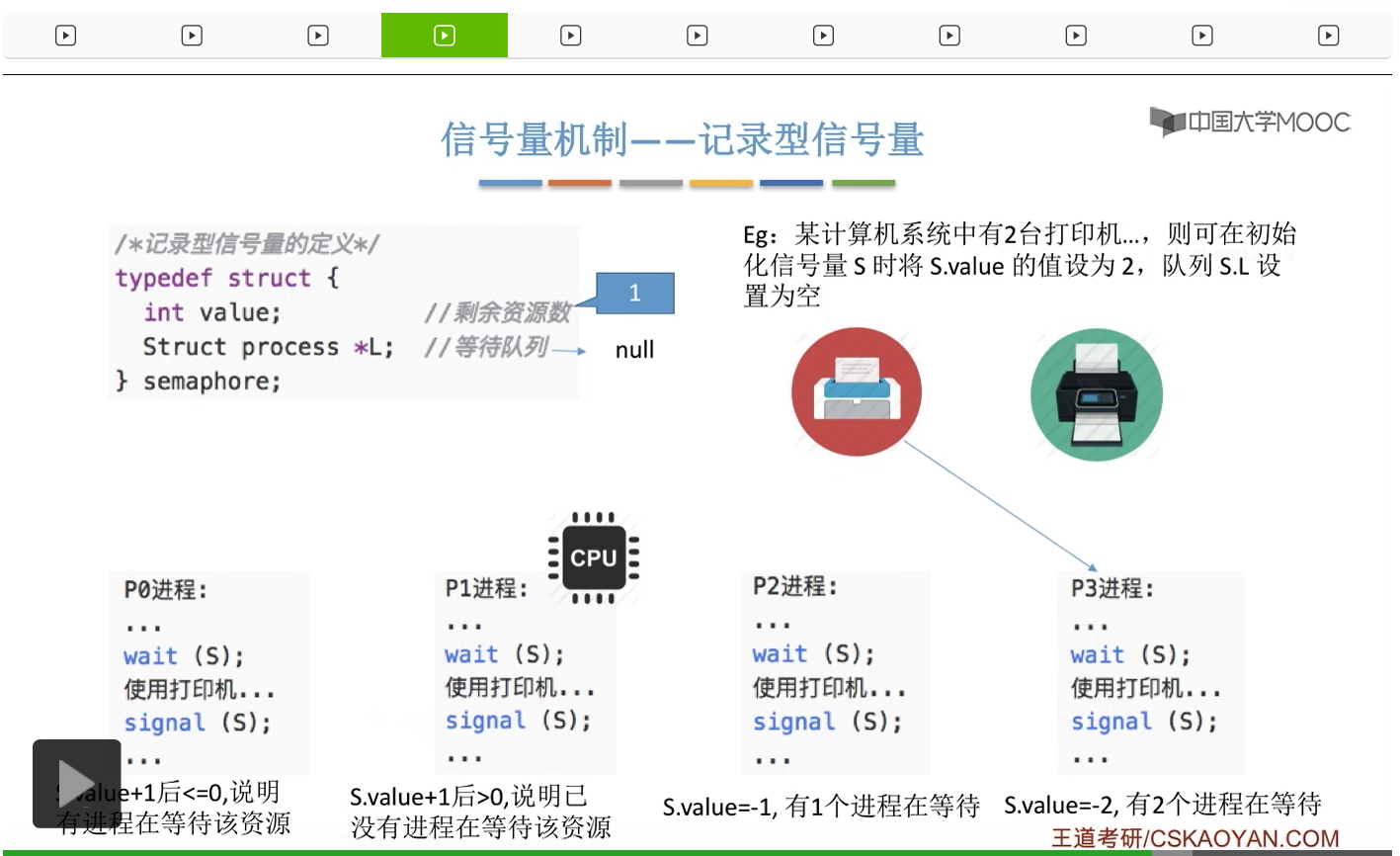








整型信号量比较容易考察的是它存在的问题,也就是不满足让权等待的原则,有可能会出现忙等的现象。而记录型信号量可以说是操作系统这门课当中最重要的知识点。在大题和小题当中都会有很高的概率会考察记录型信号量。那么大家需要自己在稿纸上动手写一下记录型信号量的PV操作,还有在什么条件下需要执行block和wake up这两个原语,一定不能用死记硬背的方式,需要把这个地方彻底地理解。如果说在题目当中出现了对某一个信号量S的P操作和V操作,那如果说题目中没有特别说明的话,这个信号量指的都是记录型的信号量。也就是说,如果说这个P操作暂时得不到它所申请的资源的话,那么这个进程不会忙等,而是会进入到阻塞的状态。
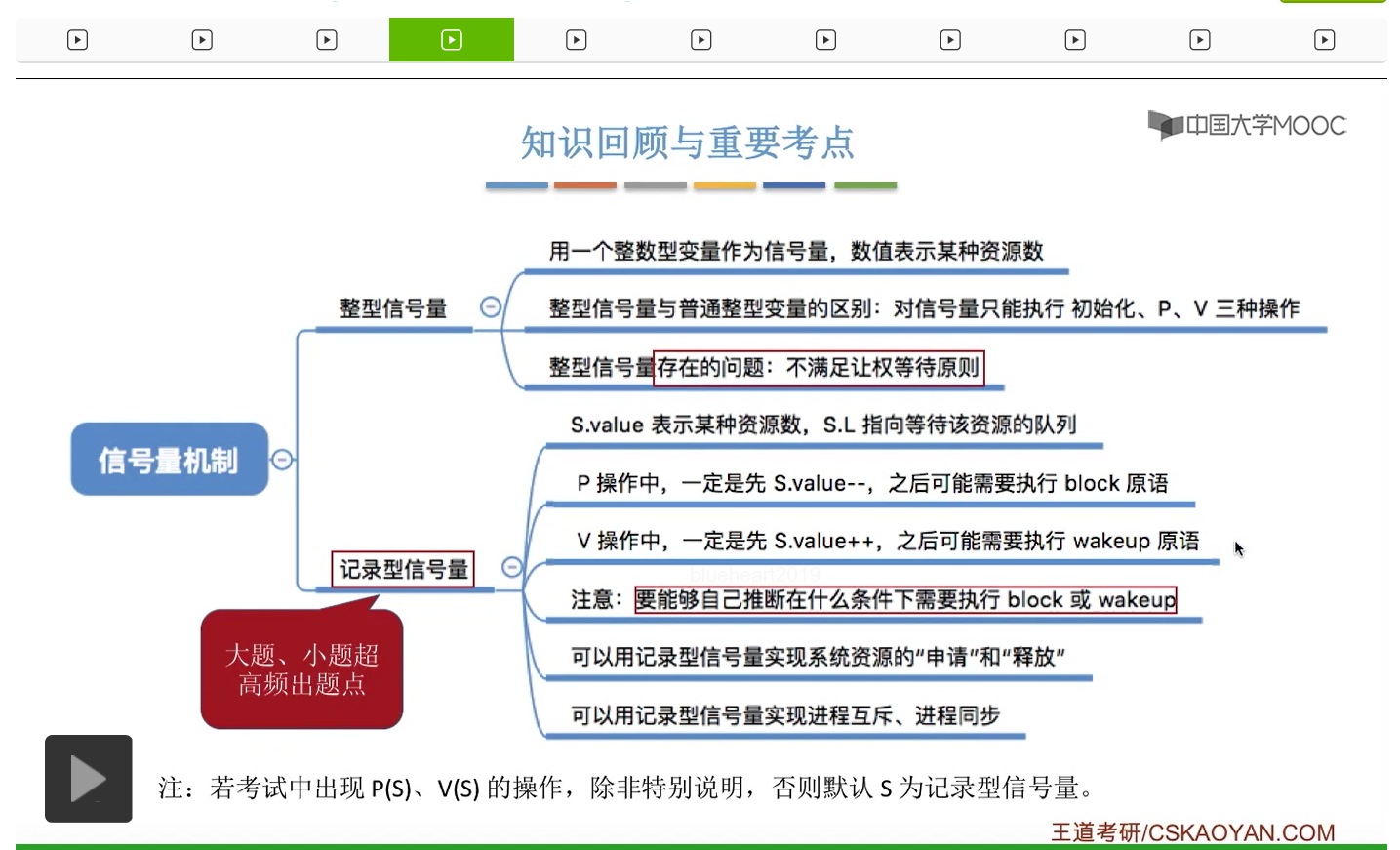

进程互斥的几种软件实现方式和硬件实现方式,但是这些实现方式都有一个共同的缺点就是,没有办法实现让权等待这个原则。而信号量机制当中,设置了进程的阻塞和唤醒,就刚好可以解决让权等待这个问题,所以信号量机制是一种更先进的解决方式。那我们上个小节介绍了信号量是什么?信号量机制的PV操作分别做了一些什么事情?不要先一头钻进代码里,而是要注意理解信号量背后的含义。
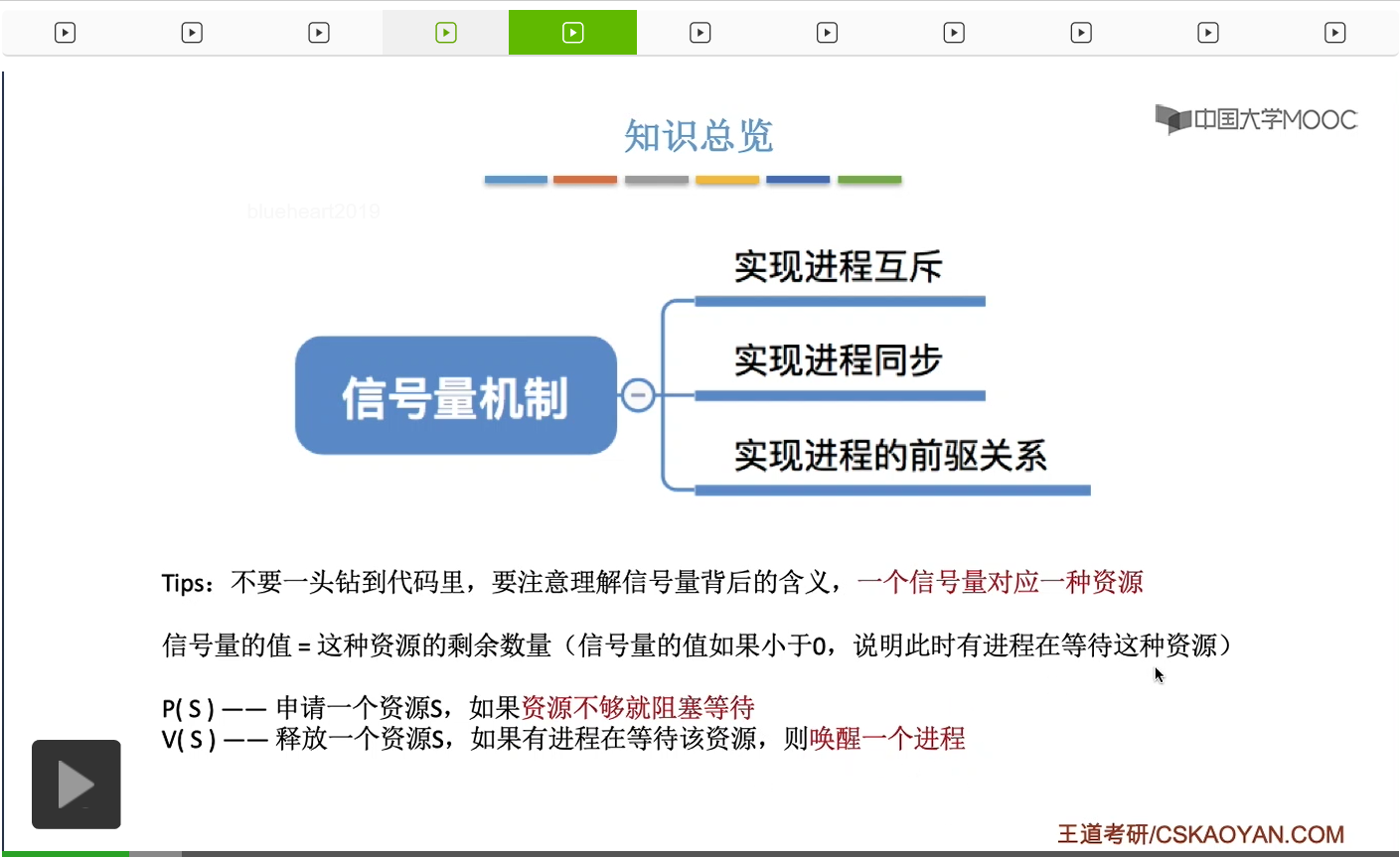
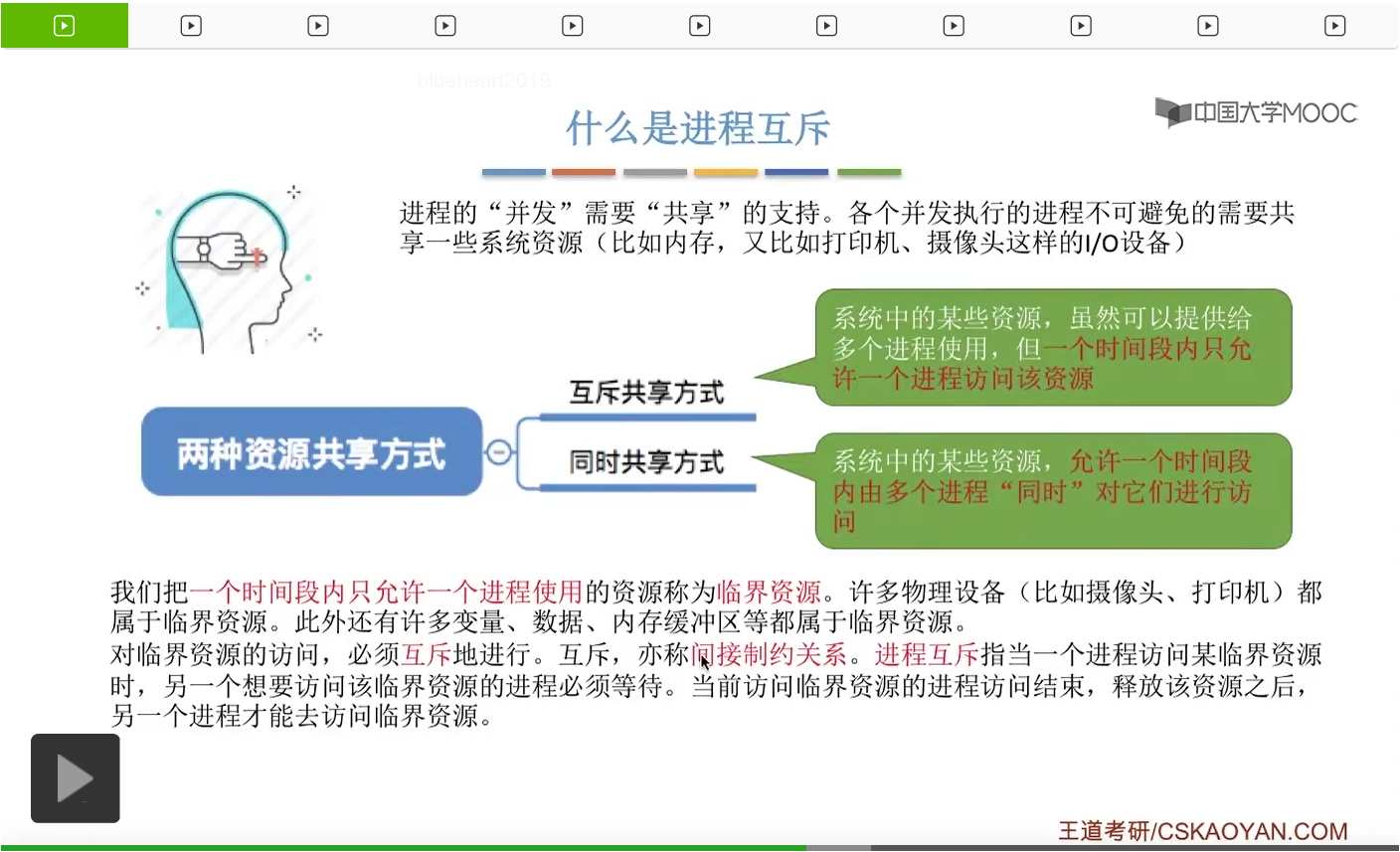
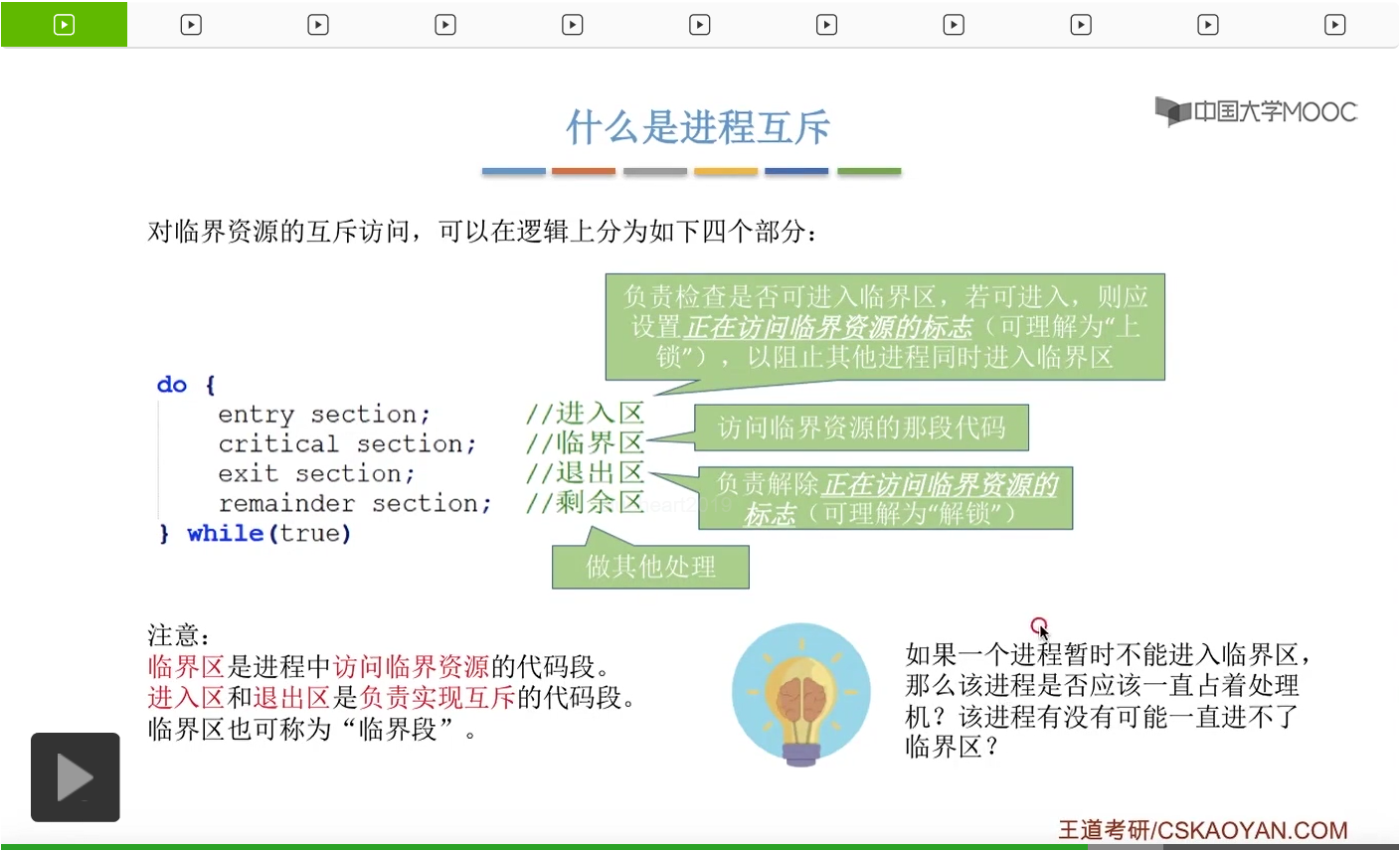
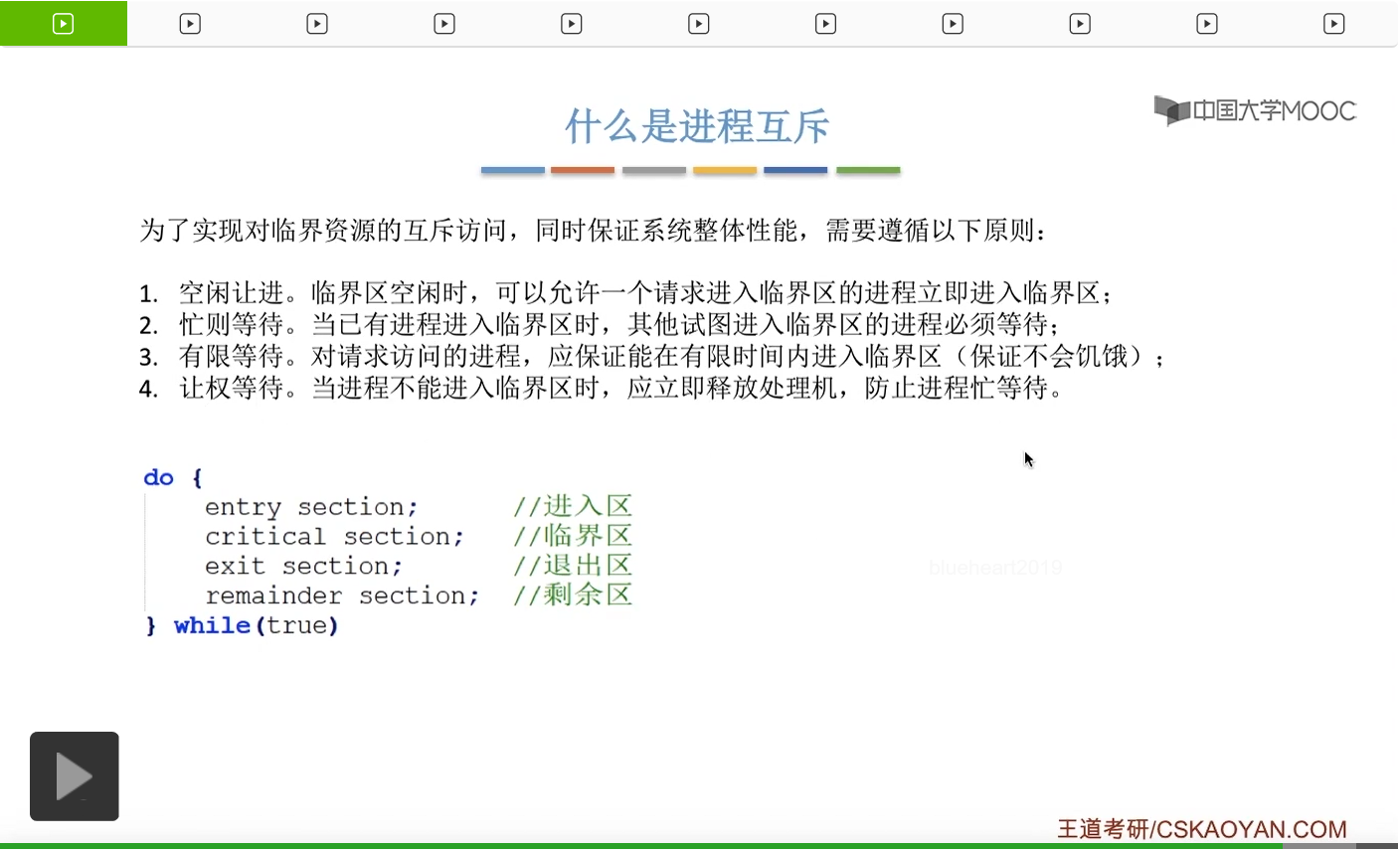
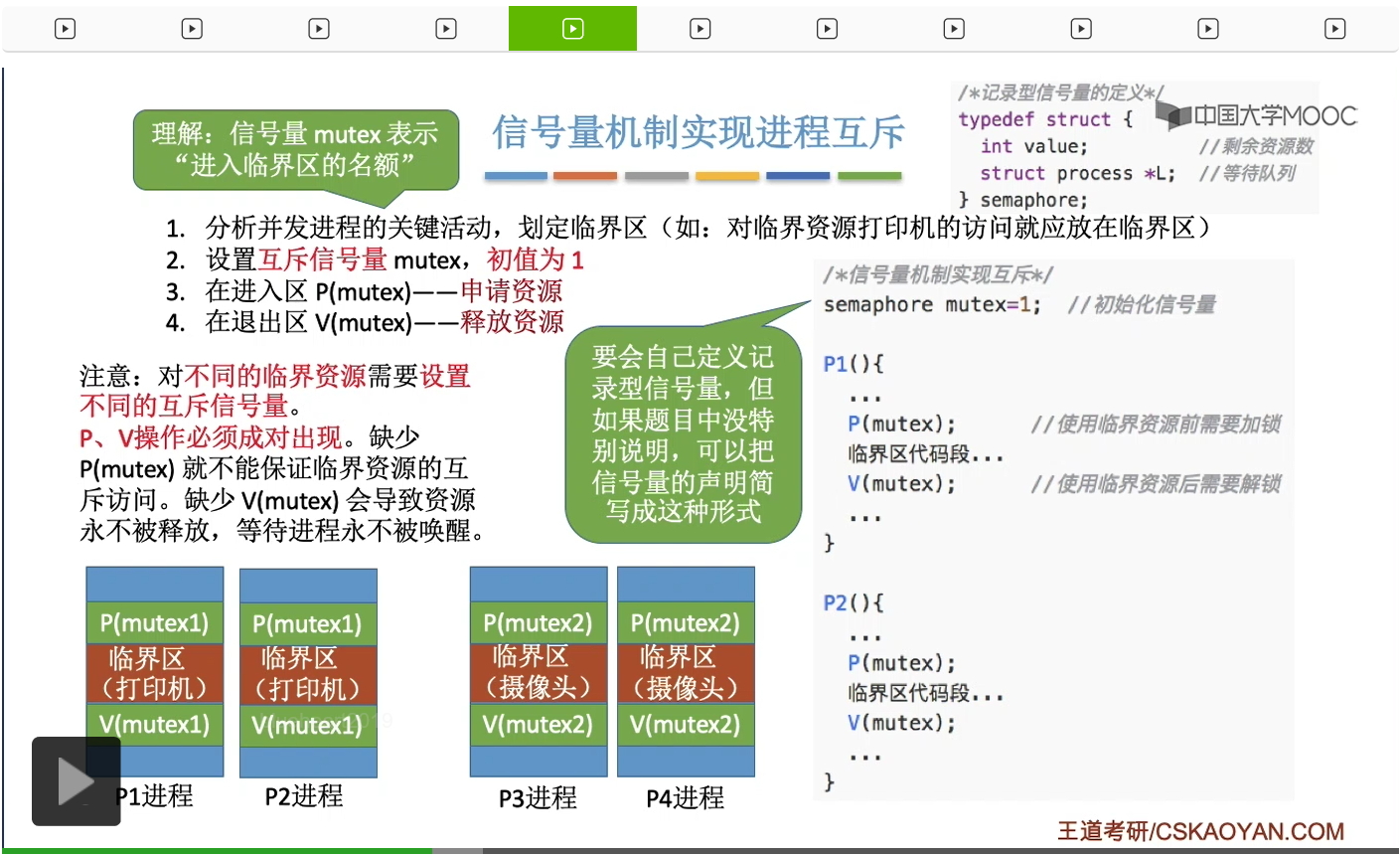
系统当中的某一些资源是必须互斥访问的,而访问这种系统资源的那段代码叫做临界区,所以既然这个资源需要互斥访问,那么就说明同一时刻只能有一个进程进入临界区代码。所以要解决进程互斥的问题,我们首先要做的是要划定临界区。也就是说,哪一段代码是用于访问临界资源的。另外为了实现对临界区的互斥访问,我们需要实现一个互斥信号量叫mutex,mutex就是英文的互斥的意思。信号量它其实就是用于表示某一种资源,这个互斥信号量mutex我们可以认为它所表示的资源是“进入临界区的名额”,它的初始值为1,那么就说明刚开始可以进入这个临界区的名额只有一个。那当某一个进程对mutex执行P操作的时候,其实在背后的逻辑就是说我想申请一个进入临界区的名额。所以可以看到,我们用这样的方式就实现了各个进程对临界区的互斥访问。
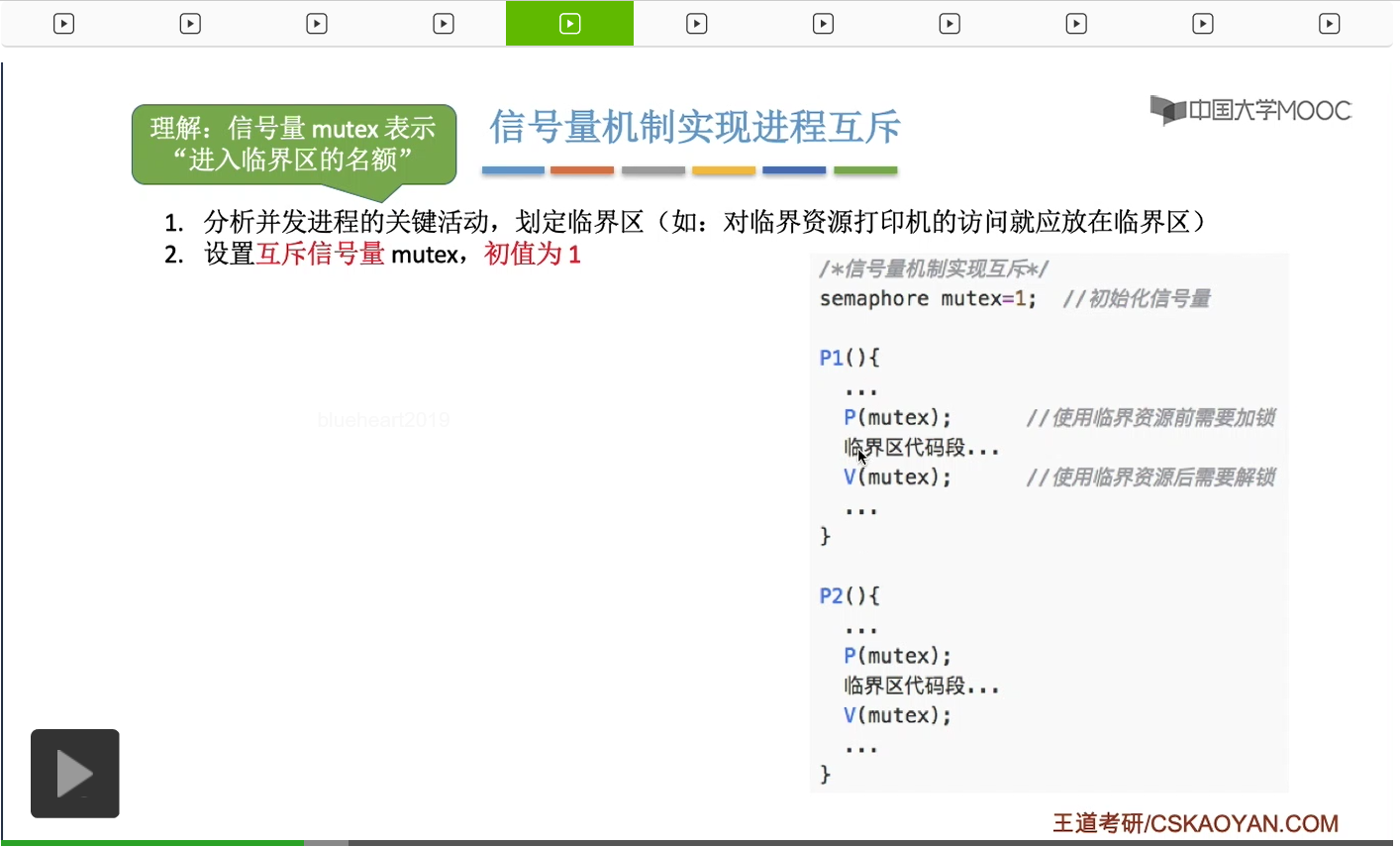
只要我们用semaphore这个关键字来开头的话,那么就意味着这个信号量它并不是整型信号量,它是一个记录型的信号量,也就是说这个信号量是带有排队阻塞的这个功能的,并不会忙等。
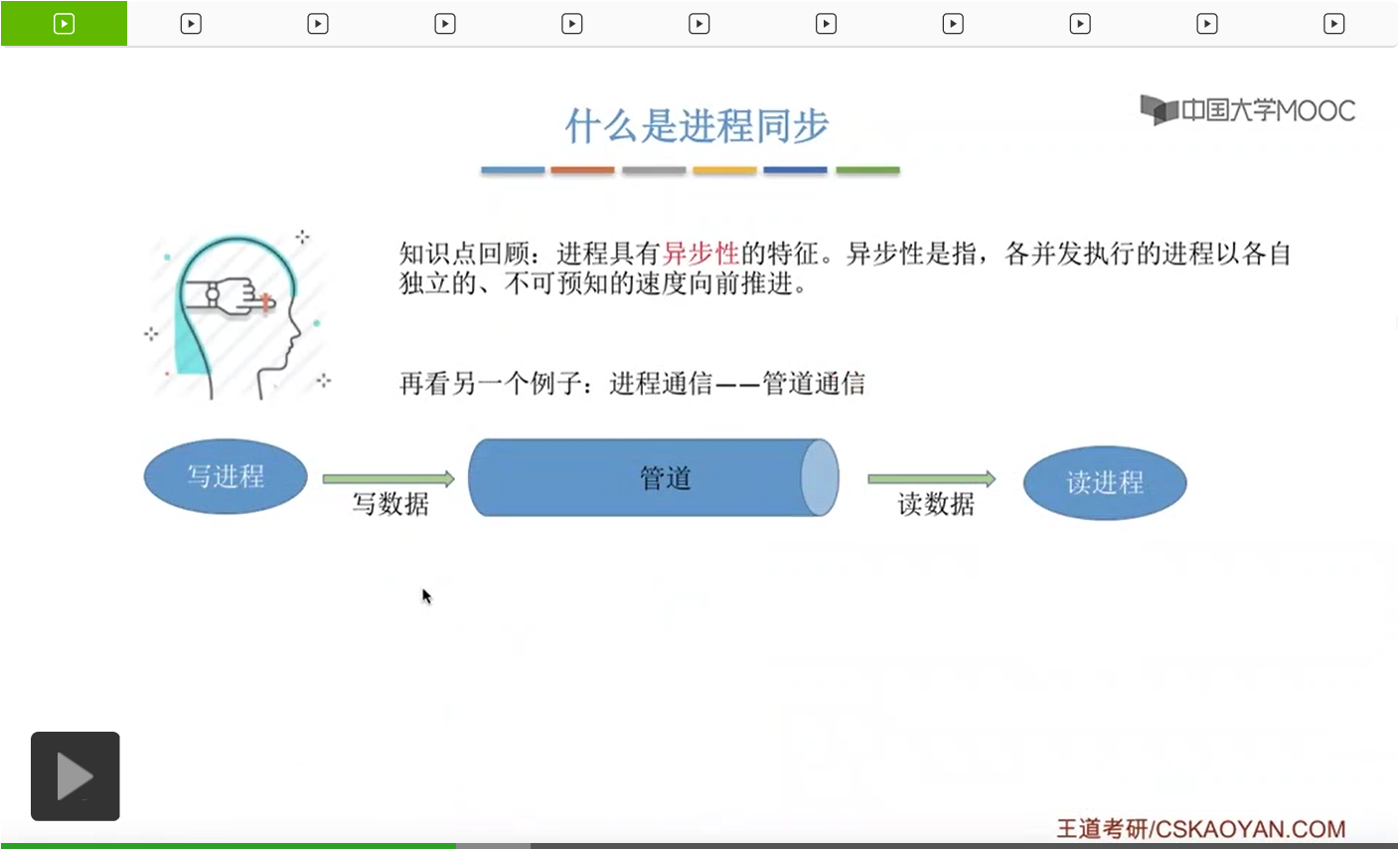
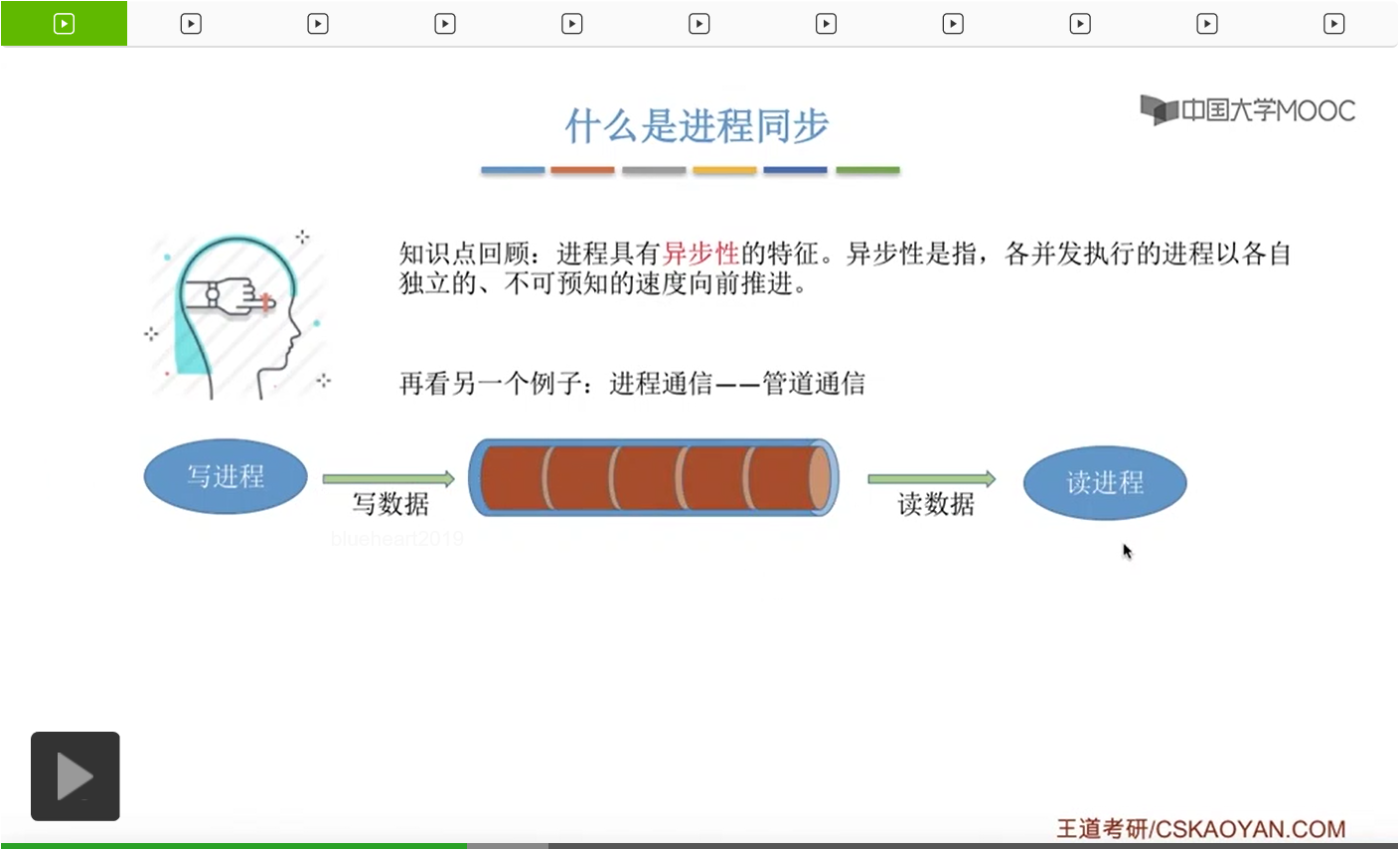
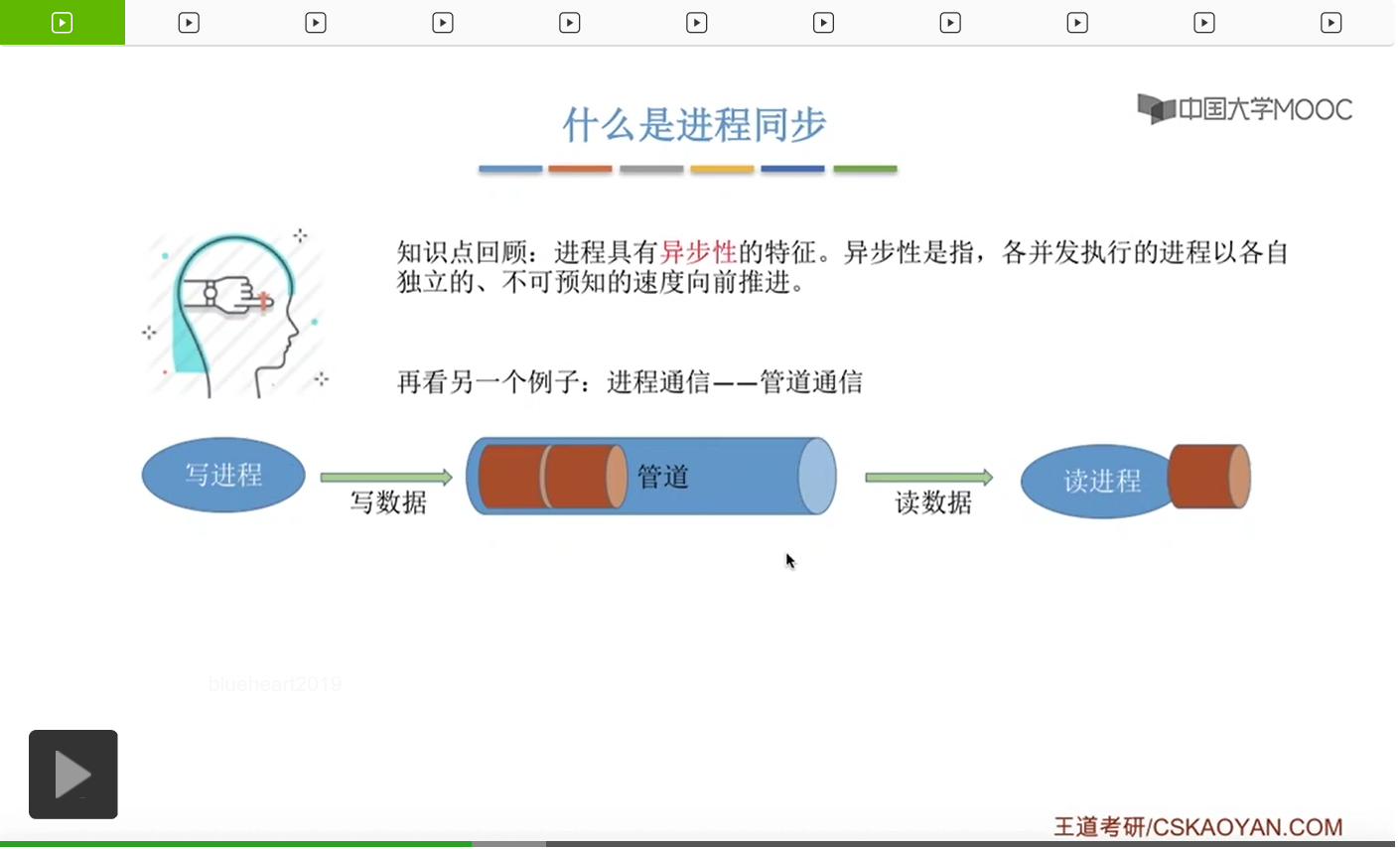
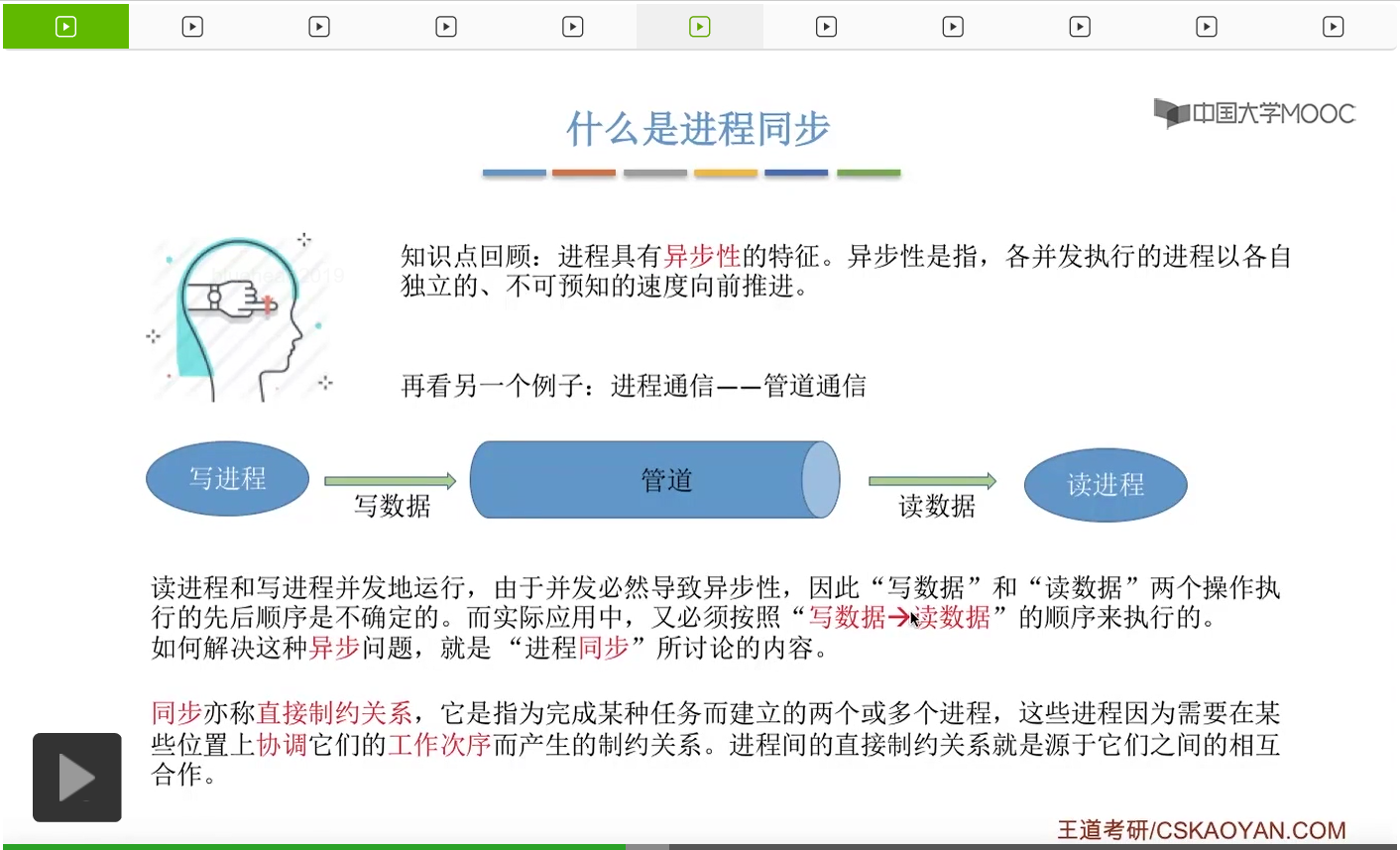
那进程的同步这个概念我们已经有一段时间没提了,再来简单地复习一下。我们要解决它们之间并发运行存在的异步性,让它们按照我们想要的顺序相互配合着有序地推进。

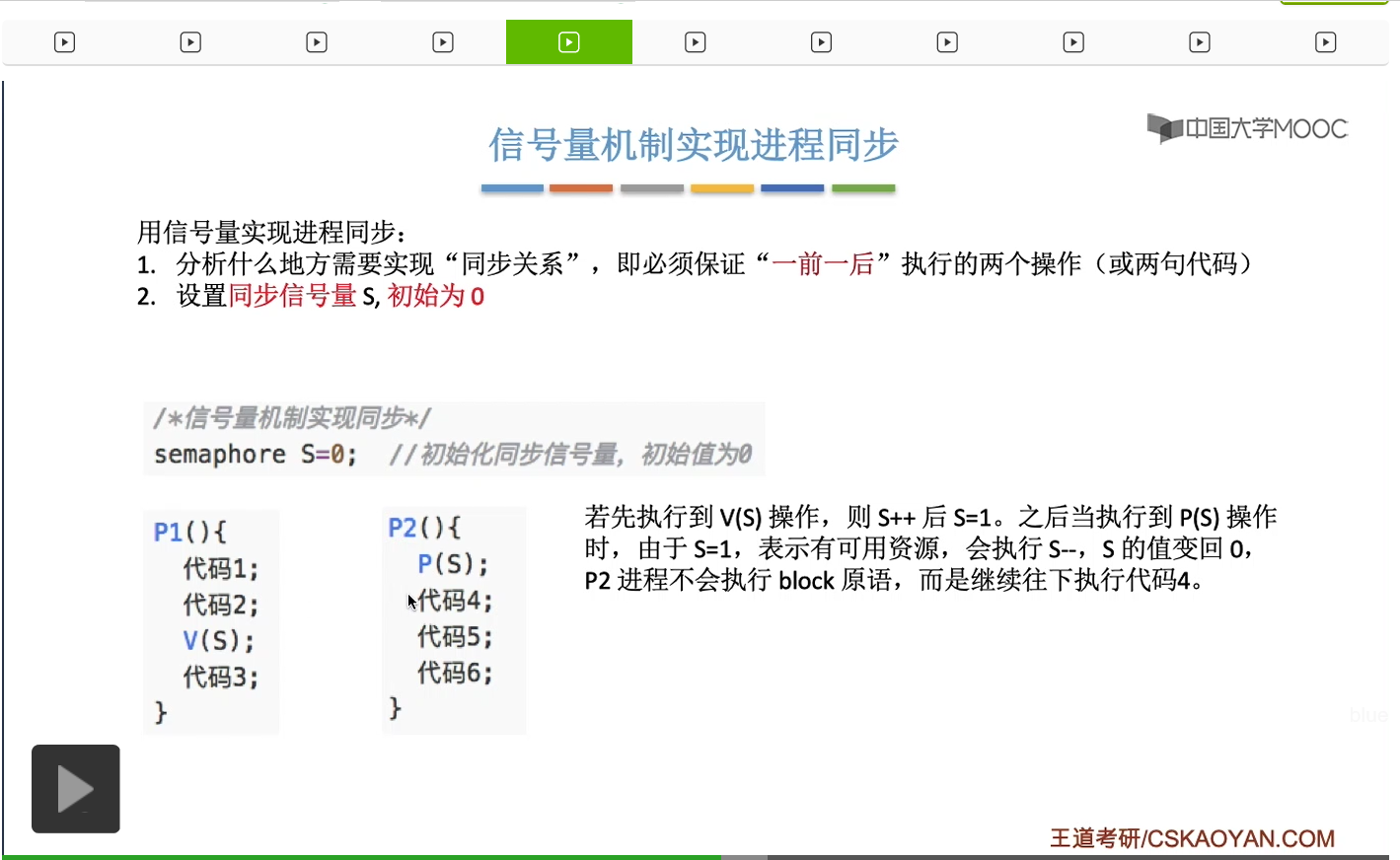
我们依然是用信号量代表某种资源这样的思路来分析这个问题。这个信号量S它表示某种资源,那具体是什么资源没必要关心。刚开始S的值是0,就意味着刚开始这种资源是没有的,而P2要执行代码4之前,它一定需要获得这个资源,所以它在执行代码四之前,需要执行一个P操作。但是呢这种资源只有P1能够释放,所以当P2申请这种资源得不到满足的时候,它就会被阻塞。而由于这种资源只有P1能够产生,所以只有P1能够在某一个特定的位置唤醒P2这个进程,所以这就实现了进程之间的同步关系。我们设置一个信号量初始值为0,表示刚开始这种资源是没有的,而只有执行前面那个操作的进程,可以释放这种资源,所以这是前V。而执行后面那个操作的进程,在它的操作之前,需要申请一个这个资源,所以这是后P。当它申请的这个资源得不到满足的时候,这个进程就会阻塞,只能由前面那个进程把它唤醒。那这个技巧是解决进程同步问题的一个关键。
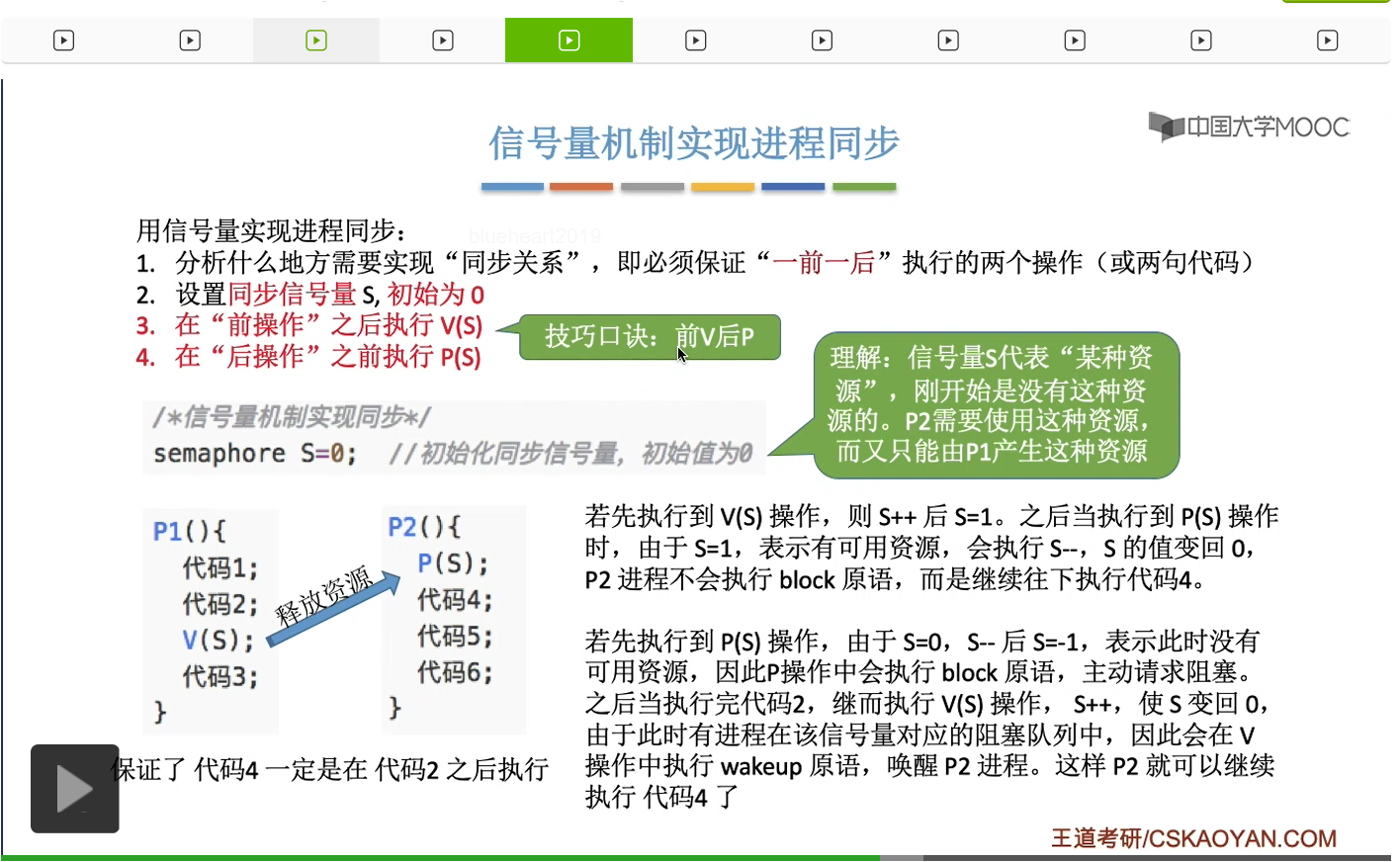
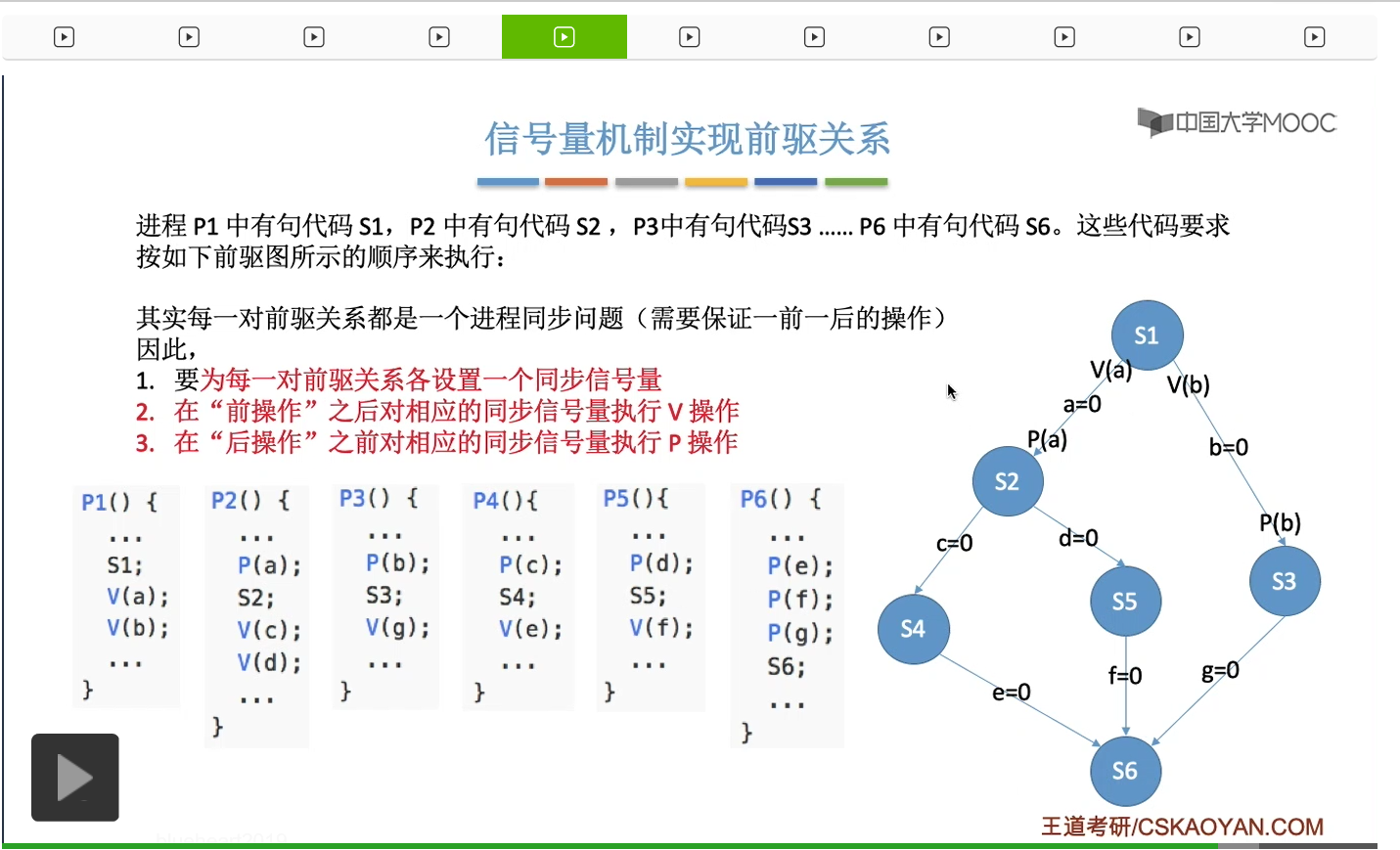
我们来看一下怎么利用这个技巧来解决更复杂的进程同步问题。我们的课本上专门讲了一个叫做进程的前驱关系。只有S1这个事件发生了之后,或者说只有S1这个代码执行了之后,才能执行S2和S3。而只有执行了S2之后,才可以执行S4和S5。另外,只有执行了S3、S4和S5之后,才能执行S6。那我们假设这几句代码分别是P1、P2、P3、P4一直到P6这几个进程需要执行的。那我们来看一下怎么用信号量机制解决这么复杂的进程之间的同步问题。
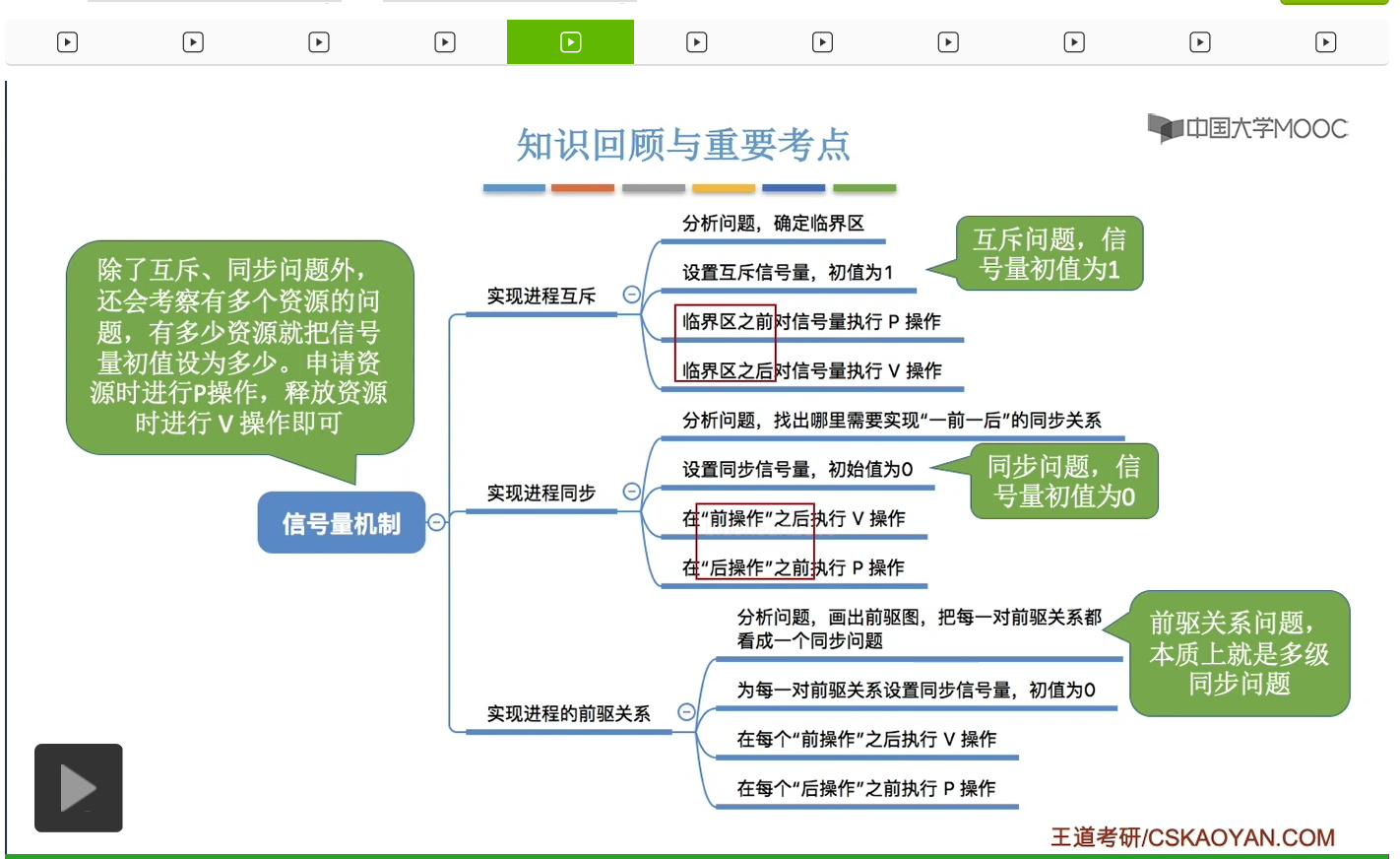
好的那么这个小节中我们介绍了很重要的知识点,怎么用信号量机制实现进程的互斥、同步。几乎每一年都至少有个大题是要考察这个信号量机制实现互斥和同步的,所以对于这个小节的掌握是十分重要的。那么如果要用信号量机制实现进程互斥的话,我们可以设置一个初始值为1的互斥信号量,并且在临界区之前执行P操作,临界区之后执行V操作。而如果要实现进程的同步的话,那么我们需要设置一个初始值为0的同步信号量。另外需要在前操作之后执行V操作,需要在后操作之前执行P操作,也就是前V后P,用这样的方式就可以保证进程之间一前一后的这种同步关系了。那这是互斥和同步问题的一个基本套路。那最后我们所介绍的进程的前驱关系,它本质上也是一个进程同步的问题,只不过它是多级的同步。那只要我们能掌握前V后P的这种技巧的话,那前驱问题其实也很好解决。那对于信号量机制的考察,除了实现互斥和同步之外,有的时候有可能会考察用信号量机制来实现资源分配的问题。比如说系统中有三个打印机,那么这种情况下我们就需要把打印机对应的那个信号量初始值设置为3,然后当一个进程需要申请使用这个资源的时候,就需要对这个资源所对应的信号量执行P操作,然后使用完了之后就需要执行V操作。那这一点其实只要掌握了信号量它在背后所表示的逻辑也并不难理解。
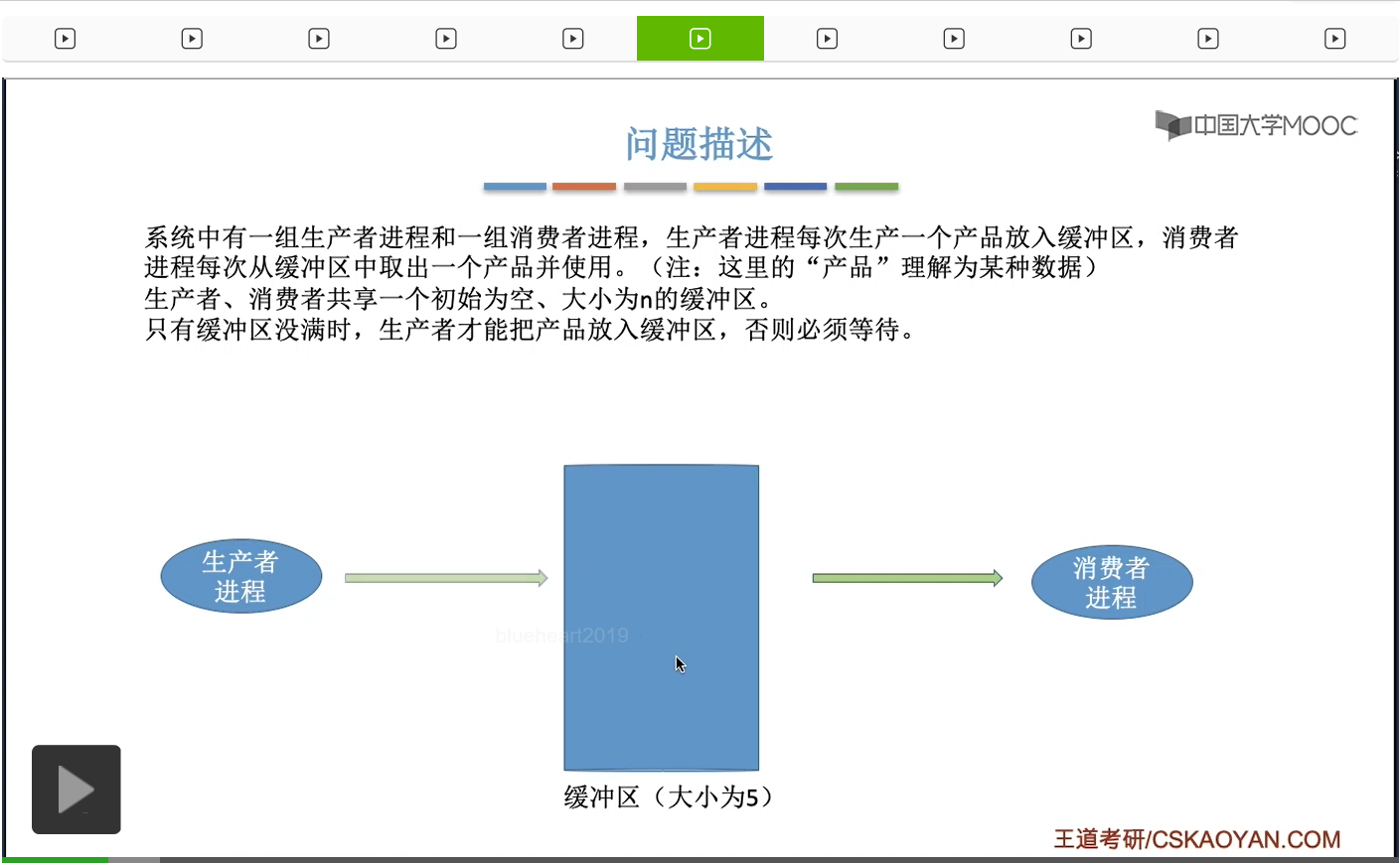
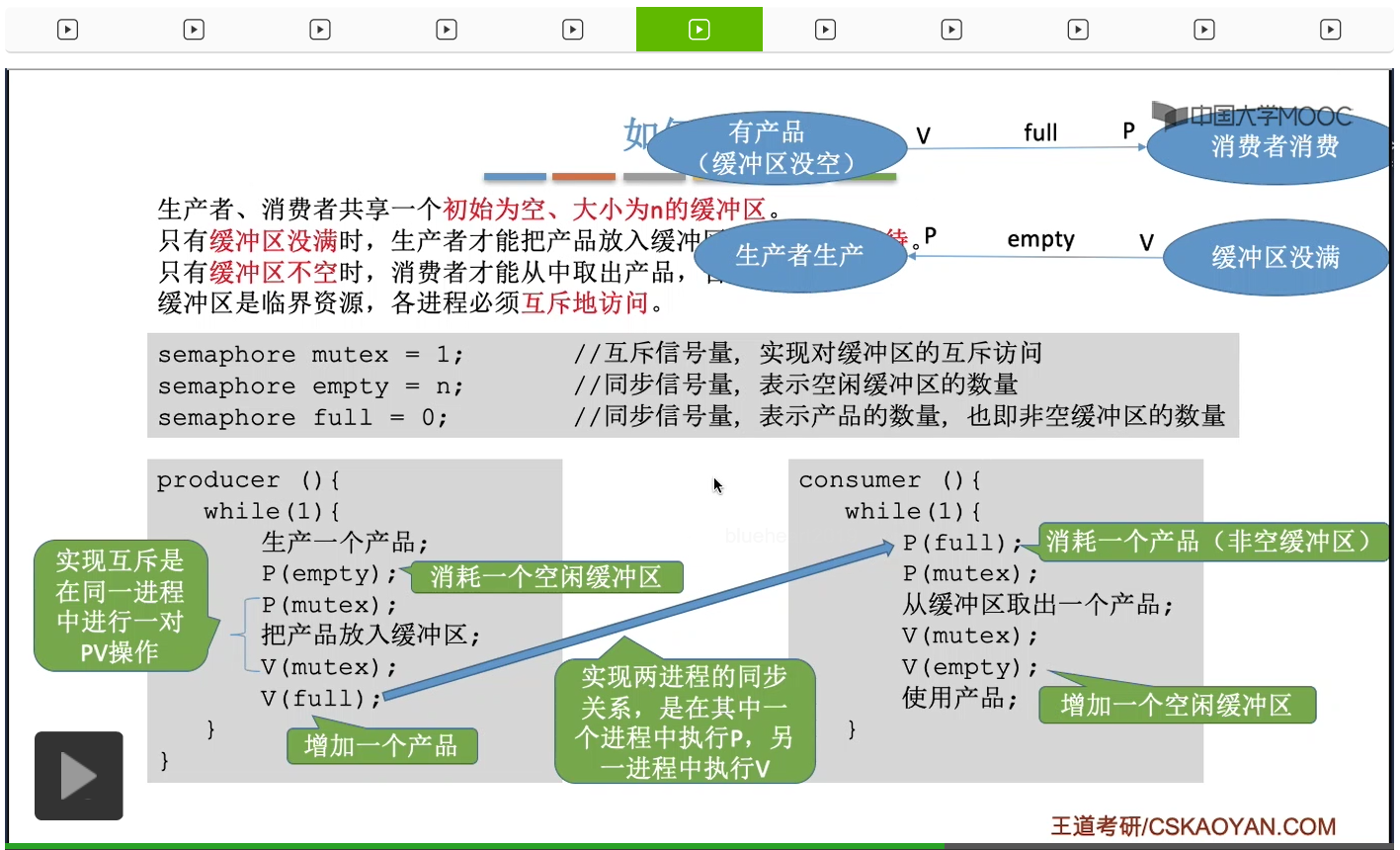
一个经典的进程同步互斥的问题,并且尝试用上个小节学习的PV操作也就是信号量机制来解决这个生产者消费者问题。缓冲区其实就是用来存放数据的一片区域,我们可以把它理解为一个一个的小格子。每一个缓冲区也就是每一个小格子里面可以放一个产品,也就是一坨数据。然后消费者呢又会从这些缓冲区当中每次取出一个产品,也就是每次取出一坨数据。那生产者和消费者这两组进程它们会共享地使用一个初始为空、大小为n的缓冲区,也就是有n个小格子可以放n坨产品。那需要注意的是,这个缓冲区是有容量限制的,它只能放五个产品。那只有缓冲区没有满的时候,生产者才可以往这个缓冲区里放入产品。

那如果缓冲区此时已经满了,但是生产者进程还想尝试往里面写数据。那生产者进程必须阻塞等待,等这个缓冲区被取空的时候,它才可以往里边写数据。这个条件就是我们上小节分析的同步问题,也就是说缓冲区没满的时候,生产者才能生产。这是一对一前一后的同步关系。另外呢消费者进程它会从这个缓冲区里取走这些产品,就是取走这些数据。
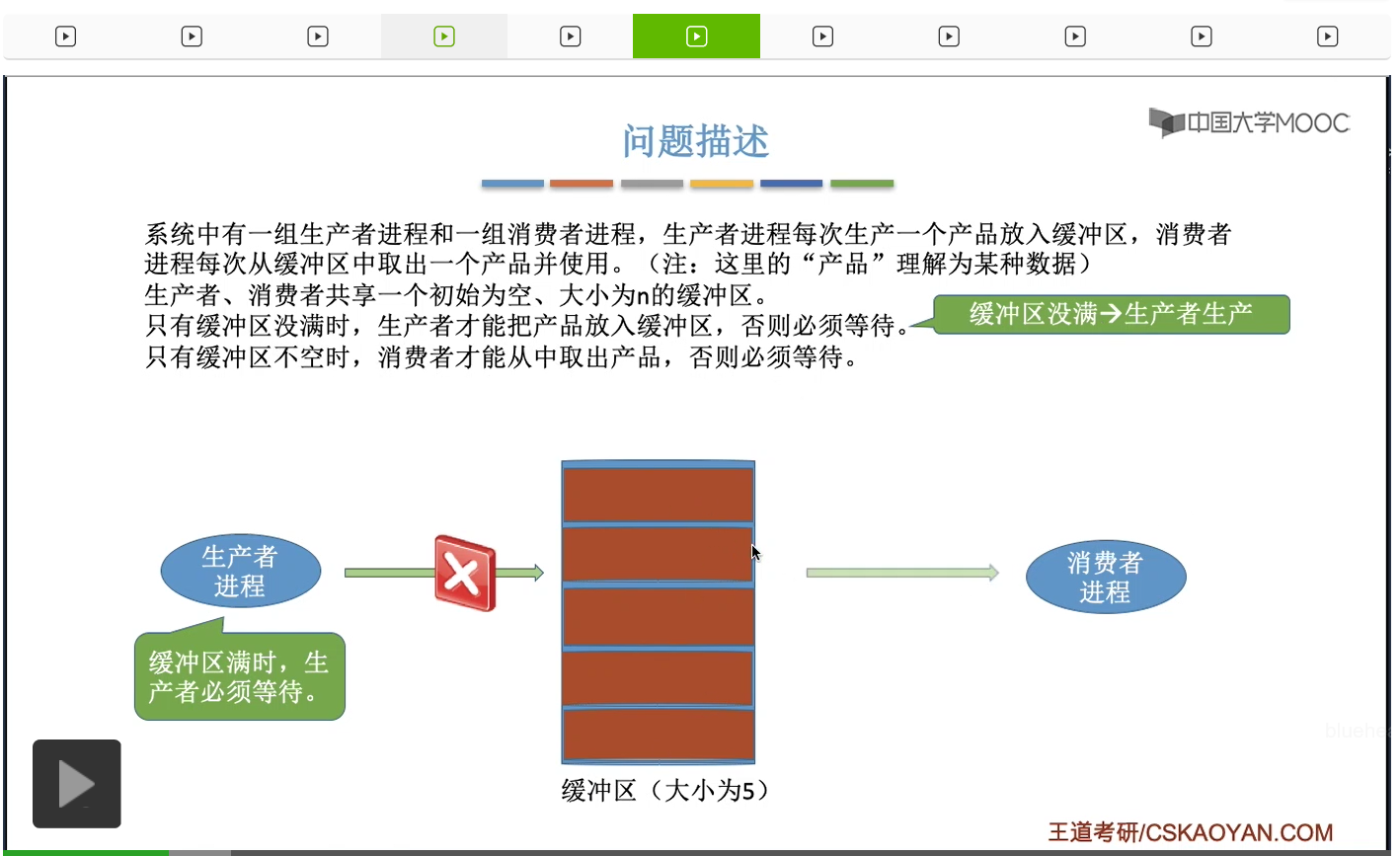
那当缓冲区没满的时候,也就是有空闲的缓冲区时候,生产者就可以继续生产。也就是说当一个消费者从缓冲区取走数据之后,如果此时有生产者是处于阻塞状态,那么消费者进程应该把生产者进程给唤醒,让它重新回到就绪态。不过呢生产者进程只是回到了就绪态,这并不意味着生产者进程会立即往里边写数据。
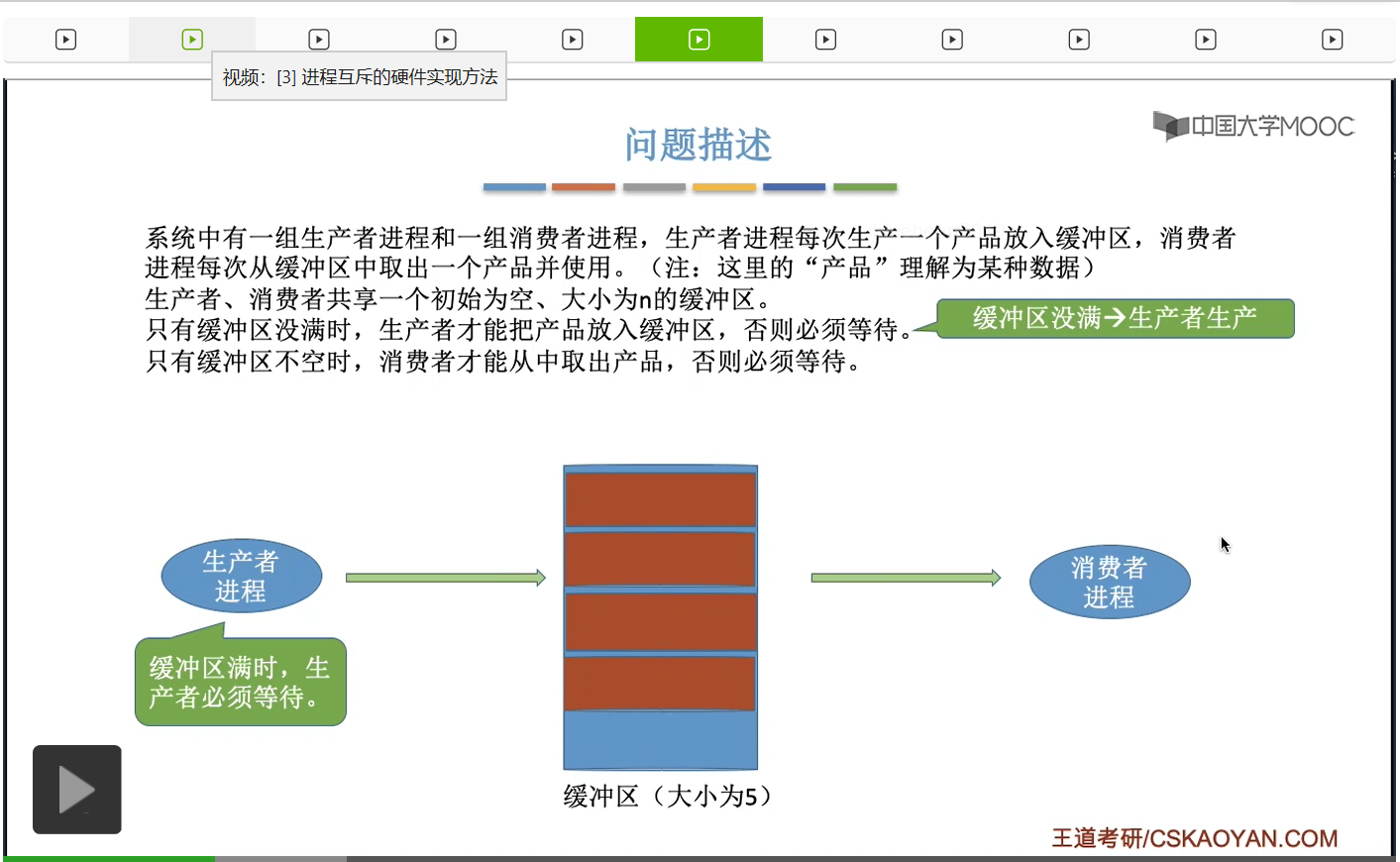
所以接下来有可能是消费者进程继续把缓冲区里的数据依次取走,那需要注意的是,只有缓冲区不空的时候,也就是说只有缓冲区里有数据有产品的时候,消费者进程才可以从缓冲区里取走数据,

不然的话消费者进程就必须阻塞等待,所以其实这个条件就是第二对的同步关系,也就是只有缓冲区没空的时候,或者说缓冲区里有产品的时候,消费者才可以取走数据,才可以消费。
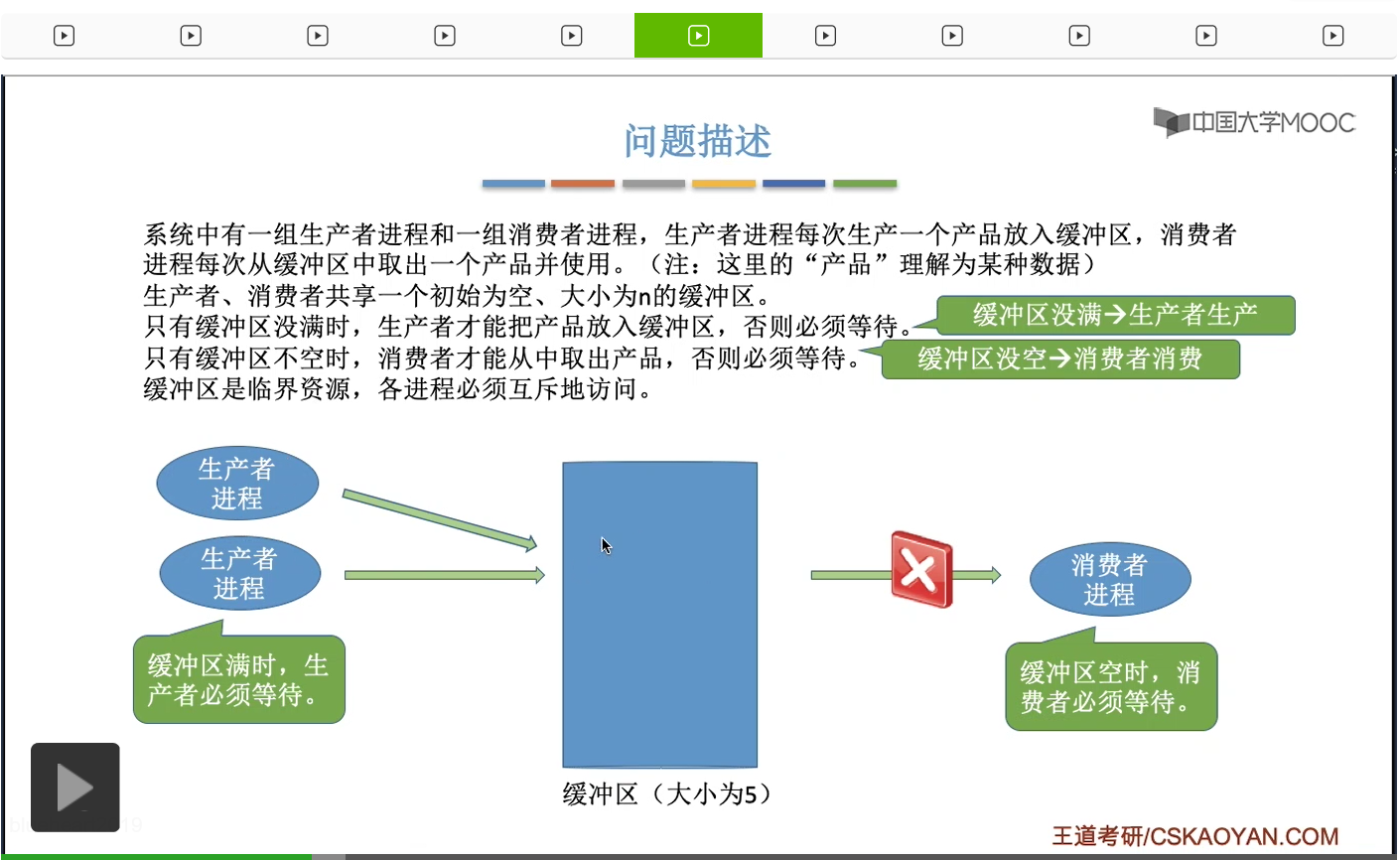
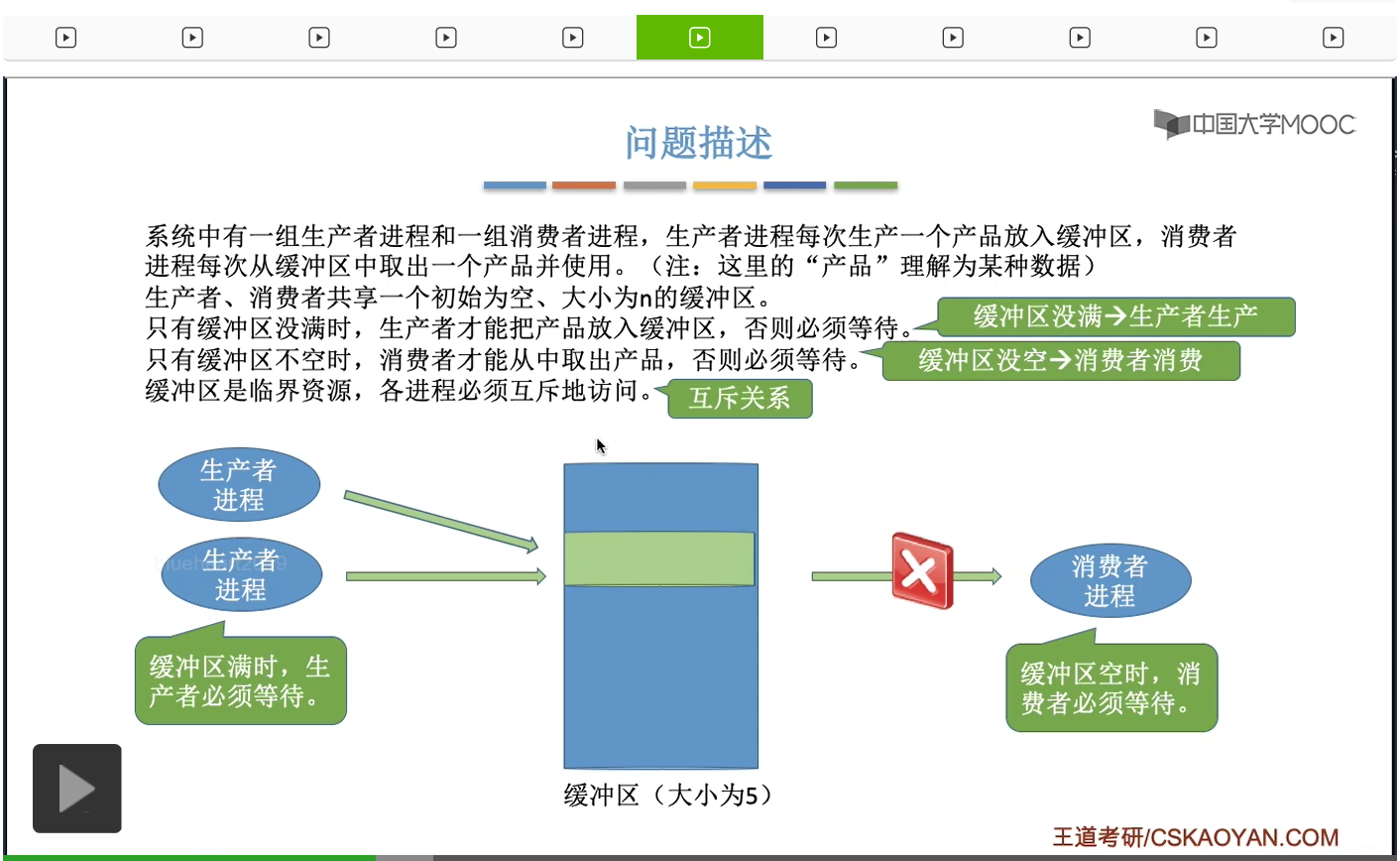
这个缓冲区它是一种临界资源,为什么必须互斥地访问缓冲区?
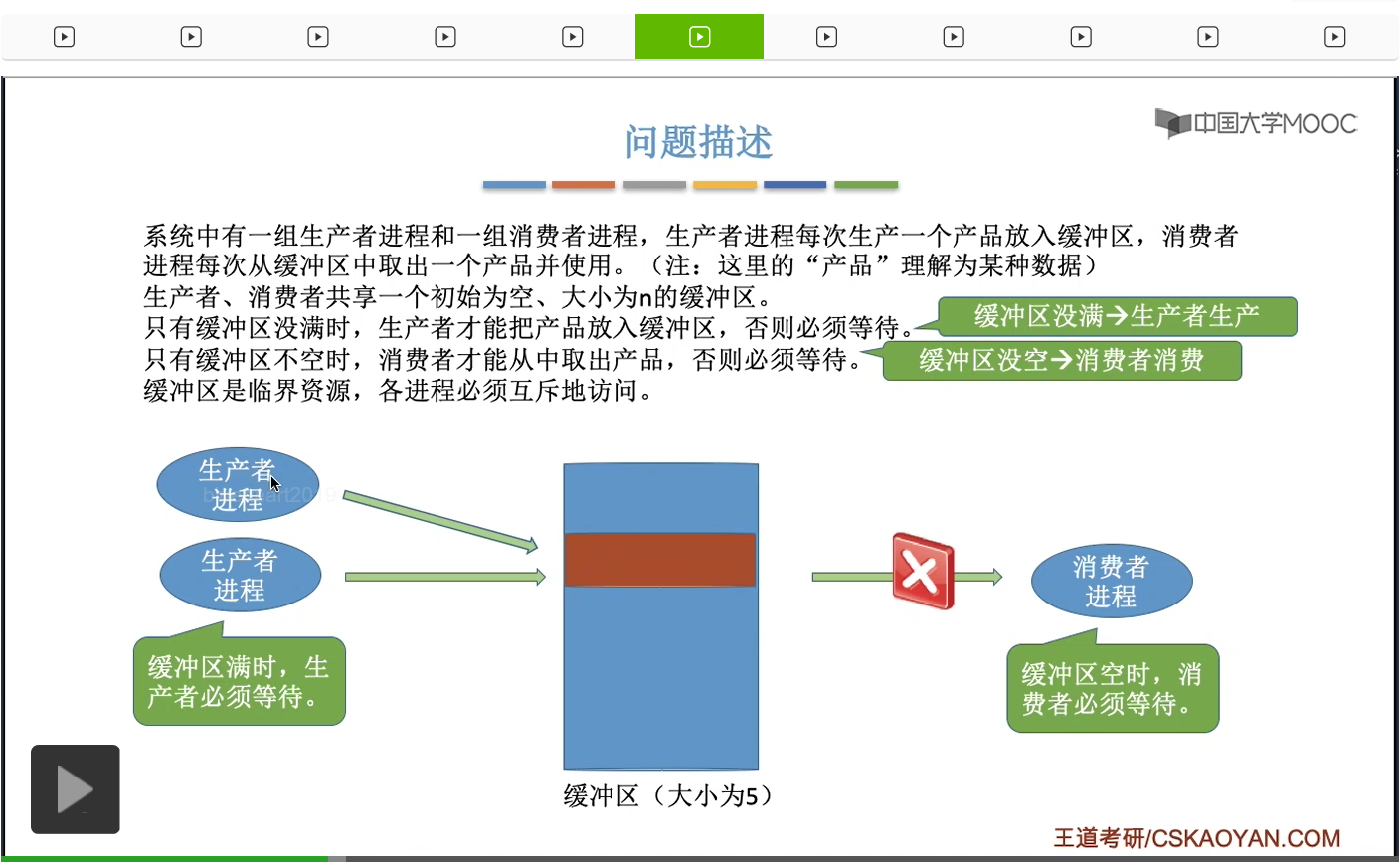
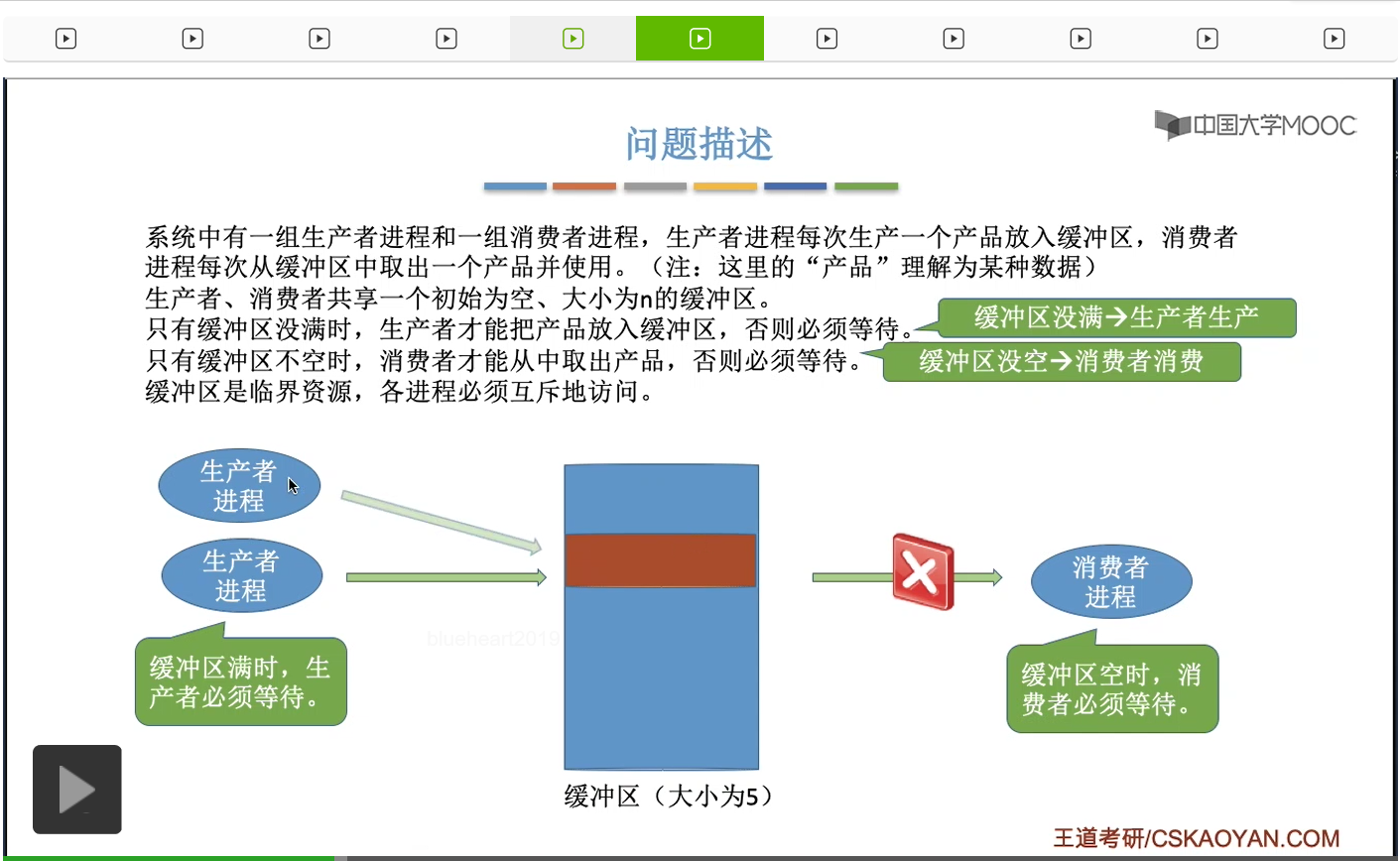
如果各个进程同时访问缓冲区的话,那么有可能会出现一系列的问题,比如说刚才我们提到的数据覆盖,所以缓冲区这种资源它是一种临界资源,各个进程必须互斥地访问。那么既然需要互斥地访问,这其实就是我们之前学过的互斥的问题。
第一对是前V后P。只有当缓冲区里有产品的时候,消费者进程它才可以消费。另外呢只有缓冲区没满的时候,生产者进程才可以生产,所以这样的两对一前一后的同步关系,我们就需要给它们分别设置一个同步信号量,并且在前面这个动作完成之后,需要对这个同步信号量执行一个V操作,在后面这个动作开始之前,需要对这个同步信号量执行一个P操作。那我们一会来解释一下这两个同步信号量它在背后的含义。那这是这两对同步关系里边PV操作的一个大致顺序。
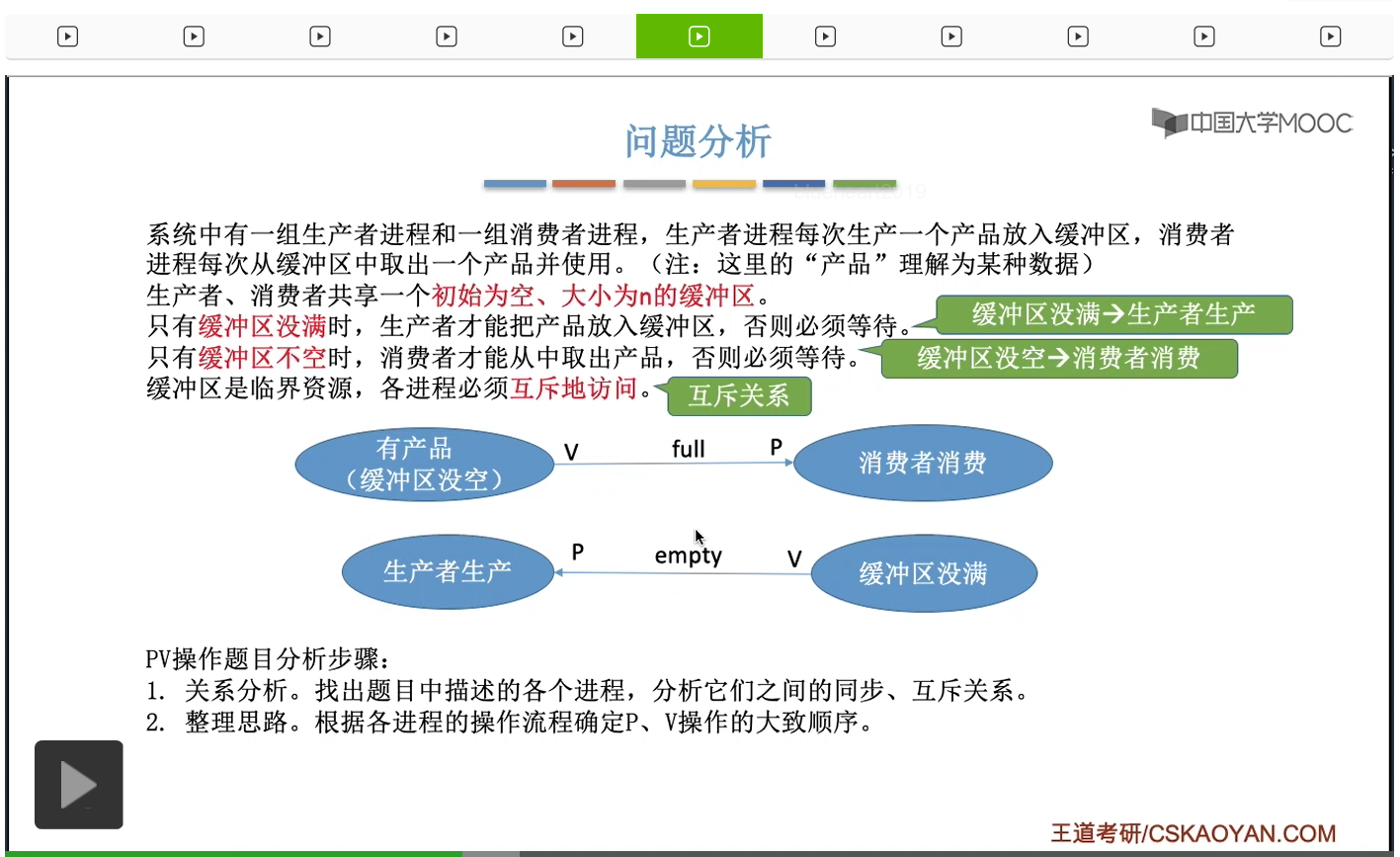
那缓冲区里有产品,这个事件是生产者进程触发的,也就是说当一个生产者进程往缓冲区里放入一个产品、放入一个数据之后,它就需要对这个信号量执行一个V操作。而当消费者进程从缓冲区里取走数据之前,它需要对这个信号量执行一个P操作。那下面的这个同步关系也一样。那除了这两对同步关系之外,我们还需要实现对缓冲区这种临界资源的互斥访问。那互斥的实现其实是很简单的,我们只需要设置一个互斥信号量mutex,并且让它的初始值为1,然后在临界区的前面和后面,分别对互斥信号量执行PV操作就可以了。那接下来我们应该做的就是要确定这些信号量的初始值,对于互斥信号量来说,一般初始值就是1,就像我们刚才所说的那样。而对于同步信号量来说,它的初始值我们要看它所对应的那种资源初始值是多少。那我们来看一下这两对同步关系所对应的这种资源到底是什么呢?
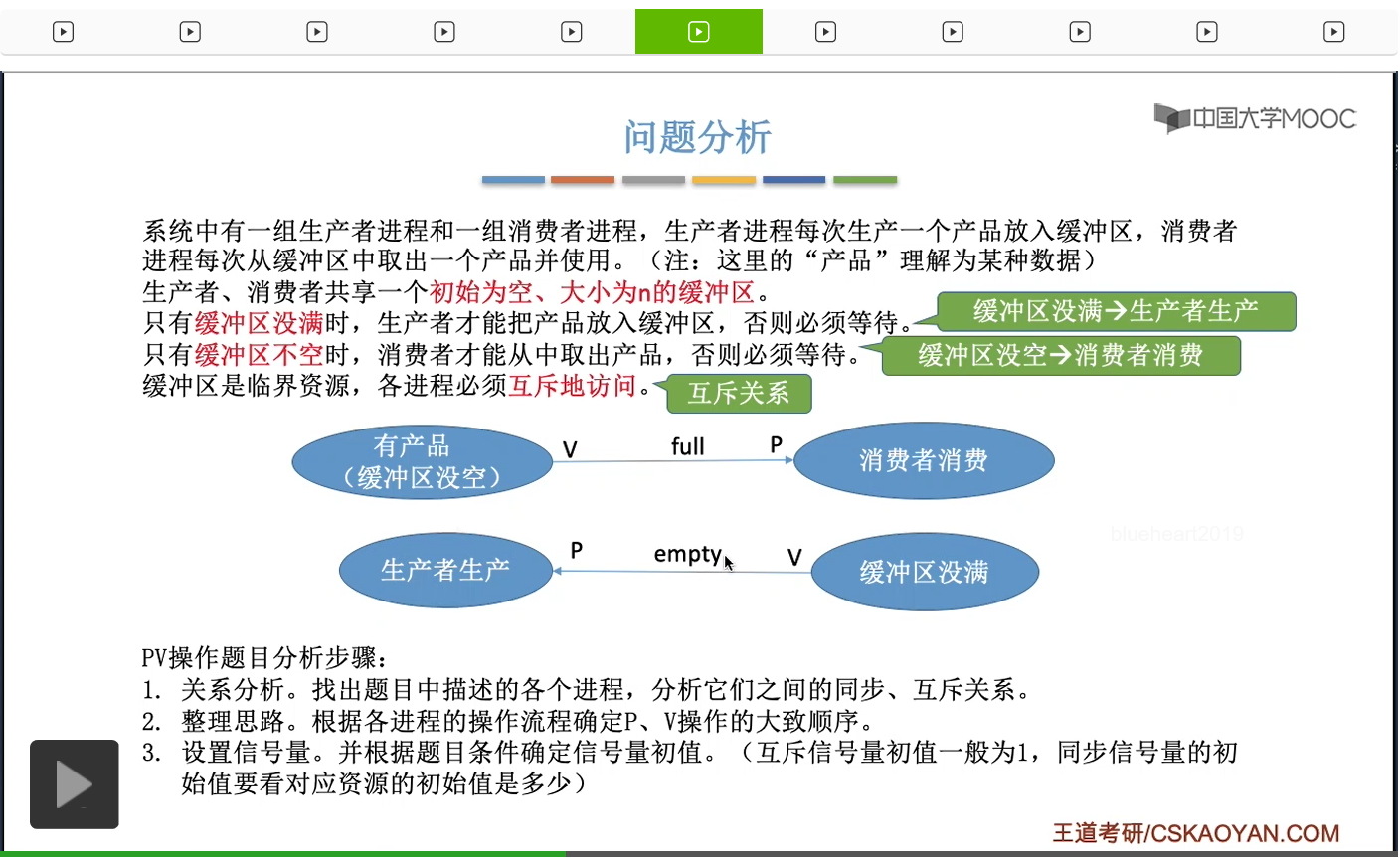
消费者进程它在消费之前需要消耗什么资源呢?需要消耗的是产品,所以它的这个P操作其实是在申请一个产品,申请一个数据,因此full这个同步信号量它所对应的资源应该是产品的数量,也就是非空缓冲区的数量。而从题目当中给的条件我们知道,缓冲区刚开始都是空的,也就是说刚开始产品的数量、产品这种资源的数量应该是0。因此full这个同步信号量的初始值我们就把它设置为0,表示刚开始没有产品这种资源,而这种资源只能由生产者进程生产了之后来释放。那再来看第二个同步信号量empty。那我们知道生产者进程每生产一个产品就需要消耗一个空闲的缓冲区,因此empty这个同步信号量它所对应的资源就应该是空闲缓冲区这种资源,它的数量就是空闲缓冲区的数量。当一个消费者进程取走了产品,也就是做了消费的动作之后,它就可以释放一个empty,也就是释放一个空闲的缓冲区。那从题目给的条件我们知道,刚开始缓冲区都是空的,有n个缓冲区,因此空闲缓冲区它的初始值应该是n,所以这样我们就确定了这两个同步信号量的一个初始值。

那接下来就是代码的实现。生产者进程在把产品放入缓冲区之前,需要申请一个空闲的缓冲区,因此当它放入产品之前,需要对empty这个同步信号量执行一个P操作。而当它把产品放入缓冲区之后,其实就相当于产品这一种资源的数量加1了,或者说非空缓冲区的数量加1了,因此当它放入产品之后需要对这个信号量执行一个V操作,表示增加一个这种资源。而消费者进程的分析也类似,当它从缓冲区取走一个产品之前,需要先对这个full变量进行一个P操作,也就是要申请消耗一个产品这种资源。而当它取走了一个产品之后,空闲缓冲区的数量就会加1,因此在这个操作之后需要对empty进行一个V操作,表示要增加一个空闲缓冲区。那这样我们就实现了两对同步关系。另外题目中要求缓冲区必须互斥地访问,它是临界资源,所以在访问缓冲区前后分别要对mutex这个互斥信号量执行P和V操作,用于实现对缓冲区的互斥访问。实现互斥的P、V操作,它是在同一个进程内进行的。这个进程对临界区上了锁,而当它访问完临界区之后,又需要对这个临界区进行解锁,所以这个P、V操作是在同一个进程的代码当中实现的。而同步关系就不一样了,生产者进程里边是对full变量执行了V操作,而消费者进程里边是对full变量执行了P操作,也就是对同一个变量的P、V这两个操作,是分别需要在不同的两个进程之间执行的。执行V操作的这个进程,会唤醒相对应的执行P操作的这个进程。自己体会一下前V后P。
这种情况就是我们之后会学习到的死锁。进程和进程之间发生了循环等待,被对方唤醒这样的一个神奇的情况。V操作的顺序颠倒是不会出现问题的,因为V操作并不会导致任何一个进程阻塞,所以它们俩个顺序颠倒并不会发生这种循环等待的问题,所以俩个V操作的顺序是可以交换的。生产者生产一个产品和消费者使用一个产品是否可以放到PV操作之间呢?其实逻辑上看是可以放到PV操作这里边的,但是如果我们把这两部分的处理都放到PV操作里边的话,那么就会导致临界区代码变得更长,也就是说一个进程对临界区上锁的时间会增长,那这样的话肯定不利于各个进程交替地来使用这个临界区资源,所以我们要让临界区的代码尽可能地短,因此逻辑上来看,把这两个部分放进去是没有问题的,但是实际上会对系统的效能产生影响,因此并不建议把这两个部分的操作放到PV操作里边。

好的那么这个小节当中我们介绍了一个很经典的进程的同步互斥问题,就是生产者-消费者模型。对于初学者来说最难的是发现题目中隐含的两对同步关系,有时候是生产者进程在等待消费者进程,有的时候又是消费者进程需要等待生产者进程,所以这是这个题目当中的难点,它是两对不同的、一前一后的这种关系,所以我们相应的也需要给它们设置两对不同的信号量,但是对这些信号量的操作肯定都是遵循一个前V后P的这个原则。另外还需要再强调一遍的是,实现互斥和实现同步是两个不同的P操作,而实现互斥的那个P操作,一定要在实现同步的P操作之后,否则会导致死锁的问题。我们不会再像之前一样,每一个同步信号量都来分析它背后的含义,这个需要大家自己去练习和体会。

在这个小节中我们会学习一个多生产者-多消费者的这样一个问题模型。



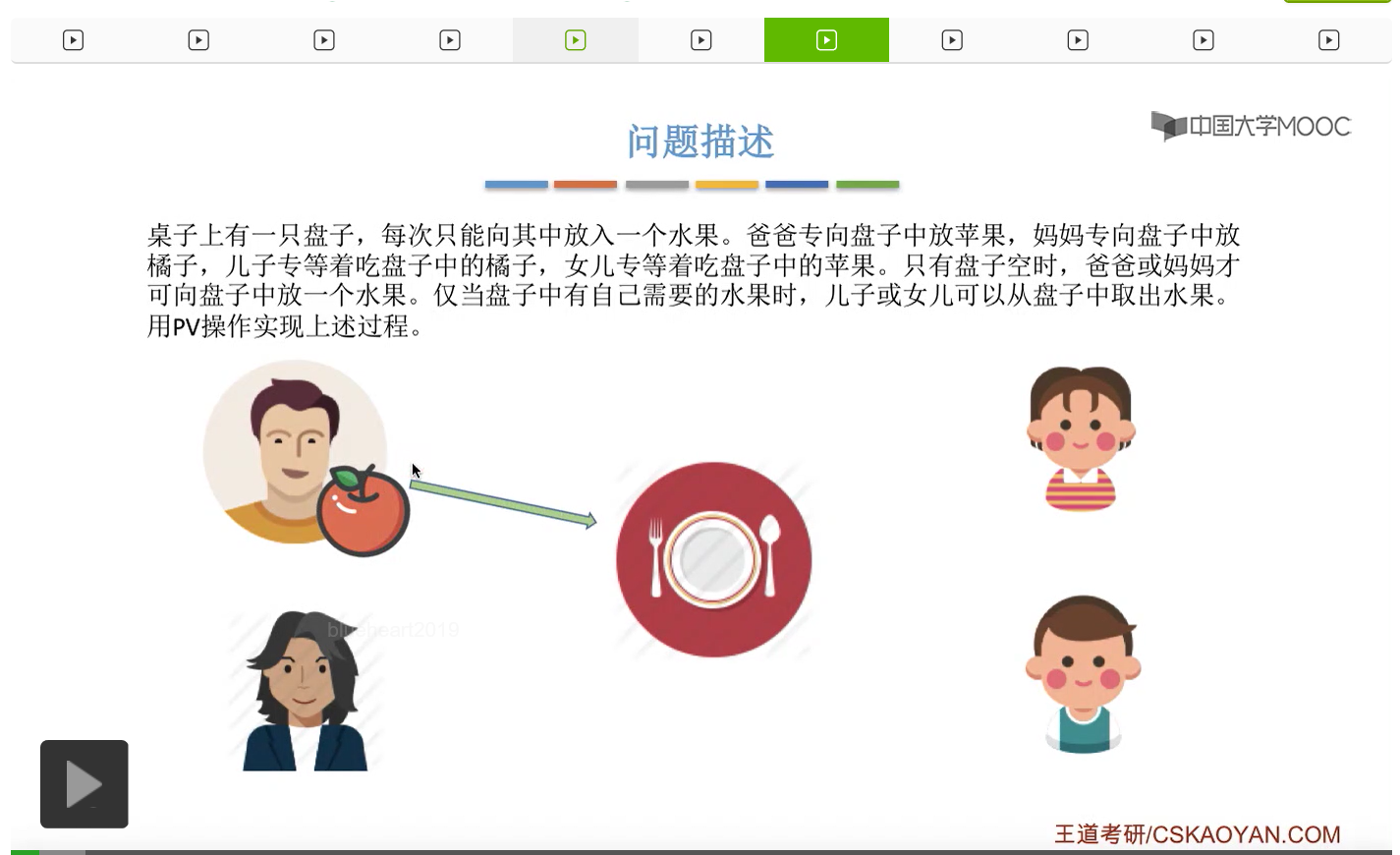
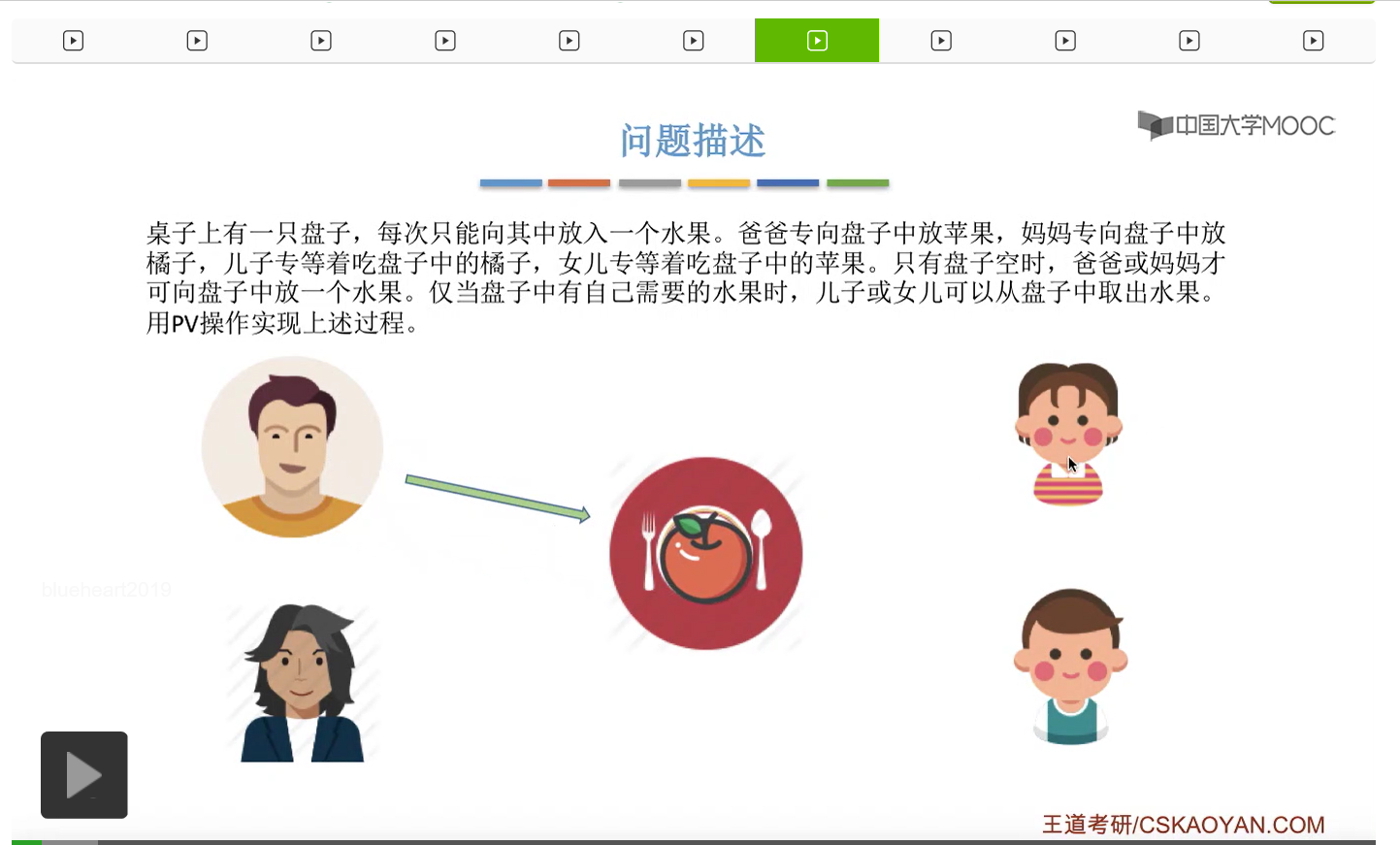
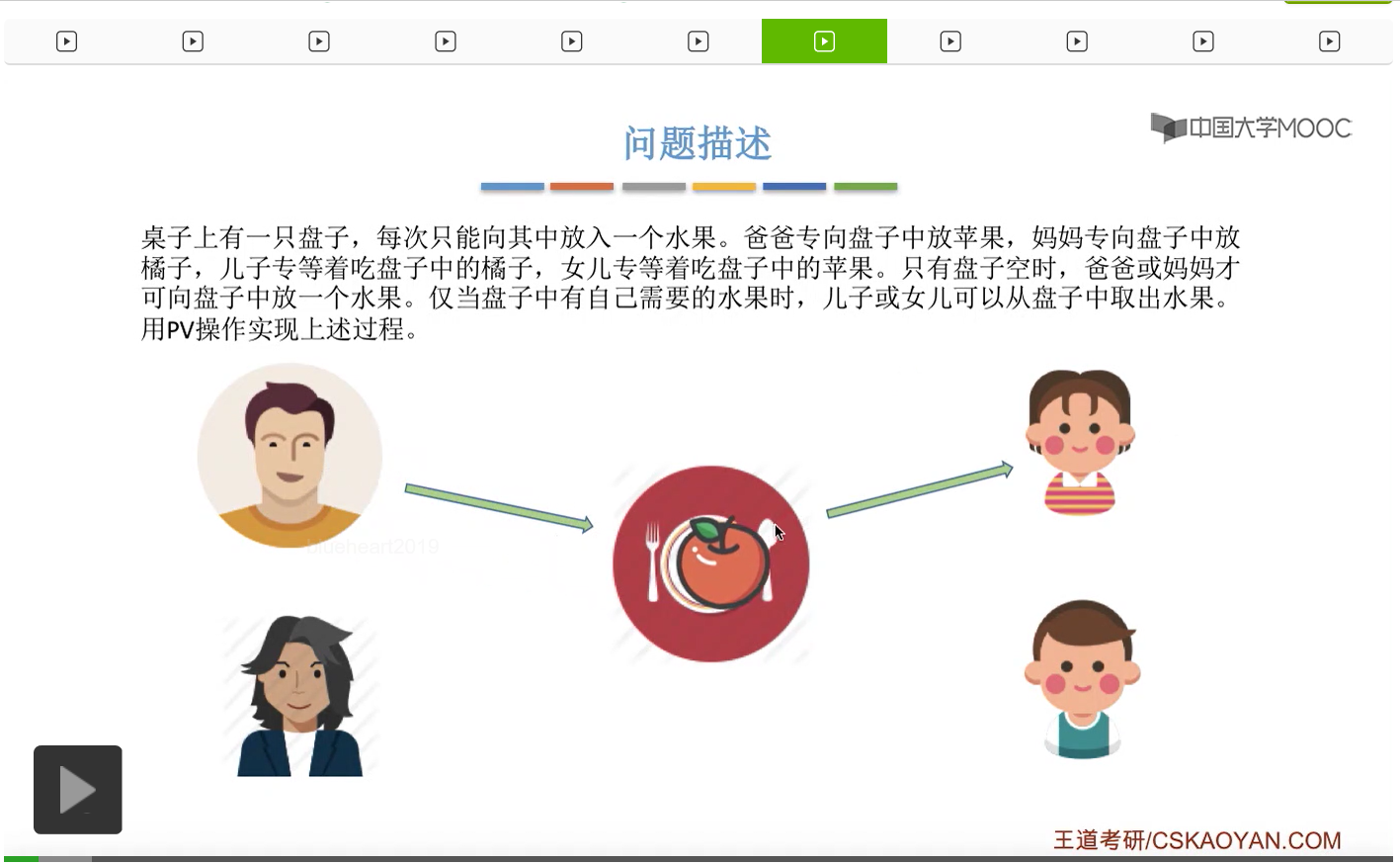
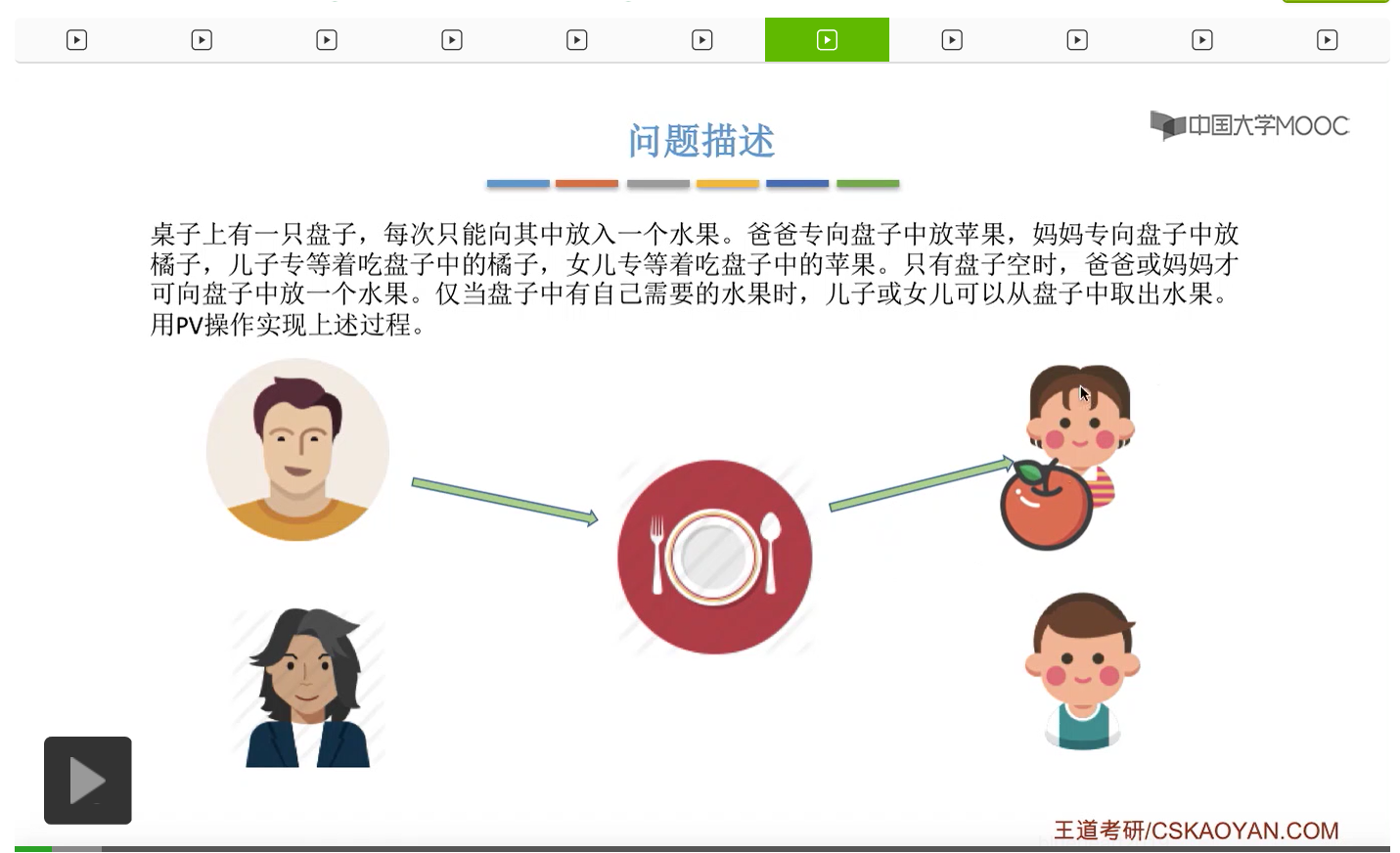
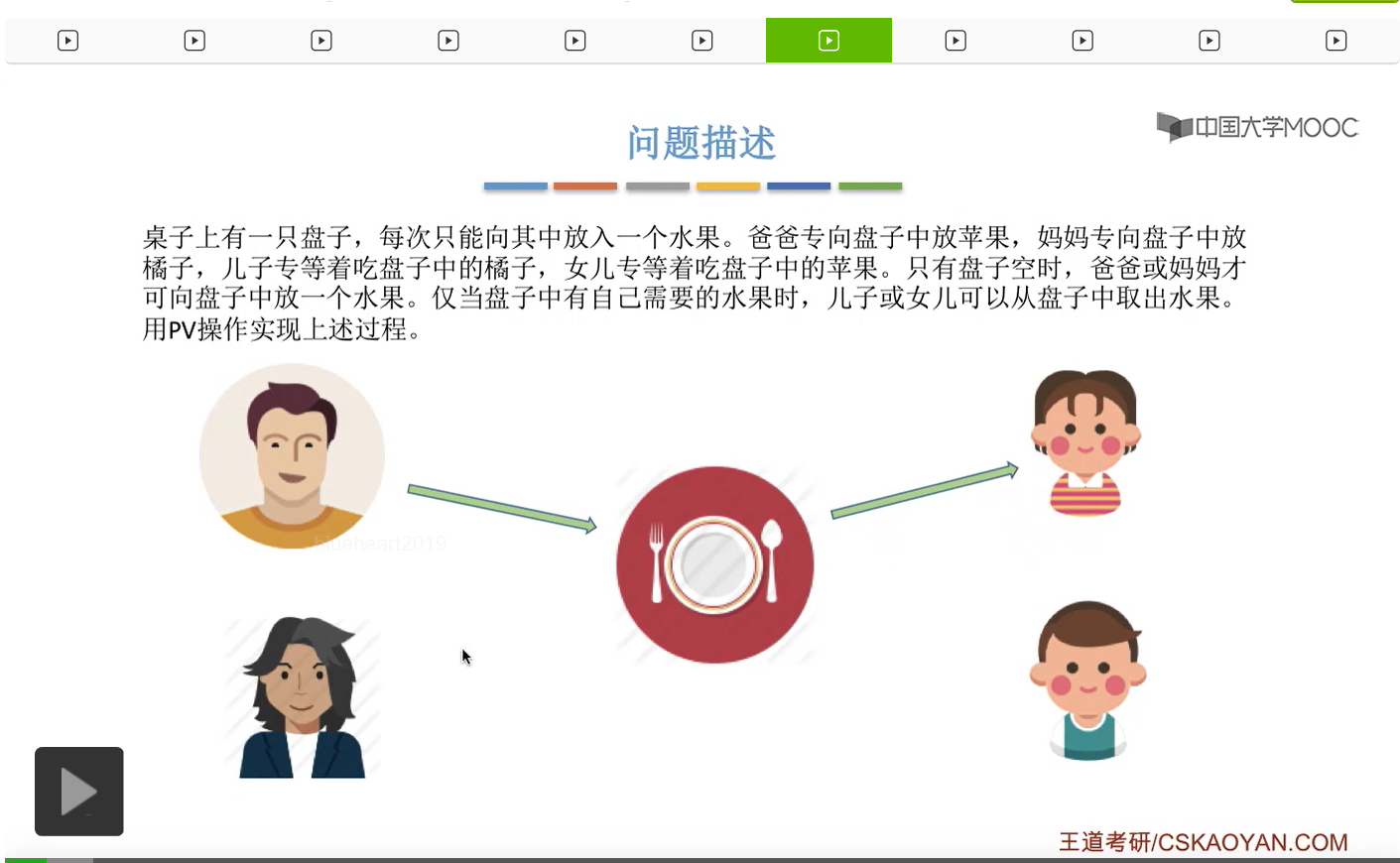
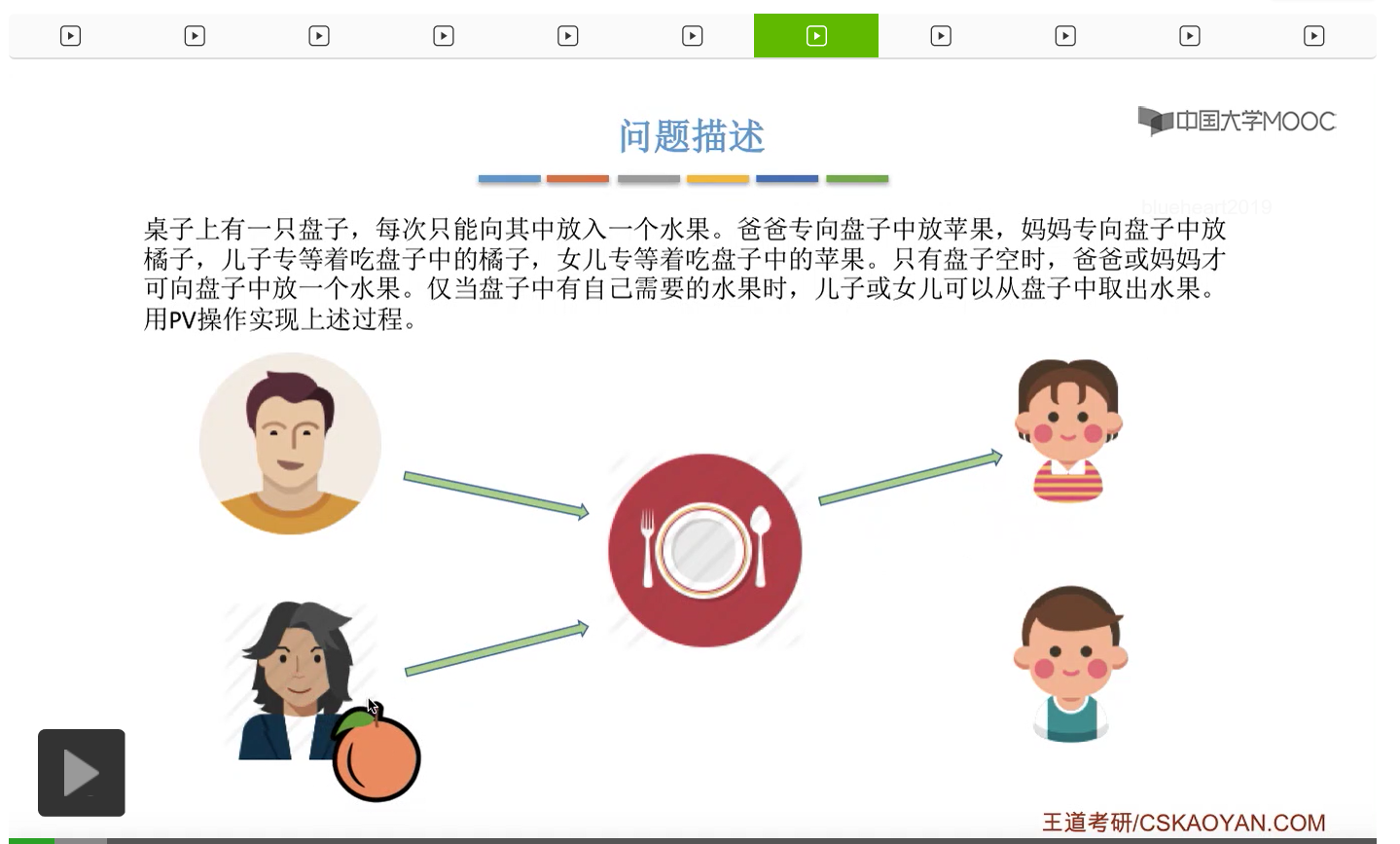
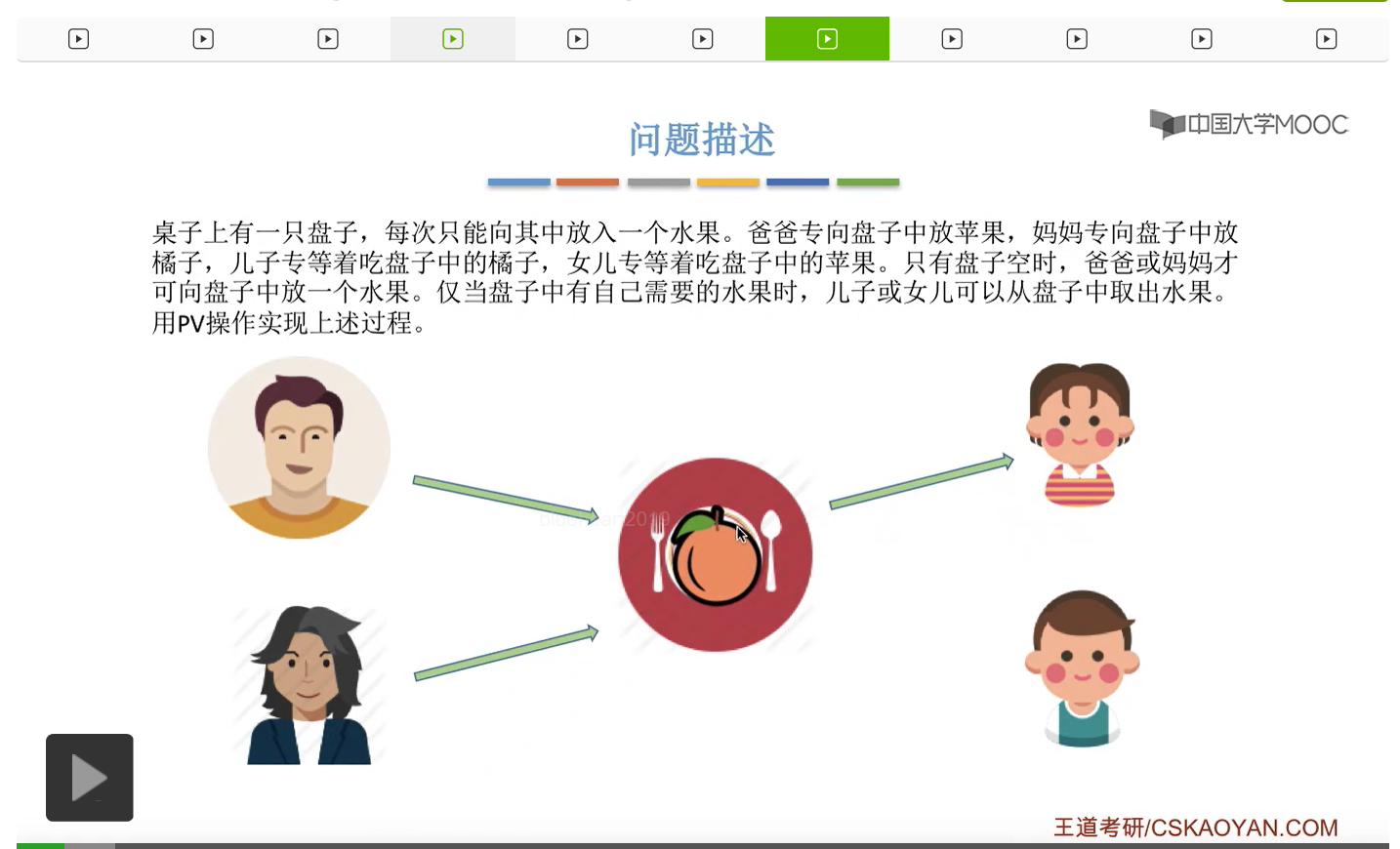
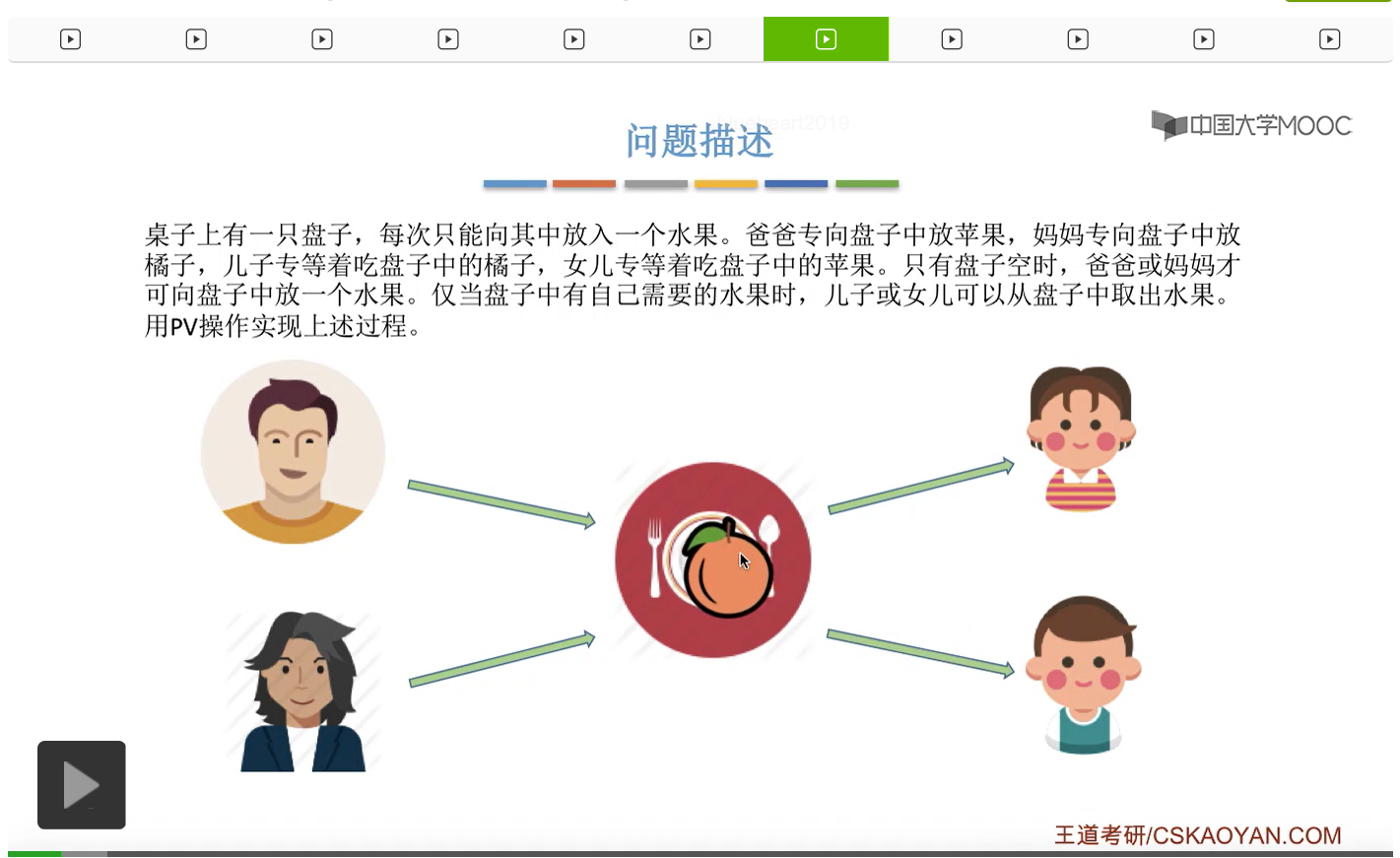
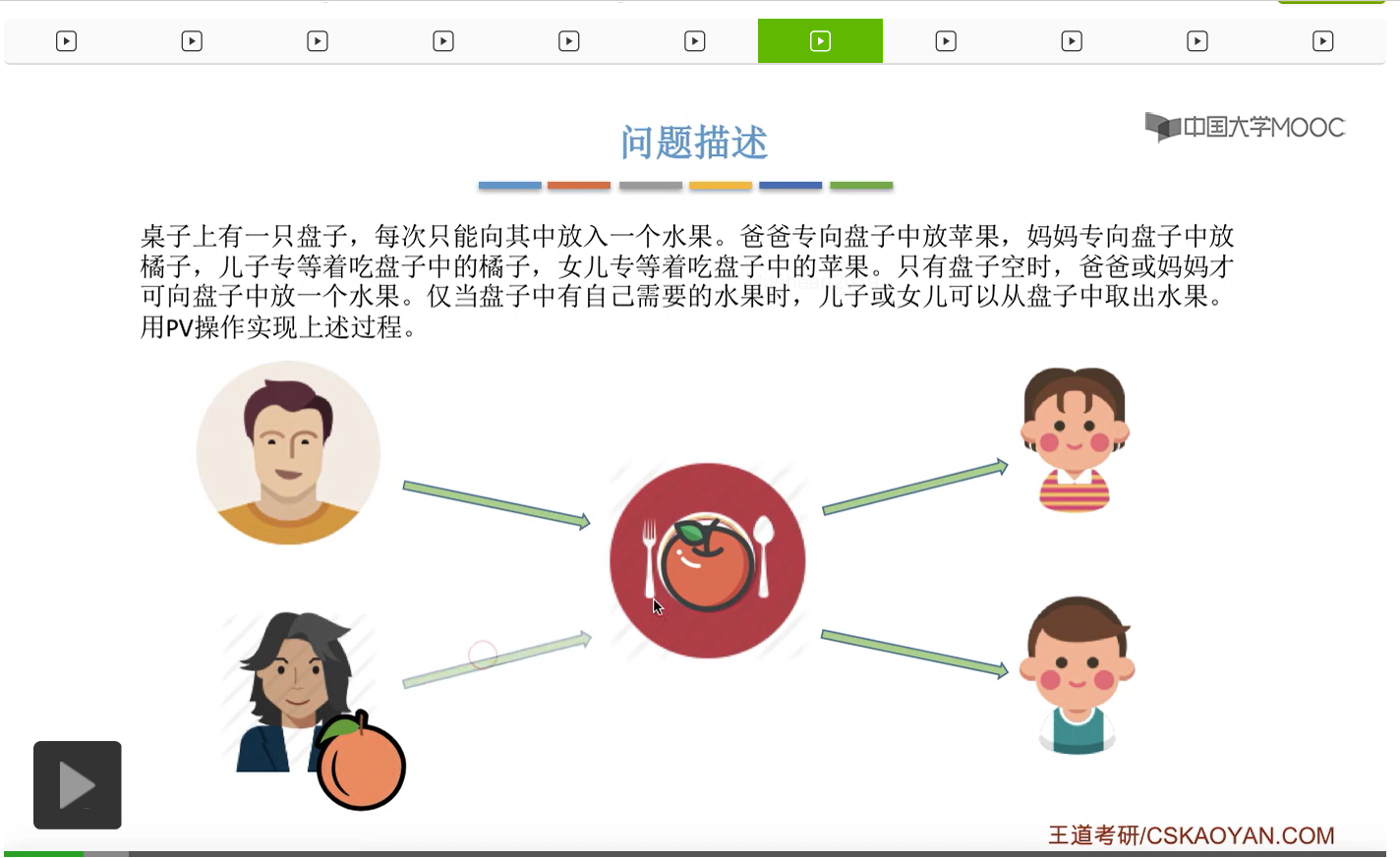
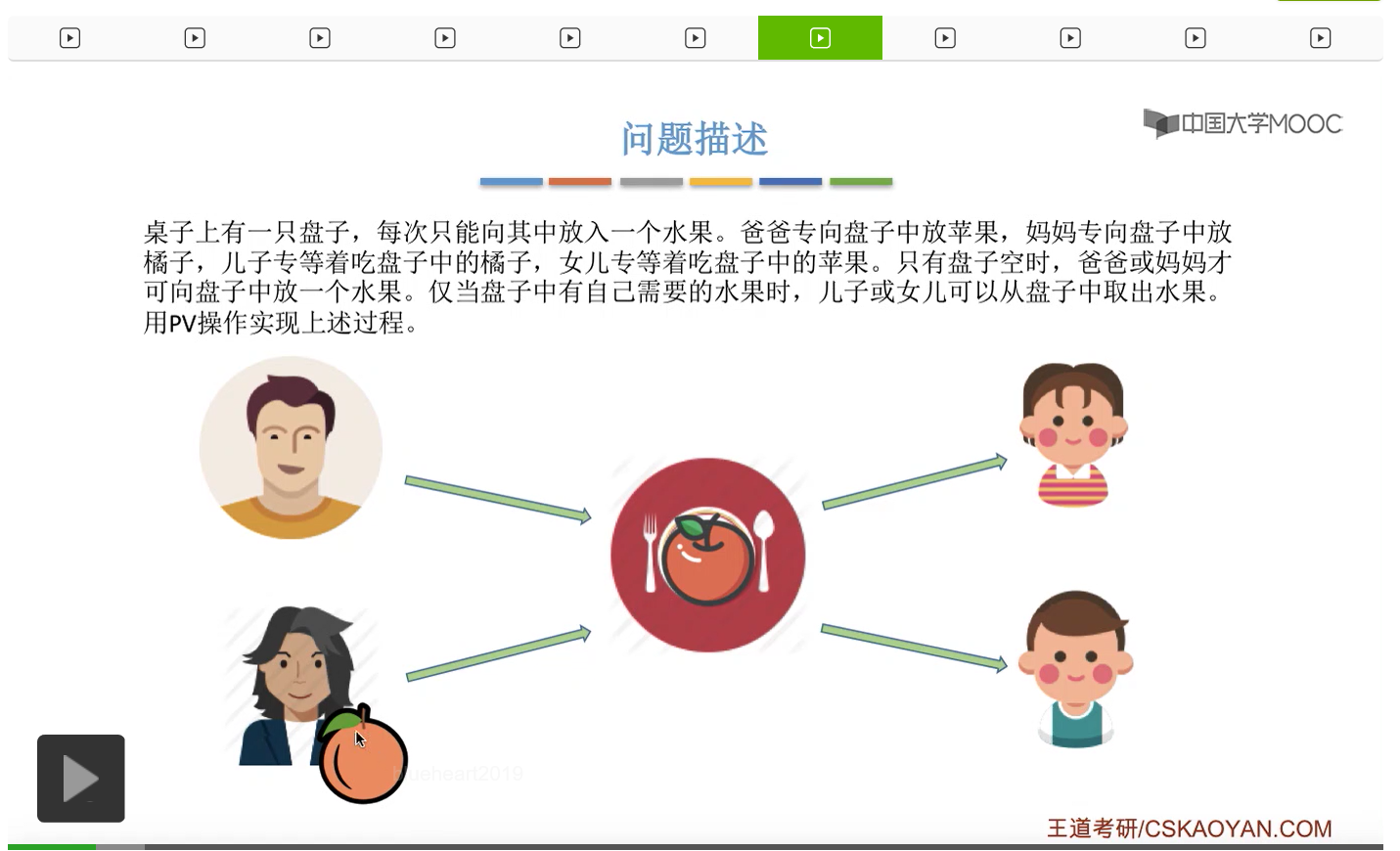
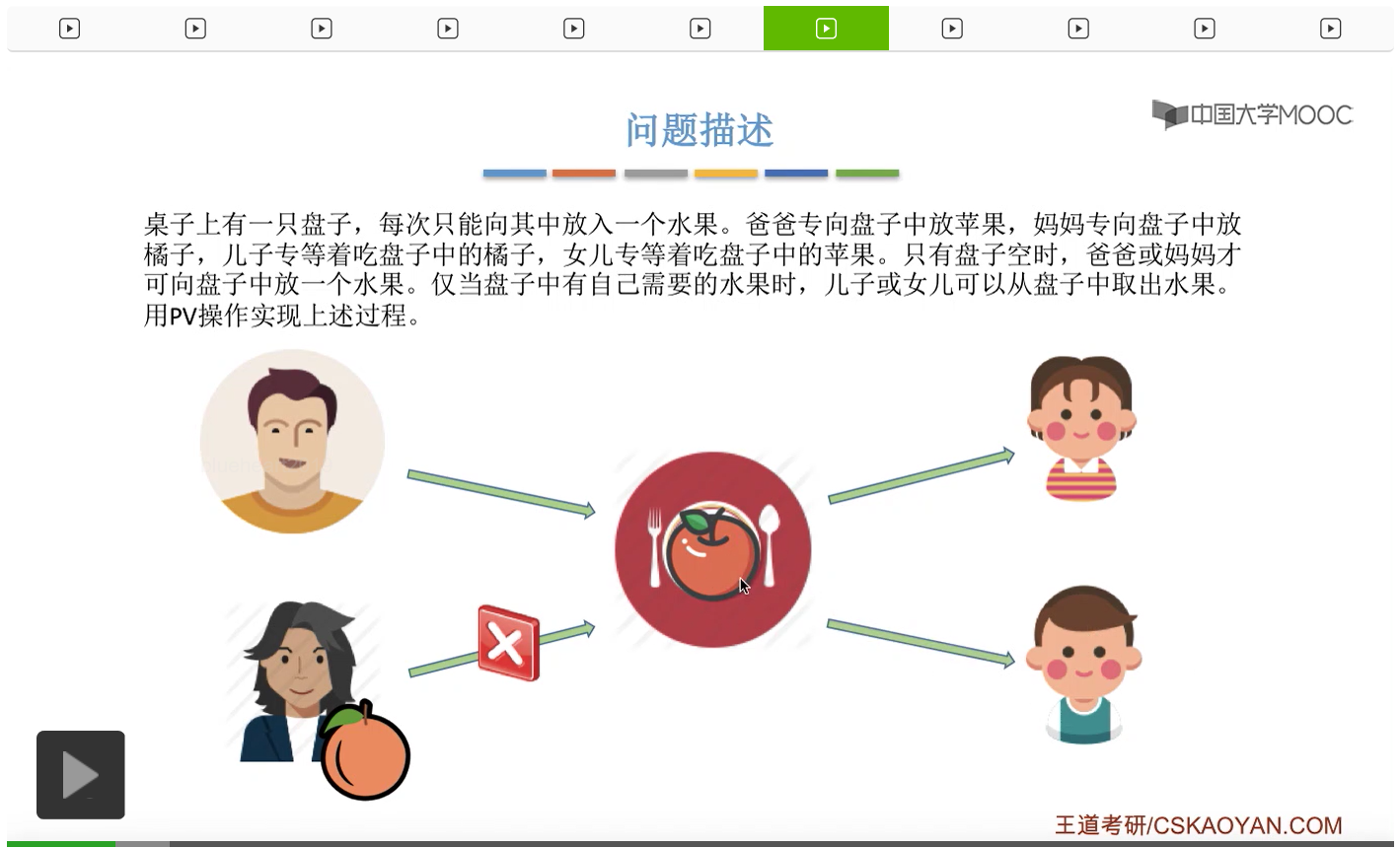
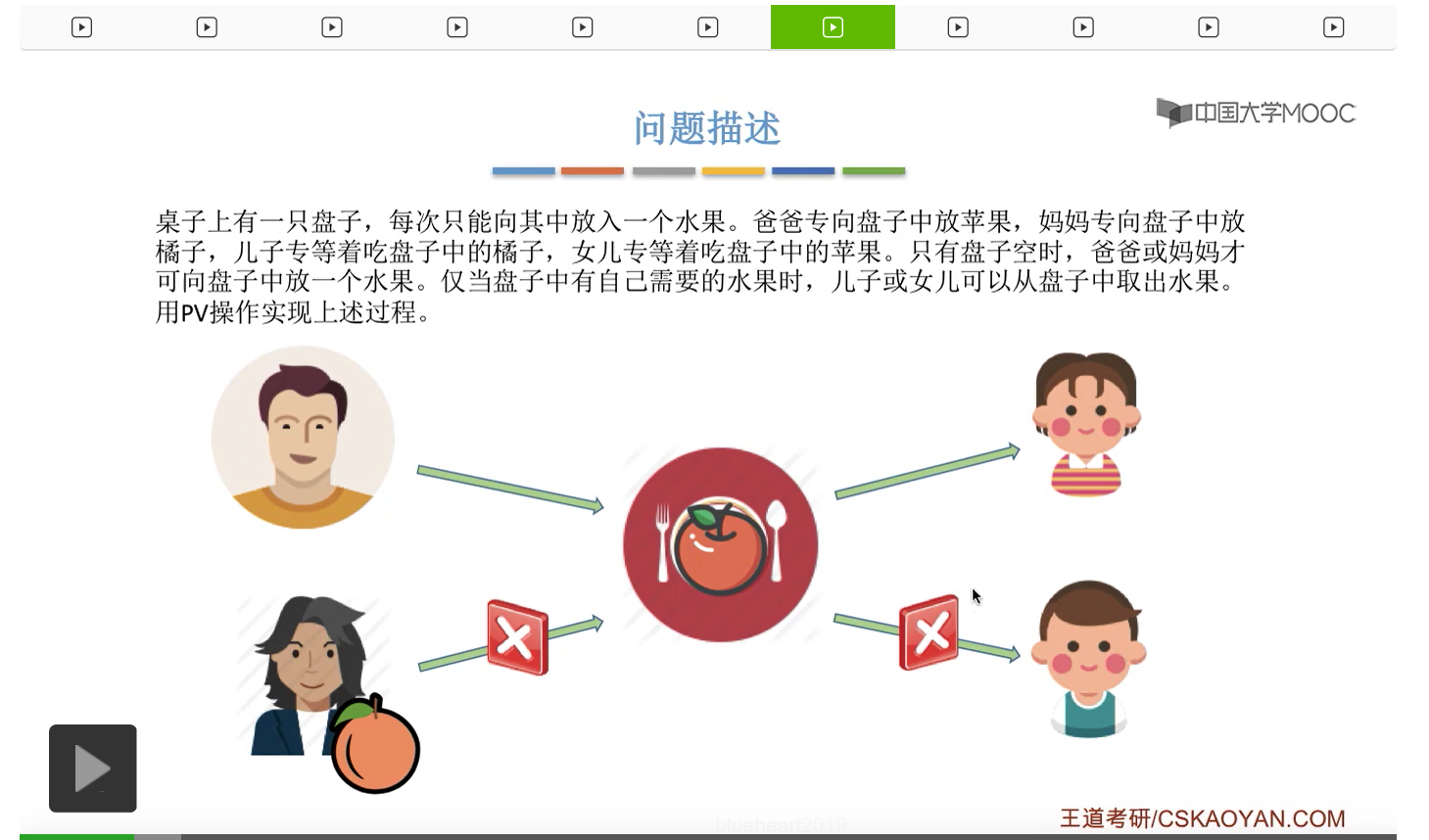
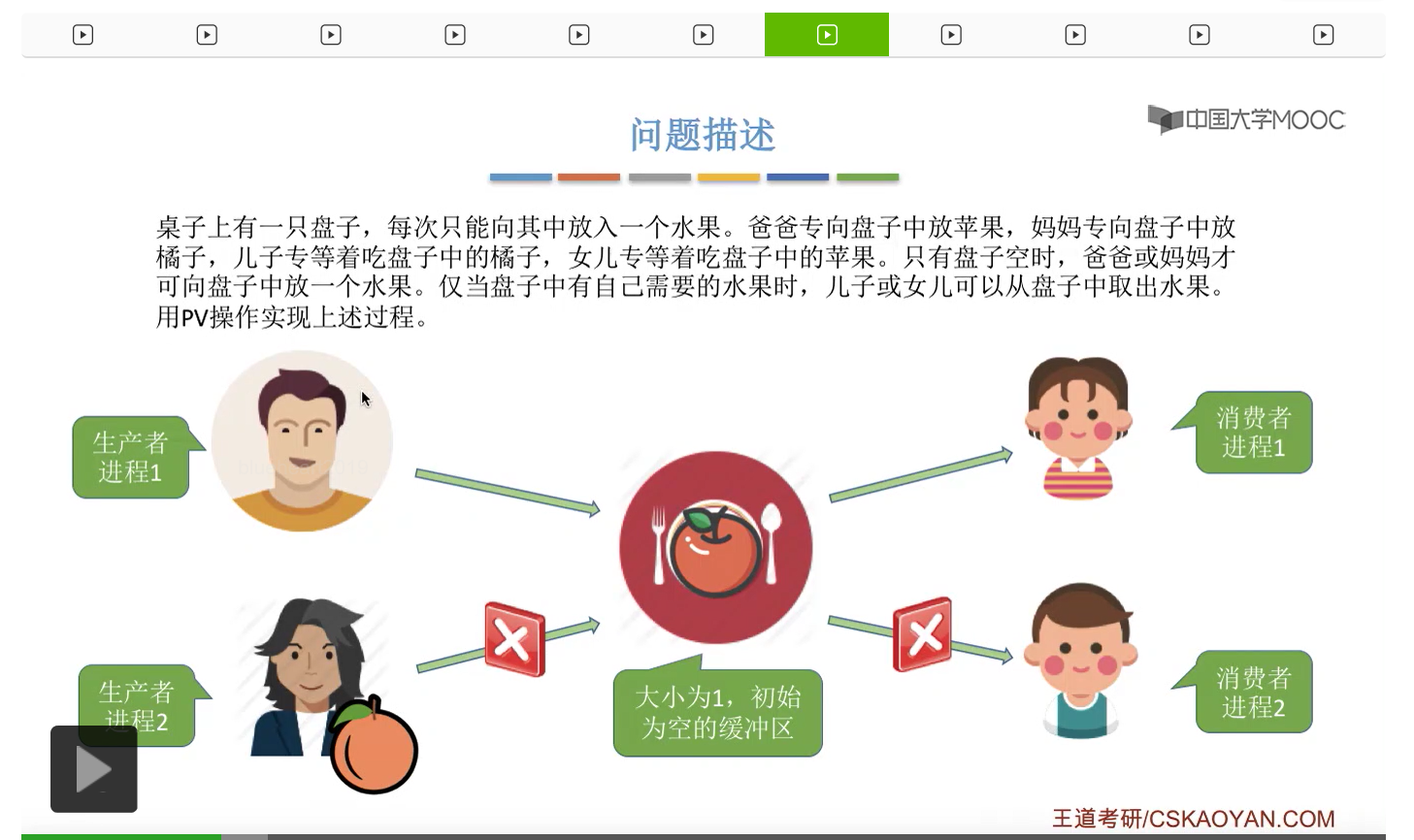
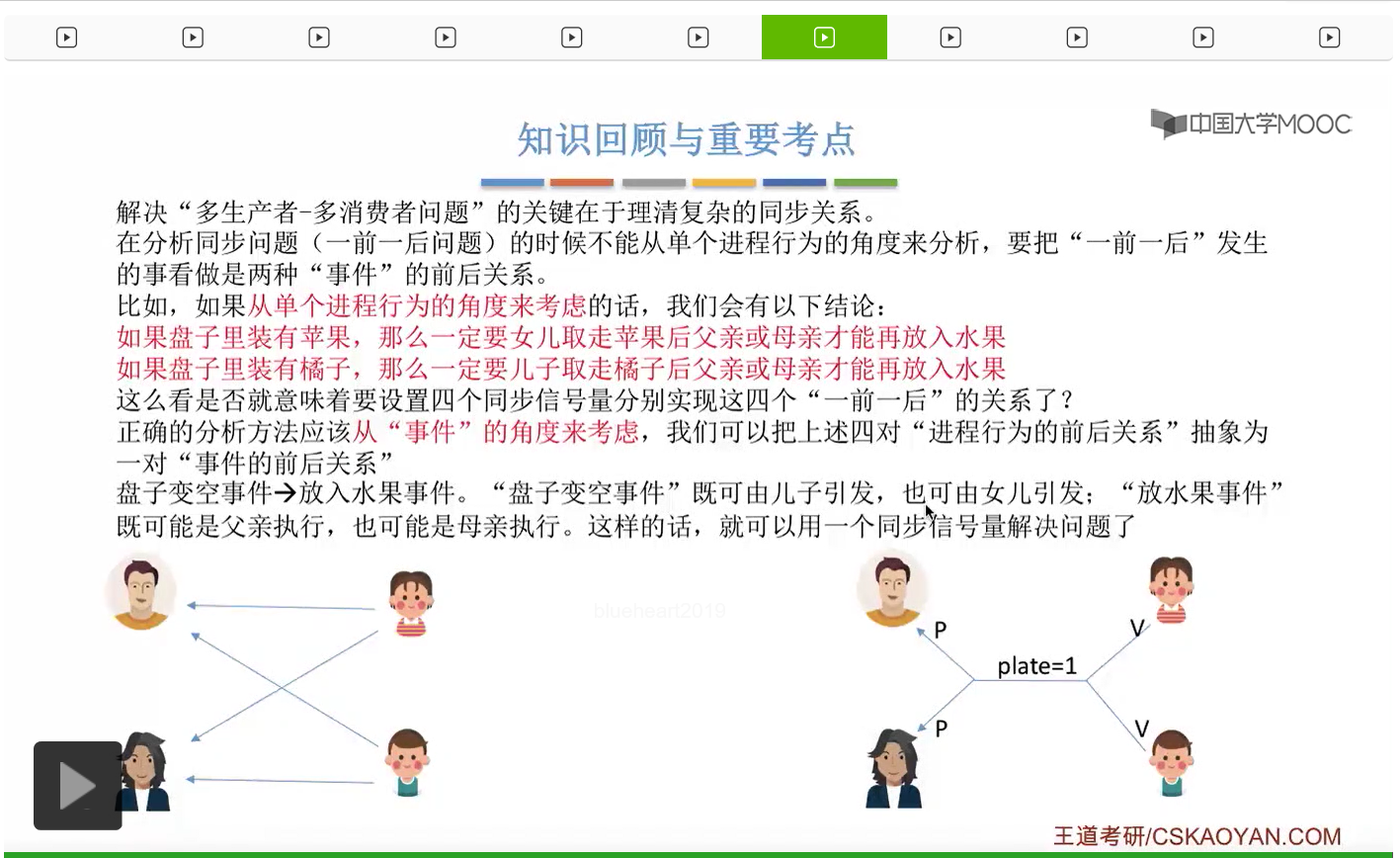
而上一节我们聊过,对于缓冲区的访问,一般来说都需要互斥地进行,所以我们需要实现对盘子这种缓冲区的互斥访问。另外,是否存在这种一前一后的同步关系呢?首先父亲要将苹果放入盘子之后,女儿才能取到苹果,所以父亲进程和女儿进程它们之间有一对同步关系。另外,母亲要把橘子放入盘子之后,儿子才可以取到橘子,所以他们两之间也存在一对同步关系。第三,只有盘子为空的时候,父亲或母亲才可以把水果放到盘子当中,而这个地方的盘子为空这个事件,其实既可以由儿子触发,也可以由女儿触发。假如说盘子里放的是橘子,那么盘子为空这个事件就应该由儿子来触发,由儿子取走橘子。而如果说盘子里放的是苹果的话,那就应该由女儿取走苹果,然后由女儿来触发盘子为空这个事件。而只有盘子为空这个事件发生之后,才能允许父亲进程或者母亲进程往盘子里放入水果。我们知道实现互斥其实很简单,无非就是在访问这个临界资源之前和访问临界资源之后,分别对互斥变量实行一个P操作和一个V操作。而实现同步关系其实我们之前也说过,我们只需要遵循一个原则,就是所谓的前V后P,也就是前面的这个事件发生了之后,我们需要执行一个V操作,而后面的这个事件发生之前,我们需要执行一个P操作。

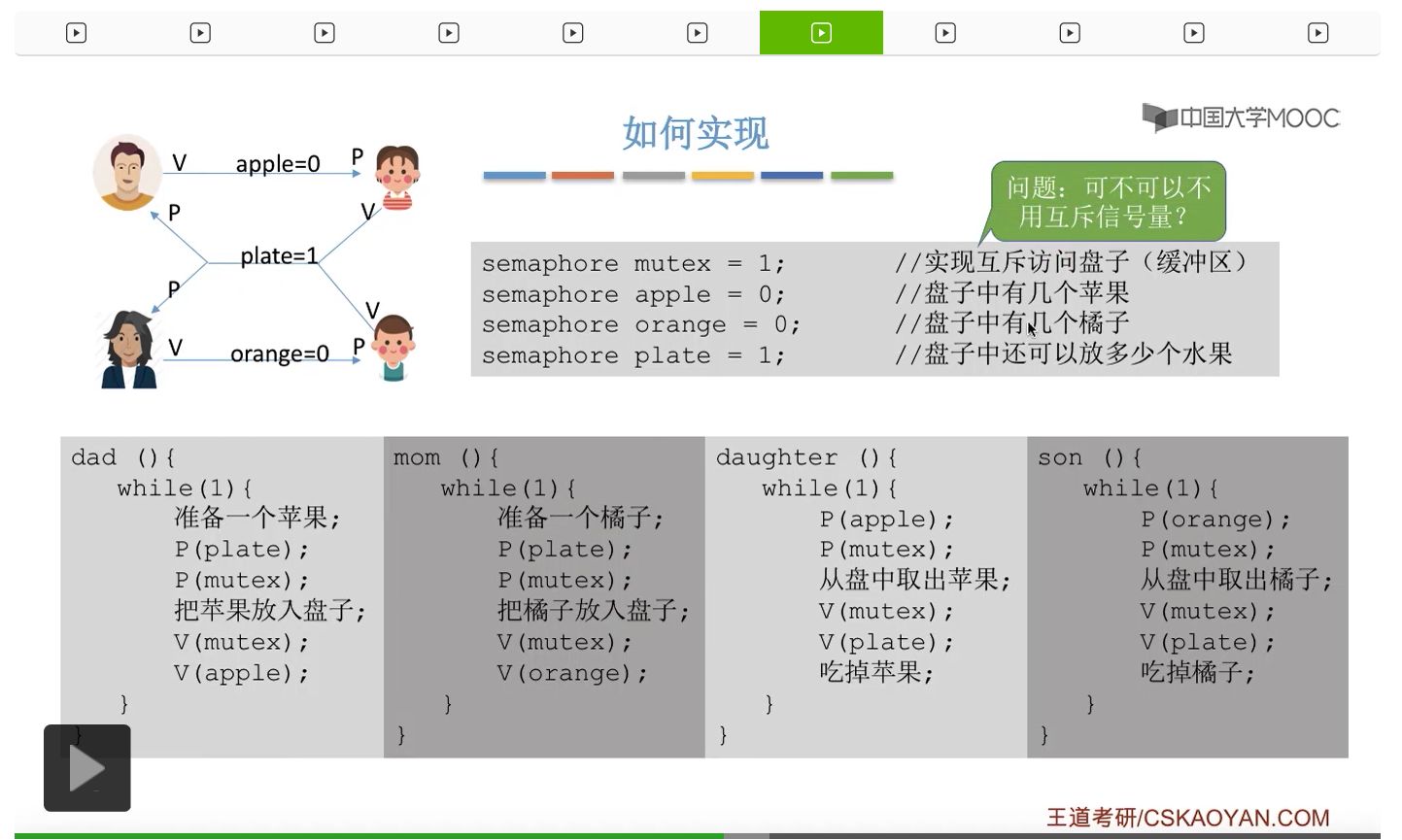
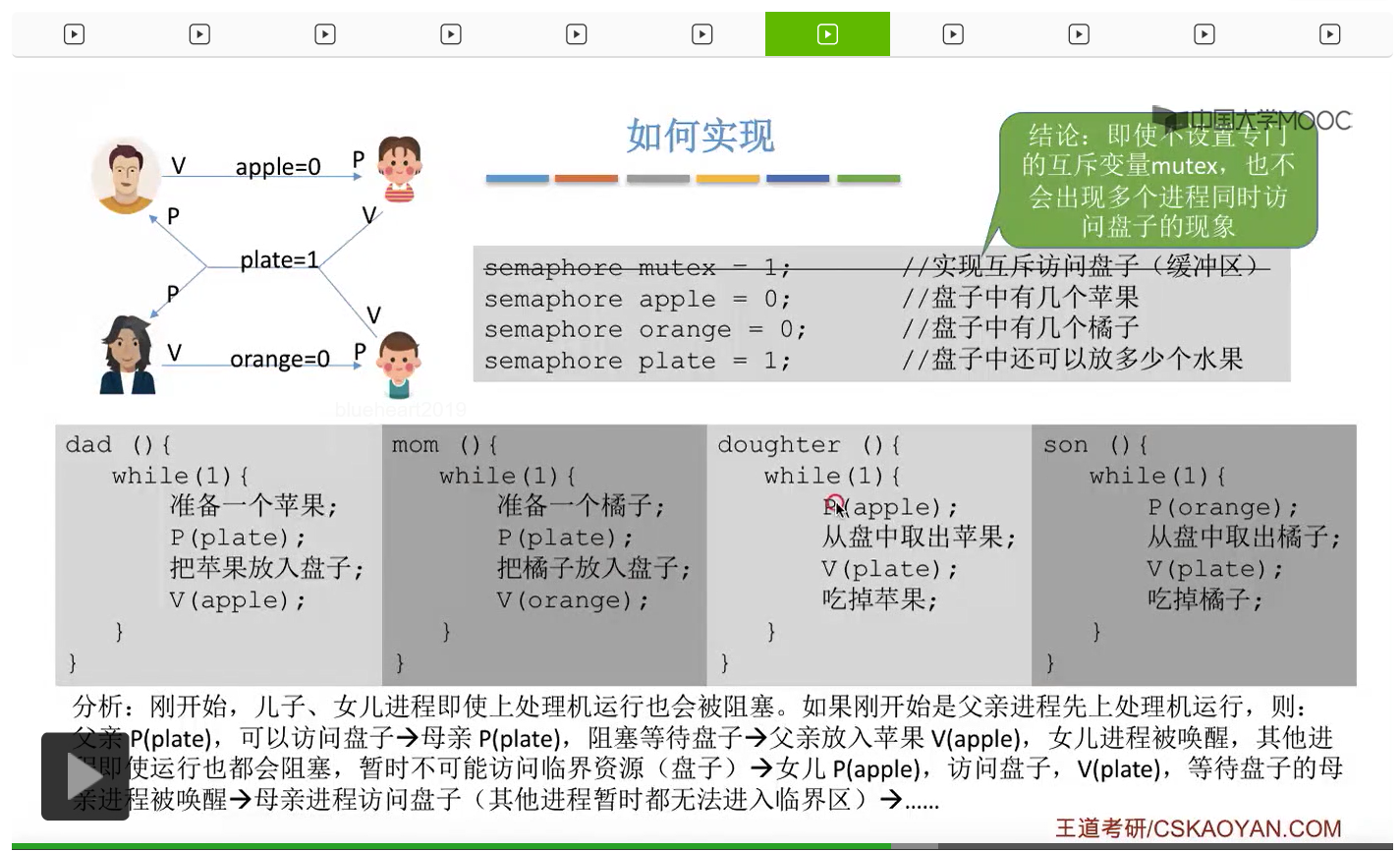
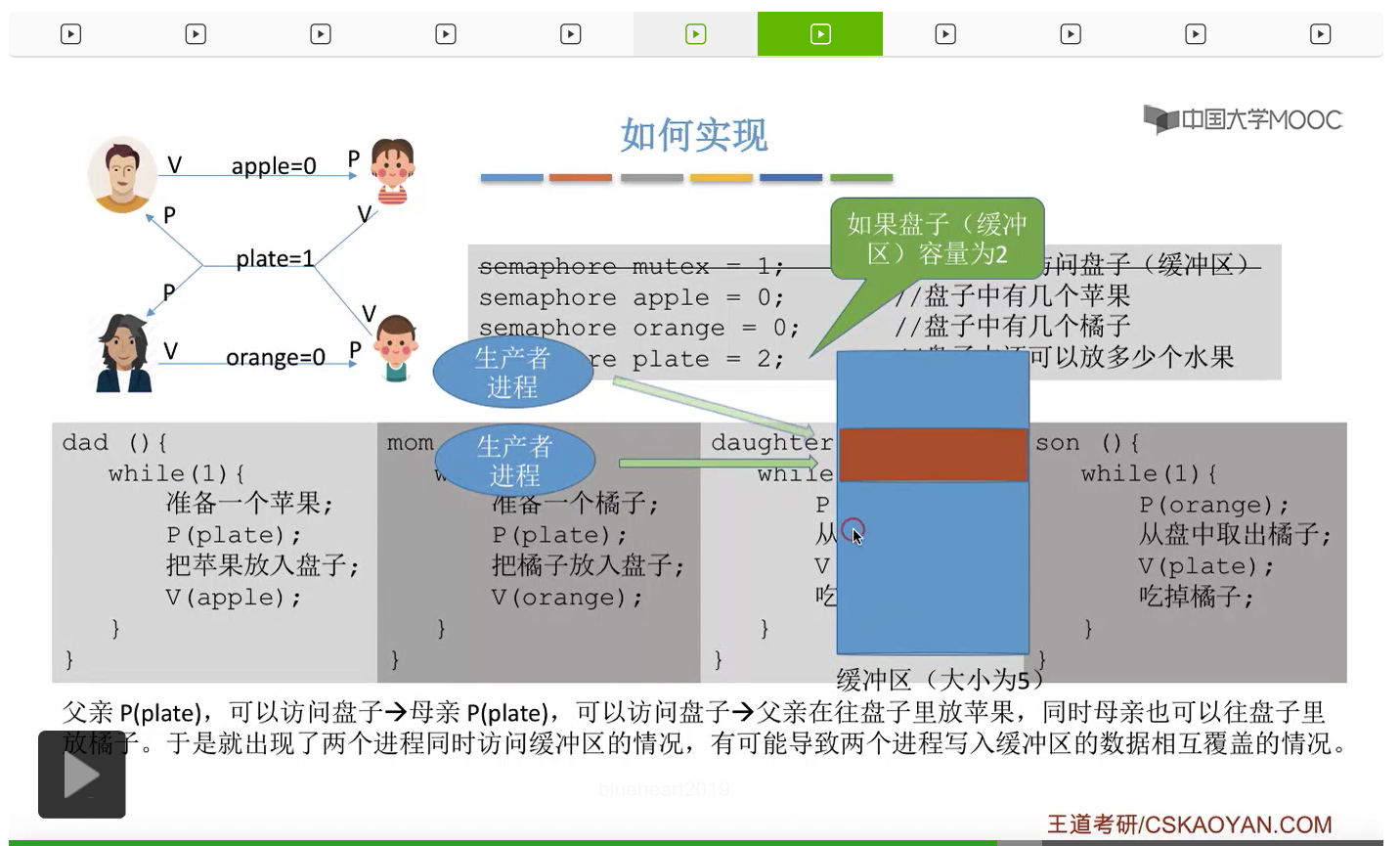
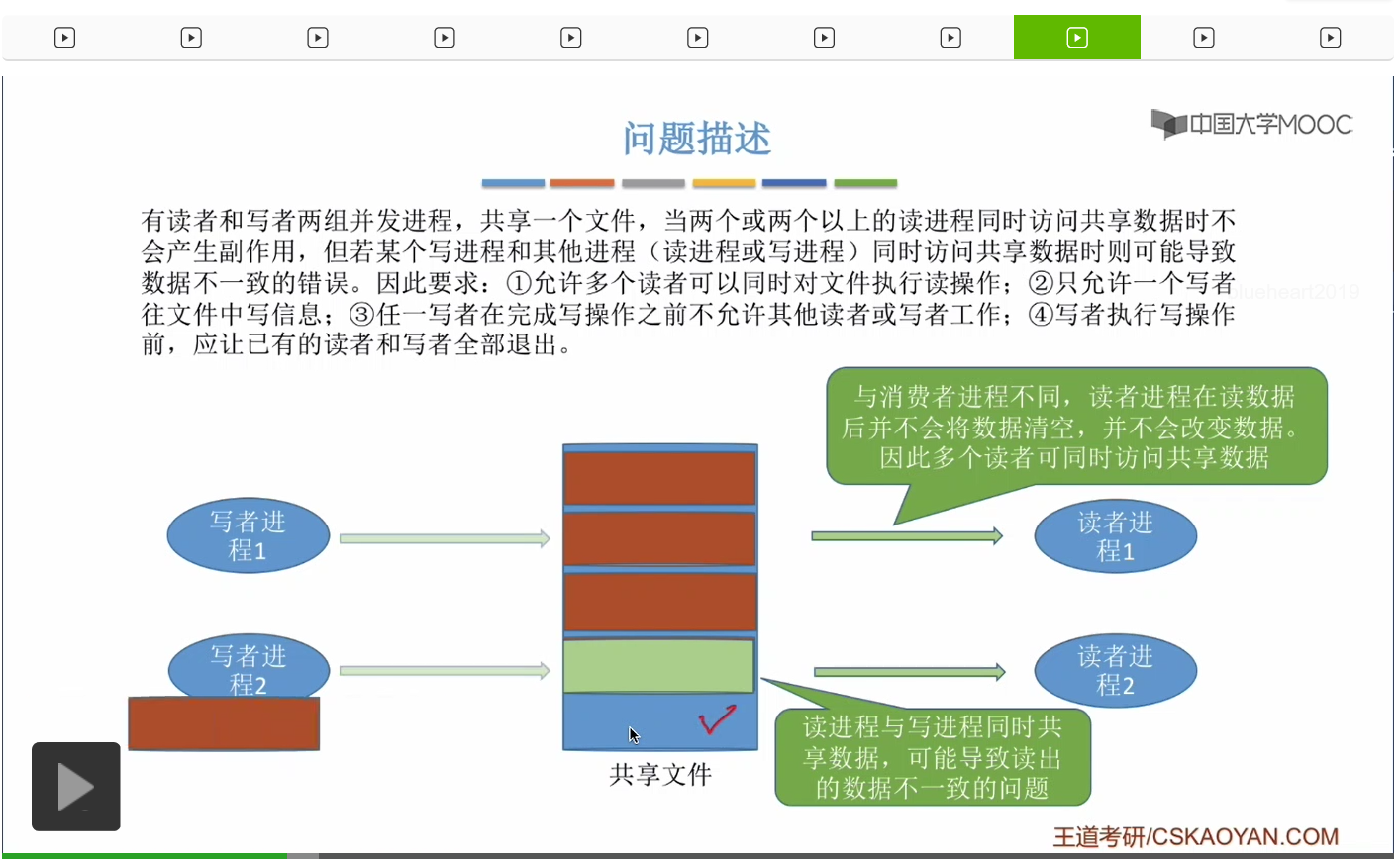
那通过上个小节的讲解我们知道,如果两个生产者进程它们同时对一个缓冲区进行访问的话,那么有可能会导致数据覆盖的问题。这个地方也一样。
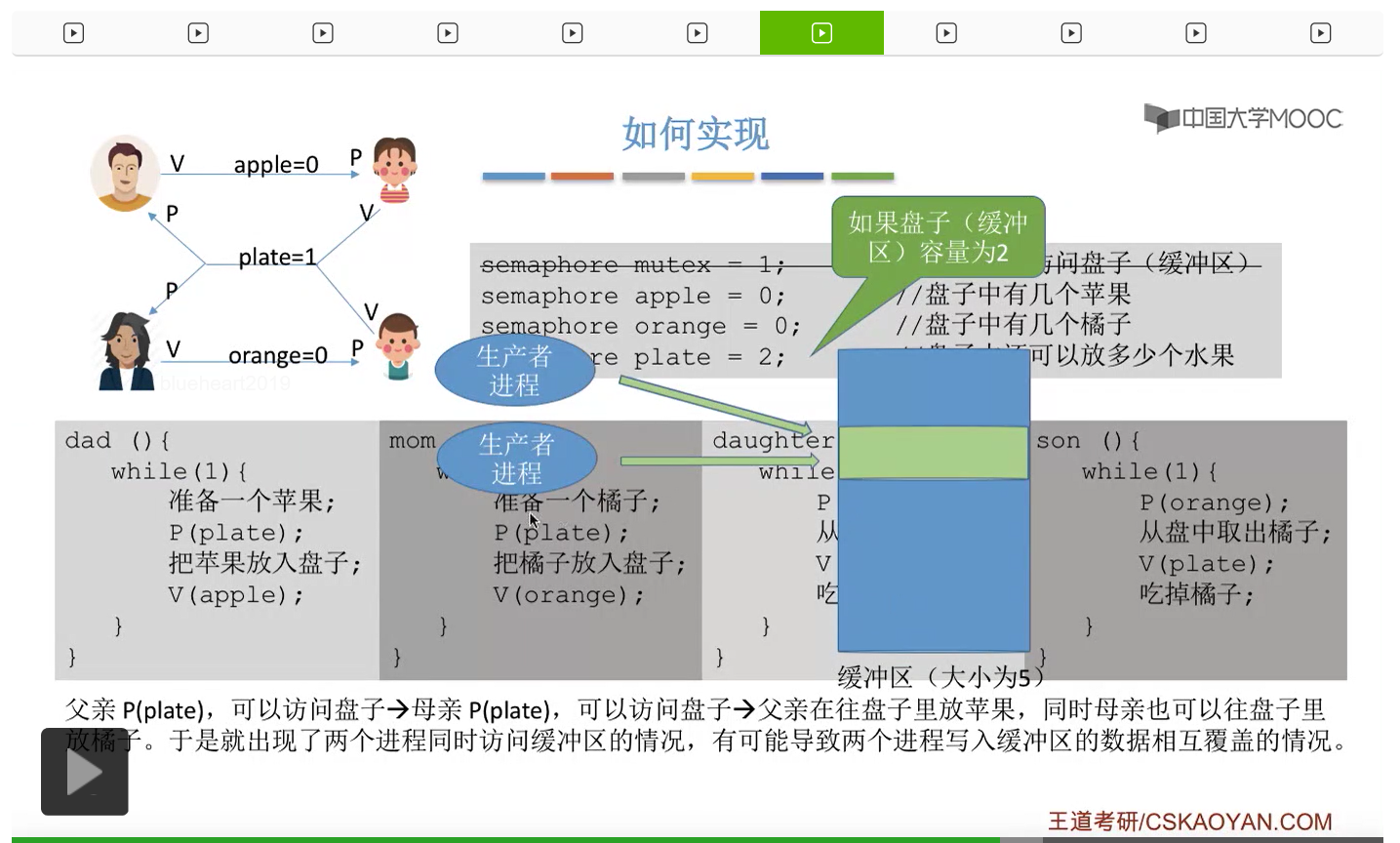
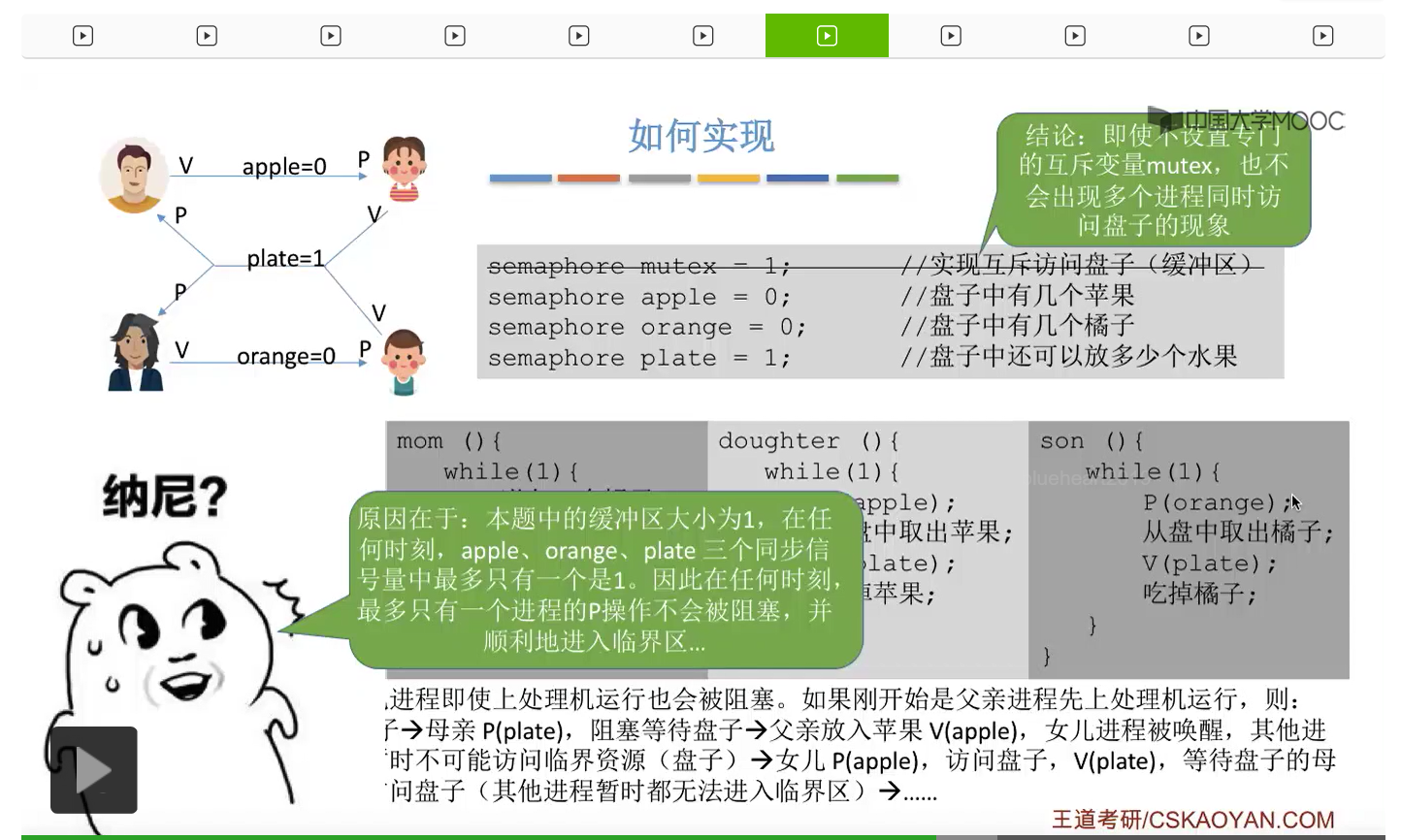
因此如果我们在生产者-消费者问题当中,遇到了缓冲区大于1的情况,那么我们就必须设置一个互斥信号量mutex来保证各个进程是可以互斥地访问缓冲区的。而如果缓冲区大小等于1的话,那我们即使不设置这个互斥信号量,有可能也可以实现互斥访问临界区这个事情,当然这不是绝对的,只是有可能不需要设置互斥信号量,要具体问题具体分析。如果大家在考试的时候遇到缓冲区大小为1的情况的时候,那么可以自己分析一下如果能确定不需要使用互斥信号量的话那么不设置也可以。但如果来不及仔细分析的话,大家最好是加上这个互斥信号量,因为加上了肯定也没错。不过我们需要注意的是,上个小节强调过的那个问题,实现互斥的对于mutex那个信号量的P操作一定要在实现同步的P操作之后,否则是有可能会引起死锁的。
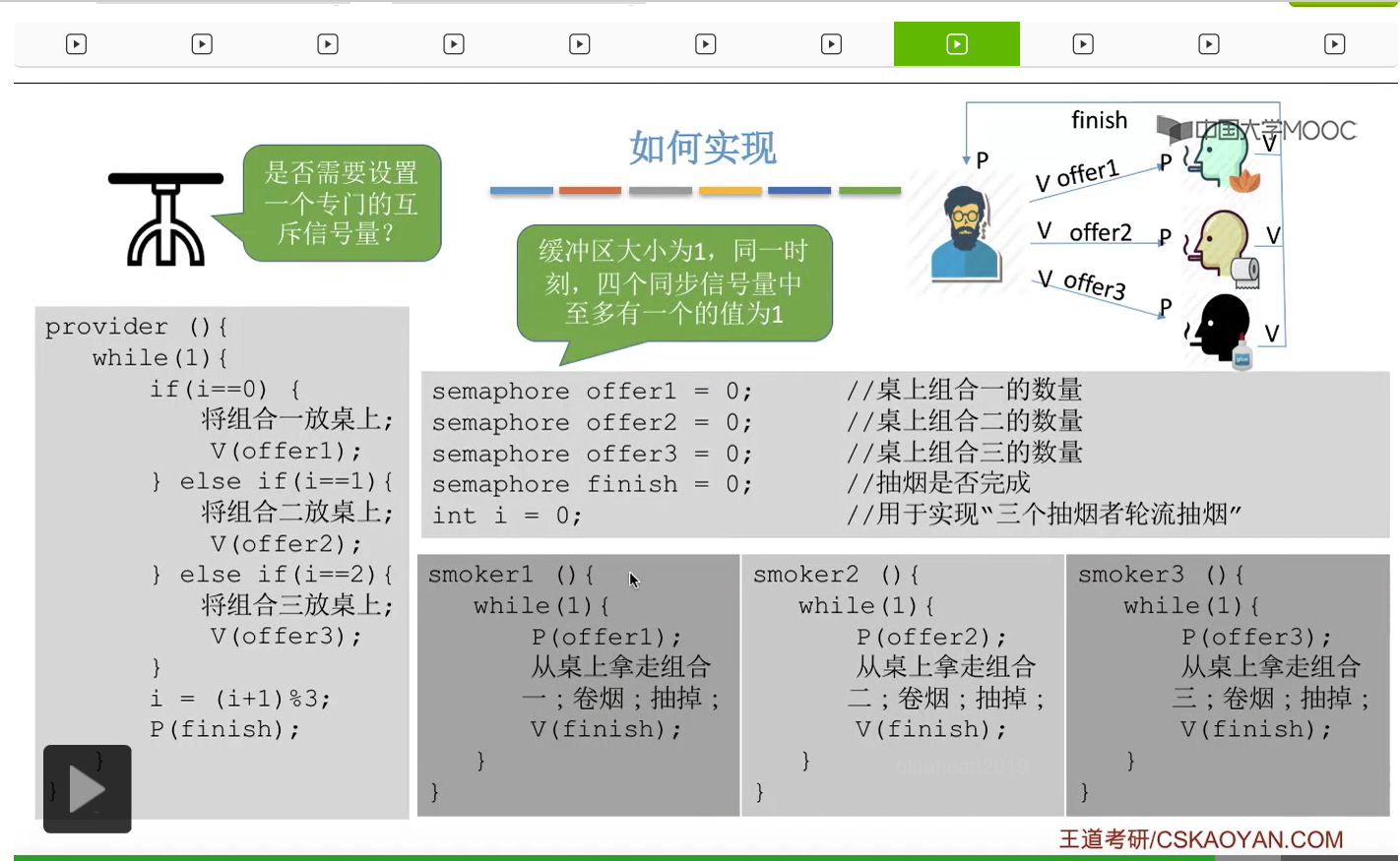
在这个小节中我们会学习一个进程同步互斥的问题,叫做吸烟者问题。

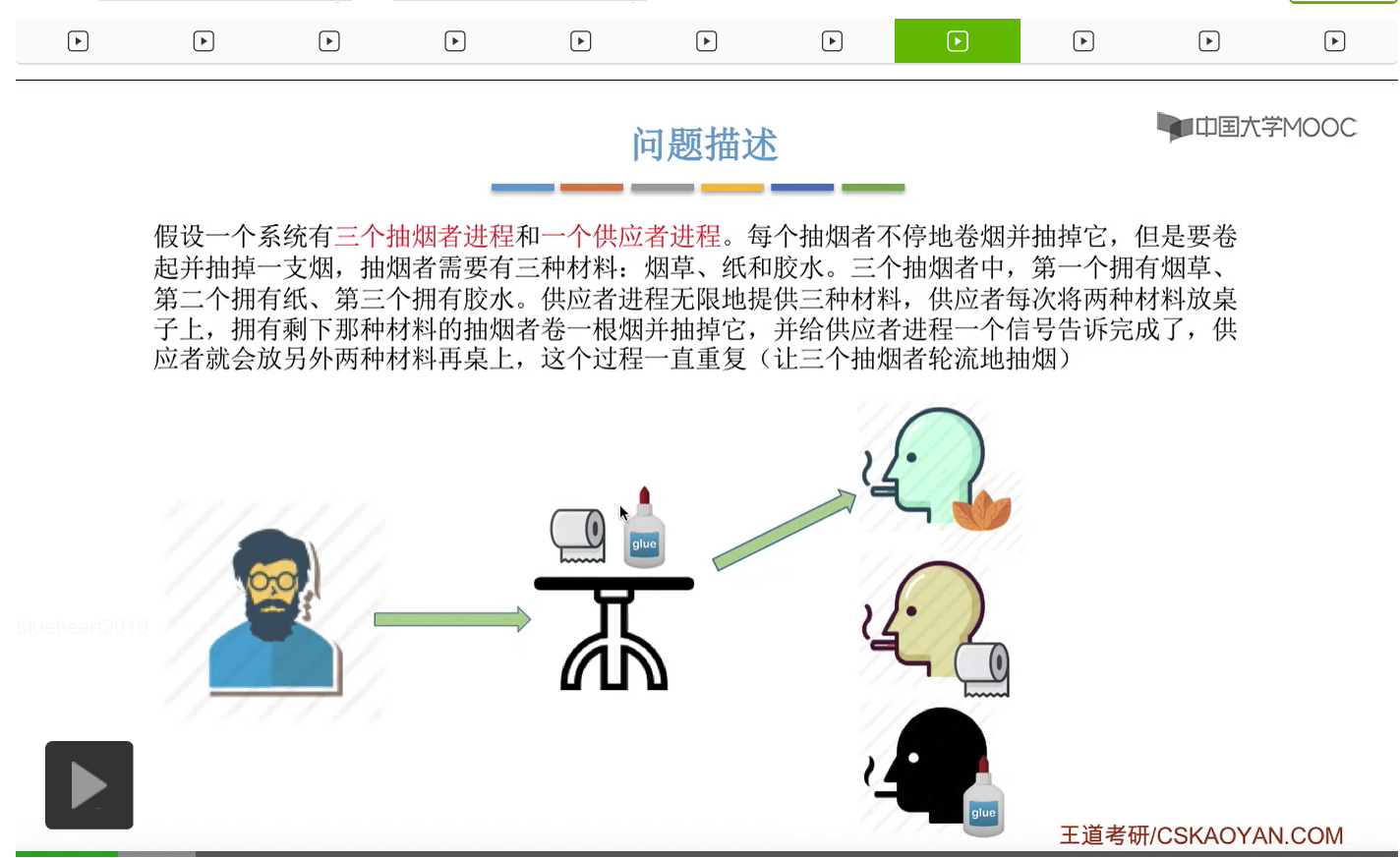
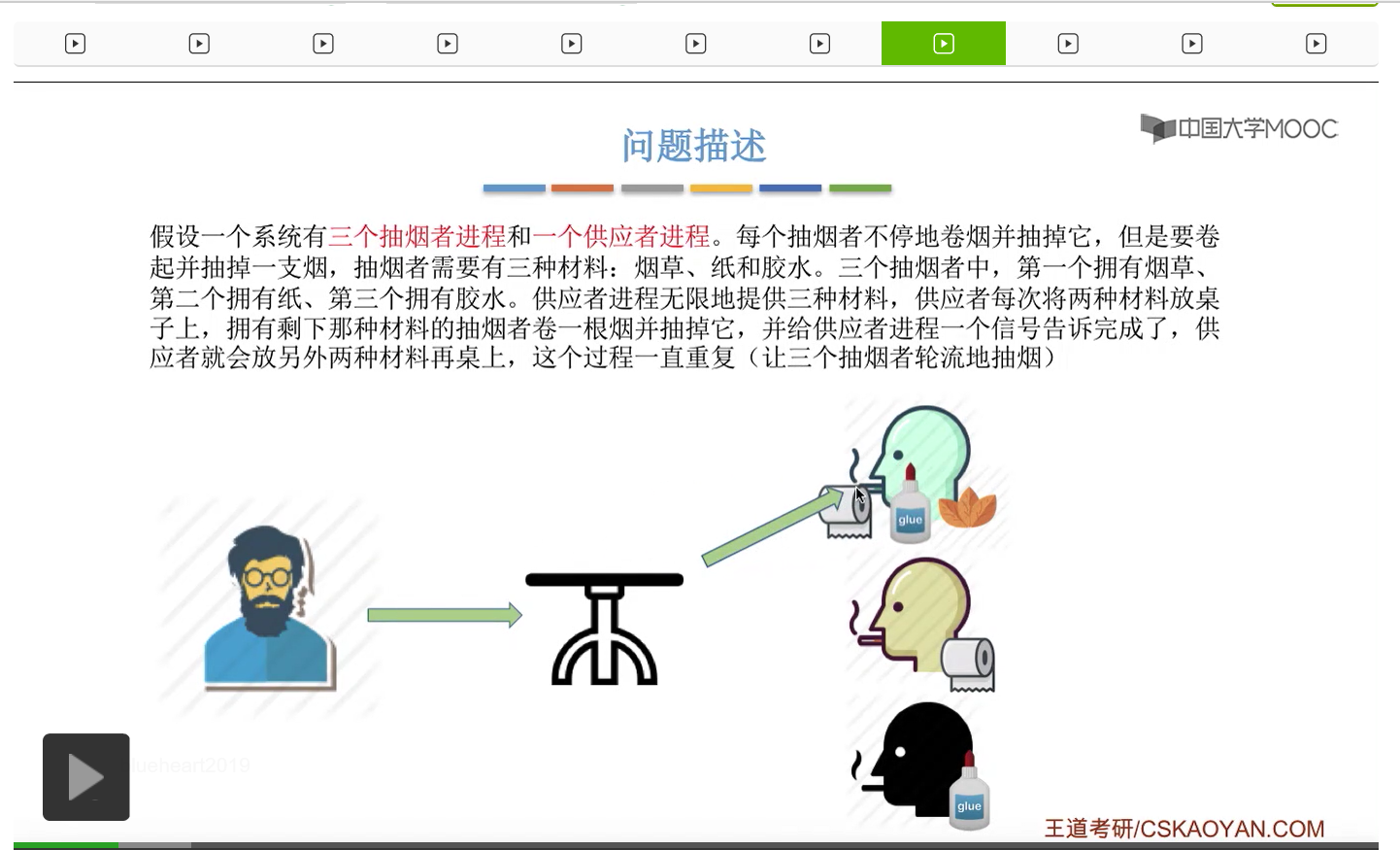
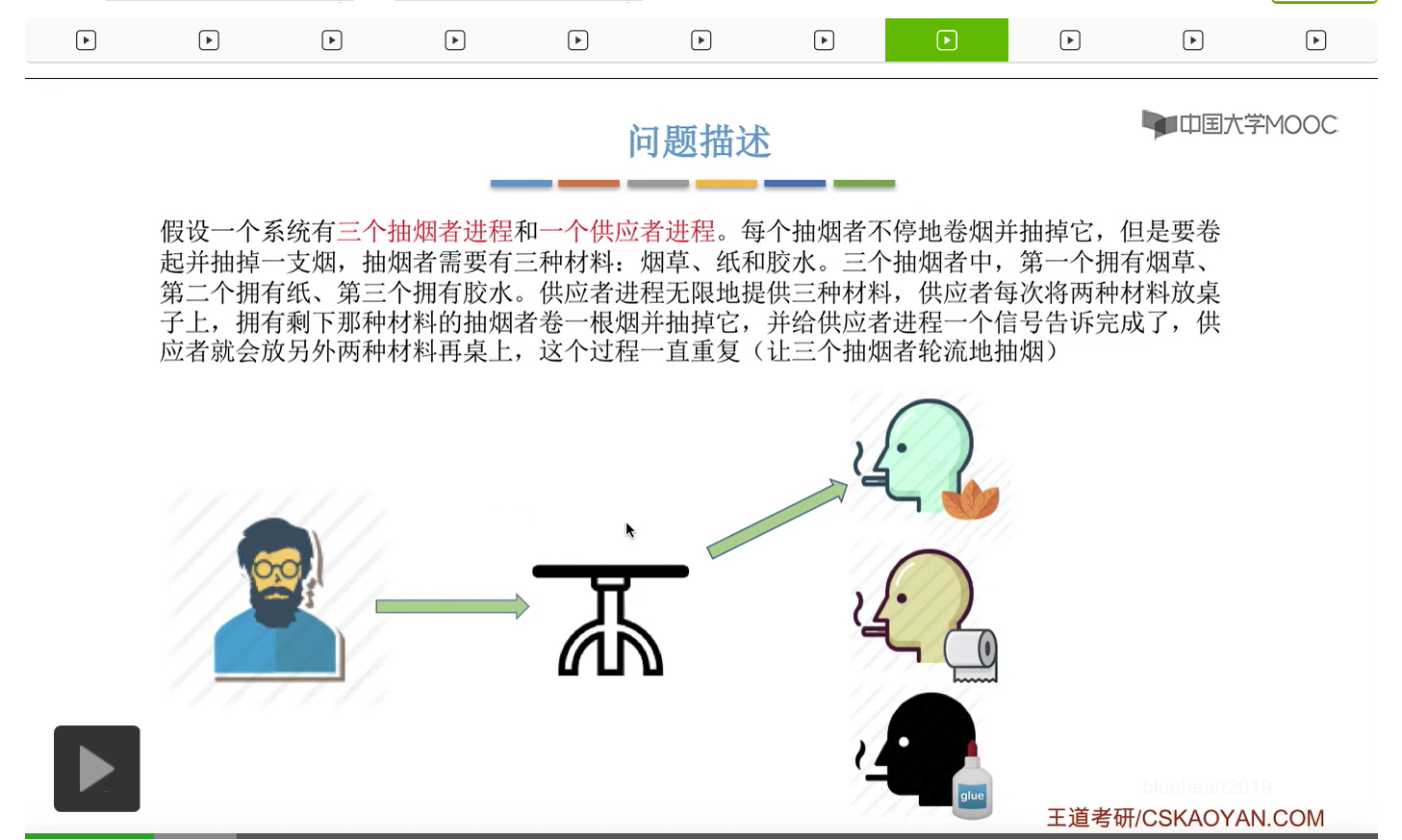
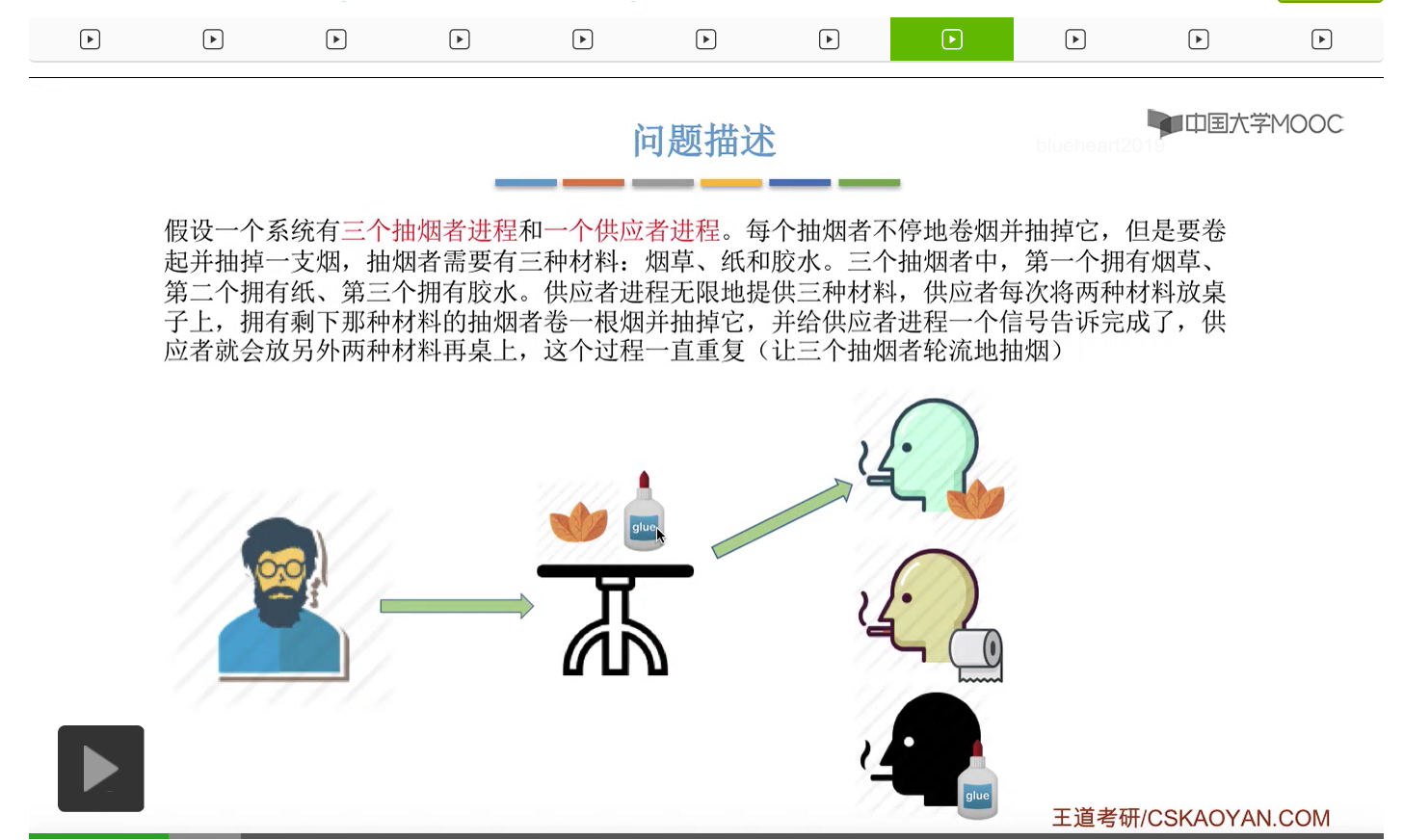

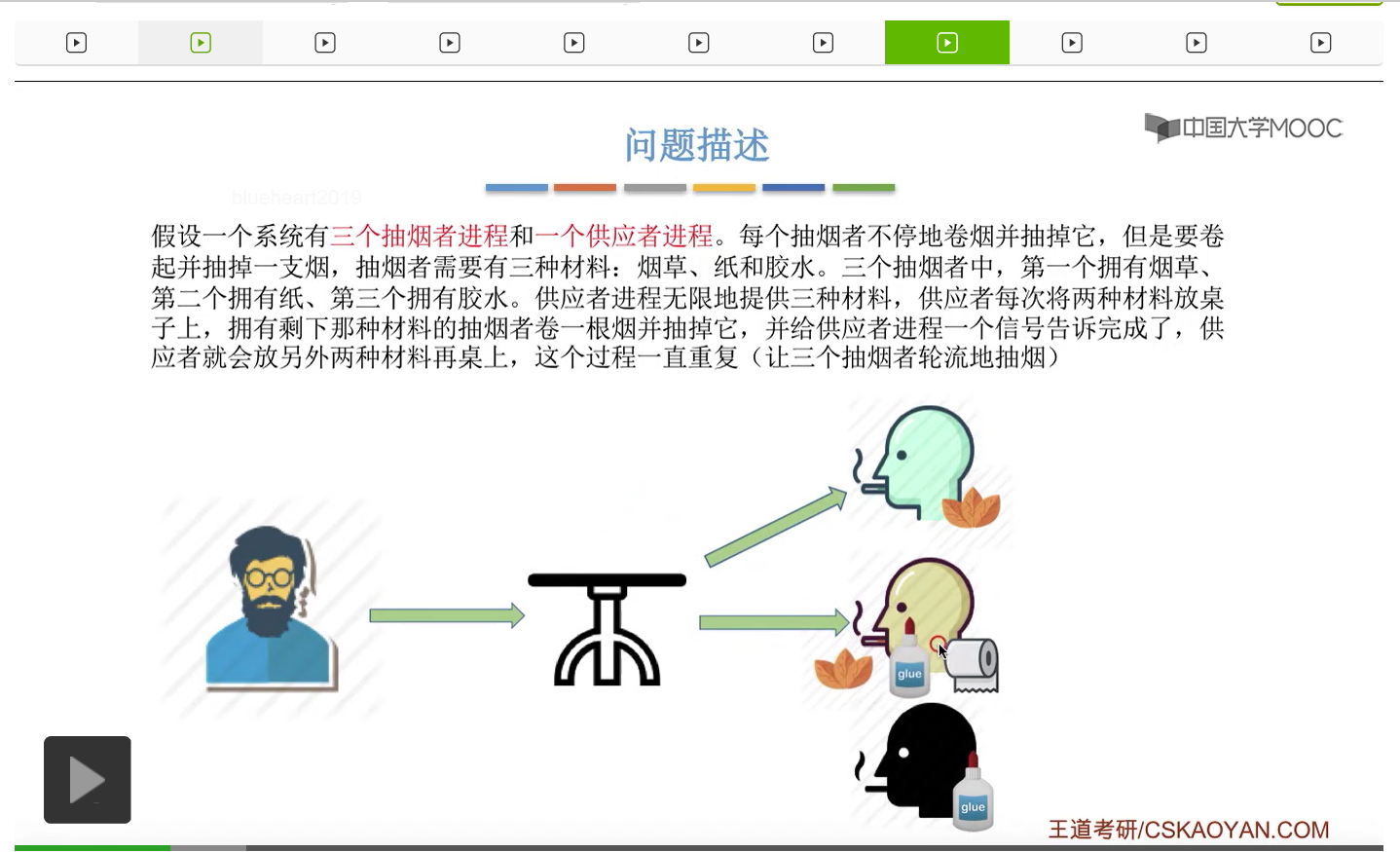
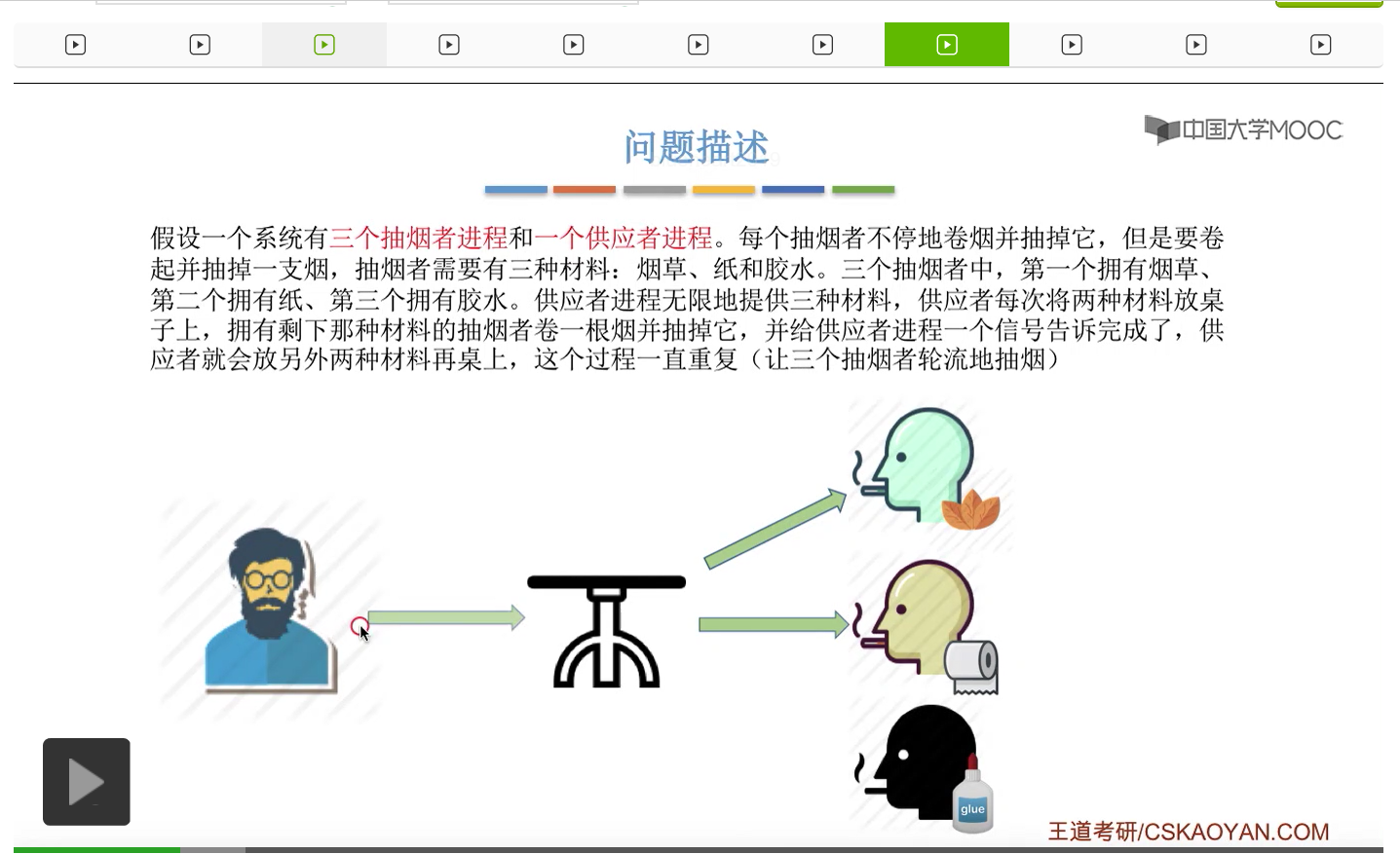
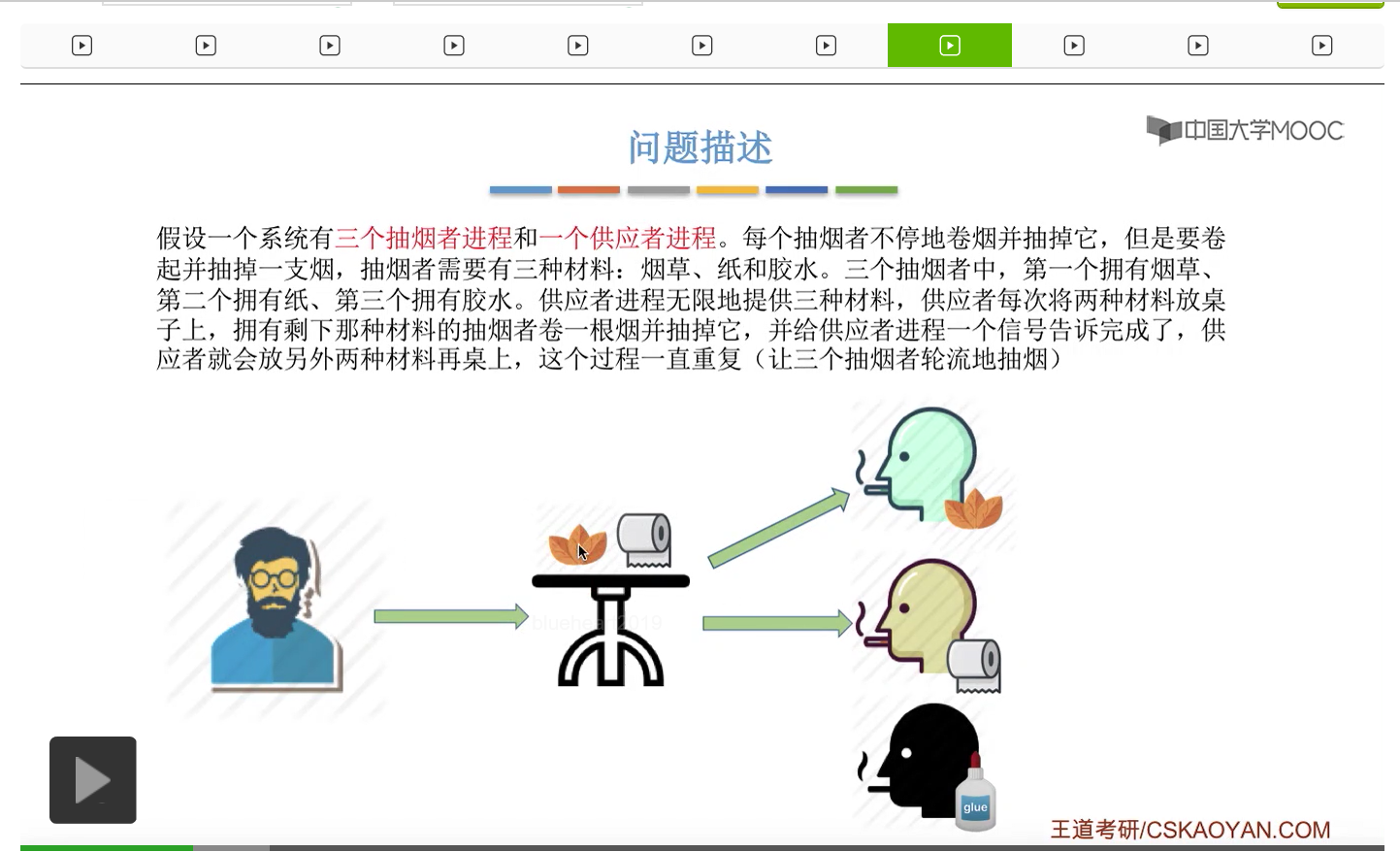
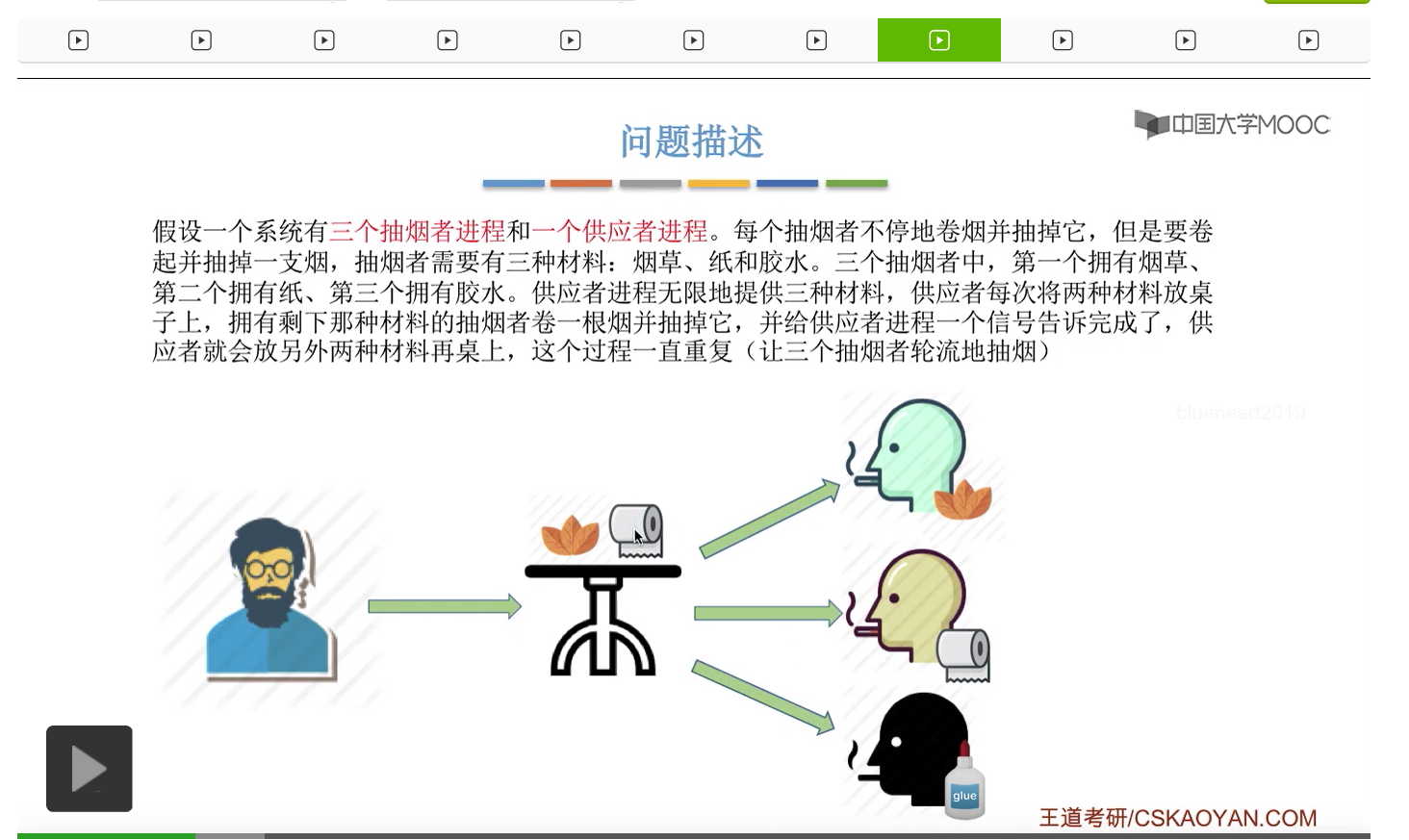
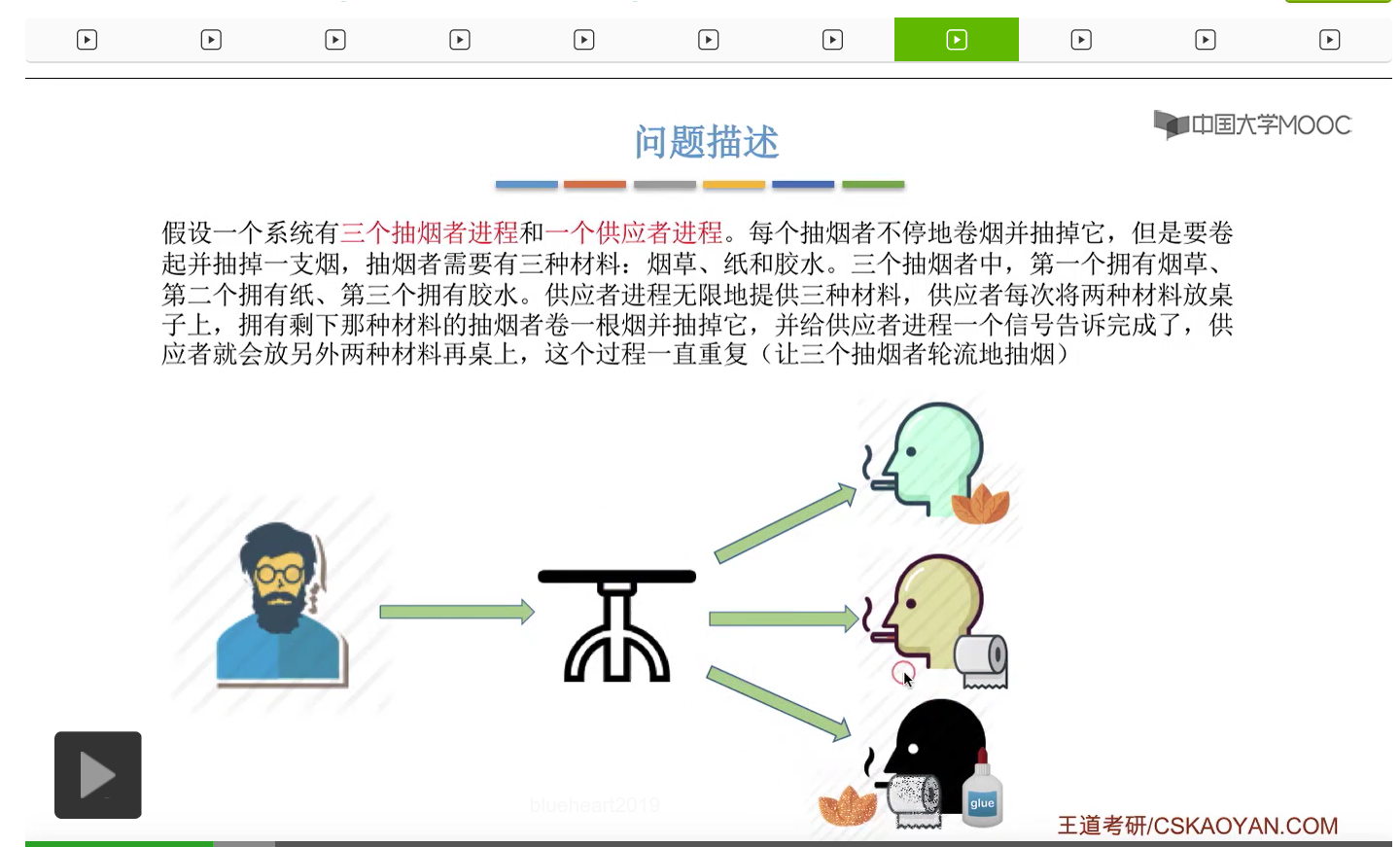
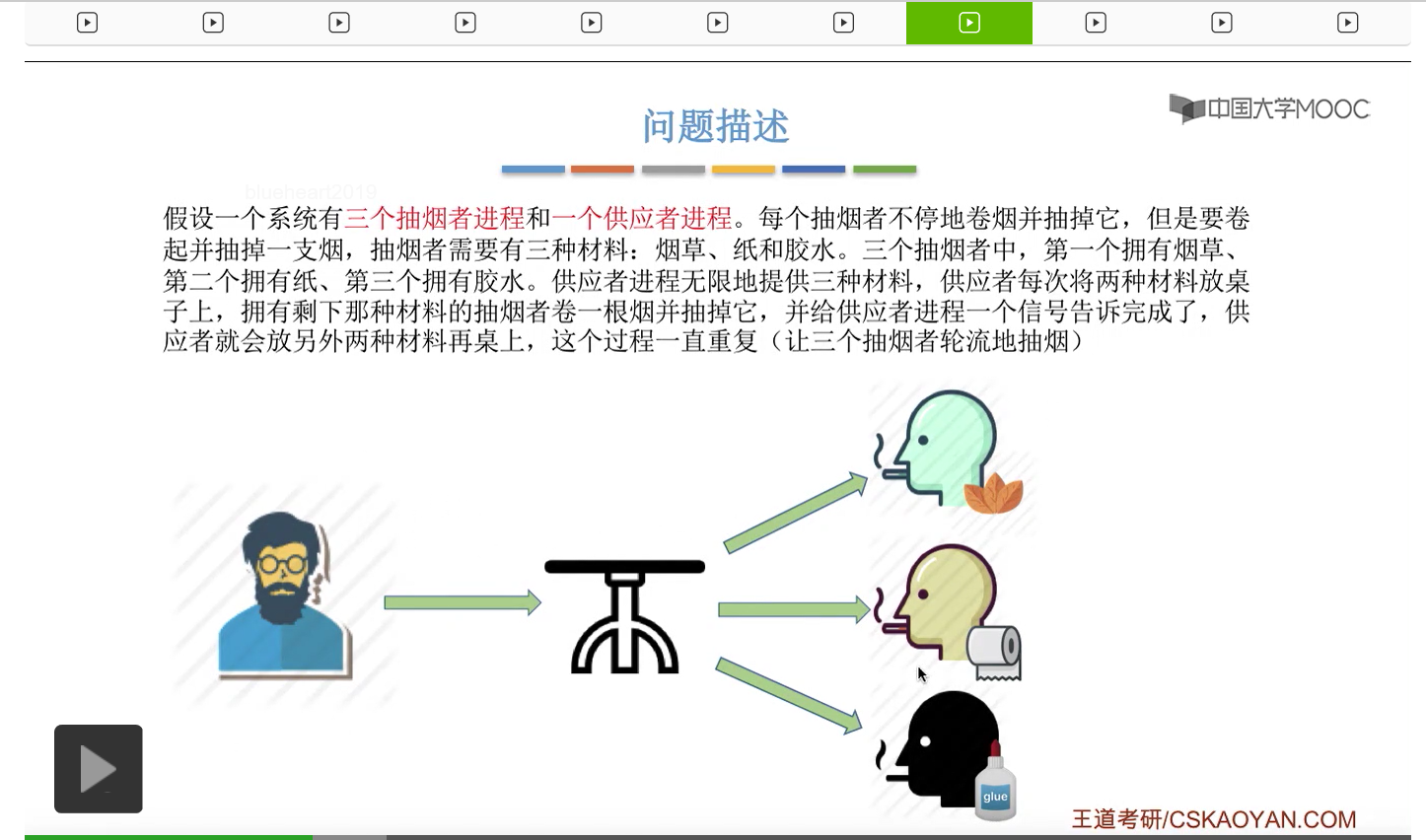
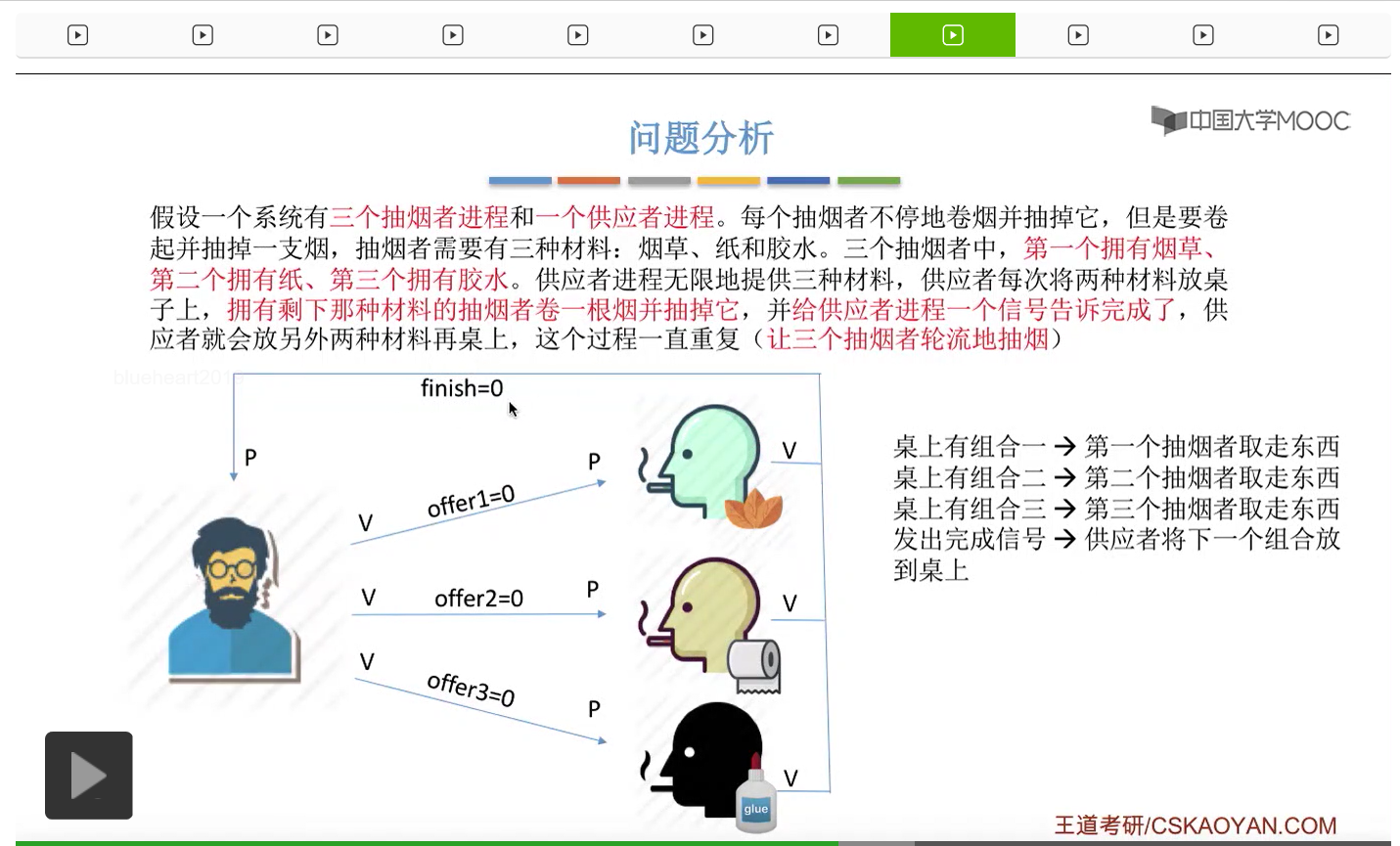
所以我们可以把桌子看做是一种容量为1初始为空的缓冲区,而对缓冲区的访问需要互斥地进行。对于实现互斥的PV操作来说,很简单,无非就是在访问这个临界资源之前和访问临界资源之后,对互斥信号量分别执行P和V操作。而对于同步问题来说,我们需要遵循前V后P这样的原则,必须发生在前面的这个事件发生了之后,我们需要执行一个V操作,而必须发生在后面的这个事件发生之前我们需要执行一个P操作。

对于互斥问题来说,由于这个缓冲区的大小为1,所以我们即使不设置专门的互斥变量,其实也可以实现互斥访问临界区这件事情。

所以我们只考虑设置这些同步信号量。
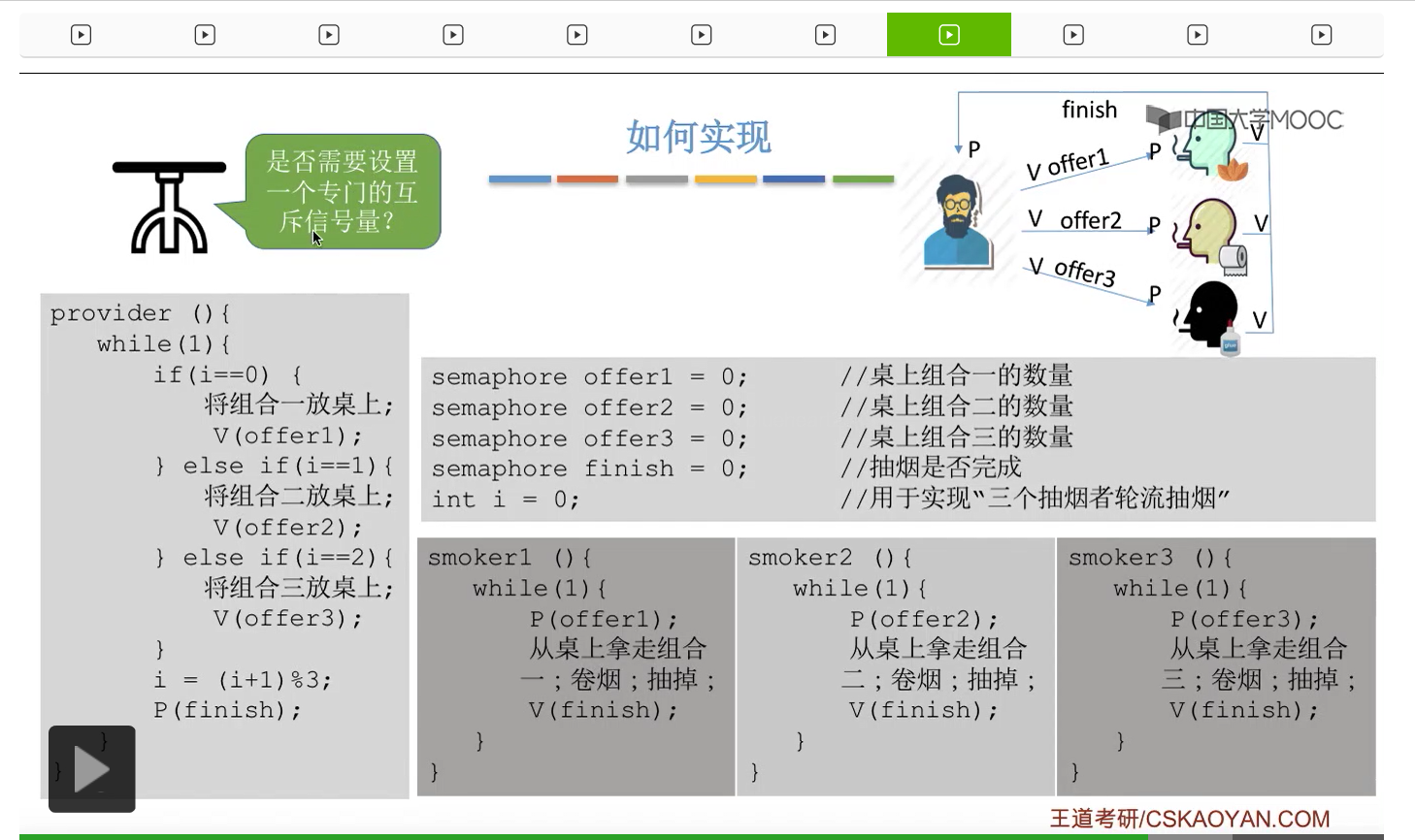
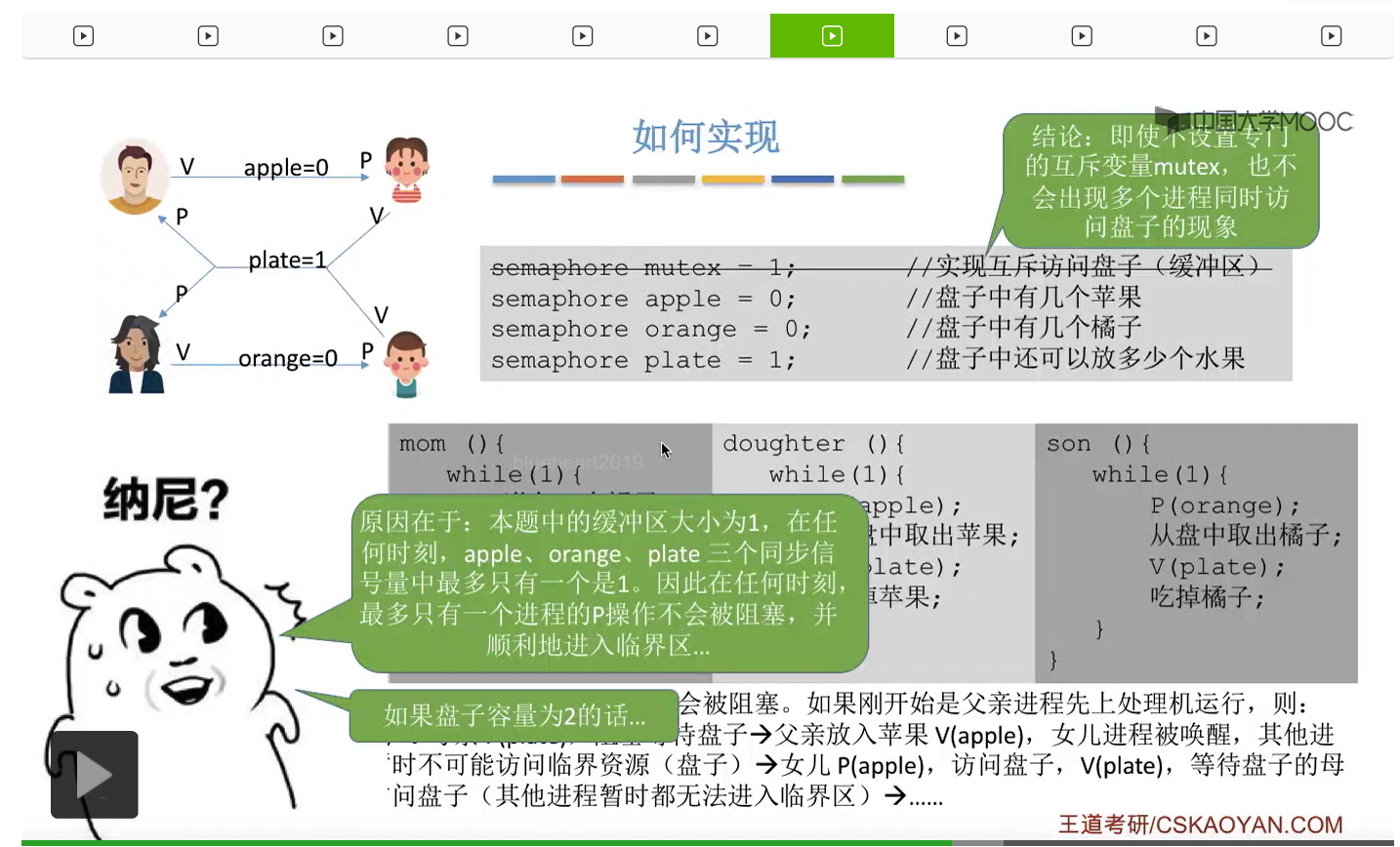
那這個地方大家再結合這些代碼來分析一下到底是不是需要專門地設置一個互斥信號量才可以保證各個進程它們互斥地訪問桌子這個緩衝區呢?其實如果經過分析之後大家會發現,這些信號量同一時刻只會至多只有一個的值可能是1,也就是說這四個進程在同一時刻最多只會有其中的一個不被這個P操作所阻塞,可以順利地進入桌子這個臨界區。那這個地方感興趣的大家可以自己再推一下。
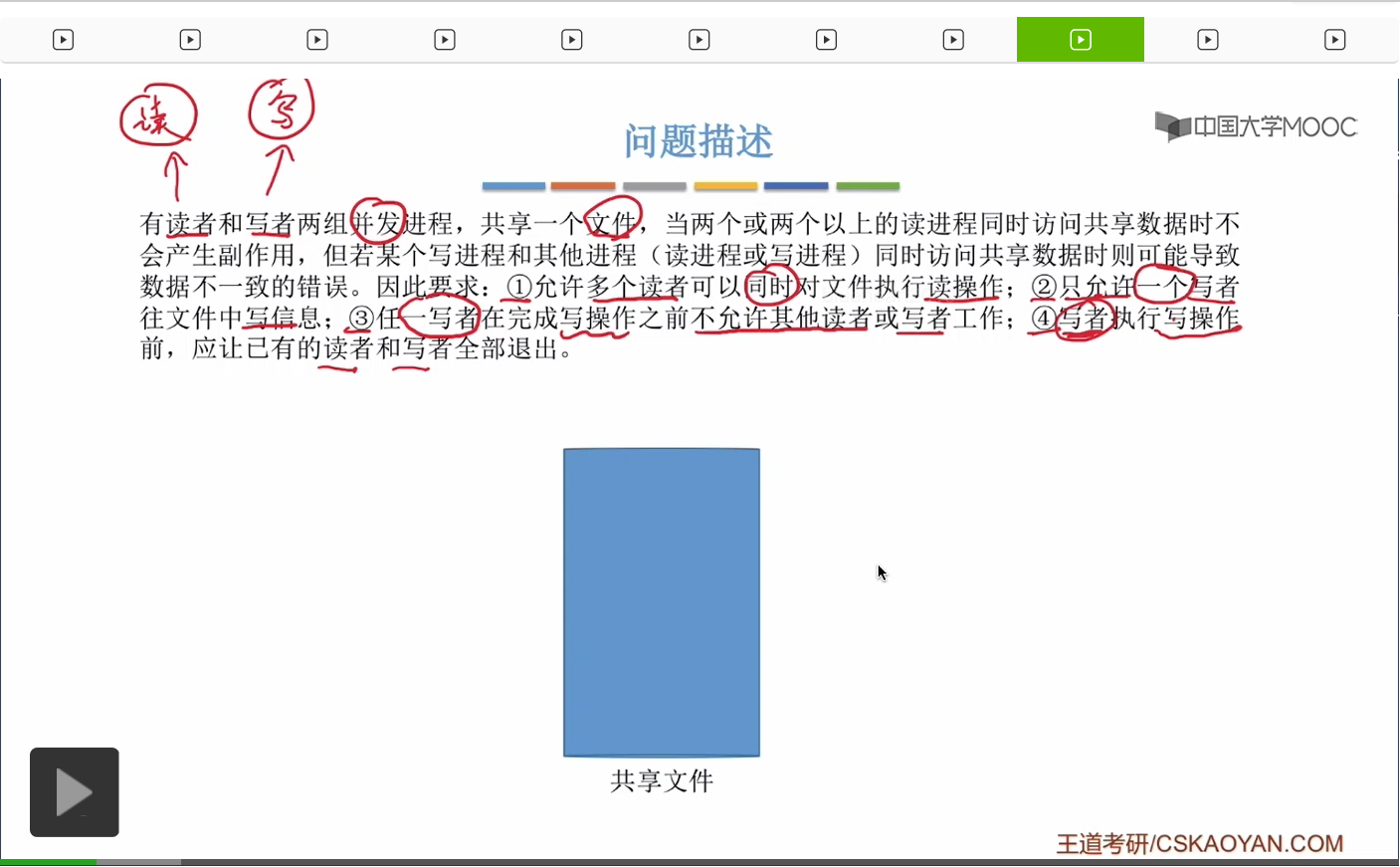
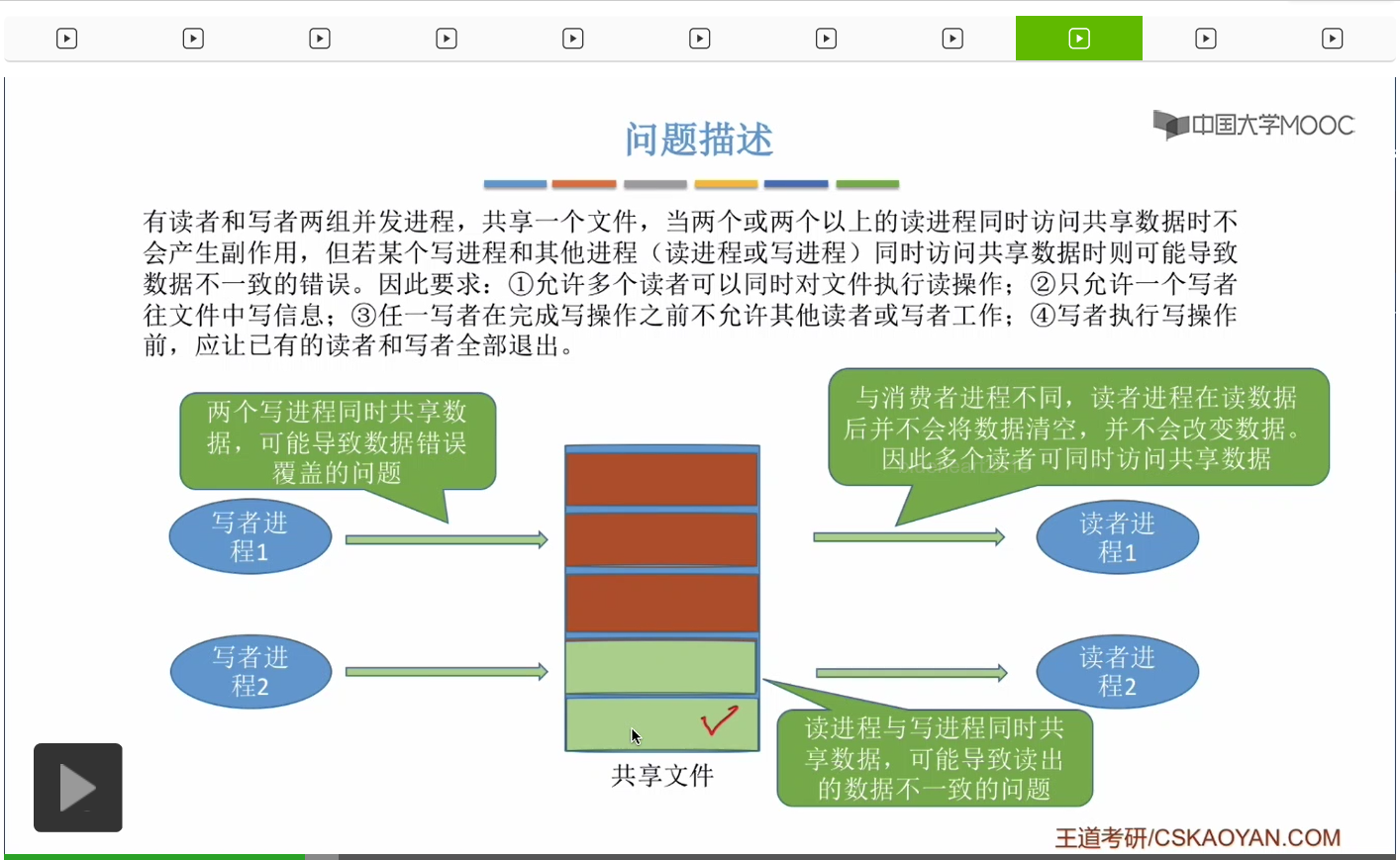
在這個小節中我們會學習另一個經典的進程同步、互斥的問題——讀者-寫者問題。

爲什麽可以多個讀者同時讀文件?等大家學過第四章就會知道,一個文件由一條一條的記錄組成。
一個文件它是由一坨一坨的數據組成,那麽這個文件可能同時會有多個讀進程想對它進行讀操作。那由於這兩個讀進程在讀這個文件的時候,并不會更改這個文件的這些數據的信息,所以多個讀進程同時讀這個文件是可以被允許的。
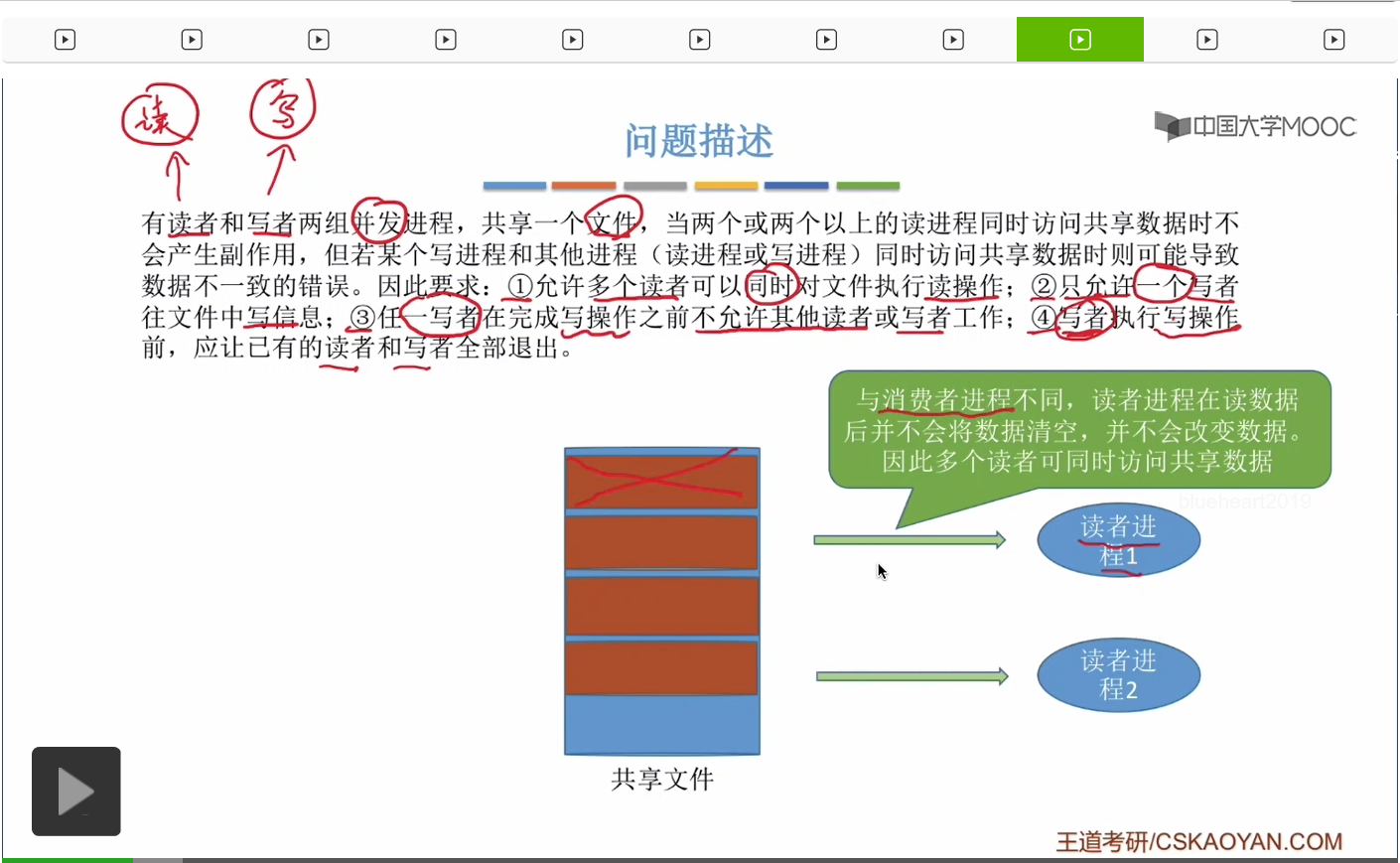
當一個寫者進程正在對文件進行寫操作的時候,其他進程是不能訪問這個文件的。或者換一個角度來講,當一個寫進程想要寫這個共享文件的時候,它必須先等到其他進程對這個文件的操作結束之後它才能往裏邊開始寫數據。
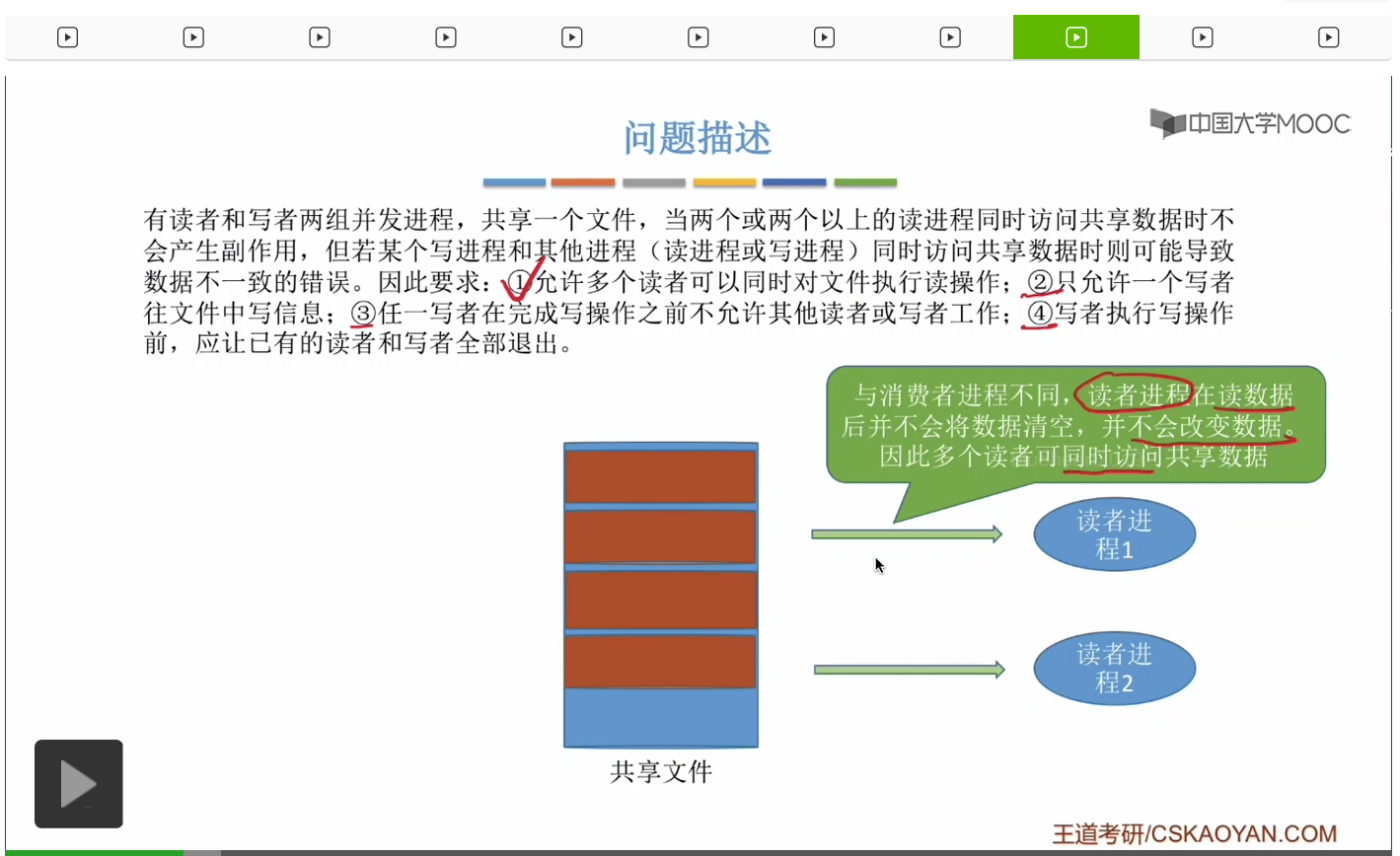
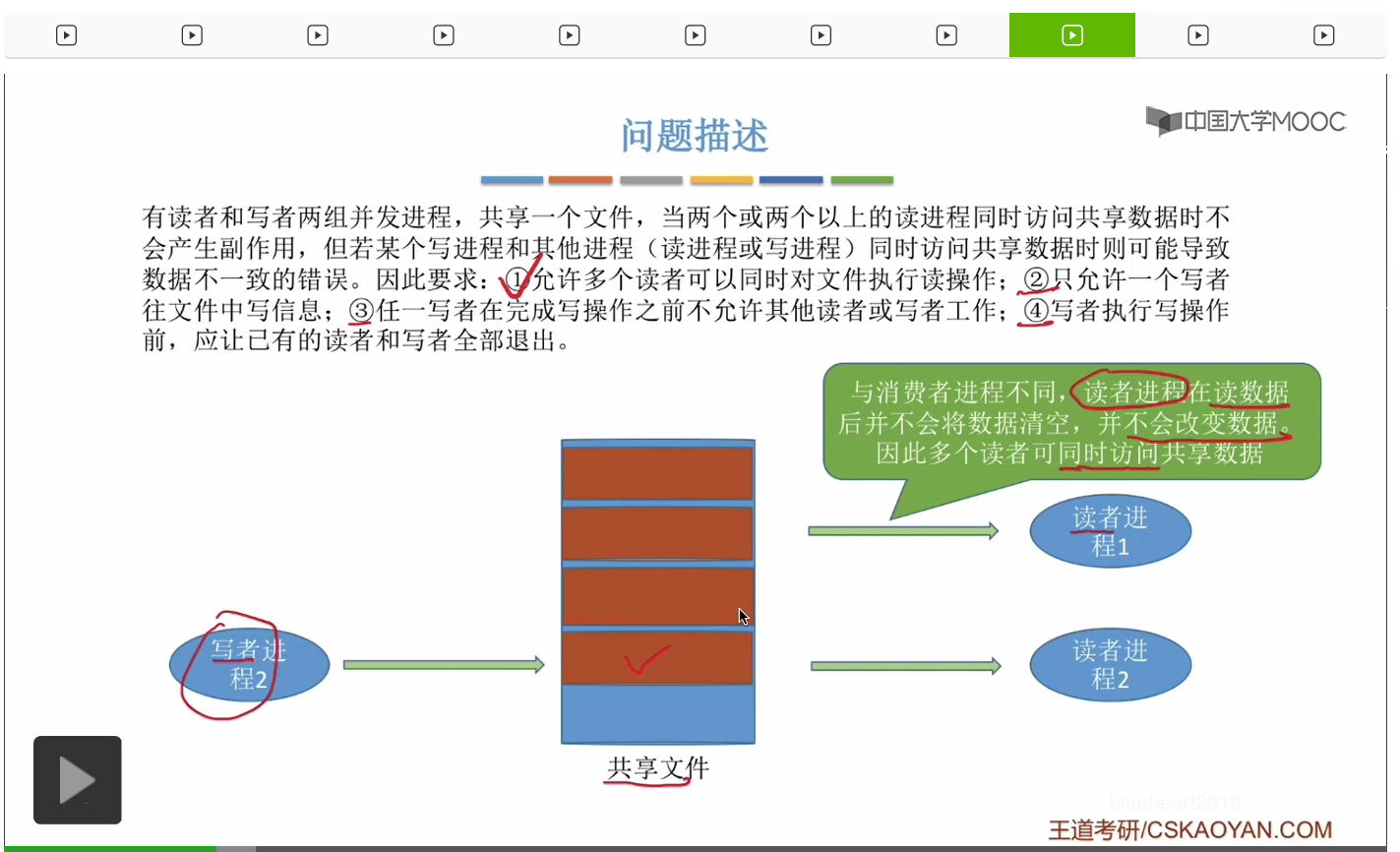
因此由於寫者進程它會改變這個共享文件的内容,所以寫者進程是不可以和其他進程同時訪問這個共享文件的。
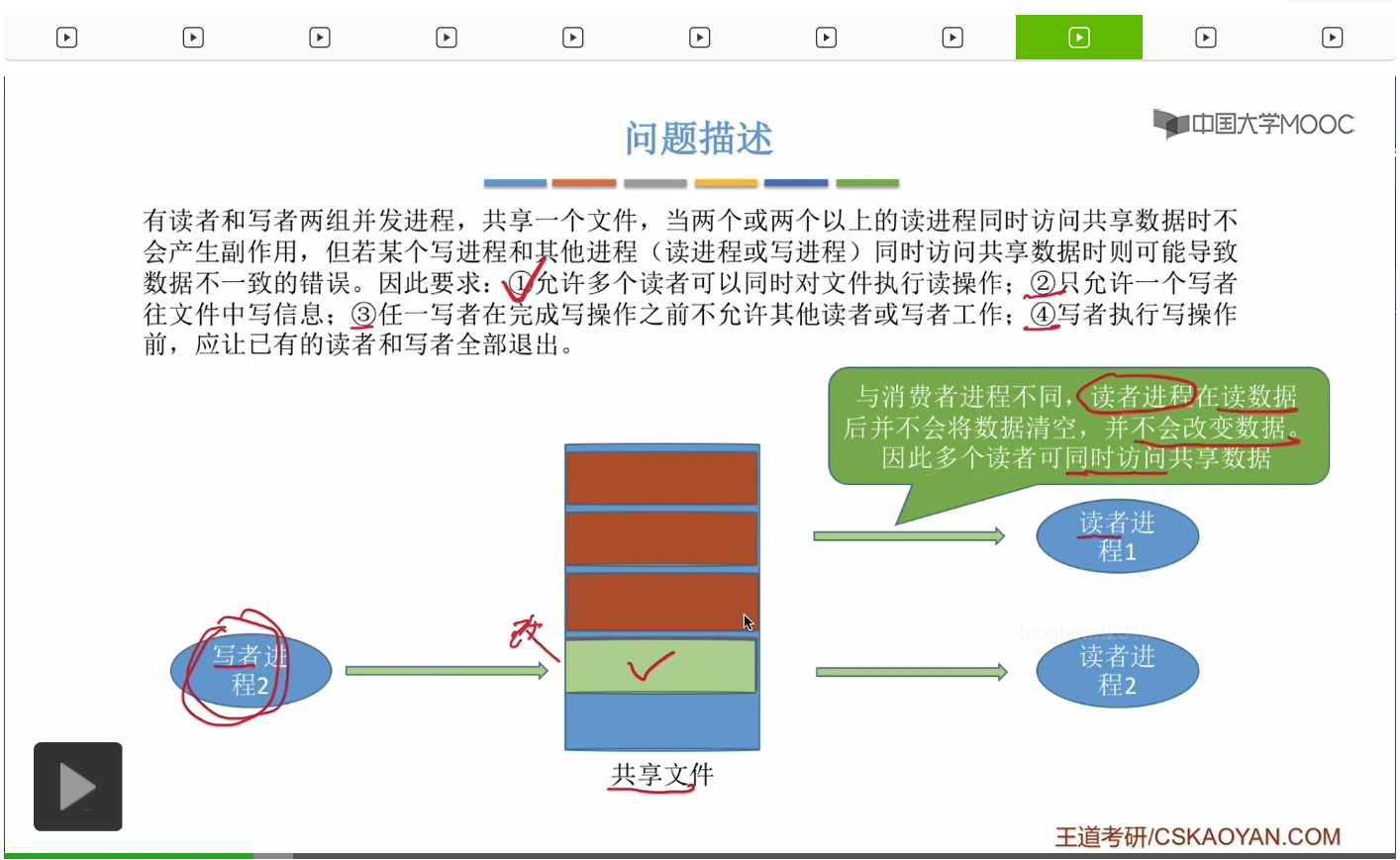
如果兩個寫者進程并發運行會發生什麽情況?

嘗試用PV操作解決這個問題。那我們怎麽用PV操作來實現這個互斥關係呢?那接下來我們要考慮的就是要怎麽樣設計信號量,然後用PV操作來解決這個問題。

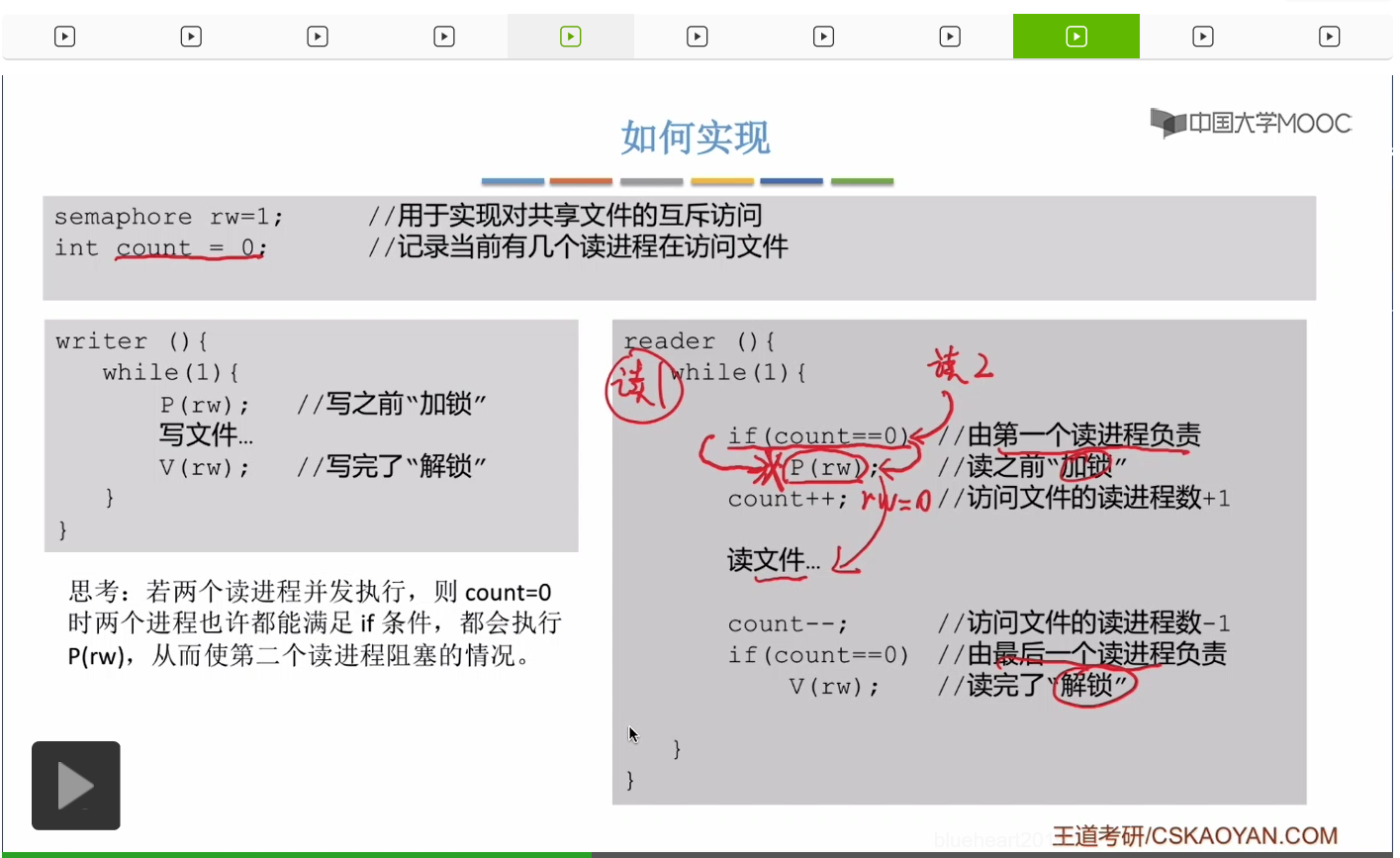
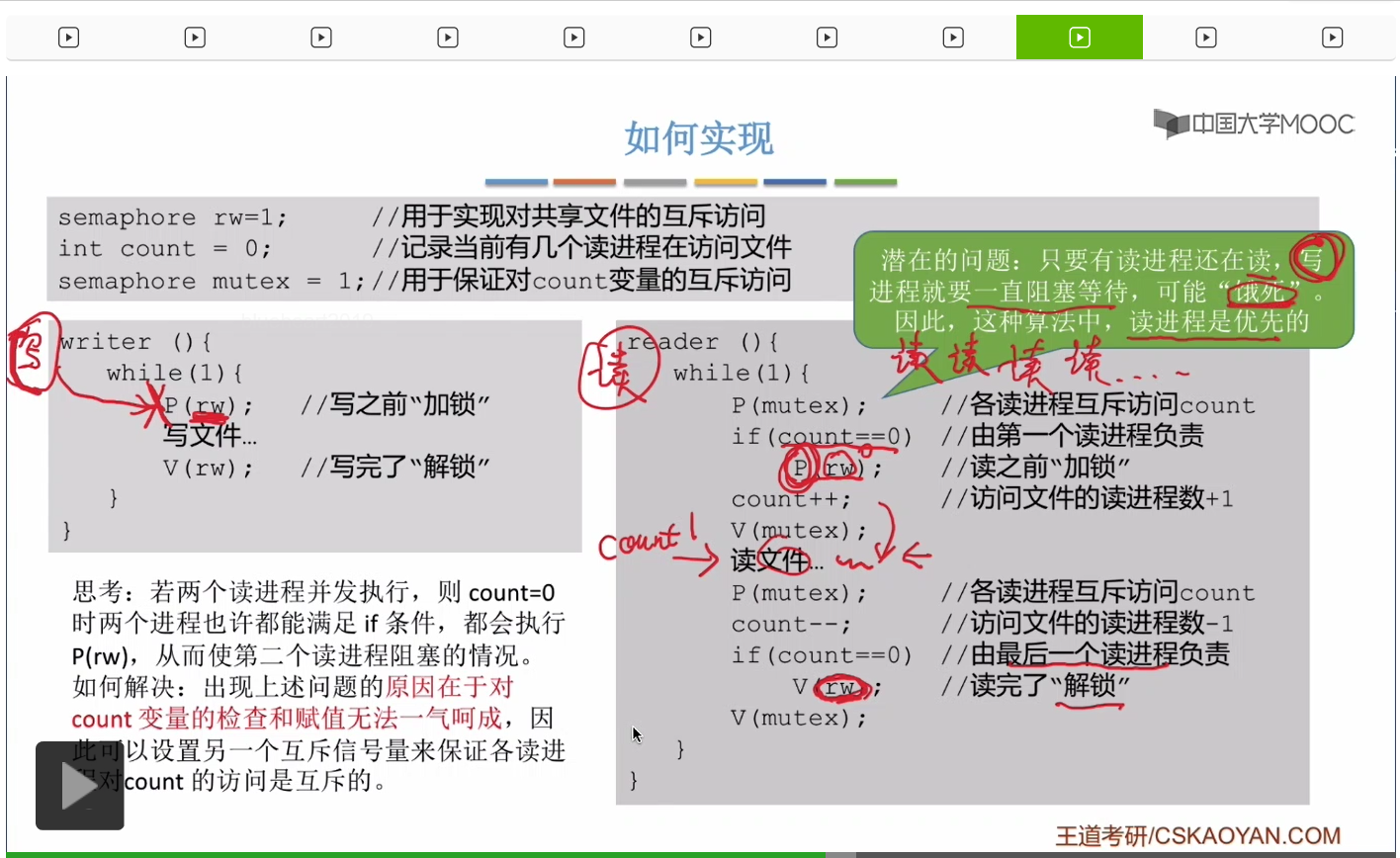
我們設計一個叫做rw的互斥信號量,用於實現各個進程對於共享文件的互斥訪問。但是如果我們只是簡單地在讀文件之前加鎖,讀完了文件之後解鎖,那麽這種方案會導致讀者和讀者之間不可以同時訪問這個共享文件。

因爲只有第一個讀進程才需要對這個文件進行加鎖,才會執行P操作。而只要此時有一個讀者正在讀這個文件,也就是說只要此時count的值它大於零的話,那麽接下來的讀者進程就不會再對這個互斥信號量執行P操作,就不會再進行加鎖,它可以直接跳過這個條件判斷,而直接進行count++操作。所以由第一個讀進程負責加鎖,由最後一個讀進程負責解鎖,這個方案看起來似乎是可以實現我們讀者和讀者之間可以同時共享這個文件這件事情的。

不過這個方案也存在一個問題,我們來深入思考一下,如果兩個讀者進程它們并發地執行的話,剛開始如果count的值是零,那麽讀者1當它在執行到這個判斷語句的時候發現此時count的值是零,所以這個條件滿足因此讀者1接下來會執行這個P操作。那如果此時切換成了讀者2進程,那這個進程它在執行這一句條件判斷的時候也會發現count的值此時是零,所以這個條件也滿足,因此讀者2接下來也會來執行這個P操作。所以讀者2對rw執行了P操作之後,rw的值就變爲了0,那接下來如果再切換回讀者1這個進程的話,它在執行這個P操作的時候,會發現rw已經為零。這個讀者1就會被阻塞在這個地方。因此這種情況下雖然讀者2已經可以開始讀文件了,但是讀者1又被阻塞在了這個P操作這兒。
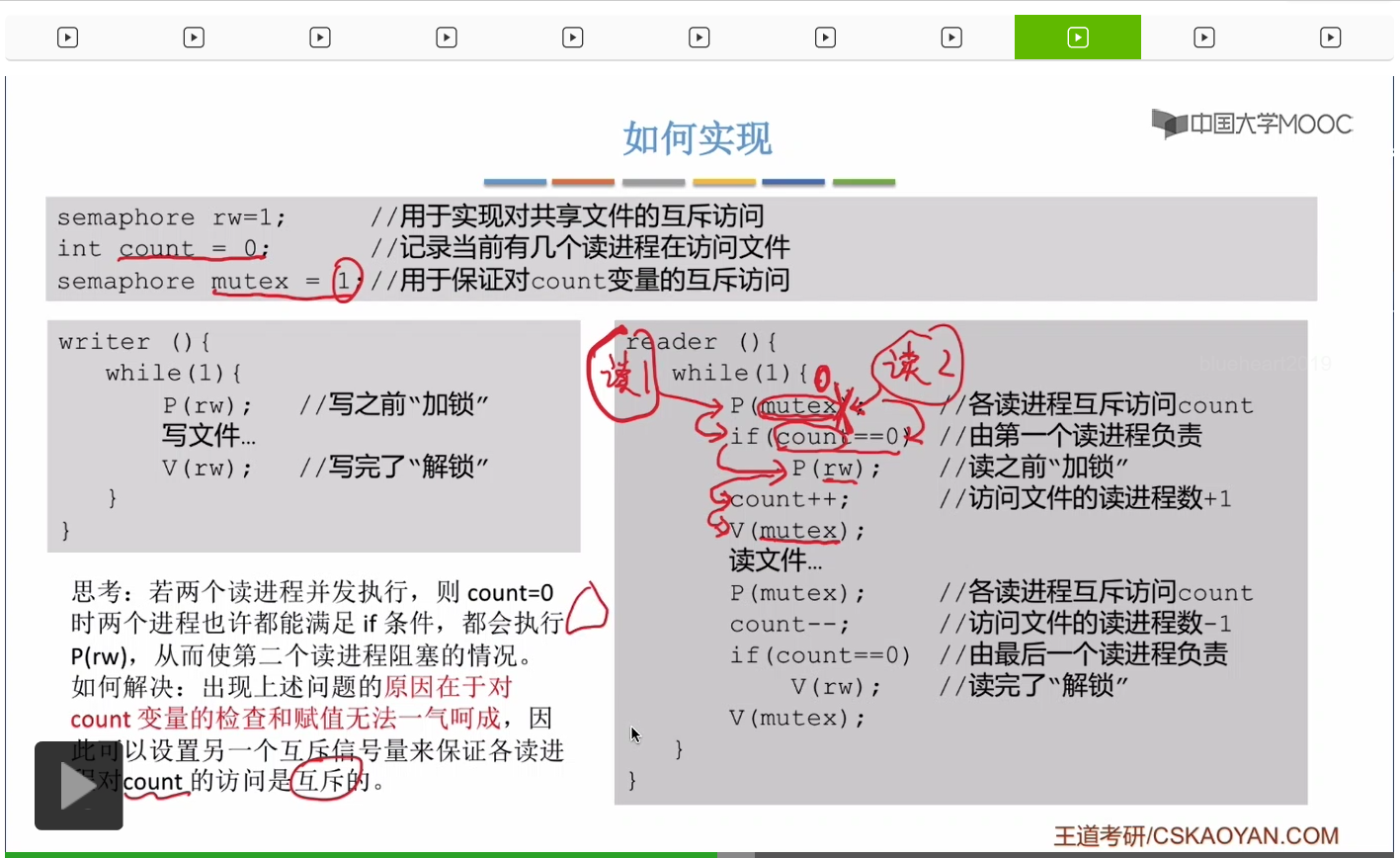
那導致這個問題的原因在於我們對count變量的檢查和賦值這兩個操作沒有辦法一氣呵成。當一個讀進程對count的值進行檢查之後,有可能切換成第二個讀進程,它也進行檢查操作,那這樣的話就會出現問題。那爲了解決這種無法一氣呵成的問題,我們應該很自然地想到我們可以讓各個讀進程互斥地來訪問count這個變量,

所以我們可以再多增加一個互斥信號量叫mutex,用於保證對這個count的互斥訪問。然後在對count進行操作之前,執行P操作,操作完了執行V操作。
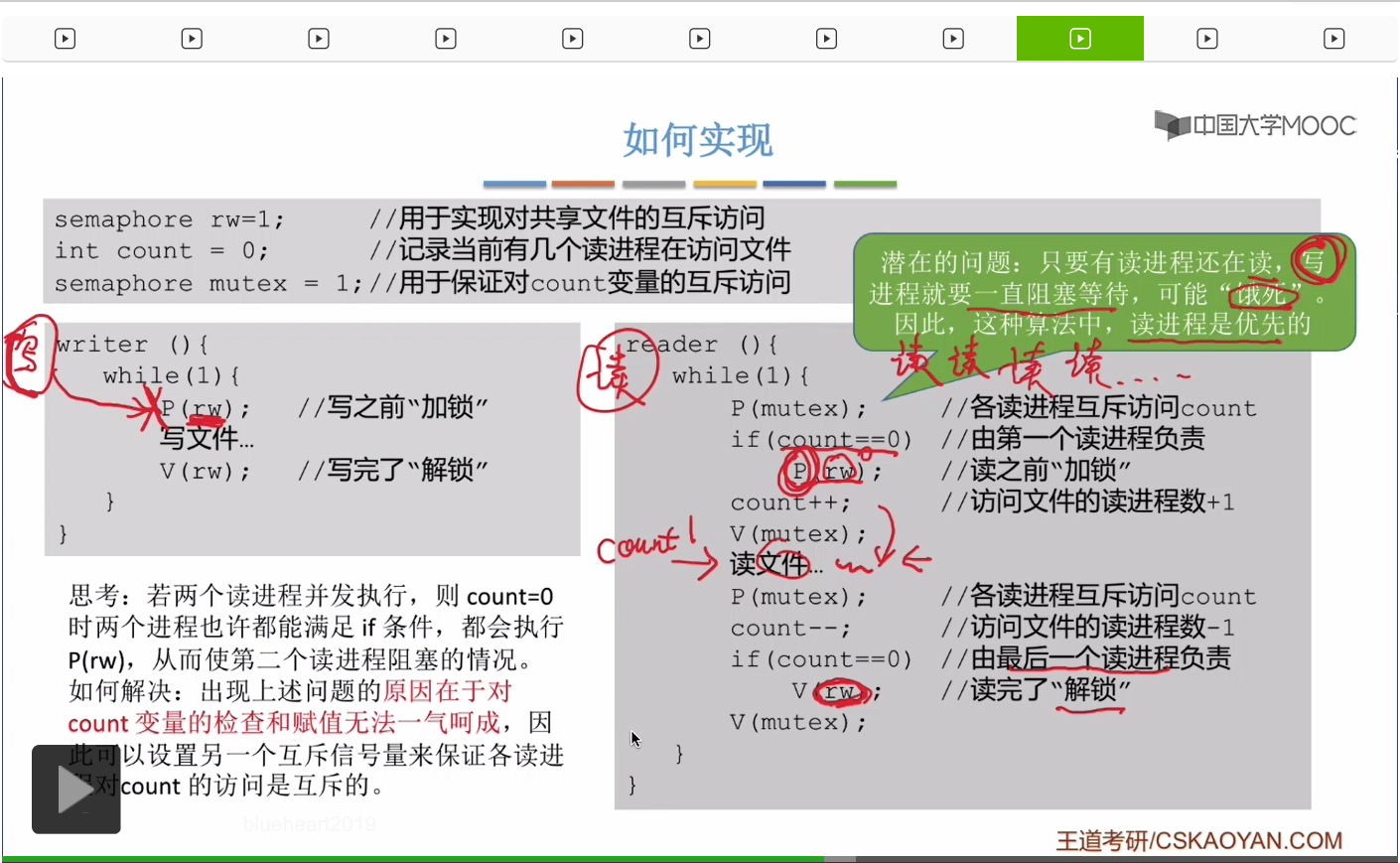
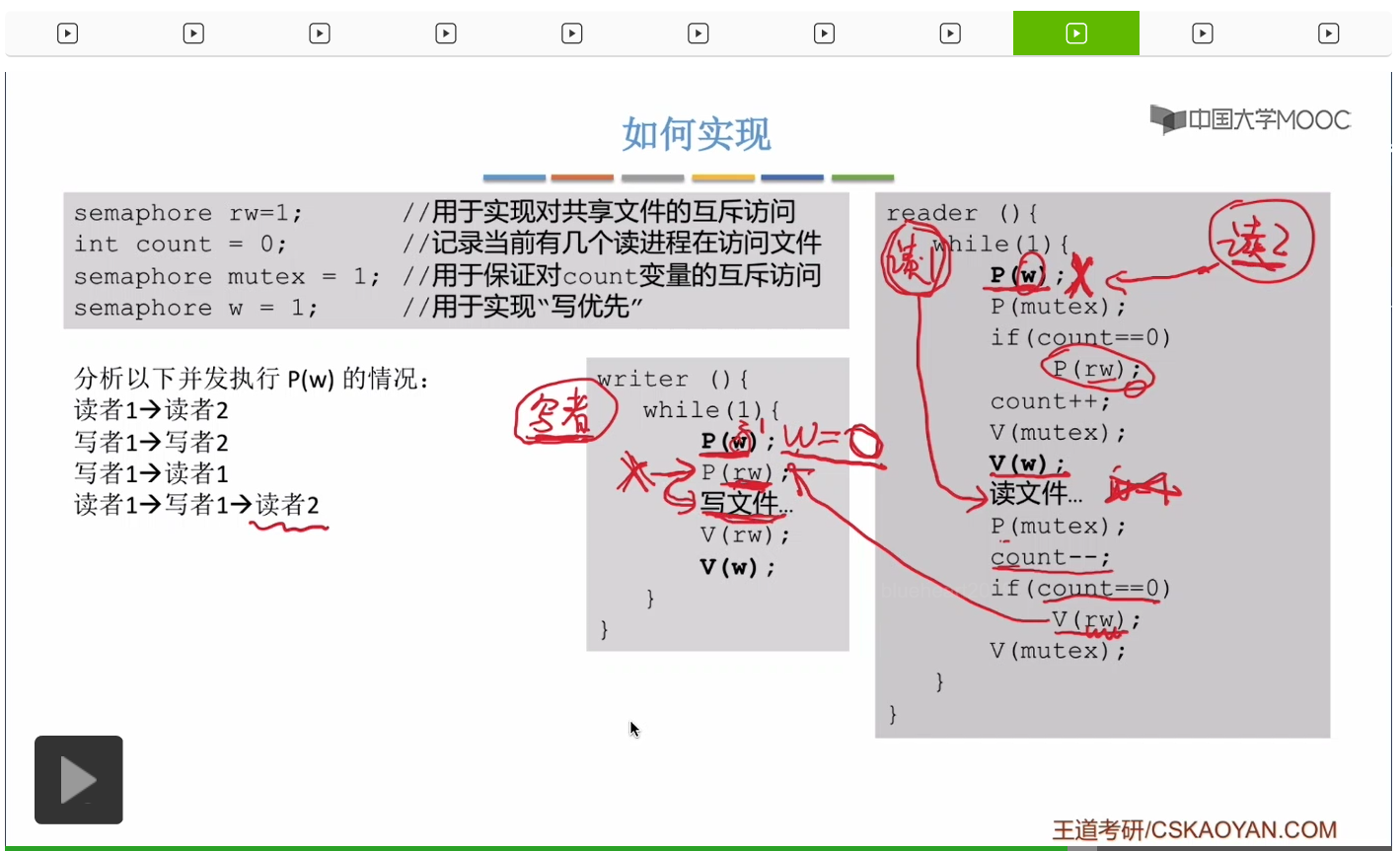
那我們怎麽解決這個寫進程餓死的問題呢?我們可以再設置一個互斥信號量w,這個題目的信號量確實有點多,這個信號量是用於實現“寫優先”,然後我們可以在這兩個位置分別對w執行P操作和V操作。



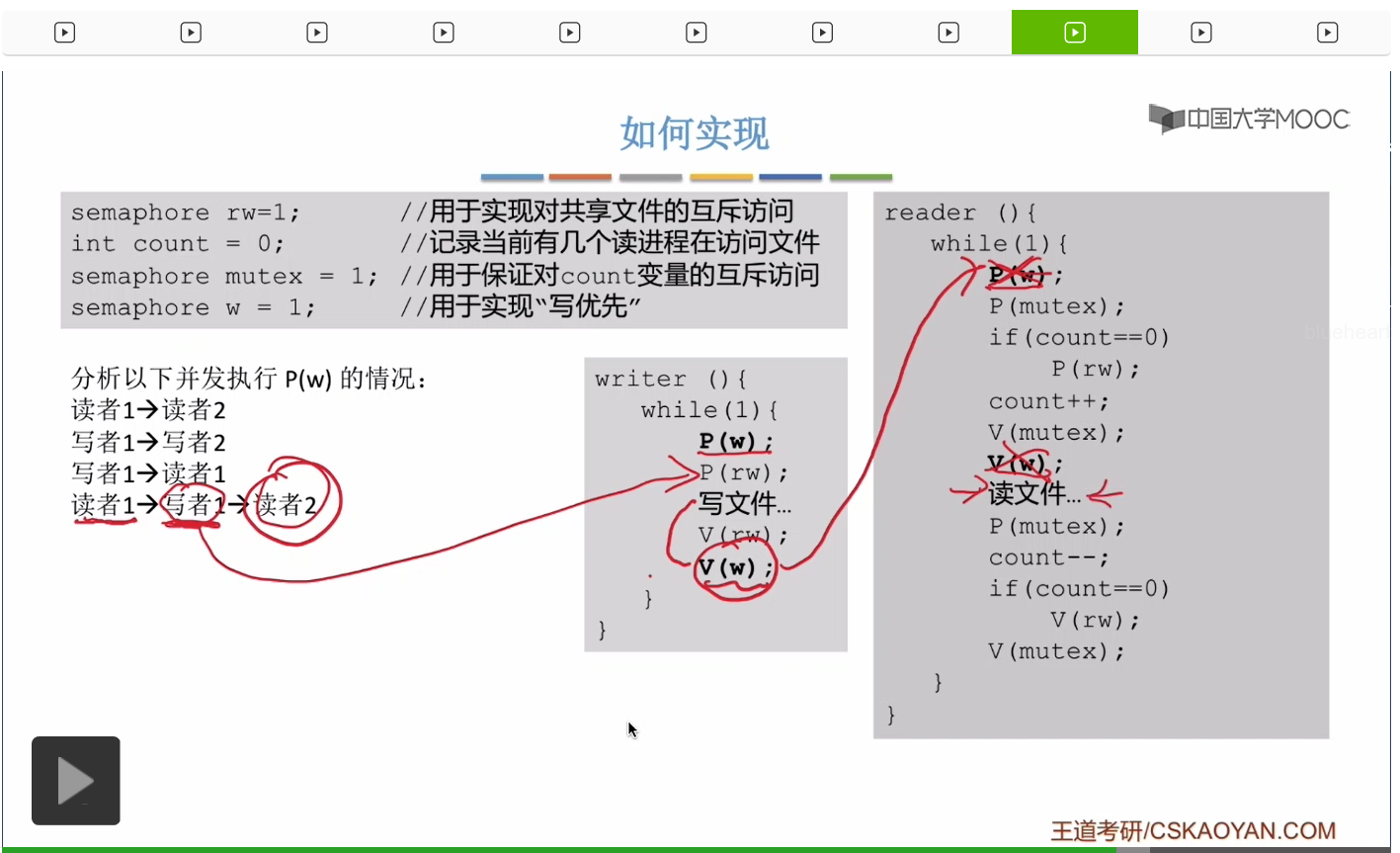

那在之前信號量機制那個小節當中我們講到過,信號量除了這個數字表示資源之外,它還有一個功能就是排隊的功能,由於這個讀者先對w執行了P操作,所以這個讀者它會排在w這個互斥信號量後面的這個隊列當中,它屬於隊頭的位置。而接下來這個寫者進程2它是之後對w執行P操作的,所以寫者進程2它會被排在讀者進程之後。因此當第一個寫者在寫完文件并且對w這個互斥信號量執行V操作的時候,它喚醒的其實是讀者,而不是之後到來的寫者。因爲讀者排在這個w信號量的隊頭,而寫者是之後才會被喚醒。
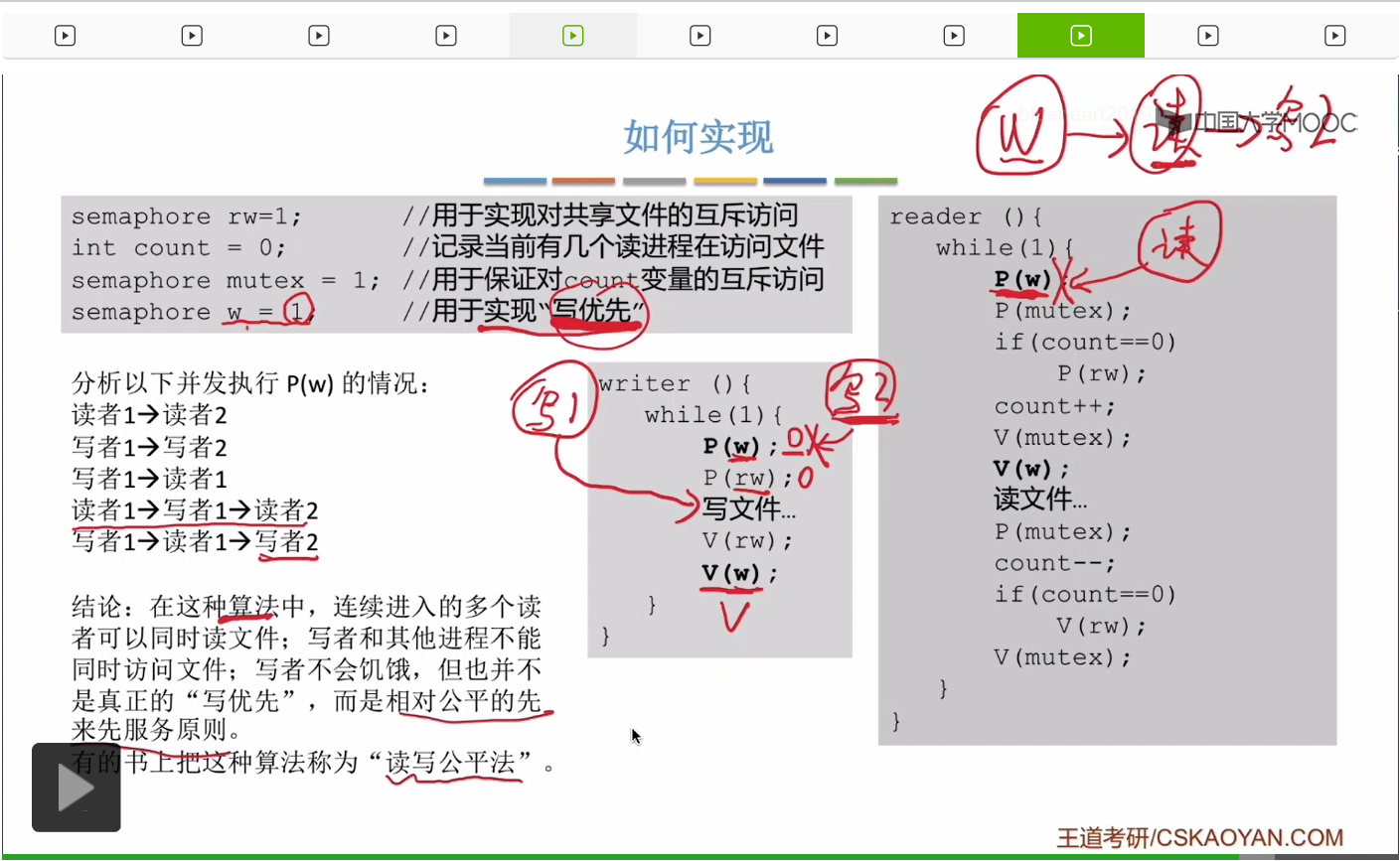
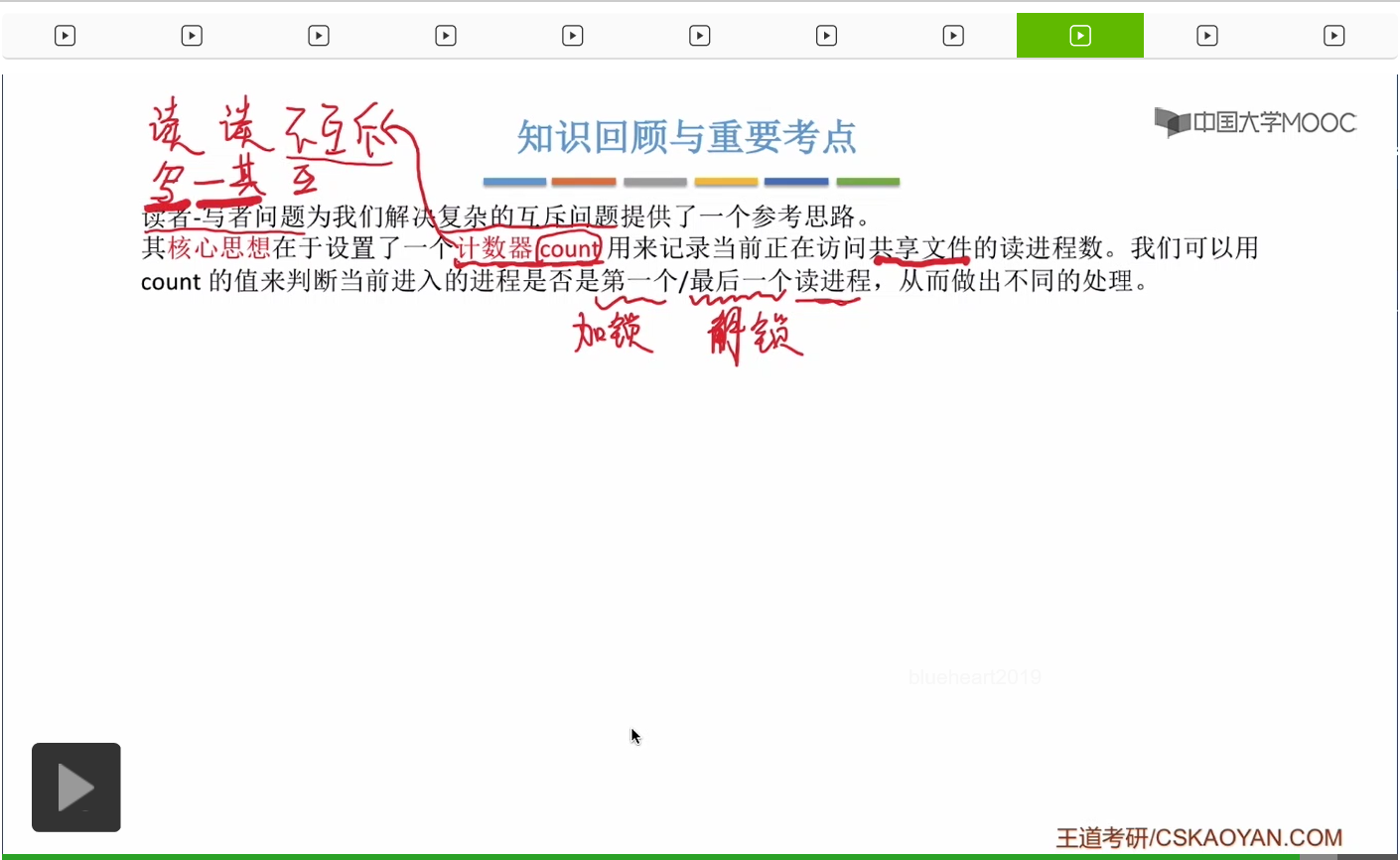
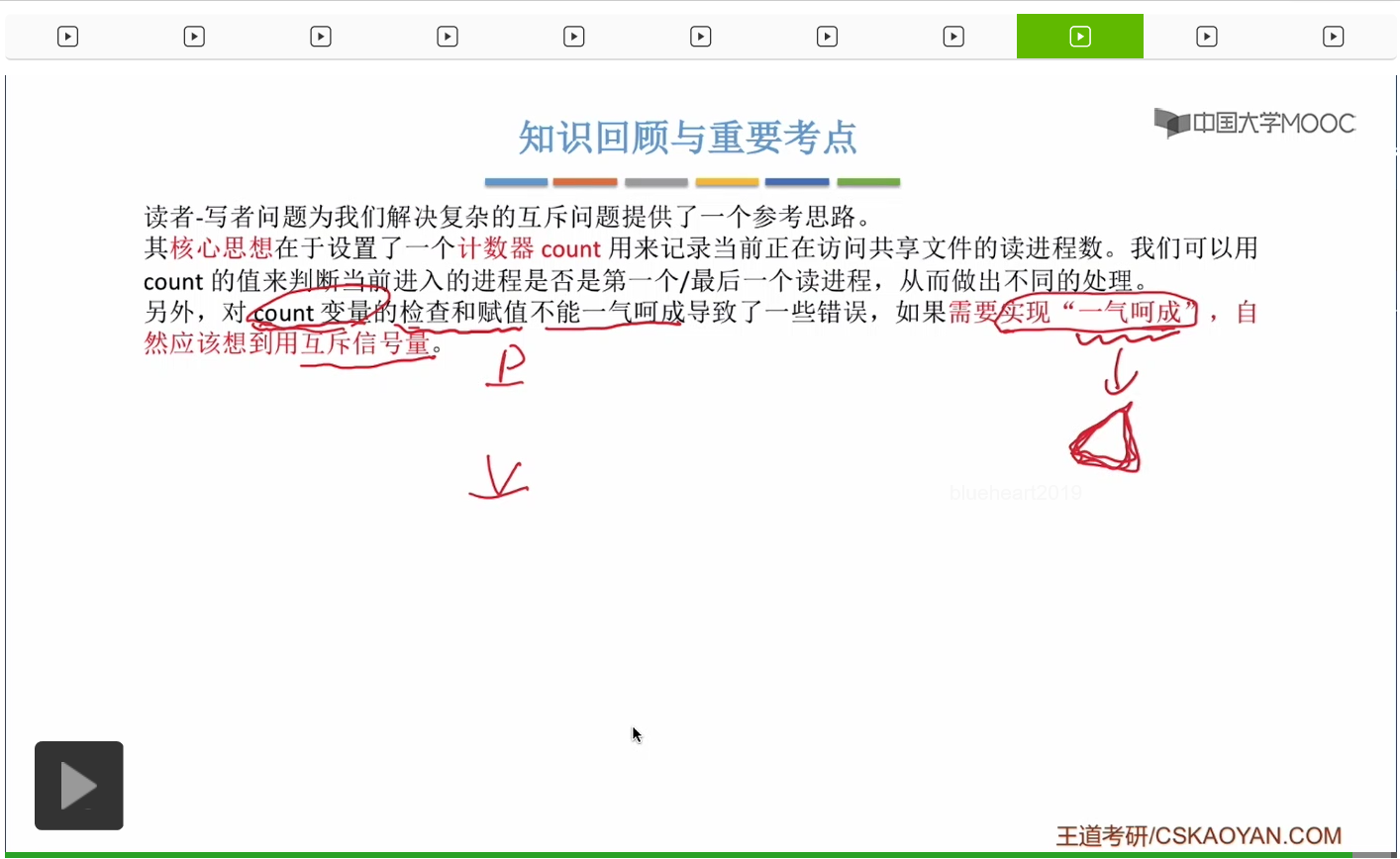
那我們在考研當中遇到的絕大多數PV操作的大題,其實都可以用我們之前學到的生產者-消費者的那種思路來解決。不過有的時候我們確實有可能會遇到像讀者寫者這種很複雜的互斥的問題。當我們遇到同步問題的時候,我們更多的應該參考的是這個生產者-消費者這種模型的思想,而當我們遇到複雜的互斥問題的時候,我們應該想到的是這個讀者-寫者問題,想想它是怎麽用這個計數器count來實現複雜的互斥規則的。
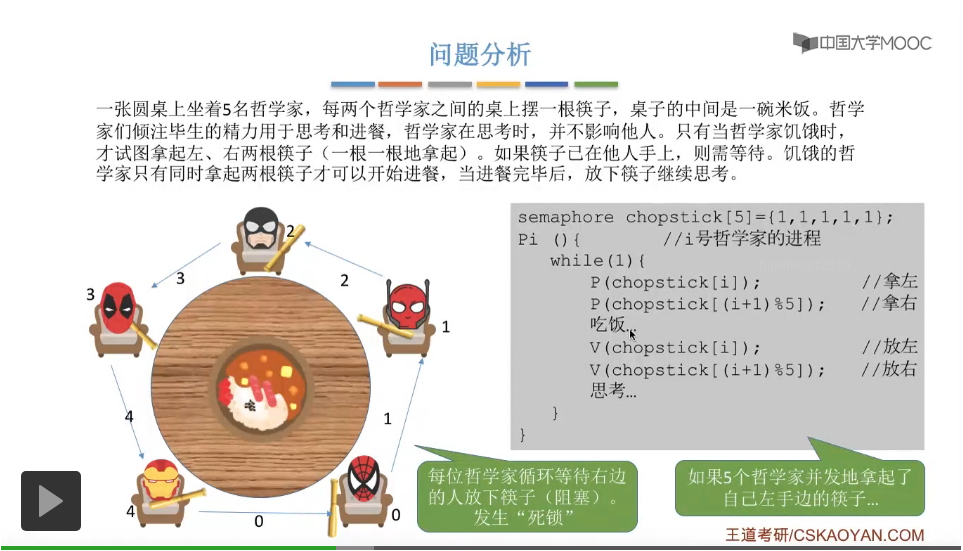
在这个小节中我们会介绍进程同步互斥的最后一个经典问题——哲学家进餐问题。

那这个题目和咱们之前介绍过的那些互斥问题不太一样的是,每一位哲学家他需要拿起两根筷子也就是两个临界资源他才可以正常地开始执行吃饭这件事。而咱们在介绍之前的那些互斥问题当中,每一个进程一般都说都只需要持有一个临界资源就可以顺利地执行了,所以这是哲学家问题和之前的那些互斥问题不同的地方。由于每一位哲学家都需要同时持有两个临界资源他才可以顺利地执行吃饭这件事情,所以如果说我们对这些临界资源的分配不当的话,那么这些哲学家进程有可能会发生死锁的现象,所以这也是哲学家问题最主要要解决的问题,怎么避免死锁。





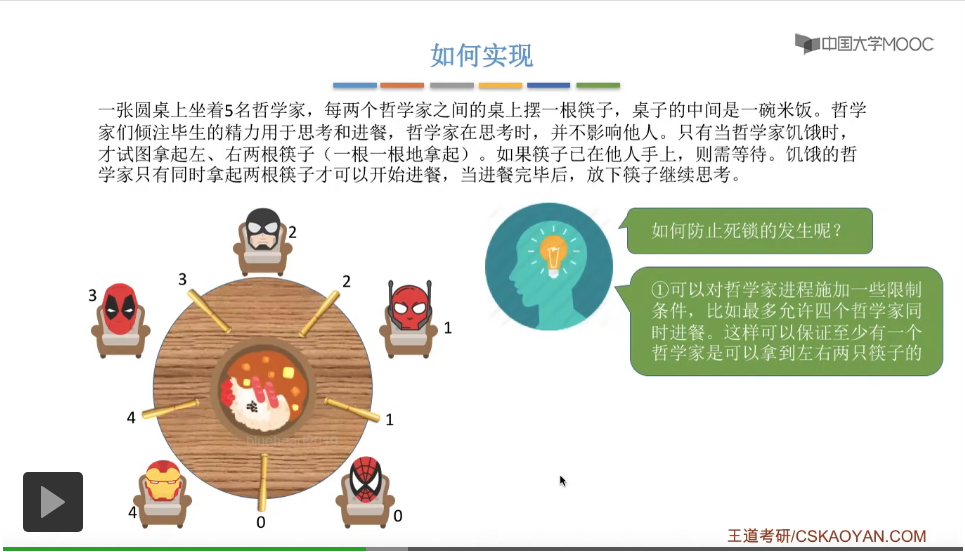
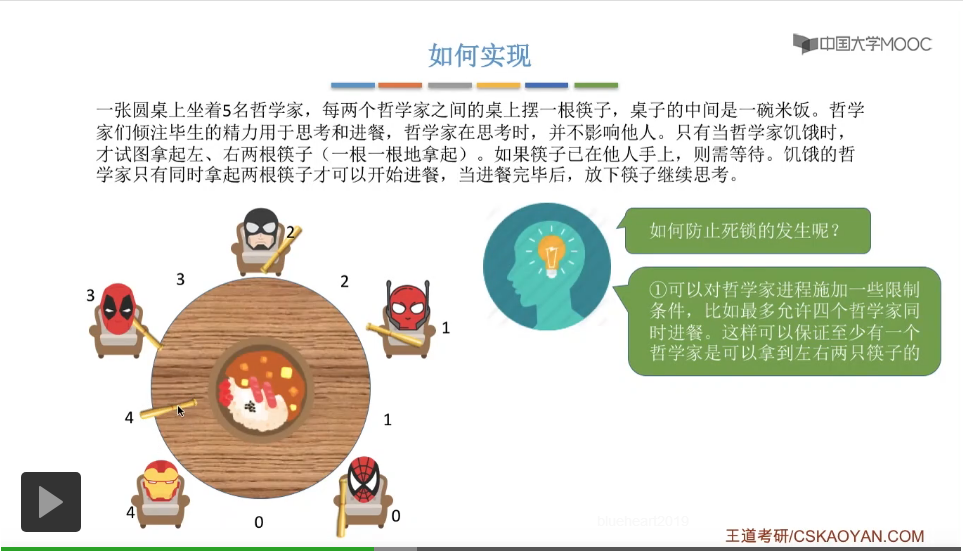
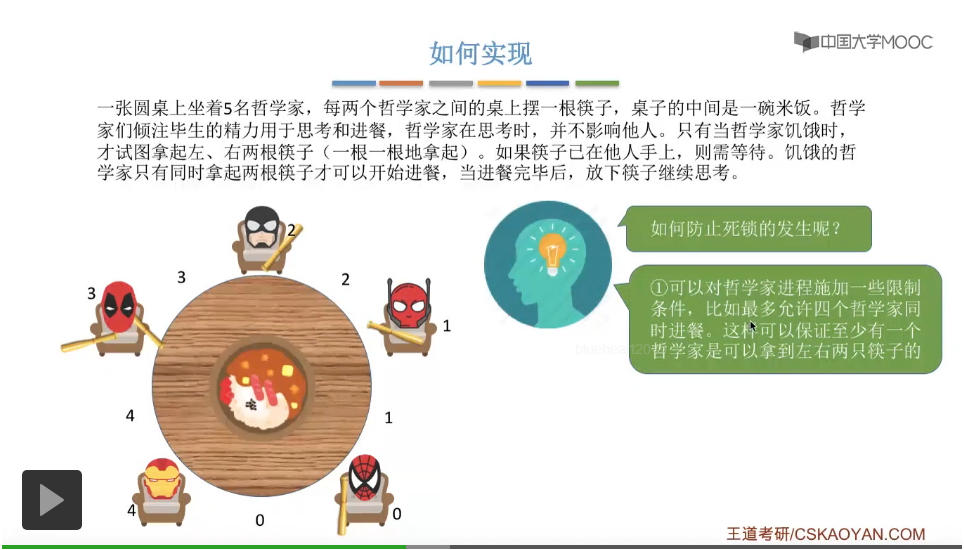
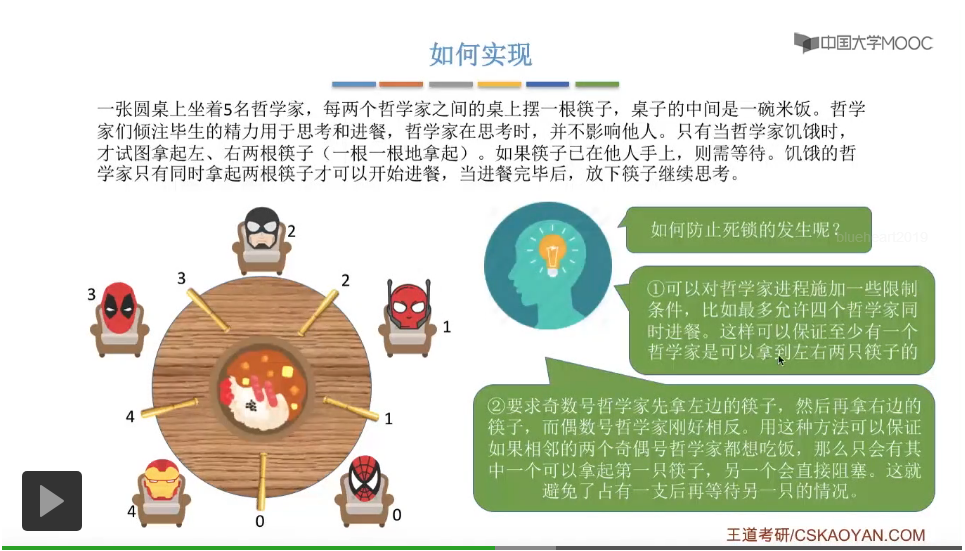
那这两个方式的具体的代码实现其实都不复杂,大家可以思考并且尝试在稿纸上自己写一遍。给一个小小的提示,第一个方案要实现允许最多四个哲学家同时进餐的话,那么我们可以设置一个初始值为4的同步信号量,那这个信号量怎么使用呢,大家自己动手尝试一下。而第二个方案的话就更简单了,我们可以在每一个哲学家拿筷子之前,先判断一下他们的序号到底是奇数号还是偶数号,然后再根据自己的这个序号来做下面的一些处理,具体的大家也自己动手尝试一下。
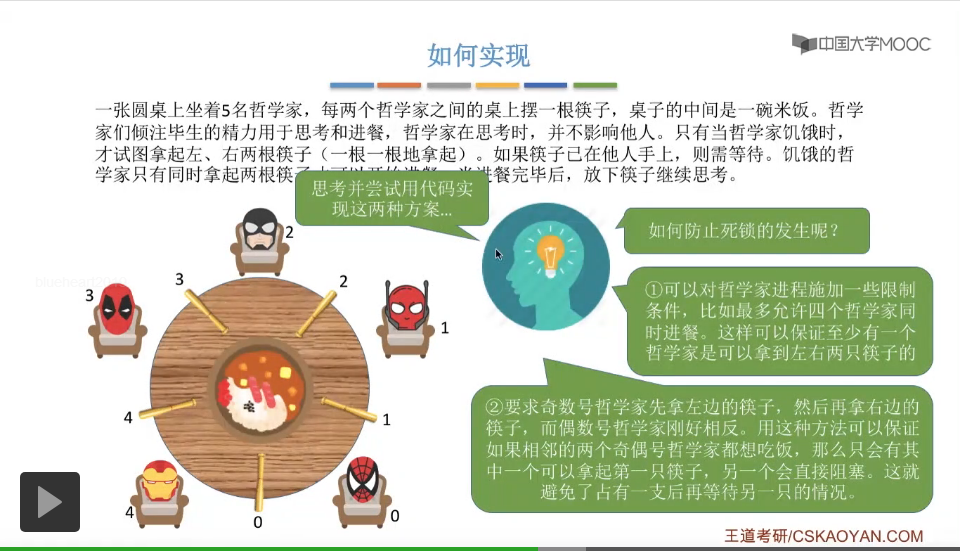
那么除了这两种方式之外,我们还可以用这样的方式来解决死锁问题。我们可以规定仅当一个哲学家左右两支筷子都可以使用的时候,才允许他抓起筷子。
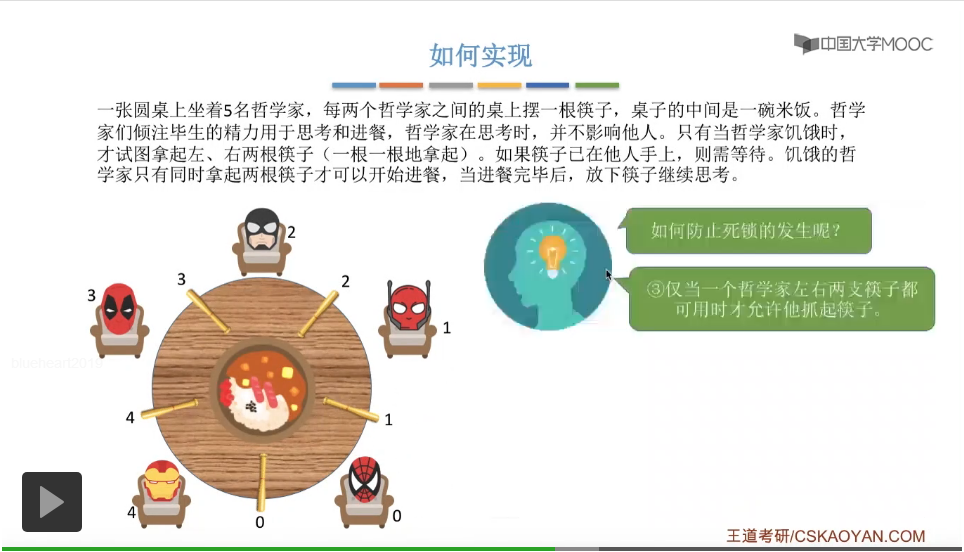











避免循环等待,发生死锁的那种现象,因此这种解决方案是可行的,它并不会发生死锁。

那么我们在学习哲学家进餐问题的时候,最关键的地方就是要理解它解决进程死锁的这种思想。而具体死锁什么时候会发生,死锁的发生又需要一些什么样的条件,这个在之后的小节当中还会有更详细的说明。

那么首先来看一下为什么要引入管程?在管程引入之前,其实人们用来实现进程同步和互斥,主要是使用信号量机制,就是咱们之前学过的那种PV操作。但是信号量机制存在的问题就是编写程序困难、易出错,这点大家在做题的时候应该也有体会过。比如说咱们在生产者-消费者问题当中提到过,如果说实现互斥的P操作在实现同步的P操作之前,那么就有可能会引起死锁的状态。我们在使用信号量机制的时候,就不得不关心这些PV操作的顺序,这就造成了我们在编写程序的时候很困难,并且极易出错的这种问题。管程,其实它是一种高级的同步机制,它本质上也是用于实现进程的互斥同步的,只不过它比之前的这种信号量机制要更方便易用一些,是一种更高级的同步机制。
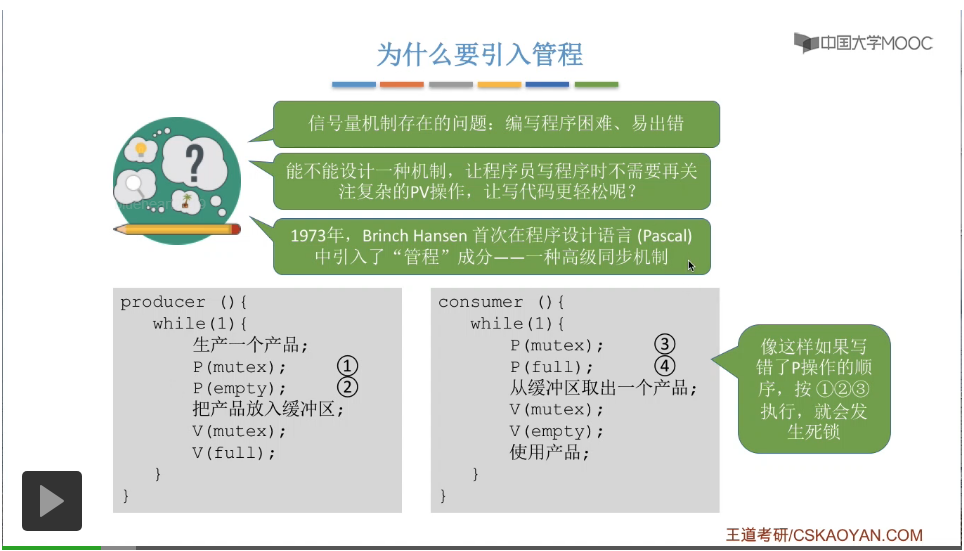
那么什么是管程?管程又有什么基本特征呢?管程其实和之前学过的PV操作一样,它也是用来实现进程的互斥和同步的。而进程之间要实现互斥和同步,是因为进程之间可能会共享某些数据资源。比如说像生产者-消费者问题当中,生产者和消费者都需要共享地访问缓冲区这一种资源,所以为了实现各个进程对一些共享资源的互斥或者同步的访问的话,那么管程就要由这样一些部分组成。第一,局部于管程的共享数据结构说明。比如说咱们刚才提到的生产者-消费者问题当中,生产者和消费者都需要共享访问的那个缓冲区,其实我们可以用一种数据结构来表示这个缓冲区,对缓冲区进行管理,所以在管程当中需要定义一种和这种共享资源相对应的这种共享数据结构。管程当中还需要定义对之前所提到这种共享数据结构进行操作的一组函数。对这个数据结构要进行初始化的语句,也需要在管程当中说明。如果学过面向对象设计的同学可能会发现,管程的定义其实就有点类似于我们的类。在类当中我们可以定义一些数据,并且还可以定义对这些数据进行操作的一组函数,一组过程。另外我们还可以在这个类当中定义一些对这些数据进行初始化的语句。当然如果没有学过面向对象语言的同学理解不了也没有关系,咱们之后还会有别的例子来让大家理解。那爲了用管程實現進程之間的互斥和同步,那管程有這樣一些特徵。管程当中定义的这些共享的数据结构,只能被管程当中定义的这些函数所修改。所以如果我們想要修改管程當中的這些共享數據結構的話,我們只能通過調用管程提供的這些函數來間接地修改這些數據結構,其實這就是第一句和第二句的意思。第三,每次僅允許一個進程在管程内執行某個内部進程。就是說,管程當中雖然定義了很多函數,但是同一時刻肯定只有一個進程在使用管程當中的某一個函數。別的進程如果也想使用這個管程當中的某一些函數的話,那只要之前的這個進程還沒有用完,別的進程就暫時不能開始執行管程的這些函數,所以這是第三句的意思,每次僅允許一個進程在管程内執行某個内部過程。那爲什麽要這麽設計呢?我們可以想一下,比如説我們把生產者-消費者問題當中的緩衝區定義爲了管程當中的某一種共享數據結構。那按照之前咱們學習的内容我們知道,各個進程對緩衝區的訪問必須是互斥的,也就是有一個進程在訪問緩衝區的時候,別的進程肯定不能同時訪問,必須先等待,所以如果我們能夠保證每一次僅有一個進程能在管程當中的某一個内部過程當中執行的話,那麽這就意味著每一次對這個共享數據結構的訪問肯定只有一個進程正在進行,而不可能有多個進程正在同時地訪問這個共享數據結構,所以這就是管程的精髓所在。

那接下來我們用一個具體的例子看一下管程是怎麽解決生產者-消費者問題的?需要注意的是在這個地方并沒有按照某一種嚴格的語法規則來進行表述,這個地方只是爲了讓大家容易能夠理解,所以用了類C語言的僞代碼來表示管程當中的這一系列邏輯。我們可以用程序設計語言當中提供的某一種特殊的語法,比如說monitor,end monitor,用這樣一對關鍵字來定義一個管程,就是指中間的這個部分就是管程的内容。那管程的名字叫ProducerConsumer。另外我們可以定義一些條件變量用来實現同步,還可以定義一些普通的變量,用來表示我們想要記錄的信息,比如說緩衝區當中的產品個數。那除此之外我们还需要定义对缓冲区进行描述的一些数据结构,不过为了方便我们这儿就省去了。那生产者进程想往缓冲区里放入一个自己新生产的产品,可以直接调用管程当中定义的这个insert函数就可以实现。像之前咱们用PV操作的时候,生产者进程需要有一堆PV操作,但如果采用了管程,那这个代码就变得特别简洁。首先,就是生产一个产品。之后,就是定义这个管程当中的insert函数,然后把自己生产的这个产品作为这个函数的参数传进去。那接下来的问题,生产者进程就不用管了。接下来就由管程来负责解决剩下的什么同步啊互斥啊一系列很复杂的问题。同样的,消费者进程也可以很简单地调用管程当中定义的某一个函数就可以实现从缓冲区当中取出一个产品这样的事情,所以消费者进程的代码也变得非常简洁。而从缓冲区当中取出一个产品的时候,缓冲区空了怎么办?还有对缓冲区的互斥怎么办?这些消费者进程都不用关心,剩下的都是管程会负责解决的问题。我们定义了管程之后,在编译的时候其实会由编译器负责实现各个进程互斥地进入管程当中的过程这样一件事情。举个例子,比如说有两个生产者进程并发地执行,并且先后都调用了管程的insert这个过程,或者说insert这个函数,那么由于刚开始没有任何一个进程正在访问这个管程当中的某一个函数,所以第一个生产者进程在调用insert函数的时候是可以顺利地执行下去的。它会执行完一系列代码,包括判断缓冲区是否满了,或者此时是否有一些消费者进程需要唤醒,这一系列的事情都是在管程的insert函数里面进行完成的。而如果在第一个进程没有执行完这个函数相应的这一系列逻辑的时候,第二个进程就尝试着也想调用insert函数。那么由于编译器实现的这些功能,它会暂时阻止第二个进程进入insert函数,所以就会把第二个进程阻塞在insert函数后面,就类似于一个排队器,让它先等待,等第一个进程访问完了insert函数之后,才会让第二个进程开始进入insert函数,然后执行相应的这一系列逻辑。所以互斥地使用某一些共享数据,这是由编译器负责为我们实现的,程序员在写程序的时候不需要再关心如何实现互斥,只需要直接调用管程提供的这一系列的方法,其实它本身就已经能够保证这是互斥地进行的。那除了互斥之外,管程还可以实现进程的同步。我们可以在管程当中设置一些条件变量,比如在这个地方我们设置了full和empty这两个条件变量。还有与它们对应的等待和唤醒操作,用来实现进程的同步问题。比如说如果有两个消费者进程先执行,生产者进程后执行,那么第一个消费者进程在执行的时候首先是调用了这个管程的remove这个过程,或者说这个函数。那首先需要判断此时缓冲区里是否有可用的产品,那由于刚开始count的值本来就是零,所以第一个消费者进程需要执行wait,也就是等待操作。于是第一个消费者进程会等待在empty这个条件变量相关的这个队列当中。同样的,第二个进程开始执行remove函数的时候,也会发现此时count的值是零,所以它也需要执行这个等待操作。同样的,也会插入到empty这个条件变量对应的队尾,就像这个样子。那之后如果有一个生产者进程开始执行,那它会执行这个管程的insert函数或者说这个过程,那么它会把它自己生产的产品放入到缓冲区当中,并且会检查自己放入的这个产品是不是这个缓冲区当中的第一个产品。那如果说是第一个产品的话,那么就意味着此时有可能有别的消费者进程正在等待我的这个产品,所以接下来这个生产者进程在执行insert函数的时候也会在其中执行一个唤醒操作——signal操作,用于唤醒等待在empty这个条件变量对应的等待队列当中的某一个进程。那一般来说都是唤醒排在队头的这个进程,也就是第一个消费者进程。那由于第一个消费者进程被唤醒了之后,它就可以开始往下执行,首先是执行count--,就是让count的值由1又变回了0,然后再检查在自己取走这个产品之前,缓冲区是不是已经满了,如果说缓冲区之前是已经是满的,那么就意味着有可能会有生产者进程需要被唤醒。于是这个消费者进程又会调用一个对full这个条件变量的signal也就是唤醒操作,那原理呢和刚才咱们介绍empty这个的原理其实是一样的。那最后remove函数会返回一个消费者进程想要的产品对应的一个指针。所以第一个消费者进程就可以通过这样一个步骤就可以取出它想要的产品。而在取产品的过程当中,如何实现对缓冲区的互斥访问,或者当缓冲区当中没有产品的时候自己的这个消费者进程应该怎么处理,这一些都不需要消费者进程再来关心,这一些都是由管程负责解决的。在采用了管程这种机制之后,实现进程的互斥和同步这件事情就变得简单多了,我们只需要调用管程当中的某一些过程来完成我们想要完成的事情就可以了。
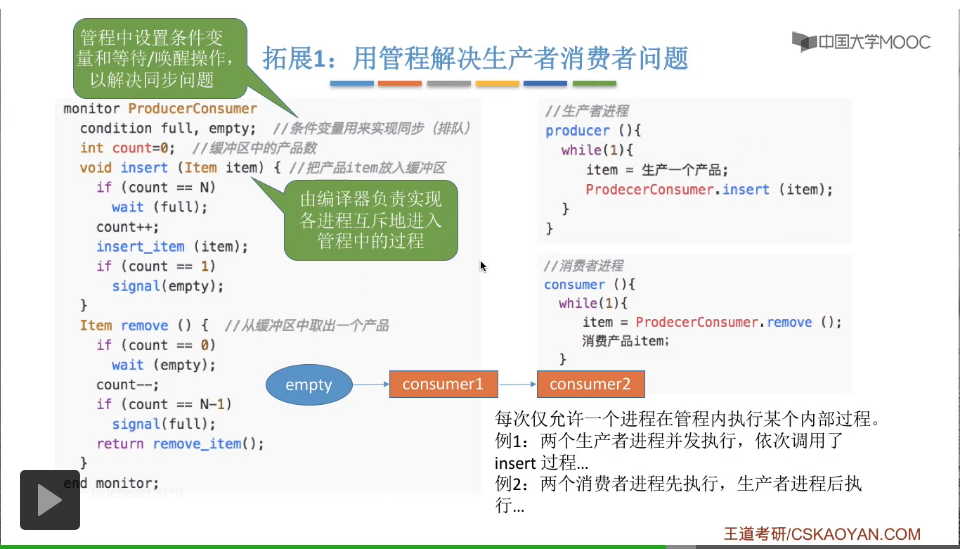
那么我们再根据刚才的例子用自己的话对管程的特点进行一个描述。第一我们需要在管程当中定义一些共享数据。比如说像生产者-消费者问题当中的缓冲区对应的数据结构我们就可以在管程当中定义。第二,我们可以在管程当中定义一些用于访问这些共享数据的“入口”,这个“入口”其实就是所谓的函数或者之前那种说法当中所谓的过程。比如说在生产者-消费者问题当中我们定义了一个insert函数和一个remove函数,通过这两个入口我们可以对缓冲区进行操作。第三,其实我们在生产者消费者进程当中,是不可以直接访问这个共享缓冲区的。我们只能通过管程当中定义的这些特定的“入口”,也就是它提供的这些函数才能访问这个共享的缓冲区。第四,管程当中有很多入口,比如说有insert“入口”,有remove这样的“入口”,也就是有很多个函数。这种互斥访问管程当中各个“入口”的这种特性,这种互斥特性,它是由编译器负责实现的,程序员其实并不需要关心。可以让一个进程或者线程在条件变量上等待,比如说咱们刚才举到的在empty这个条件变量上等待的例子。那如果一个进程在条件变量上等待的话,那这个进程应该先释放管程的使用权,也就是要让出这个“入口”,另外我们还可以通过唤醒操作,把等待在条件变量上的进程或者线程唤醒。那么通过刚才的例子我们知道,程序员其实可以通过某一种特殊的语法来定义一个管程,比如说monitor和end monitor这样一对关键字。之后其他的程序员就可以通过这个管程当中定义的这些特殊的入口,或者说这些特定的函数,就可以很方便地实现进程的同步和互斥了。其实在管程当中实现了我们之前PV操作当中需要实现的什么排队啊阻塞啊互斥啊这一系列的问题,我们只需要简单地调用一个特殊的“入口”,一个函数就可以很方便地使用了。其实这就是程序设计当中所谓“封装”的思想。把一些复杂的细节“隐藏”了,对外只需要提供一个简单易用的接口。

如果熟悉Java的同学在时间允许的情况下其实也可以自己动手用这个关键字来尝试实现一下生产者-消费者问题当中的管程到底应该怎么定义。

管程其实无非也就是为了实现进程的同步和互斥,只不过是实现起来会更方便一些。另外,我们介绍了管程的组成和基本特征,在考试当中最容易考察的其实是管程的这两个基本特征。首先,外部的进程或者线程只能通过管程提供的特定“入口”,这个“入口”其实也就是管程当中定义的某一些函数或者说过程才可以访问管程当中定义的那些共享数据。另外呢,每一次仅允许一个进程在管程内执行某个内部过程,那这两点是最容易在选择题当中进行考察的。另外,我们补充了两个知识点:各进程互斥访问管程的特性其实是由编译器负责实现的,程序员并不需要关心。另外,可以在管程当中设置条件变量还有等待唤醒操作就可以解决管程的同步问题。那管程其实就是应用了封装的思想,把进程同步、互斥这些复杂的细节隐藏在了管程定义的那些函数之内,而对外只提供一个简单易用的函数调用的接口,所以管程是应用了封装的思想。
