# -*-coding:utf8-*-
import urllib2
from lxml import etree
import re
import requests
import os
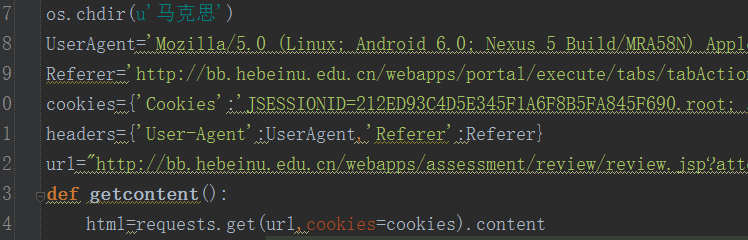
os.chdir(u'马克思')
UserAgent='Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.76 Mobile Safari/537.36'
Referer='http://bb.hebeinu.edu.cn/webapps/portal/execute/tabs/tabAction?tab_tab_group_id=_1_1'
cookies={'Cookies':'JSESSIONID=212ED93C4D5E345F1A6F8B5FA845F690.root; safedog-flow-item=1D297B60D475833D3CD94F86A368A3F1; JSESSIONID=377861A43428B1E1A04E54C9C351F2EB.root; session_id=F1CBA8BC1788C5DA57DC9654B81C3E12'}
headers={'User-Agent':UserAgent,'Referer':Referer}
url="http://bb.hebeinu.edu.cn/webapps/assessment/review/review.jsp?attempt_id=_120019_1&course_id=_1676_1&content_id=_35841_1&return_content=1&step=null"
def getcontent():
html=requests.get(url,cookies=cookies).content
reg1=re.compile(r'<div tabindex="0">s<div class="vtbegenerated inlineVtbegenerated">(.*?)</div>')
reg2=re.compile(r' s<div class="vtbegenerated inlineVtbegenerated">(.*?)</div>')
question=re.findall(reg1,html)
ans=re.findall(reg2,html)
p=0
fd=open(u'第一章多选题.txt','wb')
for (i,m) in zip(question,ans):
p+=1
fd.write('%s'%p+'.'+i+' '+u'答案:'+m+' ')
fd.close()
if __name__=='__main__':
getcontent()
登录一个网址的写法:
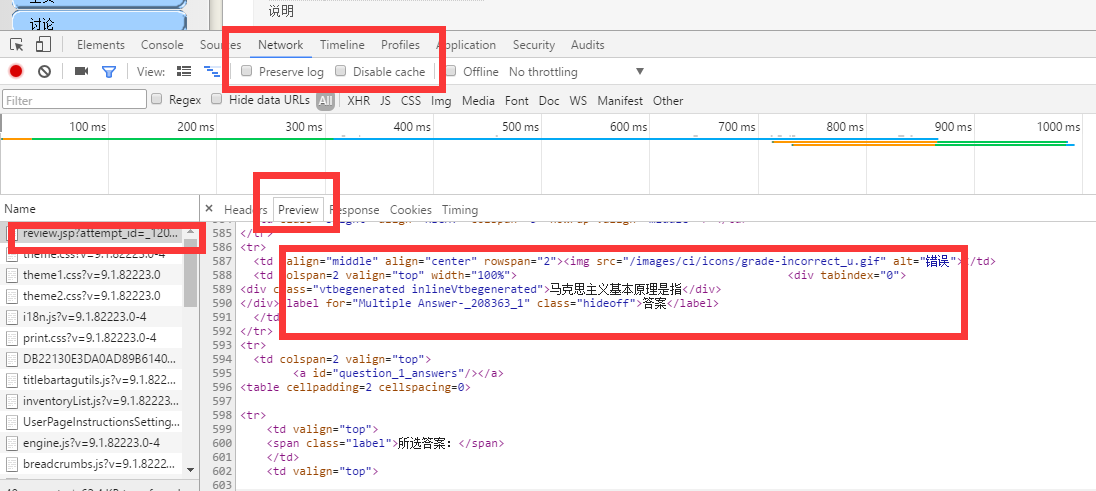
遇到的问题:
js加载的动态信息,要找到数据接口
一般都是Name比较长的是你所需需要的