drop列删除行
champion.columns = champion.iloc[0] #### 将第一行的数据 赋值给 列名
champion.drop([0], inplace=True) #### 将第一行数据 删除掉
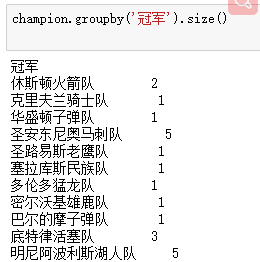
groupby(列名).groups分组。
champion.groupby('冠军').groups # 分组
- 有坑点
groupby是DataFrame对象了,只是通过groups将结果以字典的形式呈现出来。或者通过size()计算次数

* 分组为多个:用列表套起来
size()计算次数
排序(坑点)
-
sort_values()按值排序排序
-
sort_index()按照索引排序
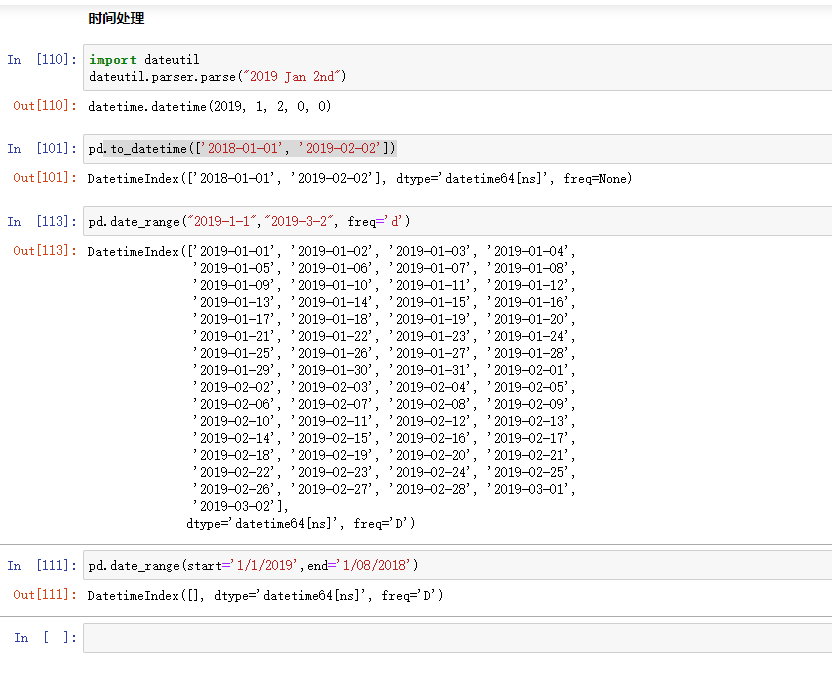
时间处理
matplotlib学习
1 标题乱码
### 解决乱码windows
plt.rcParams['font.sans-serif'] = ['SimHei']
2 画一个简单的折线图
a = [3,1,10,6] ### 默认显示Y轴的值
plt.plot(a) #### plot()画折现图的函数
plt.show() #### 显示画的图表
3 完全
x = [2,5,7,10]# 注意这是列表。通过.index得出的也是列表!!
y = [1,2,3,4]
plt.figure(figsize=(10,6)) #### 设置画布大小
plt.title('title标题', fontsize=20, color='red') #### 设置图表的标题
plt.xlabel('x轴', fontsize=20) #### 设置x轴的值
plt.ylabel('y轴', fontsize=20) #### 设置y轴的值
plt.plot(x, y, color='k', marker='D', linestyle=':') ### 画图
plt.show() ### 显示
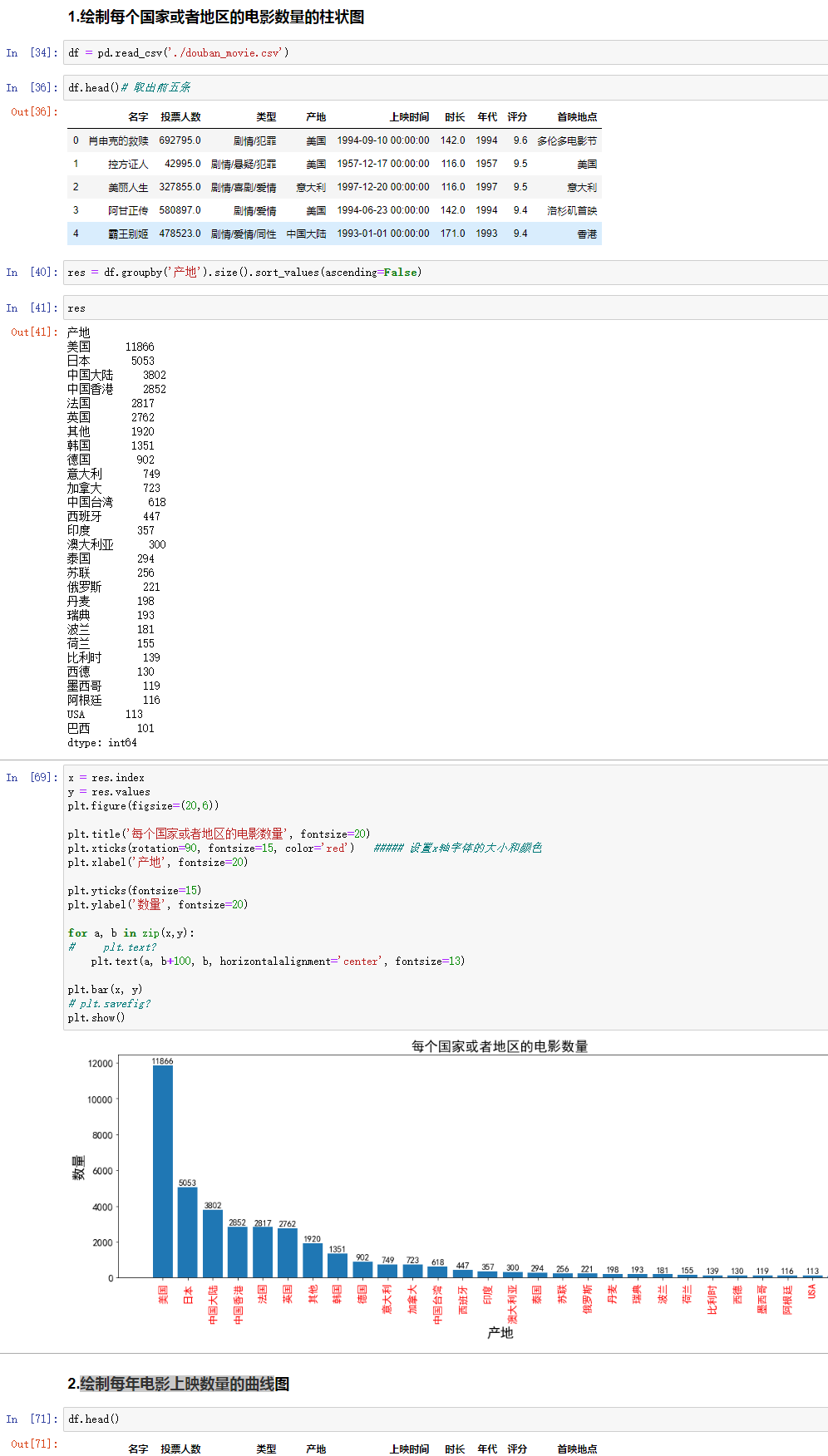
绘制每个国家或者地区的电影数量的柱状图
读 csv是pd,画图是plt
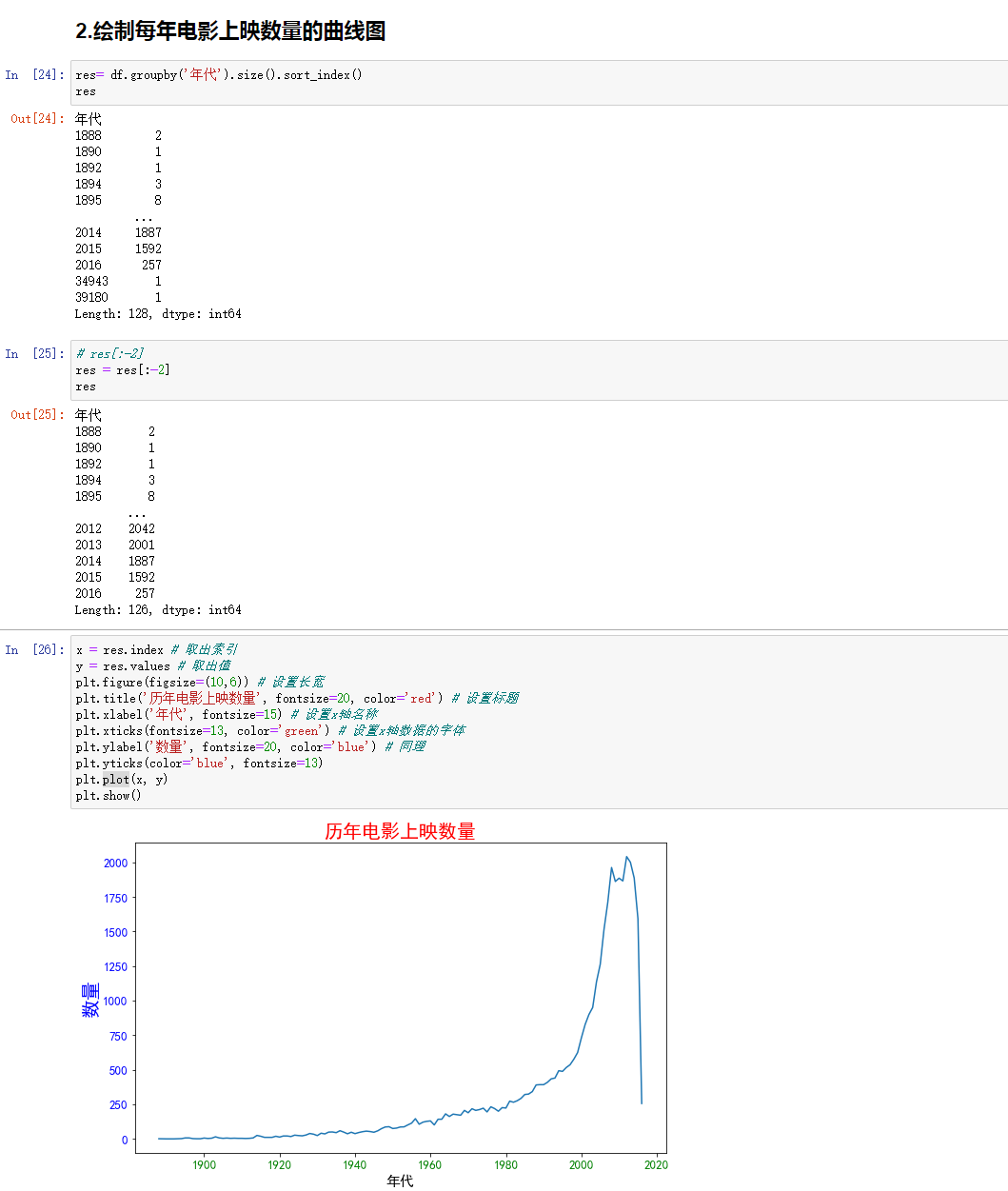
2.绘制每年电影上映数量的曲线图
3.根据电影的长度绘制饼图
df=pd.read_csv('./douban_movie.csv')
df['时长']# 读取到内容,通过字典类型的中括号取值!!
value_counts每个元素的个数